图形学面试题
仅用于个人学习记录
主要参考乐书和这篇:https://zhuanlan.zhihu.com/p/430541328
还有这个网站:https://learnopengl-cn.github.io/,这个写的真的非常好
数学方面
点乘/点积/内积
ab = axbx + ayby + azbz = |ab|cosθ
几何意义:1、a在b上的投影,再乘以b的长度,带方向;2、投影正负号和方向有关,投影=0时垂直,<0时方向相反, >0时方向相同。
点乘是标量,ab=ba
叉乘/叉积/外积
A x B = x1y2 -y1x2 = |A||B|Sin(θ)
AxB = -(BxA)
几何意义:右手定则,方向为和AB垂直的法线方向,叉乘绝对值为平行四边形面积
判断点是否在三角形内
重心坐标法
向量叉乘法:
沿逆时针方向,三角形两两顶点构成三个向量,比如AB,BC,CA,分别用这三个向量与起点和P的交点构成的向量求叉乘,如ABxAP, BCxBP, CAxCP,由右手定则,如果三个结果都是正的,说明这个点都在向量的左边;可以推导得出这个点在三角形内,否则只要有一个是负数,就说明在右手边,在三角形外了。
面积法:
叉乘可以算出面积,三个小三角形面积之和 = 原三角形面积,就在内部,>在外部。
判断光线与三角形是否相交
第一种方法:代入点法式方程计算交点坐标N(P - P0) = 0;再用叉乘判断是否在三角形内部。
第二种方法:
P=O+td代入,满足:t>0,αβγ>0时相交。若只能命中一个三角形,则根据t大小比较,先命中小的t。封闭的物体,射线从中穿过时一定命中奇数个三角形。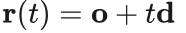
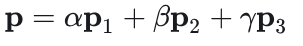
1、渲染管线(渲染流水线)计算机绘制图像的过程
图形渲染管线实际上指的是:一堆原始图形数据途经一个输送管道,期间经过各种变化处理最终出现在屏幕的过程。
分为:应用阶段、几何阶段、光栅化阶段(、像素处理阶段)
1.1、应用阶段(由CPU完成,后面的阶段为GPU完成)
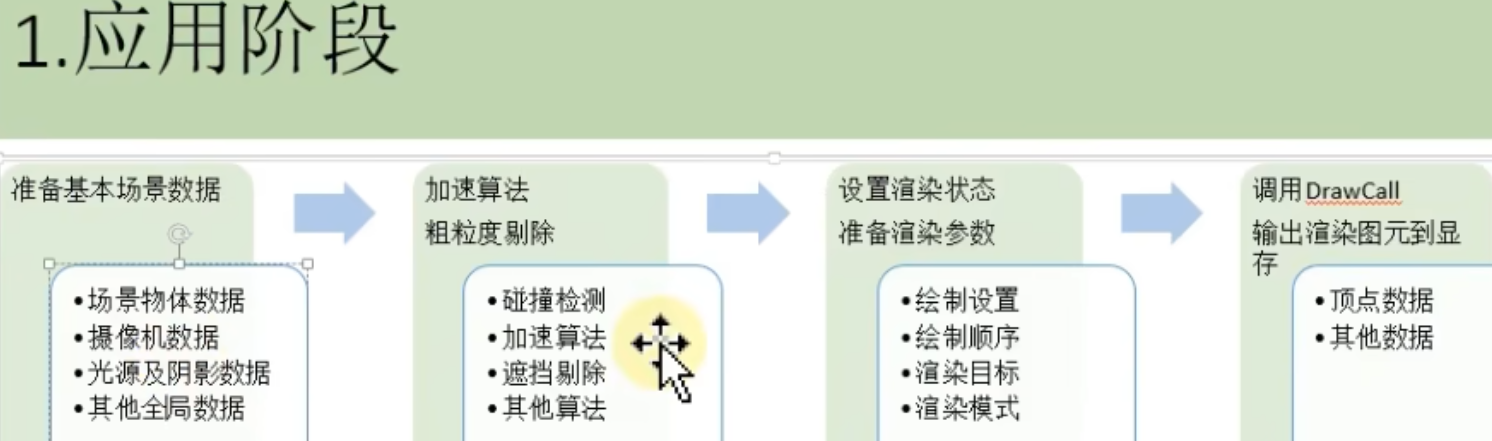
核心目标是准备渲染需要的数据并提交给GPU
三个任务:
- 判断物体的可见性并剔除不可见物体;
- 设置每个模型的渲染状态,包括材质纹理shader等;
- 通过DrawCall提交渲染图元给GPU。
1.1.1、DrawCall
DrawCall是通知GPU绘制的指令。DrawCall开销大,主要是因为CPU的性能瓶颈。
每次调用DrawCall需要CPU准备渲染数据,通知GPU切换渲染状态。并且涉及用户态到内核态的切换。
1.1.2、DrawCall优化
优化方法:
批处理,GPU实例化,共用材质,合并纹理图集,遮挡剔除,减少透明物体。
- 静态批处理:适合不会移动的静态物体,但合并的网格数据放在内存中,增加内存占用
- 动态批处理:适合顶点数少的动态物体,小于300个顶点,并且材质等相同,CPU对顶点进行模型变换,到统一的世界空间,合并网格,把所有顶点数据放到新的顶点缓冲区,一次setpasscall和drawcall,因此太多顶点反而可能导致性能下降;
- GPU实例化:适用于大量相同的物体,允许相同的模型和材质批量渲染
CPU准备共享的材质网格数据作为模板;实例化数据缓冲区放矩阵变换,uv偏移等数据;还有顶点数据缓冲区放顶点数据,由GPU进行矩阵变换,
CPU准备好共享数据和独有数据后打包成一个数组,一次DrawCall,发送所有数据,GPU快速渲染。 - 合并纹理/图集,减少纹理切换
- LOD:远处用低精度模型,减少顶点数(不减少drawcall)
- 共用材质:材质相同才可以合批,因为材质不同必须得切换渲染pass
- 遮挡剔除:减少不必要的DrawCall
- 减少透明物体:透明物体需要额外处理混合顺序,混合依赖背景色,容易破坏合批要求的连续渲染相同材质物体条件,还会overdraw(一个像素处理多遍)。
动态批处理和GPU实例化的区别:GPU实例化是一次drawcall用相同的shader处理不同的参数,而动态合批是让物体合并为一个网格
1.2、几何阶段
将3D顶点数据变换到屏幕空间。
主要包含:顶点着色器(MVP变换)、图元装配、曲面细分着色器、几何着色器、裁剪、屏幕映射
1.2.1、顶点着色器:
可编程,对每个顶点进行计算操作,很多效果可以在这一阶段实现,相对逐片元操作来说,计算开销小,但效果较差。
- 模型变换:将模型坐标从本地空间变换到世界空间;类似于归一化
- 视图变换:从世界空间变换到观察空间;从原点坐标改为观测点的坐标和方向
- 投影变换:从观察空间变换到裁剪空间;将视锥体或立方体转为立方体空间
1.2.2、其他
图元装配:不可变,将顶点数据转为图元数据(三角形、线段、点)
曲面细分着色器:可编程,动态添加更多的顶点,动态细分LOD
几何着色器:可编程,增减顶点及其他操作,效率低
变化回执:后缓冲在渲染时可以用前缓冲的信息作为上一帧信息
裁剪:可配置,剔除视野外的顶点
屏幕映射:不可变,将裁剪空间转为屏幕空间
1.3、光栅化阶段(有的认为包含像素处理阶段)
利用上一阶段的数据生成屏幕图像。
主要包含:三角形设置、三角形遍历、片元着色器、逐片元操作,最后生成屏幕图像。
三角形设置:不可变,计算每个三角形的边函数和顶点属性梯度
- 顶点属性梯度:用于快速计算在三角形内部的颜色纹理等属性
三角形遍历:不可变,遍历所有像素,计算是否在三角形内,输出片元序列,MSAA在这里进行计算,透视校正插值进行非线性插值,
1.3.1、像素处理阶段
片元着色器:可编程,输出每个片元的颜色深度等
逐片元操作:可配置,裁剪测试、透明测试、模板测试、深度测试以及色彩混合等
2、各种测试
2.1、深度测试
根据深度值决定是否渲染。深度缓存储存了每个像素到相机的最近的深度,计算每个物体时会与深度缓存对比,当前深度小于缓存就更新缓存,反之则当前点会被丢弃。需要在内存中维护深度缓存区。
2.1.1、Early-Z
Early-Z技术将深度测试提前到片段着色器之前,提前剔除不会显示的部分,减少片元着色器中光照等计算操作,减少OverDraw。在片元着色器修改深度值、有透明物体、alpha test等操作的情况时会自动关闭,因为透明测试在片元着色器之后,Early-Z在片元着色器之前,这时候不知道遮挡的会不会通过透明测试,可能会出现透明物体在不透明物体前,结果不透明物体渲染不出来的情况。
2.1.2、PreZ
阶段一:深度预写入通道(Depth Prepass / Z-Prepass)
目标:生成一张准确的、包含所有不透明与透明测试(Alpha Test)物体最终深度信息的深度缓冲区。
渲染对象:
必须渲染:所有不透明物体(RenderQueue = Geometry)和所有使用clip/discard进行透明测试的物体(如树叶、栅栏,RenderQueue = AlphaTest)。
不渲染:真正的半透明混合物体(RenderQueue = Transparent,使用Alpha Blend)。
渲染状态与Shader:
深度测试:开启,通常为ZTest LEqual。
深度写入:开启(ZWrite On)。
颜色写入:关闭(ColorMask 0),不输出任何颜色,只填充深度。
使用极简Shader:仅包含必要的顶点变换,对于透明测试物体,需要执行clip操作。
关键原理:此阶段唯一目的就是写入深度。虽然clip会导致本通道的Early-Z优化失效(所有片元都需经过深度测试),但这是必要的代价,目的是为下一阶段“清扫战场”。
结果:GPU的深度缓冲区中存储了场景最终可见的不透明及透明测试表面的精确深度值。
阶段二:主着色通道(Main Color Pass)
目标:在阶段一生成的深度缓冲区“保护”下,高效地执行所有复杂的像素着色计算(纹理采样、光照模型等)。
渲染对象:所有需要最终显示颜色的物体(同样包括不透明和透明测试物体)。半透明物体通常不在此流程中,按标准方式渲染。
核心渲染状态:
深度写入:关闭(ZWrite Off)。避免破坏阶段一生成的完美深度图。
深度测试:设置为 ZTest Equal(或LEqual并配合深度偏移确保精确匹配)。这是关键设置,意味着只有深度值与缓冲区中存储值完全一致的像素才会被处理。
Shader:使用完整的、包含光照和纹理的着色器,但严禁任何会修改深度或导致深度测试不确定的操作,如:
再次使用clip/discard。
在片元着色器中写入深度(SV_Depth)。
开启Alpha To Coverage(在某些硬件上会影响Early-Z)。
2.2、模板测试
根据像素的范围决定是否渲染。可用于渲染物体轮廓边框,限制渲染区域,做复杂遮罩,贴花效果等。需要模板缓冲区,与深度缓存区共享内存。
2.3、alpha测试
根据透明度决定是否被渲染,常用于不影响深度测试的全透明片段。将alpha值与参考值对比,没通过就不会被渲染。
2.4、裁剪测试
简单设置一个矩形裁剪框,限制渲染范围。灵活度低。
顺序:裁剪测试,alpha测试,模板测试,深度测试。
4、光照模型
Lambert光照:
漫反射光照颜色 = 光源颜色 * 材质漫反射颜色 * max(0, 法线向量 * 光源向量)
背面无光是0,黑色,而不是为负。记得单位化
还有半兰伯特:
漫反射光照颜色 = 光源颜色 * 材质漫反射颜色 * (max(0, 法线向量 * 光源向量) * 0.5 + 0.5)
Phong式高光:
高光反射颜色 = 光源颜色 * 材质高光反射颜色 * max(0, 观察方向向量 * 反射向量)幂
Blin-Phong高光:
高光反射颜色 = 光源颜色 * 材质高光反射颜色 * max(0, 法线向量 * 半角方向向量)幂
半角方向向量 = 入射光单位向量 + 视角单位向量
原本的冯需要计算反射向量,反射向量涉及点积和反射公式,而半角向量只有加法,高效很多,并且高光过渡更为平滑。反射光线与观察方向向量夹角>=90°时,phong式高光为0,此时高光在边界处突然消失。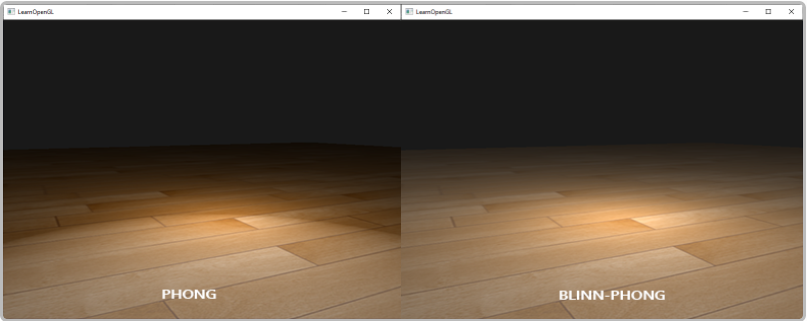
详细区别可以看这个:https://learnopengl-cn.readthedocs.io/zh/latest/05%20Advanced%20Lighting/01%20Advanced%20Lighting/
光照模型:
物体表面光照颜色 = 环境光 + 漫反射 + 高光反射
5、PBR基于物理的渲染
基础(三大)条件
-
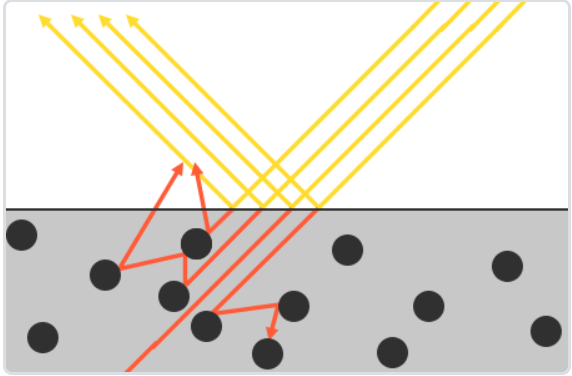
基于微平面(Microfacet)的表面模型:将物体表面分为无数随机朝向的理想镜面反射的小平面,越粗糙,漫反射越强;越光滑,高光越明显。

-
能量守恒:出射光线能量不超过入射光线的能量,并且随着粗糙度提升,有更多的反射光线被遮挡,导致能量损失
-
应用基于物理的BRDF
采用ωi和ωo作为输入的 Blinn-Phong光照模型也是BRDF。但不符合能量守恒,因此不是PBR。
菲涅尔反射:不同角度入射会有不同的反射率,比如玻璃或水面,镜面,边缘更多是反射出来的高光,而正对着的区域可以看清纹理,不同物质也有不同反射率,主要可分为金属和非金属。
线性空间:光照计算在线性空间完成。
色调映射:HDR渲染出来的亮度值会超过显示器最大亮度,需要把光照亮度映射到显示器正常显示的范围。
物质的光学特性:渲染中主要分为金属和非金属。非金属具有灰色的镜面反射,而金属是彩色镜面反射,金是金色,铁是银色,铜是黄色。
BRDF。
5.1、辐射度量学
辐射能Q,光穿过平面的光能;
辐射通量ɸ,单位时间内光穿过平面的光能;
辐射强度/光强度I,单位立体角的辐射通量;
辐射率/光亮度L,单位立体角单位面积的辐射通量,是带方向的向量;
辐照度E,单位面积的辐射通量,是辐射率的积分。
5.2、BRDF
BRDF(Bidirectional Reflectance Distribution Function),译作双向反射分布函数,是一个用来描述物体表面如何反射光线的方程。
精确定义是出射光辐射率(Radiance)的微分和入射光辐照度(Irradiance)的微分之比。
BRDF 定义了从某个特定方向入射的光线,有多少比例被反射到另一个特定的出射方向。
5.3、渲染方程
在一个点看向物体一点,看到的出射点亮度=点的自发光亮度+四面八方入射光对这个方向的反射光亮度之和
渲染方程是一个描述光能在场景中流转的方程,它基于能量守恒定律,在理论上给出了一个完美的光能求解结果。
其含义是:在某个视点看向特定的位置x,看到的出射光亮度(辐射率)Lo等于x点的自发光亮度Le(辐射率)以及该点的反射光亮度之和。
5.4、Cook-Torrance BRDF
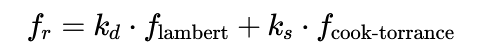

albedo是表面颜色,/π是为了标准化。
D:法线分布函数,决定高光反射的形态和集中程度,以Trowbridge-Reitz GGX为例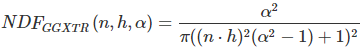
n为表面的法线,h为半角向量,a为表面的粗糙度
G:几何函数,负责计算因微几何表面的自遮挡而损失的光线比例
这里是GGX与Schlick-Beckmann近似的结合体,因此又称为Schlick-GGX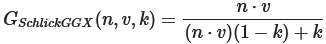
k是α的重映射(Remapping)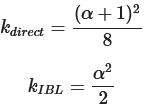
F:菲涅尔方程,决定反射与折射的能量分配,垂直观察物体时会看到正常的表面,而观察角度与法线接近垂直时会有明显的高光
菲涅尔方程是一个相当复杂的方程式,不过幸运的是菲涅尔方程可以用Fresnel-Schlick近似法求得近似解: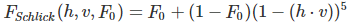
F0表示平面的基础反射率,它是利用所谓折射指数(Indices of Refraction)或者说IOR计算得出的。
金属物体直接使用这个公式并不正确,需要对照表代入计算。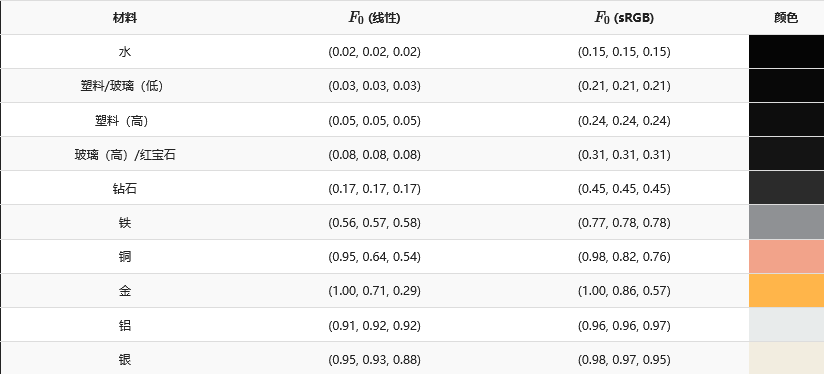
分母 4(n·l)(n·v)是一个校正因子,用于完成从微观几何局部空间到整个宏观表面的局部空间之间变换的微平面量的校正
5.5 间接光/环境光
IBL,将环境光的积分操作预处理存在立方体贴图中,也可分为漫反射和镜面反射,计算公式和直接光照类似。
漫反射预处理辐照度图,对环境贴图进行余弦加权的半球卷积积分,表示每个法线方向的入射光平均亮度,运行时根据法线即可采样出漫反射光;
预滤波环境贴图进行不同粗糙度卷积,储存到mipmap中;镜面反射要预处理BRDF-LUT,这是一个储存系数的纹理贴图,里面包含菲涅尔方程的scale和bias,直接查找表就可以得到数值,再带入方程就可以得到镜面反射的环境光照。
纹理过滤
邻近过滤直接选择最近的像素,适合像素风
线性过滤基于附近的像素计算插值得出颜色
mipmap
远处物体只要用几个像素就能描述,此时再用复杂纹理采样会浪费性能,一个像素映射到纹理上有较大的范围,计算较多。提前存储好不同分辨率的纹理,可简化计算。每次都是当前分辨率/2,占用内存为1+1/4+1/16+…,为1.3(循环),额外内存占用并不多,却能较明显加速。
好处1、cache命中率高,远处采样4096*4096会跳来跳去,命中率极低;2、远处占用内存低;3、占用带宽少;
欧拉角、旋转矩阵、四元数表示旋转角度
欧拉角表达直观,存储占用小,只有三个数。但有万向节死锁问题。计算效率低,不能插值计算。用于人机交互方便
旋转矩阵计算效率高,避免万向节死锁。储存占用大,9个参数,无法线性插值。
四元数非常不直观,四个参数,存储占用小。计算效率高,可进行球面线性插值,计算旋转中间形态,避免万向节死锁。
阴影
lightmap
适用于静态物体,可渲染出静态阴影,存储好静态物体对应的光照后就直接拿来混合就行,但是在动态场景动态光源下,阴影不会随运动变化而变化。
shadowmap
传统(前向渲染):1、从光源对整个场景计算深度图;2、屏幕空间的每个像素变换到光源空间,每个像素对比深度值,在光源空间判断是否有阴影,并在屏幕空间渲染。
屏幕空间阴影(延迟渲染):1、得到摄像机视角的深度纹理(延迟渲染自带G-Buffer);2、得到光源视角的深度纹理;3、全屏幕的后处理Pass(对所有物体渲染后,对整个屏幕后处理,因此把最终计算放到屏幕空间),把第一步的深度纹理变换到光源空间和第二步的深度纹理对比深度值,输出到一张屏幕空间阴影图;4、最终计算时采样屏幕空间阴影图的信息,判断是否有阴影,并在屏幕空间渲染。优化了对阴影的overdraw
屏幕空间阴影的优化主要是,原本一个物体被多个物体挡住,会多次完整的计算光照和阴影,overdraw。而屏幕空间阴影相当于在一张纹理图上作计算,避免了overdraw,
但如果一个物体在摄像机视野之外,它既不会出现在G-Buffer中,也无法贡献阴影。这可能导致当物体移入或移出屏幕时,阴影会突然出现或消失。
存在一些缺点:
1、深度是浮点数,本身存在精度问题,在和光线平行的地方会出现自己挡住自己的现象,存在抖动;
2、shadowmap本身也是一个像素图,若太小,会存在比较明显的锯齿,太大又会占用过多内存。
解决方法:
1、添加深度偏移,固定偏移或法线偏移(根据与光源夹角),但会引起彼得潘效应:阴影与物体存在一条缝隙,好像阴影飘在物体上,需要找准合适的偏移。
2、软阴影,软阴影不容易暴露锯齿,
3、提高阴影贴图分辨率
4、级联阴影贴图(CSM):近处用高分辨率阴影贴图,远处用低分辨率,提升整体质量。
/*
你问到了核心!让我重新仔细分析——**实际上你的理解流程有个关键错误**,这导致了困惑。
## 重新梳理:两种技术的本质区别
### 传统 Shadow Mapping(你的理解正确)
光源视角渲染场景 → Shadow Map(包含:物体A、B、C的深度)
↓
摄像机视角渲染场景时:
像素P(对应世界点X)→ 变换到光源空间 → 采样Shadow Map对比深度
**关键点**:Shadow Map是在**光源空间**生成的,包含**所有在光源视野内的物体**,不管它们在不在摄像机视野内。
### 屏幕空间阴影(你描述的流程有问题)
你描述的流程:
> "把第一步的深度纹理(摄像机深度)变换到光源空间和第二步的深度纹理对比"
**这个描述是错误的** ❌
如果真的是这样操作,确实不会丢失屏幕外阴影。但实际的屏幕空间阴影**不是这样做的**。
---
## 正确的屏幕空间阴影流程
屏幕空间阴影(如UE的Contact Shadows)真正的做法:
步骤1:G-Buffer Pass(摄像机视角)
- 得到屏幕空间的深度图、法线图、世界坐标等
步骤2:屏幕空间Ray Marching(关键!)
- 对每个屏幕像素,沿光源方向在屏幕空间做Ray Marching
- 采样G-Buffer深度,判断射线是否被遮挡
- 完全不使用光源视角的Shadow Map!
**核心区别**:
| | 传统Shadow Map | 屏幕空间阴影 |
|---|---|---|
| **遮挡查询方式** | 像素→光源空间→采样Shadow Map | 屏幕空间Ray Marching采样G-Buffer |
| **使用的数据源** | 光源视角的深度图 | 摄像机视角的G-Buffer |
| **屏幕外物体** | 只要在光源视野内就能投射阴影 | 不在G-Buffer中 = 无法投射阴影 |
---
## 为什么你会混淆?
可能你把**"延迟渲染中的Shadow Map应用"**和**"屏幕空间阴影技术"**搞混了:
### 情况A:延迟渲染 + 传统Shadow Map(不是屏幕空间阴影)
1. G-Buffer Pass(摄像机视角)
2. 光源Shadow Map Pass(光源视角)
3. 光照Pass:读取G-Buffer,像素变换到光源空间采样Shadow Map
**这个不会丢失屏幕外阴影**,因为用了Shadow Map。
### 情况B:真正的屏幕空间阴影(Contact Shadows)
1. G-Buffer Pass
2. 屏幕空间Ray Marching(只用G-Buffer,不用Shadow Map)
**这个会丢失屏幕外阴影**,因为遮挡查询完全依赖G-Buffer。
---
## 图示说明
场景:光源在上方,墙在屏幕外,角色在屏幕内
[光源]
|
↓
[墙](屏幕外)---- 投射阴影 ----> [角色](屏幕内)
| 技术 | 结果 | 原因 |
|------|------|------|
| 传统Shadow Map | ✅ 角色有阴影 | Shadow Map包含墙的深度 |
| 屏幕空间阴影 | ❌ 角色无阴影 | G-Buffer中没有墙的信息,Ray Marching找不到遮挡物 |
---
## 总结
> **你描述的流程(摄像机深度变换到光源空间采样Shadow Map)实际上是"延迟渲染+传统Shadow Map",不是真正的屏幕空间阴影技术。**
真正的屏幕空间阴影**完全抛弃Shadow Map**,只在屏幕空间做Ray Marching,所以才会丢失屏幕外信息。这也是为什么它通常只作为**短距离接触阴影(Contact Shadows)**的补充,而不是替代完整Shadow Map。
*/
光线追踪
普通光线追踪考虑镜面反射,只处理直接光照,从观察点确定的向每个像素射线,达到散射点就计算颜色,达到折射面或镜面则继续,直到最大递归深度或射出场景。
路径追踪考虑漫反射,在直接光照的基础上加入了间接光照,每个像素随机的采样几条射线,根据俄罗斯轮盘赌决定是否反射,并按材质概率随机反射,直到逃出场景、射中光源或轮盘决定不反射,每条成功路径都对像素计算贡献。
俄罗斯轮盘赌:为了控制路径长度,避免无限递归,并且整体统计符合期望;
随机发射多条光线,按照蒙特卡洛积分近似求解颜色。
空间加速
1、AABB包围盒
轴对齐包围盒,计算仅用轴向量,计算快;
2、均匀格子,效率较低
3、八叉树,有些还在用
4、kd树,无法保证一个物体在一个格子,很难计算三角形和格子相交情况,因此不好用
5、层次包围盒Bounaing Volume Hierarchy(BVH)好用
一个物体只出现在一个包围盒,省去三角形和包围盒求交。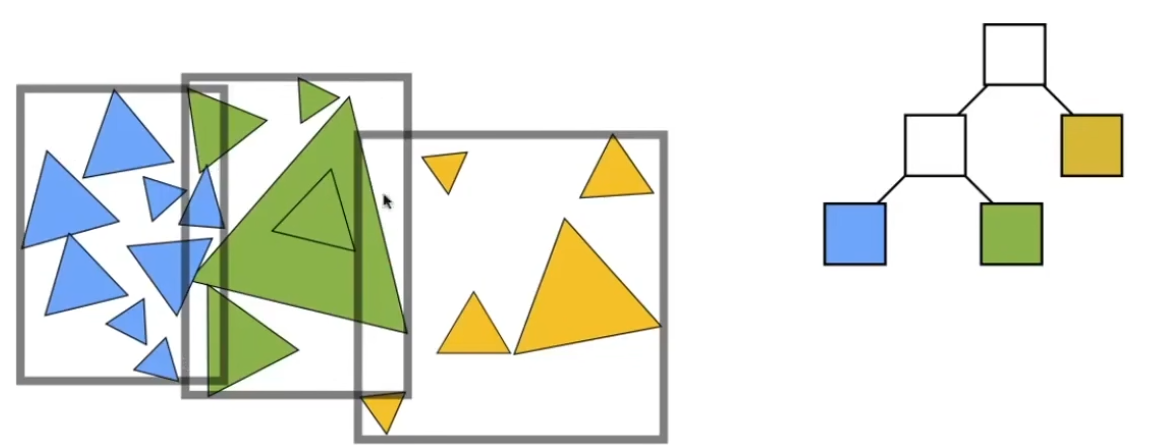
抗锯齿
SSAA简单,以4xSSAA为例,原本800x600,变为1600x1200,所有计算都乘4倍。
SSAA在光栅化阶段对每个像素进行多重采样,每个子样本独立执行完整的片元着色器计算,最后在输出到帧缓冲区前进行一次下采样(解析/滤波)。
MSAA只在光栅化阶段在一个像素采样4个点,但是着色阶段片元着色器一个像素依然只计算一次,而着色阶段是比较耗时的,因此MSAA比SSAA好很多。
MSAA在光栅化阶段,需要对所有子样本进行几何计算,计算有没有被遮挡,然后延迟渲染有个gbuffer,它在gbuffer里面存储了整个像素中心的几何信息,但它这样就丢失了对子样本的几何信息的计算。
FXAA计算一个边缘图,在边缘图上进行范围加权平均。
前向渲染和延迟渲染
前向渲染(对场景复杂度和光源数敏感)
类似暴力的对每个物体的片元每个光源遍历计算光照,O(所有物体产生的总片元数*n)的复杂度,并且会计算被遮挡的光源,允许为每个物体使用高度定制化的shader,对于很多shader的渲染画面表现较好,但是多光源时效率低,可以通过先计算深度的方式先剔除不需要的光照,还有光源重要性分级,等级高的逐像素计算,次级逐顶点,其他按球谐函数计算。
延迟渲染
分两步,先计算所有顶点信息并存为一个二维的Gbuffer,Gbuffer储存了法线,颜色,世界坐标等信息,第二步对Gbuffer的每个片元计算光照。这样做的复杂度是O(屏幕像素数*n),但要求存储较多信息,手机带宽少,无法使用,且需要shader类型少,多种shader时在光照阶段根据ID分支调用不同的shader,这会增加复杂性和性能开销,并且半透明物体需要延迟渲染后再前向渲染。
双缓冲
单缓冲的绘图操作直接在显示缓冲区进行,屏幕同步读取;因绘制未完成时屏幕就开始读取,导致一帧内显示新旧不同内容。
双缓冲分为前台缓冲区 和 后台缓冲区,所有绘图操作先在后台缓冲区完成,再一次性切换到前台,切换操作非常快(可能是交换指针地址)。
帧率太高,渲染的慢的时候仍有可能出现撕裂,用垂直同步强制绘制完一帧再刷新可避免画面撕裂,但会有画面延迟。
为什么有了VAO和VBO还要有EBO?
在没有EBO的情况下,如果要绘制一个矩形,需要将6个顶点的数据全部传入GPU,即使有两个顶点是重复的,这会导致内存浪费和传输效率降低。
EBO通过 “索引绘制” 解决了这个问题:
- 在顶点数组中定义不重复的顶点(例如,矩形的4个角)。
- 在索引数组中定义绘制的顺序,即指明哪三个顶点构成一个三角形。
半透明物体和不透明物体渲染顺序
先渲染不透明物体,开启深度测试和深度写入,再渲染半透明物体,开启深度测试,关闭深度写入,开启混合。
如何优化shader计算量
提前剔除:early-z,z-prepass
计算频率优化:将精细要求低的放到顶点着色器计算,
精度控制:使用数据类型优先级fixed > half > float > double,非必要不用高精度
运算优化:优化运算表达式,MAD,多个标量间相同操作合并为一组向量操作(SIMD)等
预处理与烘焙:提前烘焙,将一些计算储存在纹理贴图中
合并纹理:将多张小纹理放到一个图的不同通道
性能优化——减少分支语句
我的理解:原本GPU对于所有的区域都有一个线程负责执行计算,GPU基本调度单位称为wrap或wavefront。一个wrap的计算因为处理逻辑相同,只有数据不同,所以可以并行执行。而有了分支语句会破坏这个并行计算,wrap会让活跃线程进入a语句执行,其他线程通过执行掩码 控制不让执行,但仍然占用指令带宽,再让部分线程进入b语句执行,其他线程不动,以此类推,原本可能是一次32个线程并行计算,8个分支后可能变为8次分别有4个线程先后串行计算。
Warp 是物理单位,不会拆分:你的理解中“分割出两个wrap”或“变为8次分别有40个线程”是一种逻辑上的比喻。实际上,物理上的 Warp (32线程) 并不会被拆分成更小的调度单位。它始终作为一个整体被调度器处理,只是内部的线程在执行不同分支时,会通过执行掩码 (Execution Mask) 来控制哪些线程是活跃的。
性能损失不仅是“串行”:性能损失不仅来自于串行执行,还来自于GPU实际上执行了所有分支的所有代码。对于那些被遮蔽的线程,它们可能仍然占用了指令发射带宽或产生了开销(尽管不执行有效操作)。
并非所有分支都如此糟糕:如果你的分支条件是一个Uniform变量(在一个Draw Call或Warp内所有线程的值都相同),或者编译器能在编译时确定分支路径(如使用宏#ifdef),那么不会发生Warp Divergence,因为所有线程都会做出相同的选择,这时性能开销极小甚至为零。
线性空间和srgb空间是怎么映射的
线性空间是为了让计算机进行正确的物理计算,而sRGB空间是为了让人眼看到舒适的图像。
储存的是sRGB空间的值,计算时先去除gamma矫正,在线性空间中完成计算,再用gamma矫正转到人类适应的sRGB空间。
gamma矫正,计算得出的线性空间的值计算0.45次幂,转为gamma空间。
因为人类对暗部特征信息比较敏感。
为什么延迟渲染对MSAA支持不好
MSAA在光栅化前,顶点着色器后,需要几何信息,而延迟渲染将信息输出到G-buffer纹理上,是二维空间,丢失了几何信息。
色调映射,HDR与LDR的区别
正常设备是LDR,亮度范围是[0, 1],HDR技术允许亮度超过1,渲染时通过色调映射转回LDR,可以保证在明亮和黑暗区域无细节损失。
FrameBuffer
一个帧缓存是这样的,两个帧缓存组成双缓冲区
变换反馈
OpenGL3.0的新特性,主要是存储上一帧信息,通常来计算粒子,直接取上一帧数据提高效率
cpu的命令缓冲区保证渲染顺序正确,然后通过双缓冲,前缓冲用于显示当前画面,同时后缓冲在渲染时可以用前缓冲的信息作为上一帧信息
双缓冲:渲染管线通常使用前缓冲区(用于当前显示)和后缓冲区(用于下一帧绘制)来避免画面撕裂。当一帧绘制完成后,通过“交换”操作呈现。这个过程本身就是一种最基础的“回执”,确保我们总是基于一个完整的、最新的画面状态进行下一步。
命令缓冲区:CPU和GPU是并行工作的。CPU将渲染命令(如DrawCall)放入一个命令缓冲区,GPU再从其中读取并执行。这个缓冲区保证了命令的有序提交和执行,是协调CPU和GPU工作的“回执”系统。
齐次坐标
用 N+1 维的向量来表示一个 N 维空间中的点或向量,
引入这个额外的维度 w(通常称为齐次坐标的“重量”)使得齐次坐标具有尺度不变性。
在笛卡尔坐标系下引入一个维度使得齐次坐标具有尺度不变性,原本旋转缩放用矩阵乘法,而平移变换用加法,引入齐次坐标后可以把平移放在第四维,使得这几种变换都可以用矩阵乘法表示。
并且可以用w分量来作投影除法将裁剪空间转为NDC空间。
若没用齐次坐标,则只有旋转和缩放是线性变换,平移不是线性变换。
仿射变换
线性变换+平移变换
3、MVP变换矩阵
这篇讲的不错:https://blog.csdn.net/zsy721201/article/details/140572065
法线变换
法线是方向向量,不关心位置,只关心方向。
如果有不等比缩放,那么原本垂直的法线会变得不垂直。
法线变换要用逆转置矩阵,
逆转置矩阵的作用,就是为了抵消非均匀缩放对垂直关系的破坏,强行把法线“掰”回垂直的位置。
模型变换model transform
顶点变换的第一步:将顶点坐标从模型空间变换到世界空间,先进行缩放、旋转后,再进行平移。
观察变换view transform
步骤推导:
已有条件:摄像机坐标 P:(x,y,z),向上方向up。
把摄像机作为原点,因此最终摄像机坐标(x,y,z)->(0,0,0)。那么原本世界空间所有点的平移(-x,-y,-z)。设平移矩阵为T。
最终的变换矩阵V=RT,先平移,再旋转。
摄像机在世界空间的三个方向[up,right,forward],forward=P-O,right=cross(forward,up),设[up,right,forward]为R’,是从观察空间到世界空间的旋转变换,而它的逆矩阵是世界空间到观察空间的旋转变换,并且由于是正交矩阵,因此转置即可求出逆矩阵,(R’)T=R,V=RT=(R’)TT。
详细整理:
第二步,将顶点坐标从世界空间转到观察空间(把摄像机作为原点,变换结束后的坐标是相对于摄像机的三维坐标)
这里是从一个世界坐标系变为一个局部坐标系。
如果摄像机在世界空间中的位置是 e=(eyex,eyey,eyez),那么平移矩阵 T 就是将整个世界平移 −e,使得摄像机原点与世界原点重合,设平移矩阵为T(transform)。
摄像机世界坐标:(x,y,z),方向矩阵[up,right,forward]。
通过叉积计算得到了相机局部坐标系的三个单位基向量。将它们作为列向量组合成一个矩阵[up,right,forward],设为R’(Rotation’)。这个矩阵R’本身表示的是从相机空间到世界空间的旋转变换。然而,观察变换的目的恰恰相反:我们需要将顶点从世界空间变换到相机空间。因此,我们需要的是矩阵R’的逆变换。M=RT。
旋转矩阵不好求,但逆矩阵已经有了(R’),逆矩阵转置一下就等于旋转矩阵,最终变换矩阵:M=RT=(R-1)TT=(R’)TT。
因为OpenGL使用右手坐标系,unity的观察空间也跟着用右手坐标系,但模型空间和世界空间还是左手坐标系。
投影变换projection transform
投影变换将顶点坐标从观察空间转到裁剪空间,再通过透视除法除以w分量标准化到NDC(归一化设备坐标),后续的屏幕映射用视口变换再转到屏幕空间。
正交投影的w分量等于1,因此数值和NDC一样。
而透视投影w分量为当前顶点的深度z,xy除以z后会有近大远小的区别,越远,z越大,xy就越小;
z_ndc = (A * z_view + B) / (-z_view) = -A - (B / z_view),存储在深度缓存中的ndc的深度值是非线性的,反比例的,越近,精度越高。
裁剪空间是一个立方体空间,最终图像会投影到近裁剪面。
透视投影
透视投影可以看作先把梯形挤压为长方形,再进行正交投影,这里的挤压只针对x,y。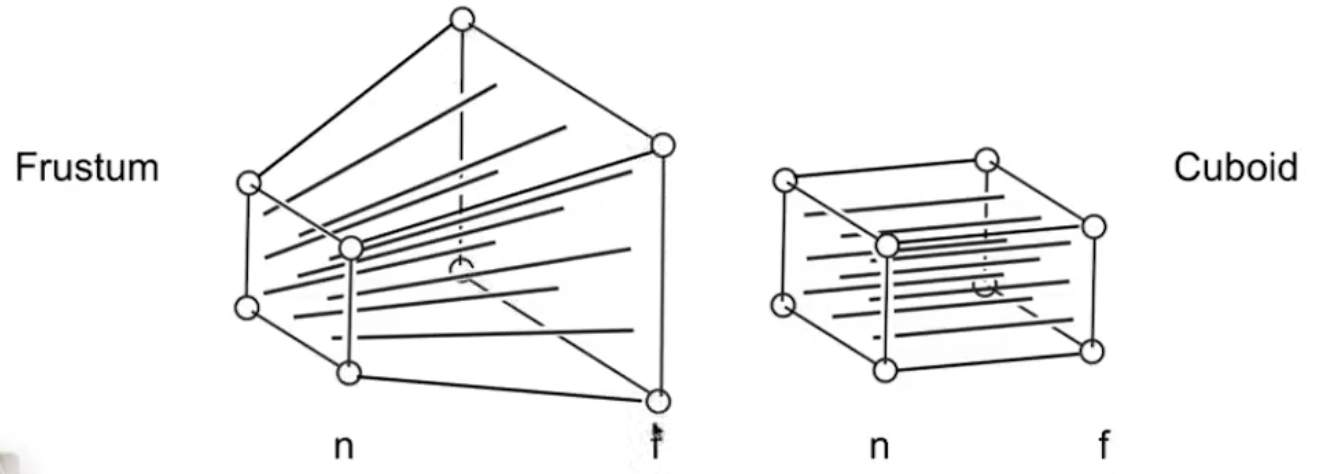
某个点(x,y,z,1)挤压后变为(nx/z,ny/z,unknown,1),乘z后变为(nx,ny,unknown,z)
带入下面的矩阵变换等式
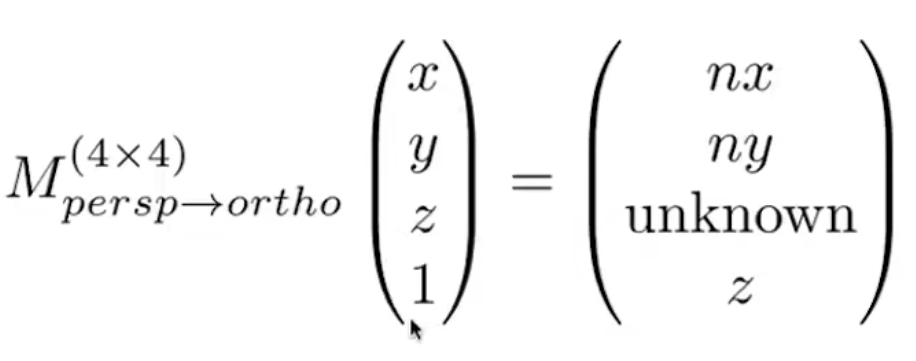
可得矩阵为: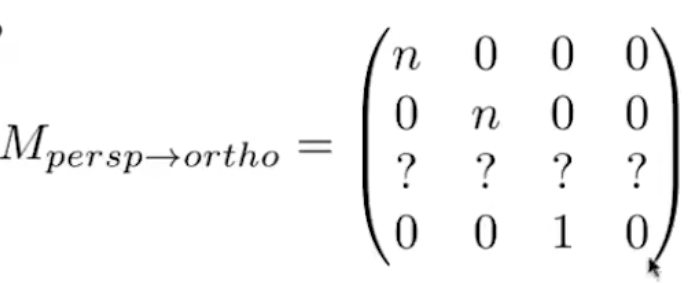
带入两个特殊点,1、近平面z=n,挤压后不变;并且xy是变量,矩阵应该是和xy无关的,因此前两个空为0。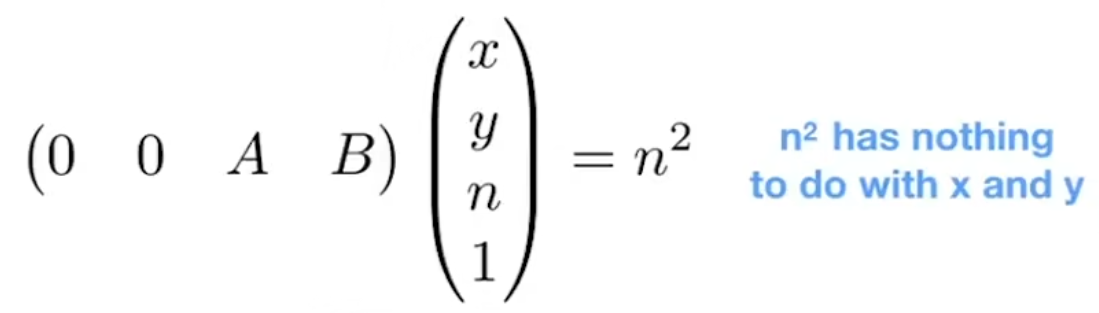
2、远平面的中心点z=f(挤压后完全不变);
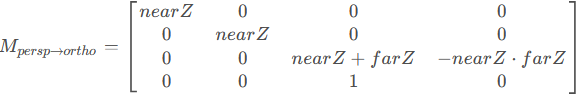
(代入(n+f)/2的点会发现非nf平面的点深度会变,会靠向远平面,这是非线性变换)
再乘以正交投影矩阵得到透视投影
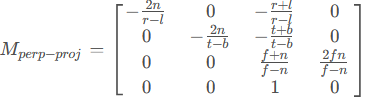
正交投影
裁剪空间是长方体,缩放至x,y,z∈[−1,1],长方体参数:Near,Far,高Size,宽高比Aspect
1、平移到观察空间原点中心
2、缩放到长宽高都为1-(-1)=2的空间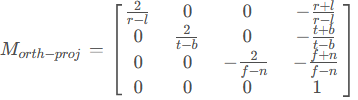

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)