搭建和训练基于线性回归算法预测房价的机器学习模型
# 导入pandas库,用于数据处理和分析
import pandas as pd
# 导入numpy库,用于数值计算
import numpy as np
# 从matplotlib库中导入pyplot模块,用于数据可视化
from matplotlib import pyplot as plt
# 读取CSV文件到DataFrame中,注意文件名与生成的数据一致
data = pd.read_csv('house_data.csv')
# 打印数据集的前10条记录,用于初步了解数据结构
print("数据集中的前10条记录:")
print(data.head(10))
print("") # 打印空行,使输出更清晰
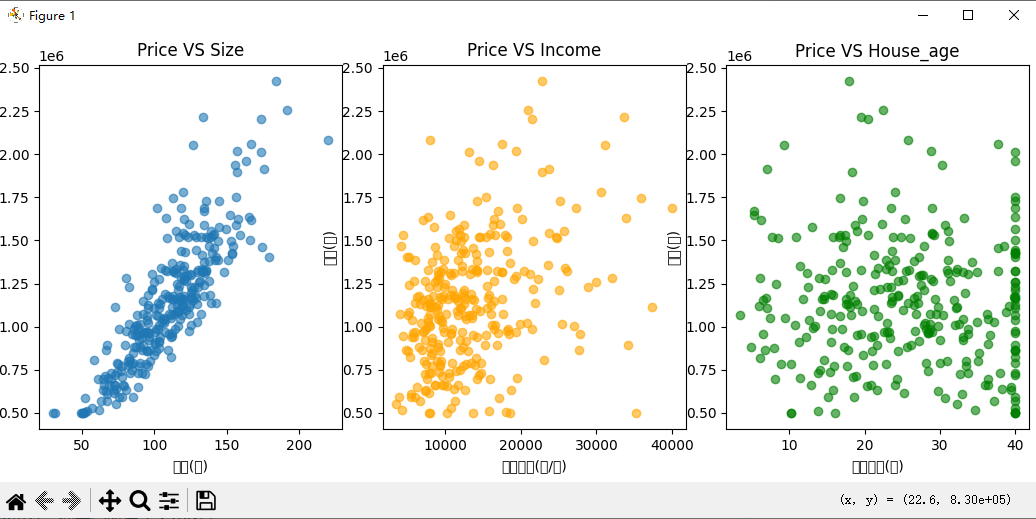
# 设置画布大小为20x5英寸,便于同时展示多个图表
plt.figure(figsize=(20, 5))
# 创建第一个子图(1行3列中的第1个)
plt.subplot(131)
# 绘制面积与价格的散点图,alpha设置透明度为0.6(避免点重叠严重)
plt.scatter(data['面积(㎡)'], data['价格(元)'], alpha=0.6)
# 设置x轴标签
plt.xlabel('面积(㎡)')
# 设置y轴标签
plt.ylabel('价格(元)')
# 设置图表标题
plt.title('Price VS Size')
# 创建第二个子图(1行3列中的第2个)
plt.subplot(132)
# 绘制人均收入与价格的散点图,设置颜色为橙色
plt.scatter(data['人均收入(元/月)'], data['价格(元)'], alpha=0.6, color='orange')
# 设置x轴标签
plt.xlabel('人均收入(元/月)')
# 设置y轴标签
plt.ylabel('价格(元)')
# 设置图表标题
plt.title('Price VS Income')
# 创建第三个子图(1行3列中的第3个)
plt.subplot(133)
# 绘制平均房龄与价格的散点图,设置颜色为绿色
plt.scatter(data['平均房龄(年)'], data['价格(元)'], alpha=0.6, color='green')
# 设置x轴标签
plt.xlabel('平均房龄(年)')
# 设置y轴标签
plt.ylabel('价格(元)')
# 设置图表标题
plt.title('Price VS House_age')
# 自动调整子图布局,避免标签重叠
plt.tight_layout()
# 显示绘制的图表
plt.show()
# 数据预处理:从数据中移除价格列,作为模型的特征变量X
X = data.drop(['价格(元)'], axis=1) # axis=1表示按列操作
# 提取价格列作为模型的目标变量y
y = data['价格(元)']
# 将特征数据转换为numpy数组格式,便于后续建模
X = np.array(X)
# 将目标变量转换为numpy数组格式
y = np.array(y)
# 打印特征数据和目标变量的形状,确认数据维度是否正确
print("特征数据形状:", X.shape) # 应输出(300, 3),表示300条记录,3个特征
print("目标变量形状:", y.shape) # 应输出(300,),表示300个目标值
# 导入数据集分割工具
from sklearn.model_selection import train_test_split
# 导入线性回归模型
from sklearn.linear_model import LinearRegression
# 导入模型评估指标(均方误差和R²评分)
from sklearn.metrics import mean_squared_error, r2_score
# 将数据集分割为训练集(80%)和测试集(20%)
# random_state=42确保分割结果可复现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化线性回归模型
model = LinearRegression()
# 使用训练集数据训练模型
model.fit(X_train, y_train)
# 使用训练好的模型对测试集进行预测
y_pred = model.predict(X_test)
# 打印模型评估结果
print("\n模型评估:")
# R²评分:越接近1表示模型拟合效果越好
print(f"R² 分数: {r2_score(y_test, y_pred):.4f}")
# 均方误差:衡量预测值与实际值的平均平方差
print(f"均方误差: {mean_squared_error(y_test, y_pred):.2f}")
# 均方根误差:均方误差的平方根,单位与目标变量一致
print(f"均方根误差: {np.sqrt(mean_squared_error(y_test, y_pred)):.2f}")
# 打印回归系数,分析各特征对房价的影响程度
print("\n回归系数:")
# 遍历每个特征,输出其对应的系数
for i, col in enumerate(data.columns[:-1]):
print(f"{col}: {model.coef_[i]:.4f}")
# 输出回归方程的截距项
print(f"截距: {model.intercept_:.4f}")

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)