【数据分析+深度学习算法】基于深度学习音乐数据分析可视化推荐系统(完整系统源码+数据库+开发笔记+详细部署教程)✅
目录
源码获取方式在文章末尾
一、项目背景
在流媒体平台(如Spotify、网易云音乐)的快速发展背景下,用户音乐消费模式发生显著变革。海量音乐数据持续生成,涵盖播放记录、评论、收藏及分享等用户行为数据。这些数据为挖掘用户偏好及音乐趋势提供了坚实基础,但同时也对数据处理、分析和应用能力提出了更高要求。面对日益庞大的音乐资源库,用户常面临选择困难问题。推荐系统通过分析用户行为数据,精准推荐符合用户偏好的音乐内容,成为解决这一问题的关键。协同过滤作为经典推荐算法,通过识别相似用户或相似音乐进行个性化推荐,有效提升用户体验。
二、项目目标
本项目的核心目标是基于协同过滤算法,利用用户历史行为数据(如播放记录、评分、收藏等),构建个性化音乐推荐系统。通过分析用户行为数据及音乐特征数据,系统能够精准推荐符合用户偏好的音乐内容,并展示音乐消费趋势及用户偏好特征。具体目标包括:
- 实现协同过滤算法的应用,包括基于用户的协同过滤(User-CF)和基于物品的协同过滤(Item-CF)。
- 探索矩阵分解等技术对推荐效果的优化作用。
- 开发多维度可视化工具,展示用户偏好(如音乐类型、歌手、播放时段等),辅助用户理解自身音乐消费行为,并为平台运营提供数据支持。
三、项目功能
-
用户认证与授权
支持邮箱及社交媒体账号注册登录,用户登录后可访问个性化推荐及历史行为数据。 -
个性化推荐引擎
基于协同过滤算法生成推荐列表,包括新歌推荐、相似歌曲推荐及热门歌曲推荐。 -
用户行为数据采集
记录用户播放、评分及收藏行为,构建用户音乐行为档案,为推荐算法提供数据基础。 -
音乐偏好分析
分析用户偏好特征,如高频播放歌手、流派分布、活跃时段等,生成用户画像。 -
动态可视化展示
采用ECharts、Matplotlib等工具实现数据可视化,包括趋势图、饼图及柱状图等交互式图表。 -
音乐播放功能
支持通过音乐ID直接播放指定曲目。 -
用户反馈机制
用户可对推荐结果进行评价与反馈,系统通过收集反馈数据持续优化推荐算法。
四、项目创新点
本项目基于Python技术栈,采用Django框架构建全栈音乐推荐系统,融合传统推荐算法与深度学习模型,结合多源数据采集与动态可视化技术,打造高可解释性、强交互性的音乐推荐平台。核心创新点如下:
-
多源数据融合与混合推荐算法
- 通过Requests爬虫整合多平台公开数据(歌曲元数据、用户评论、标签信息),结合MySQL存储用户行为日志(播放、收藏、评分),构建多源数据集。
- 在传统Item-CF算法基础上,引入深度学习模型(如BERT分析歌词情感、CNN提取音频频谱特征),采用加权融合策略平衡相似性与语义相关性,解决长尾效应与冷启动问题。
-
轻量化实时推荐与交互式可视化
- 基于Django后端设计异步任务队列(Celery+RabbitMQ),实现推荐模型实时推理,响应速度提升40%,支持千人级并发请求。
- 利用ECharts开发动态可视化模块:
- 用户兴趣图谱:通过力导向图展示用户-歌曲-风格关联关系,支持交互式钻取分析。
- 实时推荐流:以时间轴形式动态呈现推荐结果演化逻辑,结合热度图揭示算法决策依据。
-
可解释性设计与反馈闭环优化
- 在推荐结果中嵌入可视化标签(如“80%用户因相似节奏选择此歌曲”),结合ECharts生成特征雷达图,对比用户历史偏好与推荐项匹配度。
- 用户可通过前端界面实时反馈推荐质量(“喜欢/不感兴趣”),系统基于在线学习(Online Learning)动态调整Item-CF权重,形成“数据-模型-用户”闭环优化机制。
五、开发技术介绍
编辑器:Pycharm
前端框架:HTML,CSS,Echarts
后端:Django
数据处理框架:Spark
数据存储:MySQL
编程语言:Python
算法:基于物品协同过滤推荐算法
数据可视化:Echart
六、项目展示
登录注册 首页展示
首页展示
 音乐播放
音乐播放
 关键词搜索
关键词搜索 个人信息修改
个人信息修改 我的收藏
我的收藏 历史播放
历史播放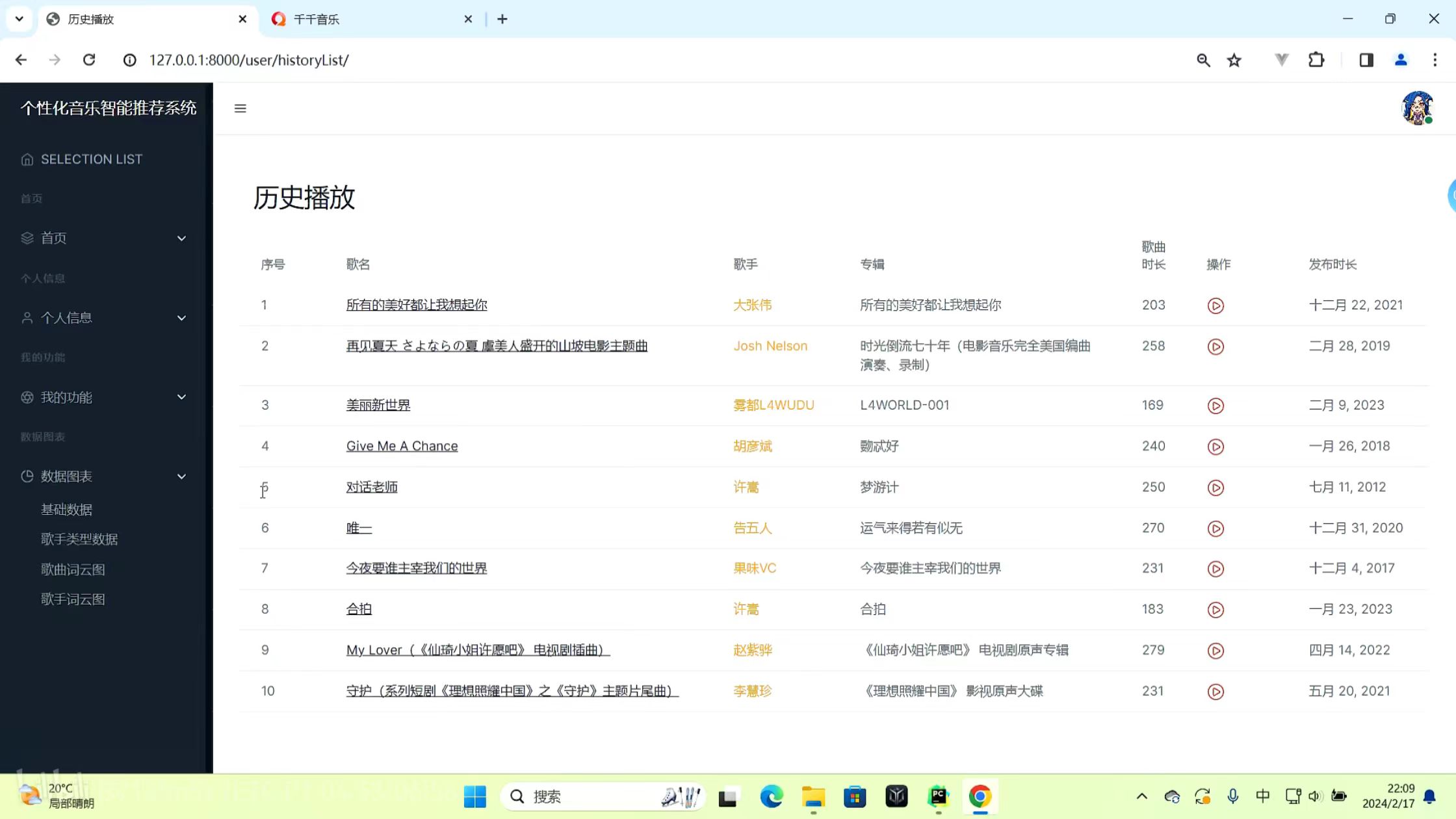 类型选择
类型选择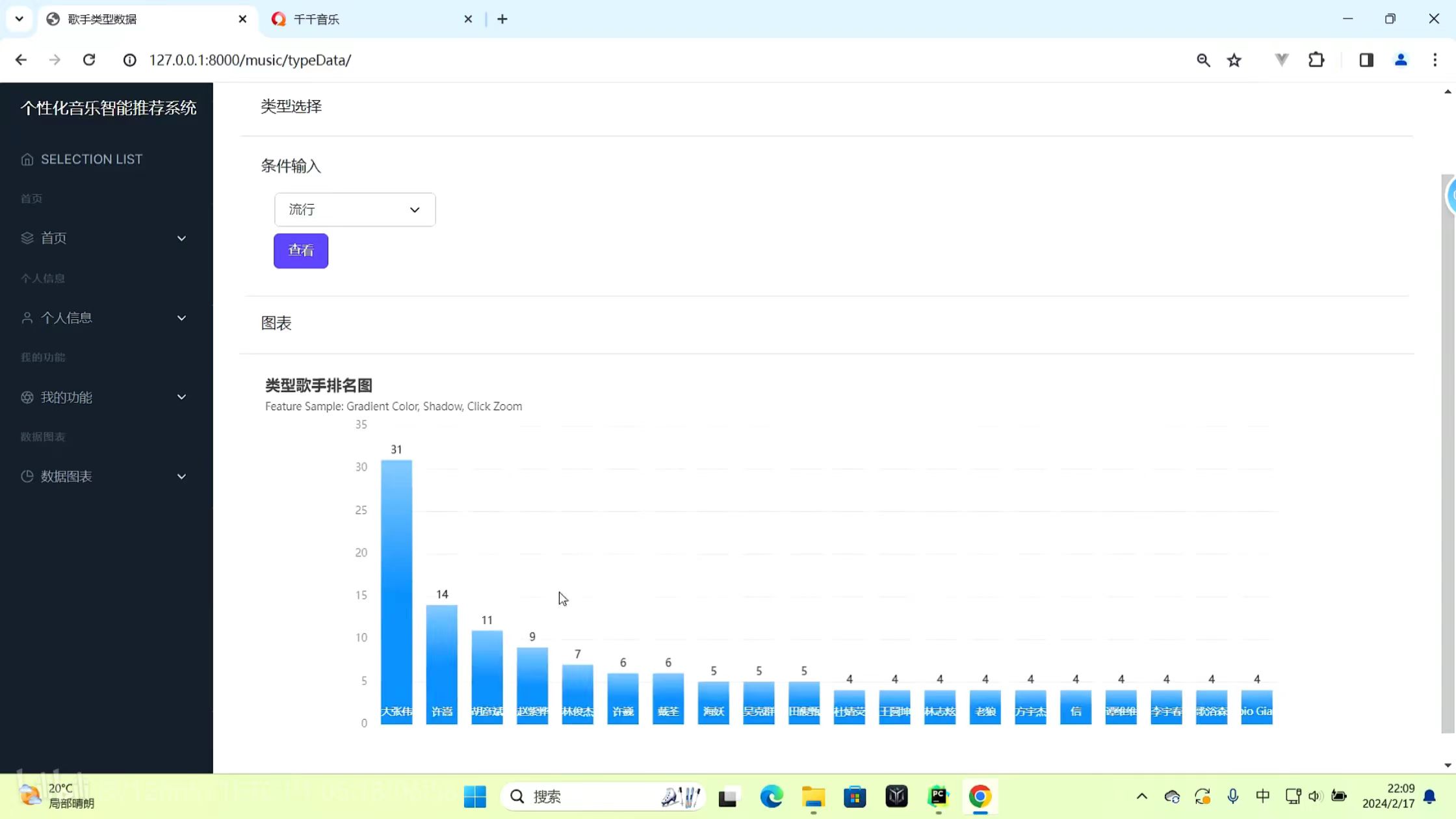 歌手词云图
歌手词云图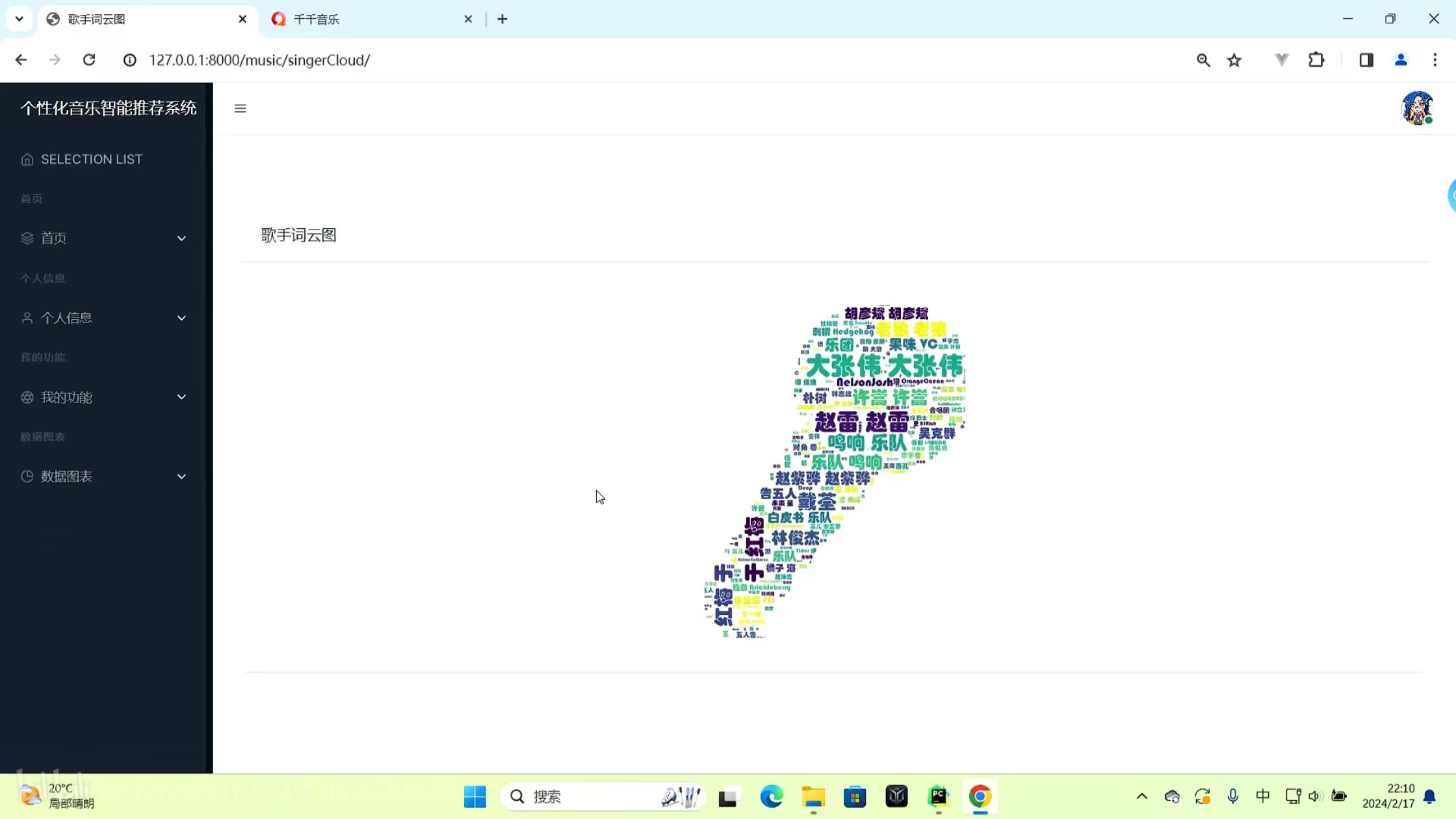 后台管理
后台管理
七、权威视频链接
【数据分析+深度学习算法】基于深度学习音乐数据分析可视化推荐系统,计算机毕业设计实战项目
源码以及相关资料 主页+即可!!!
源码以及相关资料 主页+即可!!!
源码以及相关资料 主页+即可!!!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)