《白话——机器学习中的数学》
-
与其逼着自己在两天之内读完这本书,然后再去复习,反之我为什么不直接,从这本书的整体框架入手,然后带着问题去读书,一边读一边整理笔记(自己认为重要的东西)
-
不妨大胆一点:知道自己要的是什么,过程中可以去打破规则。
书籍链接—微信读书![]() https://weread.qq.com/web/reader/dfb329b071f284b1dfbe501k67c32d7022f67c6a1e7ce82
https://weread.qq.com/web/reader/dfb329b071f284b1dfbe501k67c32d7022f67c6a1e7ce82
第一章:开始二人之旅
1.2 机器学习的重要性
机器学习能做的事情变多了得益于:
-
具备了能够收集大量数据的环境
-
具备了能够处理大量数据的环境
1.3 机器学习的算法
-
回归:
回归就是在处理连续数据如时间序列数据时使用的技术 -
分类:
鉴别垃圾邮件就可以归类为分类问题。像这种只有两个类别的问题称为二分类,有三个及以上的问题称为多分类,比如数字的识别就属于多分类问题。 -
聚类:
聚类与分类相似,却又有些不同。聚类考虑的问题是:假设在有100名学生的学校进行摸底考试,然后根据考试成绩把100名学生分为几组,根据分组结果,我们能得出某组偏重理科、某组偏重文科这样有意义的结论
注意:聚类和分类区别在于准备的数据里是否包含了标签信息
| 有标签 | 有监督学习 | 回归+分类 |
| 无标签 | 无监督学习 | 聚类 |
1.4数字与编程
第二章:学习回归基于广告费预测点击量
2.1设置问题
2.2定义模型
-
注意
在统计学领域,人们常常使用θ来表示未知数和推测值。采用θ加数字下标的形式,是为了防止当未知数增加时,表达式中大量出现a、b、c、d…这样的符号。这样不但不易理解,还可能会出现符号本身不够用的情况
2.3 最小二乘法
2.3.1 最优化问题
-
”西格玛“是求和符号,我们对每个训练数据的误差取平方之后,全部相加,然后乘以二分之一。这么做是为了找到使E(θ)的值最小的θ。这样的问题称为最优化问题。
-
(公式里面的二分之一在后面对复合函数的偏微分那里会消掉,这也是×1/2的理由,其实只要不改变函数的单调性乘以什么都可以)
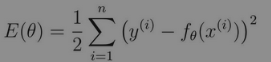
2.3.2 为什么要计算误差的平方?
-
因为如果只是简单地计算差值,我们就得考虑误差为负值的情况。但是我们一般不用绝对值,而用平方。因为之后要对目标函数进行微分,比起绝对值,平方的微分更加简单
2.3.3 最小二乘法
-
用处:用于确定数据之间关系的模型参数,通常是在存在误差或者噪声的情况下,寻找数据点到模型曲线的最佳拟合。
-
定义:这种方法通过最小化误差平方和来实现,即找到模型参数的值,使得所有数据点到模型预测值之间的距离(通常是欧几里得距离)的平方和最小
(自己的话描述)
2.3.4 最速下降法
-
微分是计算变化的快慢程度时使用的方法
-
所谓的最速下降法就是对所有的训练数据都重复进行计算
-
最速下降法的原理就是。因为导数的正负决定了函数的增减性,只要向与导数的符号相反的方向移动x,g(x)就会自然而然地沿着最小值的方向前进了
-
因为上面提到的是要将误差逐渐减小——最小二乘法——为了进一步加速减小误差——最速下降法
-
缺点:计算量大,计算时间长——引出 :随机梯度下降法
注意:
-
η是称为学习率的正的常数,读作“伊塔”。
-
根据学习率的大小,到达最小值的更新次数也会发生变化。
-
换种说法就是收敛速度会不同。有时候甚至会出现完全无法收敛,一直发散的情况。
-
η决定了模型在训练过程中更新权重参数的速度与方向如果学习率设置得过大,那么在每一步迭代中,模型参数可能会跨过最优解,导致震荡或者发散,这被称为“振荡现象”或“不稳定性”。(说白了就是“太快了,跑过了”)
-
相反,如果学习率设置得太小,模型收敛到最优解的速度将会非常慢,而且可能会陷入局部极小点,而不是全局最优解(“太慢了,追不上”)
2.4 多项式会回归
就是将一次函数变成二次函数
2.5多重回归(多个变量的回归)
-
其实就是多个变量的回归
-
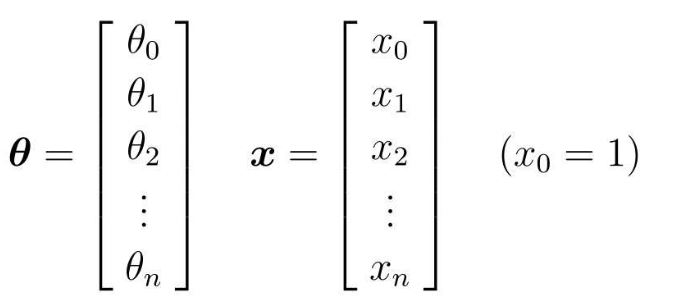
变量增加:之前我们只考虑广告费一个变量和点击量的关系,现在我们设广告费为x1、广告栏的宽为x2、广告栏的高为x3,然后再推导至n个变量(下面我们用线性代数的知识来表示)
![]()
![]()
![]()
2.6 随机梯度下降法
-
最速下降法更新1次参数的时间,随机梯度下降法可以更新n次。
-
此外,随机梯度下降法由于训练数据是随机选择的,更新参数时使用的又是选择数据时的梯度,所以不容易陷入目标函数的局部最优解
-
小批量梯度下降法:
假设训练数据有100个,那么在m=10时,创建一个有10个随机数的索引的集合,例如K={61, 53, 59, 16, 30, 21, 85, 31, 51, 10},然后重复更新参数。这种做法被称为小批量(mini-batch)梯度下降法。
这是介于最速下降法和随机梯度下降法之间的方法。
第三章 学习分类基于图像的大小进行分类
3.1 设置问题
高和宽是数据,形状是标签
3.2 内积
(比概念本身重要的是,在机器学习中怎么去理解它)
这里没想好怎么表述
3.3 感知机
-
感知机是接受多个输入后将每个值与各自的权重相乘,最后输出总和的模型
-
只能处理线性可分的问题
-
多层感知机=神经网络
3.4 线性可分
3.5 逻辑回归
3.5.1 sigmoid函数(用作概率)
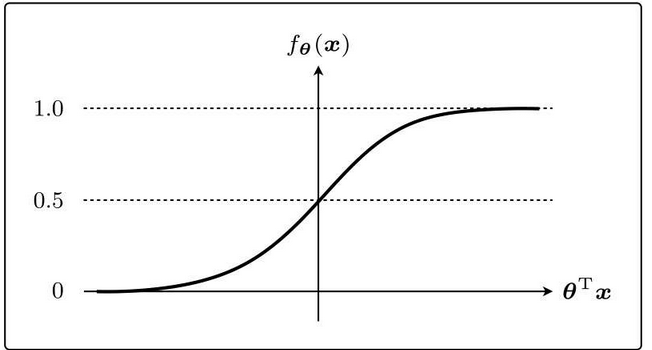
3.5.2 决策边界
用于数据分类的直线
3.6 似然函数
-
它的意思是最近似的。我们可以认为似然函数L(θ)中,使其值最大的参数θ能够最近似地说明训练数据。
-
似然函数 L ( θ ∣ X )是在给定参数 θ 下,观测数据 X 出现的概率。它是统计推断中的一个核心概念,用于衡量在特定参数假设下,观测数据的合理性。
3.7 对数似然函数
3.8 线性不可分
第四章 评估已建立的模型
4.1 模型评估
4.2 交叉验证
-
把全部训练数据分为测试数据和训练数据的做法称为交叉验证
-
交叉验证的方法中,尤为有名的是K折交叉验证,掌握这种方法很有好处。
1. 把全部训练数据分为K份
2. 将K-1份数据用作训练数据,剩下的1份用作测试数据
3. 每次更换训练数据和测试数据,重复进行K次交叉验证
4. 最后计算K个精度的平均值,把它作为最终的精度
4.2.1 回归问题的验证
-
把获取的全部训练数据分成两份:一份用于测试,一份用于训练。
-
然后用前者来评估模型。(这里二者的划分尽量随机一些)
-
对于回归的情况,只要在训练好的模型上计算测试数据的误差的平方,再取其平均值就可以了
4.2.2 分类问题的验证
-
对于分类有别的指标。由于回归是连续值,所以可以从误差入手,但是在分类中我们必须要考虑分类的类别是否正确。
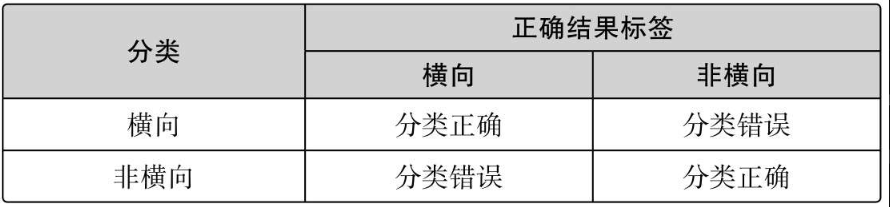
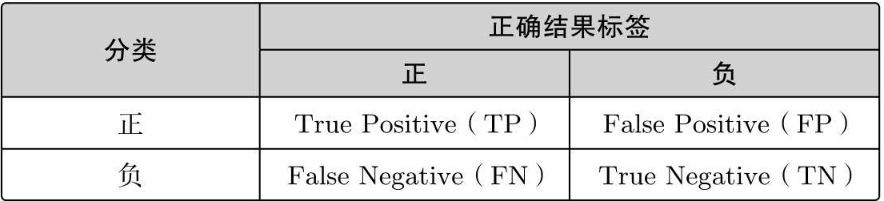
4.2.3 精度,精确率和召回率
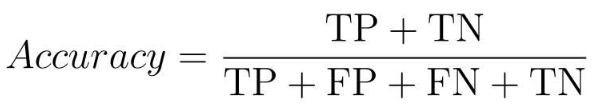
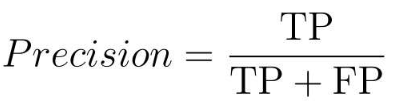
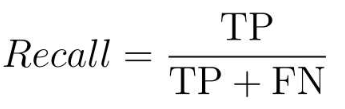
4.2.4 F1值
-
F1值在数学上是精确率和召回率的调和平均值
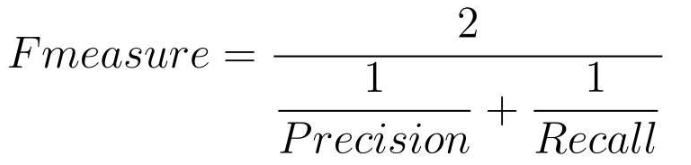
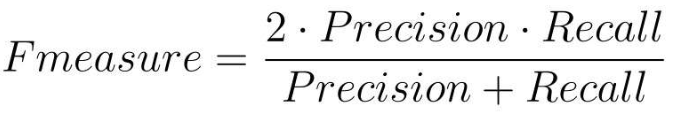
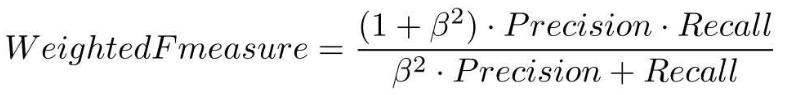
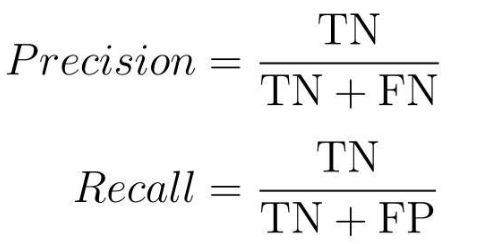
4.3 正则化
4.3.1 过拟合
有几种方法可以避免过拟合。
-
增加全部训练数据的数量
-
使用简单的模型
-
正则化
4.3.2 正则化的方法
-
其实就是在函数后面添加上一项,进而对函数的范围进行了限制
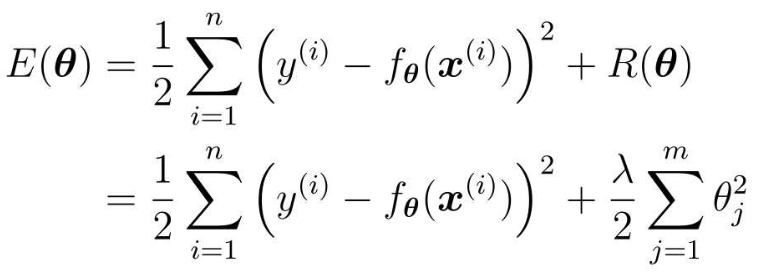
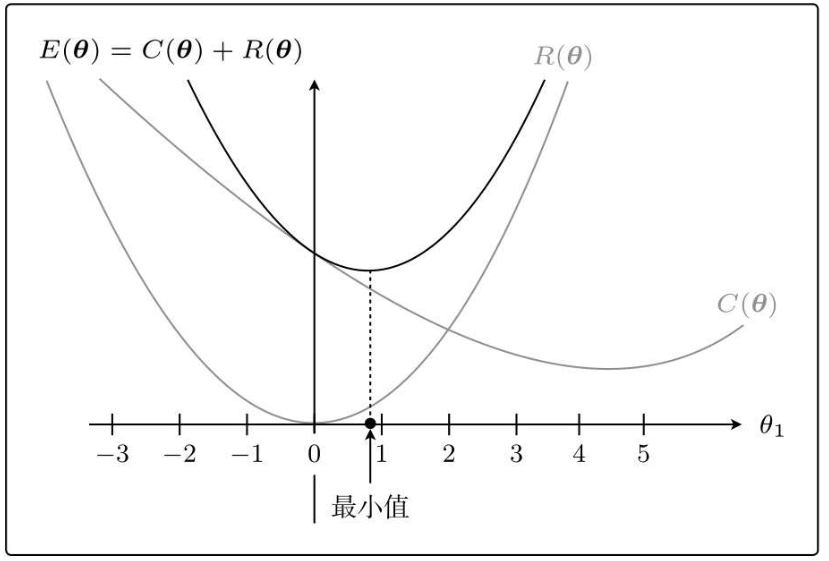
4.3.3 正则化效果
-
与加正则化项之前相比,θ1更接近0了,本来是在θ1=4.5处最小,现在是在θ1=0.9处最小,的确更接近0了。
-
这就是正则化的效果。它可以防止参数变得过大,有助于参数接近较小的值。
-
虽然我们只考虑了θ1,但其他θj参数的情况也是类似的。
-
参数的值变小,意味着该参数的影响也会相应地变小。.
-
通过减小不需要的参数的影响,将复杂模型替换为简单模型来防止过拟合的方式。
-
为了防止参数的影响过大,在训练时要对参数施加一些惩罚
-
那一开始就提到的λ,是可以控制正则化惩罚的强度吗?
-
是的。比如令λ=0,那就相当于不使用正则化
4.3.4 分类的正则化
-
分类也是在这个对数似然函数中增加正则化项就行了,道理是相同的
-
反转符号是为了将最大化问题替换为最小化问题
-
对数似然函数本来以最大化为目标。但是,这次我想让它变成和回归的目标函数一样的最小化问题,所以加了负号
4.3.5 包含正则化项的表达式的微分
L1正则化
L2正则化
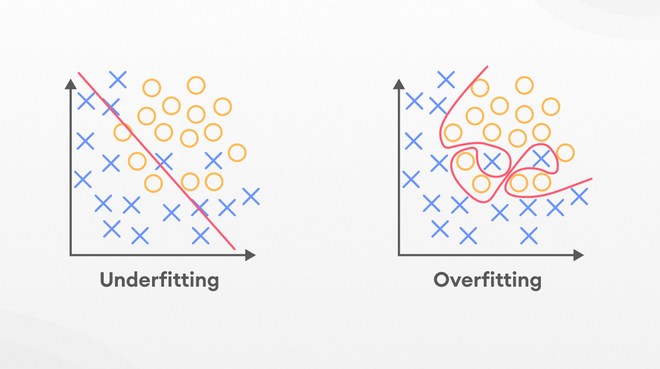
4.4 学习曲线
-
过拟合&&欠拟合
-
展示了数据数量和精度的图称为学习曲线
第五章:实现使用Python编程
5.1 使用Python实现
5.2 回归
5.3 分类——感知机
5.4 分类——逻辑回归
5.5正则化
5.6 后话
学习心得:
- 本书是文章作者在初期接触人工智能领域所读,用以知道/大致了解一些和人工智能有关的名字/术语,后面再次涉及相关内容后,进行进一步的查阅资料&&深度学习

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)