Python爬虫实战|携程景点数据爬取附完整源码
·
前言
随着旅游业的复苏,景点数据分析需求日益增长。本文将详细介绍如何使用Python爬取携程网的景点数据,并以武汉市为例,爬取完整的景点信息,包括景点名称、等级、评分、评论数、热度、标签等关键字段。
📌 技术栈:Python 3.x + Requests + Fake-UserAgent + JSON + CSV
一、项目背景与目标
1.1 数据来源分析
携程接口 https://m.ctrip.com/restapi/soa2/18109/json/getAttractionList 提供了景点列表的JSON数据,通过POST请求即可获取结构化的景点信息,比解析HTML页面更加稳定高效。
1.2 爬取字段说明
| 字段名称 | 说明 |
|---|---|
| 景点名称 | 景点中文名称 |
| 所属区域 | 景点所在行政区 |
| 所属城市 | 景点所在城市 |
| 景点等级 | 如5A、4A等 |
| 用户评分 | 用户综合评分 |
| 评论人数 | 累计评论数量 |
| 热度评分 | 携程热度分值 |
| 景点标签 | 景点特色标签 |
| 距离描述 | 与参考点的距离 |
| 图片链接 | 封面图片URL |
| 详情页链接 | 景点详情页地址 |
二、代码结构设计
采用面向对象的编程思想,封装 CtripAttractionSpider 类,主要包含以下方法:
__init__() # 初始化配置、Cookie、CSV文件
_get_headers() # 生成随机User-Agent请求头
_build_request_data() # 构建POST请求体
_fetch_page() # 请求单页数据
_save_to_csv() # 保存数据到CSV
crawl() # 主爬取逻辑
三、完整代码实现
3.1 导入依赖库
import requests
import json
import time
import random
import csv
import os
from fake_useragent import UserAgent
3.2 爬虫类完整代码
class CtripAttractionSpider:
"""携程景点信息爬虫类"""
def __init__(self, cookies, district_id=145, output_file='景点数据.csv'):
self.cookies = cookies
self.district_id = district_id # 武汉市district_id为145
self.output_file = output_file
self.base_url = 'https://m.ctrip.com/restapi/soa2/18109/json/getAttractionList'
# 基础请求头
self.base_headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9',
'content-type': 'application/json',
'origin': 'https://you.ctrip.com',
'referer': 'https://you.ctrip.com/',
'x-ctx-currency': 'CNY',
'x-ctx-locale': 'zh-CN',
}
# CSV字段(中文表头)
self.fieldnames = [
'景点名称', '所属区域', '所属城市', '景点等级',
'用户评分', '评论人数', '热度评分', '景点标签',
'距离描述', '图片链接', '详情页链接'
]
self._init_csv()
def _init_csv(self):
"""初始化CSV文件,写入表头"""
file_exists = os.path.isfile(self.output_file)
with open(self.output_file, 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=self.fieldnames)
if not file_exists:
writer.writeheader()
def _get_headers(self):
"""获取带随机UA的请求头,降低反爬风险"""
headers = self.base_headers.copy()
headers['user-agent'] = UserAgent().random
return headers
def _build_request_data(self, page_index):
"""构建POST请求的JSON数据"""
data = {
"head": {
"cid": "09031109216141753464",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "999",
"auth": "",
"xsid": "",
"extension": []
},
"scene": "online",
"districtId": self.district_id,
"index": page_index,
"sortType": 1,
"count": 10,
"filter": {"filterItems": []},
"coordinate": {
"latitude": 29.02786933333333,
"longitude": 111.62905099999999,
"coordinateType": "WGS84"
},
"returnModuleType": "all"
}
return json.dumps(data)
def _save_to_csv(self, attraction_info):
"""保存单条数据到CSV"""
with open(self.output_file, 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=self.fieldnames)
writer.writerow(attraction_info)
def fetch_page(self, page_index):
"""获取单页数据"""
try:
# 随机延时,避免请求过快
time.sleep(random.uniform(2.5, 3.5))
response = requests.post(
self.base_url,
headers=self._get_headers(),
cookies=self.cookies,
data=self._build_request_data(page_index)
)
if response.status_code != 200:
print(f"请求失败,状态码:{response.status_code}")
return None
json_data = response.json()
if 'attractionList' not in json_data:
print(f"第{page_index}页没有找到景点数据")
return None
result = []
for scenic in json_data['attractionList']:
card = scenic.get('card', {})
if not card:
continue
# 处理标签列表
tags = card.get('tagNameList', [])
tag_str = '、'.join(tags) if tags else ''
# 提取景点信息
attraction_info = {
'景点名称': card.get('poiName', ''),
'所属区域': card.get('zoneName', ''),
'所属城市': card.get('districtName', ''),
'景点等级': card.get('sightLevelStr', ''),
'用户评分': card.get('commentScore', ''),
'评论人数': card.get('commentCount', ''),
'热度评分': card.get('heatScore', ''),
'景点标签': tag_str,
'距离描述': card.get('distanceStr', ''),
'图片链接': card.get('coverImageUrl', ''),
'详情页链接': card.get('detailUrl', '')
}
result.append(attraction_info)
self._save_to_csv(attraction_info)
print(f"已保存:{attraction_info['景点名称']} - {attraction_info['距离描述']}")
print(f"第{page_index}页完成,获取{len(result)}条数据")
return result
except Exception as e:
print(f"第{page_index}页出错:{str(e)}")
return None
def crawl(self, start_page=1, end_page=1):
"""执行爬取任务"""
all_data = []
for page in range(start_page, end_page + 1):
data = self.fetch_page(page)
if data:
all_data.extend(data)
print(f"\n爬取完成!共获取 {len(all_data)} 条数据,已保存至 {self.output_file}")
return all_data
3.3 主函数调用
def main():
# 携程Cookie(需从浏览器复制)
cookies = {
'GUID': '09031109216141753464',
'_ga': 'GA1.1.2068278497.1768015686',
'ibulocale': 'zh_cn',
# ... 此处省略完整Cookie,请替换为自己的
}
# 创建爬虫实例
spider = CtripAttractionSpider(
cookies=cookies,
district_id=145, # 145代表武汉市
output_file='携程武汉景点数据.csv'
)
# 爬取第1页到第101页(可根据实际需求调整)
spider.crawl(start_page=1, end_page=101)
if __name__ == '__main__':
main()
四、关键参数说明
4.1 district_id(城市代码)
不同城市的 district_id 不同,常用城市代码如下:
| 城市 | district_id |
|---|---|
| 北京 | 1 |
| 上海 | 2 |
| 广州 | 4 |
| 深圳 | 7 |
| 杭州 | 17 |
| 武汉 | 145 |
| 成都 | 104 |
| 重庆 | 158 |
4.2 Cookie获取方式
- 打开携程景点页面:https://you.ctrip.com/sight/wuhan145.html
- 按
F12打开开发者工具 - 切换到
Network标签页 - 刷新页面,找到
getAttractionList请求 - 在请求头中复制完整的
Cookie值
4.3 爬取速度控制
代码中设置了 time.sleep(random.uniform(2.5, 3.5)),每次请求间隔2.5-3.5秒,避免因请求过快导致IP被封。
五、运行结果展示
运行成功后,控制台输出示例:
生成的CSV文件可用Excel直接打开,效果如下: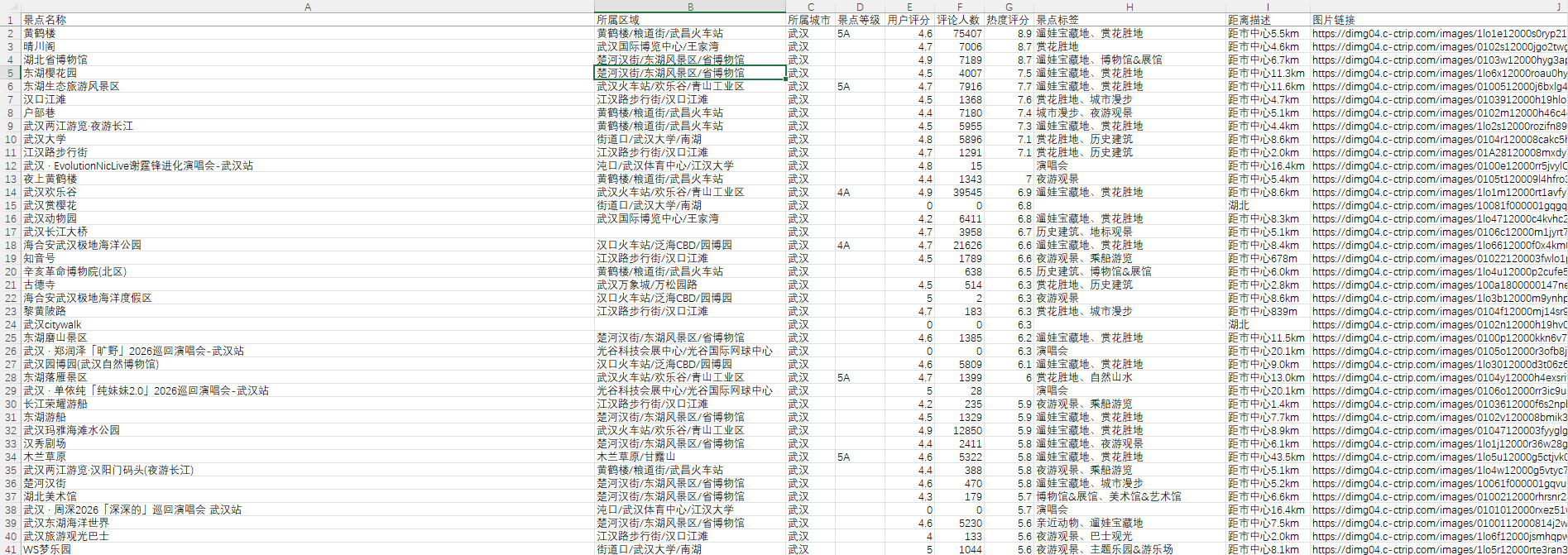
六、注意事项与优化建议
⚠️ 注意事项
- Cookie时效性:携程Cookie有一定有效期,如遇请求失败请及时更新
- 爬取频率:建议保持2秒以上的请求间隔,尊重网站服务器
- 仅供学习:本代码仅供Python爬虫技术学习交流,请勿用于商业用途
🚀 优化建议
- 代理IP池:大规模爬取时可接入代理IP池
- 异常重试:可增加请求失败重试机制
- 断点续爬:记录已爬取页码,支持中断后继续
- 多线程:在遵守爬取规范的前提下可考虑多线程提速
七、总结
本文详细介绍了携程景点数据的爬取方法,核心要点包括:
- 分析移动端接口,获取结构化的JSON数据
- 使用面向对象方式封装爬虫逻辑
- 合理控制请求频率,降低反爬风险
- 数据持久化保存为CSV格式
通过本教程,你可以轻松获取任意城市的携程景点数据,为后续的数据分析、可视化或旅游推荐系统提供数据支撑。
📎 参考资料
如果本文对你有帮助,欢迎点赞 👍、收藏 ⭐、关注 🔔
如有疑问,欢迎在评论区留言交流!
END

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)