1. 机器学习 - 入门
机器学习(ML)
1)什么是
机器学习(Machine Learning,简称 ML)是人工智能(Artificial Intelligence, AI)的一个重要分支,其核心思想是让计算机系统能够从数据中自动学习规律或模式,并在没有明确编程指令的情况下,对新数据做出预测或决策。
2)为什么
机器学习让我们能够利用数据,让计算机自己“学会”如何完成复杂的任务,而不是由人类程序员一步步地编写明确的指令。
概念
1. 常用术语
样本(sample):一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录
特征(feature):一列数据一个特征,有时也被称为属性
标签/目标(label/target):模型要预测的那一列数据
案例:预测房价
| 房屋面积 (m²) | 卧室数量 | 是否靠近地铁 | 房龄(年) | 价格(万元) |
|---|---|---|---|---|
| 80 | 2 | 是 | 5 | 120 |
| 120 | 3 | 否 | 3 | 180 |
| 60 | 1 | 是 | 8 | 90 |
| 150 | 4 | 是 | 2 | 250 |
样本(Sample)
定义:一行数据就是一个样本。
在案例中:
每一行代表一个房屋的信息 → 例如第一行 80, 2, 是, 5, 120 就是一个样本。
全部行组成一个数据集,用于训练模型。
所以:共有 4 个样本(这里只是示例,真实数据可能有上千条)。
特征(Feature)
定义:一列数据代表一个特征,也叫属性。
在案例中:
“房屋面积”、“卧室数量”、“是否靠近地铁”、“房龄” → 都是特征。
这些是用来描述样本的变量。
特征数量 = 4(即输入维度为 4)
标签 / 目标(Label / Target)
定义:模型要预测的那一列数据。
在案例中:
“价格(万元)”这一列就是标签。
我们的目标是:根据前四个特征,预测价格。
所以:这是一个回归问题(预测连续值)
数据集划分
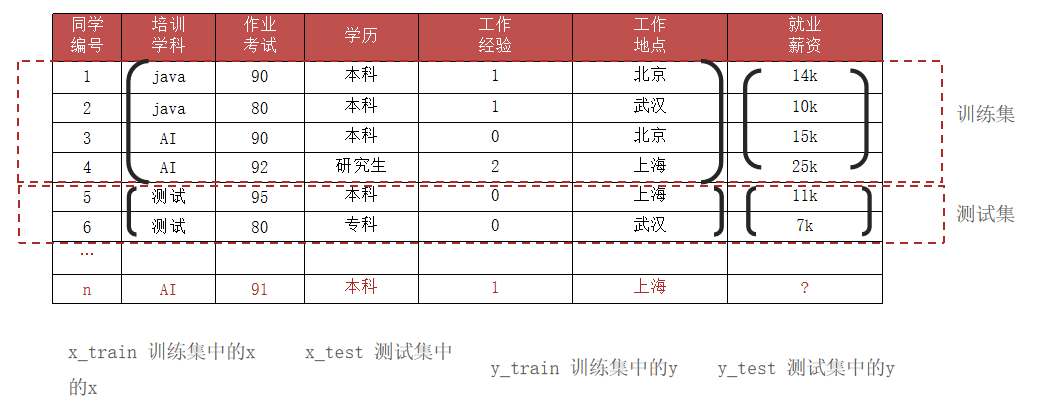
训练集
用于训练模型,让模型从数据中学习规律
测试集
模拟真实的场景,对最终模型进行无偏向化评估
通常占比权重为前者:后者8:2或者7:3
2.机器学习的算法分类
基于规则的学习:程序员根据利用手工的if-else方式进行预测
基于模型的学习:从数据中自动学出规律
1)监督学习
有标签:训练数据包含输入特征和对应的输出标签(即目标值)。
~1. 分类问题:标签是离散的类别(如“猫”或“狗”),目标是预测样本所属的类别。
~2. 回归问题:标签是连续的数值(如房价、温度),目标是预测一个具体的数值。
2)无监督学习
无标签
聚类问题
3)半监督(了解)1.让专家标注少量数据,利用已经标记的数据(也是带有类标签的)训练出一个模型
2.再利用该模型去套用未标记的数据
3.通过询问领域专家分类结果与模型分类结果做对比 ,从而对模型做进一步改善和提高
半监督的学习方式大幅度地降低了标记成本
强化学习(暂时放过)
强化学习是一种机器学习方法,智能体(agent)通过与环境交互,根据所采取动作获得的奖励或惩罚信号,不断学习并优化策略,以最大化长期累积奖励。
类:强化学习
属性和行为:环境、奖励、状态、动作、智能体
一个重要的里程碑:阿尔法狗战胜了棒子棋手
3.机器学习建模流程
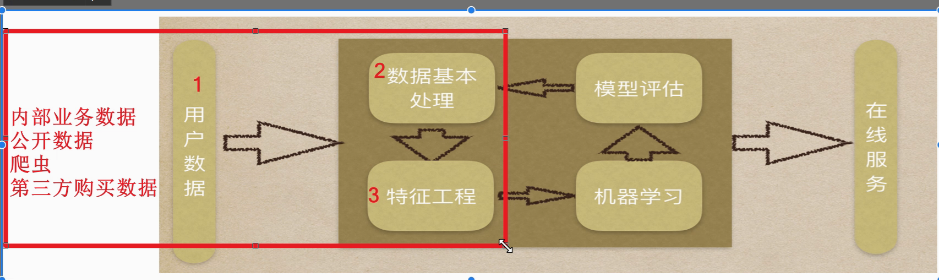
1.拿到数据
2.清洗数据
3.筛选数据/特征工程
4.处理数据/训练模型
5.模型评分
4.特征工程概念

1.特征提取 feature extraction:最终是提取到特征的向量格式的数据
计算相似性就得使用向量化格式的数据
2.特征预处理 feature preprocessing:不同特征对模型影响一致性
比如处理缺失值,特征归一化、标准化,特征预处理需要“按特征类型路由”到不同的处理流程等等…
3.特征降维 feature decomposition:保证数据的主要信息要保留下来
比如减少特征数,缓解过拟合问题。
降低算力需求,优化训练/预测的时间等等…
4.特征选择 feature selection:从特征中选出一些重要特征训练模型
从原始特征集中挑选出对模型预测最有用的子集,在不构造新特征的前提下,提升模型性能、可解释性和效率
举例:医疗数据有 1000 项检查指标,但真正与疾病相关的可能只有 10 项。选出来,模型更准、医生也信服。
5.特征组合 feature crosses:把多个特征合并组合成一个特征
很多现实问题的规律不是单个特征能表达的,而是多个特征共同作用的结果。
案例1
“用户年龄” → 年轻人可能更爱买潮鞋
“商品类别” → 潮鞋本身销量高
但真正关键的是:“年轻用户 + 潮鞋” 这个组合!
→ 这就是特征交互(Interaction)。
如果模型只看到原始特征,可能无法自动学到这种复杂关系(尤其在线性模型中)。
案例2
金融风控:逾期次数 / 历史借款次数
医疗诊断:血压 × 年龄 / BMI
电商:是否在促销期 & 是否浏览过优惠券
这类特征往往可解释性强、效果显著,是数据科学家的核心竞争力。
5. 拟合与泛化
欠拟合
训练误差高,测试误差高
学不到规律(笨)
过拟合
训练误差低,测试误差高
学到了不该学的(坏)
良好拟合
训练好,测试好
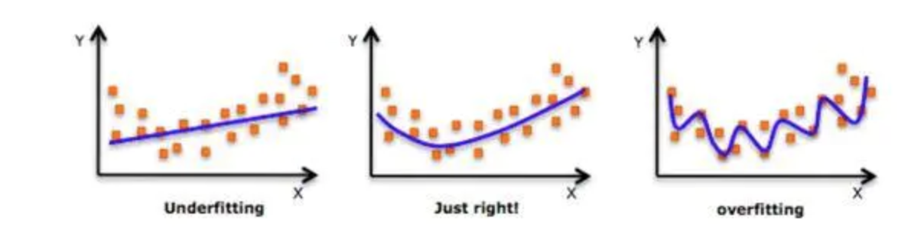
泛化
模型在从未见过的新数据(测试集/真实场景)上依然能做出准确预测的能力。
奥卡姆剃刀原则:给定两个具有相同泛化误差的模型,较为简单的模型比较为复杂的模型更可取
6.python机器学习开发环境的搭建
scikit-learn库
官网:https://scikit-learn.org/stable/
python库安装指令:
pip install scikit-learn -i https://mirrors.aliyun.com/pypi/simple/
验证安装结果:
python -c “import sklearn; print(sklearn.version)”
现实版本则安装成功
7.虚拟环境准备上的一些指令
删除
conda env remove --name 要删除的环境名
conda env remove --prefix “全路径名”
进入/退出
conda activate <环境名>
conda deactivate
自定义默认环境安装的目录
conda config --add envs_dirs <目录的全路径名>
自定义虚拟环境
conda create -n <自定义的环境名> python=<python版本号>
安装sk(阿里镜像)
pip install scikit-learn -i https://mirrors.aliyun.com/pypi/simple/
常用的数学符号

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)