机器学习---逻辑回归
一、逻辑回归概述
1.逻辑回归(Logistic Regression)也称作 Logistic 回归分析,是一种广义的线性回归分析模型,属于机器学习中的监督学习。它实际上主要是用来解决二分类问题。通过给定的 组数据(训练集)来训练模型,并在训练结束后对给定的一组或多组数据(测试集)进行分类,其中每一组数据都是由 个指标构成。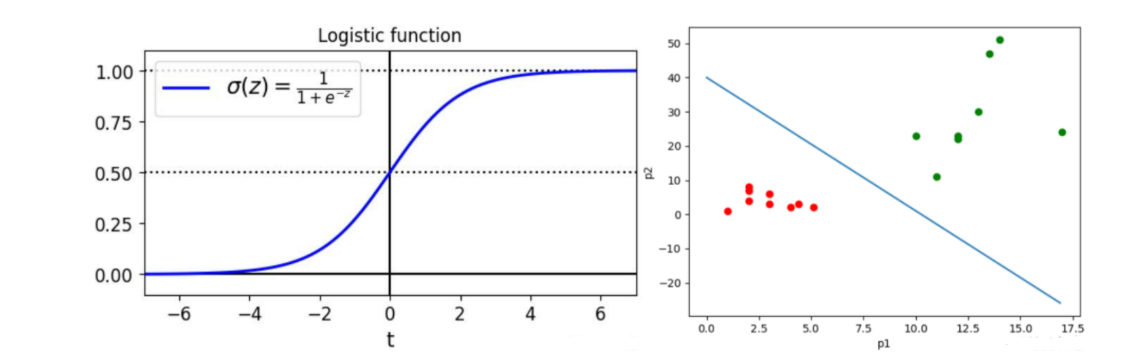
逻辑回归 = 线性回归 + S i g m o i d SigmoidSigmoid函数(分类函数)
2.损失函数
为求出好的逻辑回归,引出损失函数 :
①损失函数是体现“预测值”和“真实值”,相似程度的函数
②损失函数越小,模型越好
逻辑回归的损失,称之为对数似然损失,公式如下:
if y=1
if y=0
其中y为真实值,为预测值
无论何时,我们都希望损失函数值,越小越好
分情况讨论,对应的损失函数值:
当y=1时,我们希望值越大越好;
当y=0时,我们希望值越小越好;
综合完整损失函数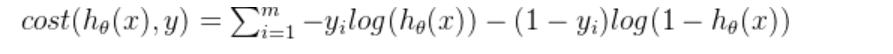
3.优点与缺点
优点:简单而且容易实现。逻辑回归的模型相对简单,只需要对输入特征进行线性组合,然后通过S i g m o i d SigmoidSigmoid函数进行分类预测。
计算效率高。逻辑回归的计算量相对较小,可以处理大规模的数据集。
可解释性强。逻辑回归的结果可以解释为某个事件发生的概率,比较直观易懂。
可以在线学习。逻辑回归可以通过梯度下降算法进行在线学习,适用于增量学习和实时预测。
缺点:对特征的依赖性强。逻辑回归对特征之间的依赖性较为敏感,如果特征之间存在较强的相关性,会导致模型效果较差。
对异常值较为敏感。逻辑回归对异常值较为敏感,可能会影响模型的预测结果。
需要大量的特征工程。为了提高逻辑回归的性能,通常需要进行大量的特征工程,包括特征选择、特征变换等。
无法处理非线性问题。逻辑回归是一种线性模型,无法处理非线性问题,需要通过添加多项式特征或者引入核函数来解决非线性问题
二、代码实现
1.数据加载函数 loadDataSet
def loadDataSet():
data = []
label = []
fr = open(filename)
for line in fr.readlines():
lineArray = line.strip().split()
data.append([1.0, float(lineArray[0]), float(lineArray[1])])
label.append(int(lineArray[2]))
return data, label这个函数从文件中读取数据和标签。每行数据被分割成三个部分:前两个是特征值,第三个是标签(类别)。特征值被转换为浮点数,标签被转换为整数。每个数据点还添加了一个额外的特征值1,用于计算截
2.Sigmoid函数 sigmoid
def sigmoid(X):
return 1.0 / (1 + exp(-X))激活函数,用于将任何实数映射到(0,1)区间
3.学习率 alpha
alpha = 0.001
学习率是梯度下降算法中的一个超参数,控制着权重更新的步长。
4.梯度计算函数 gradient
def gradient(weights, data, label):
dataMatrix = mat(data)
classLabels = mat(label).transpose()
h = sigmoid(dataMatrix * weights)
error = (classLabels - h)
q = -dataMatrix.transpose() * error
return q这个函数计算了损失函数的梯度。它首先将数据和标签转换为矩阵形式,然后计算预测值h,接着计算误差error,最后计算梯度q。
5.梯度下降函数 gradient_Accent
def gradient_Accent(data, label):
m, n = shape(data)
weights = ones((n, 1))
q = gradient(weights, data, label)
while not all(absolute(q) <= 2e-5):
weights = weights - alpha * q
q = gradient(weights, data, label)
return weights这个函数使用梯度下降法来更新权重。它初始化权重为1,然后在一个循环中不断更新权重,直到梯度的绝对值小于一个预设的阈值(这里设为2e-5)。
6.绘制决策边界函数 plotBestFit
def plotBestFit(weights): # 定义一个函数,用于画出最佳拟合线
import matplotlib.pyplot as plt # 导入matplotlib.pyplot,用于绘图
dataMat, labelMat = loadDataSet() # 加载数据集
dataArr = array(dataMat) # 将数据集转换为NumPy数组
n = shape(dataArr)[0] # 获取数据集中的样本数量
# 初始化两个空列表,用于存储两类数据的坐标
xcord1 = [];
ycord1 = []
xcord2 = [];
ycord2 = []
# 遍历数据集中的每个样本
for i in range(n):
# 根据标签将样本分为两类
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i, 1]) # 如果是第一类,添加x坐标
ycord1.append(dataArr[i, 2]) # 如果是第一类,添加y坐标
else:
xcord2.append(dataArr[i, 1]) # 如果是第二类,添加x坐标
ycord2.append(dataArr[i, 2]) # 如果是第二类,添加y坐标
fig = plt.figure() # 创建一个新的图表
ax = fig.add_subplot(111) # 在图表中添加一个子图
# 绘制两类样本的散点图
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') # 第一类样本,红色,形状为正方形
ax.scatter(xcord2, ycord2, s=30, c='green') # 第二类样本,绿色
# 创建一个x的数组,用于画出最佳拟合线
x = arange(-3.0, 3.0, 0.1)
# 使用逻辑回归模型的权重计算最佳拟合线的y值
y = (-weights[0] - weights[1] * x) / weights[2]
# 画出最佳拟合线
ax.plot(x, y)
plt.xlabel('X1') # 设置x轴标签
plt.ylabel('X2') # 设置y轴标签
plt.show() # 显示图表
这个函数用于绘制数据点和决策边界。它根据权重计算出决策边界,并将数据点根据类别用不同的颜色和标记绘制出来。
7.主函数 main
def main():
dataMat, labelMat = loadDataSet()
weights = gradient_Accent(dataMat, labelMat).getA()
plotBestFit(weights)首先加载数据,然后使用梯度下降法找到最佳权重,并绘制出决策边界
8.运行主函数
if __name__ == '__main__':
main()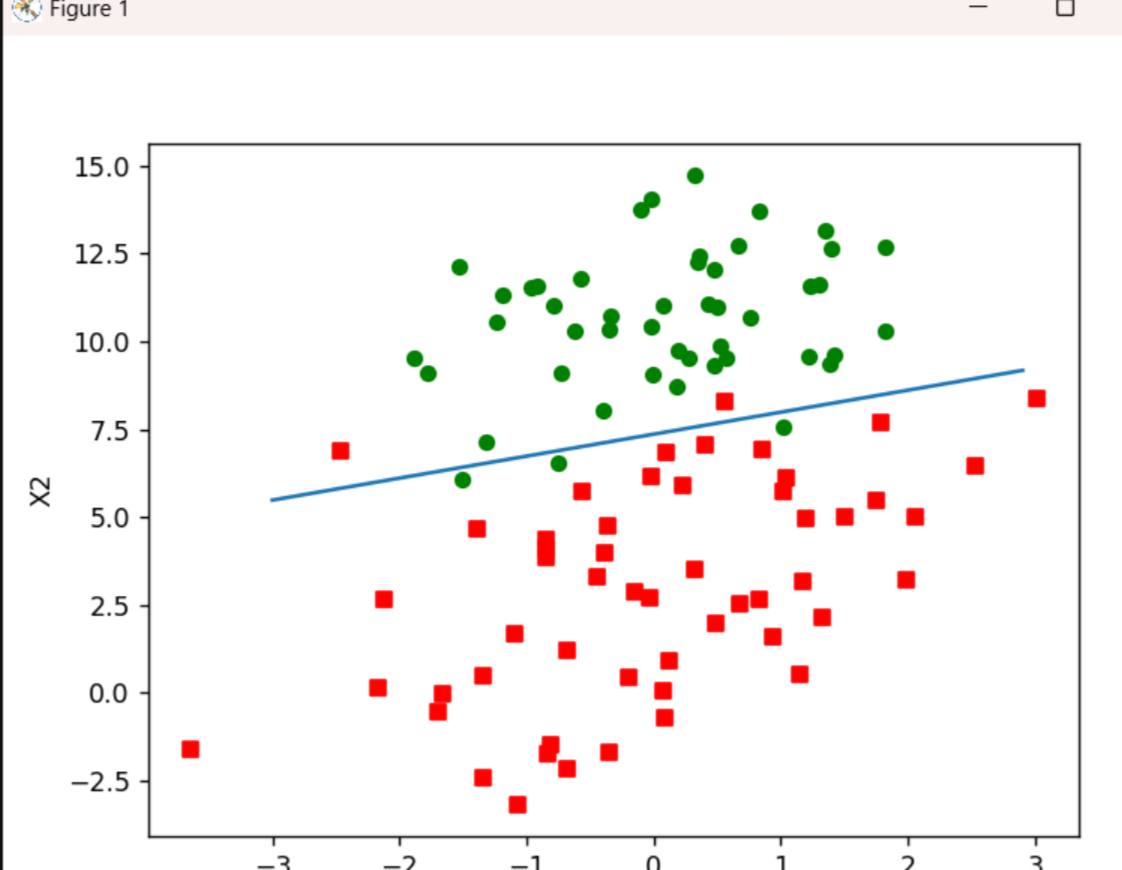

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)