2022年第十九届五一数学建模竞赛-B题 矿石加工质量控制问题
基于机器学习回归预测矿石加工的系统温度和产品质量
关键词:多元线性回归、随机森林、决策树
摘 要:
有效提高冶炼效率,可以提高矿石加工质量,节约不可再生的矿物资源以及加工所需的能源。为解决矿物资源不可再生问题,我们对矿石加工质量控制问题进行建模和描述。
对于问题一,首先对数据进行预处理,对系统温度、产品质量和原矿参数的数据集进行归一化和异常值点过滤处理,由于记录数据的单位时间不相同,统一以小时作为记录数据的时间基准,在excel软件中调用vlookup函数,使得产品质量的记录时间与系统温度的记录数据一一对应,对缺失值进行删除处理,建立多元回归线性模型,利用stata软件批量处理数据,对指标ABCD进行多元线性回归拟合,并对已经构建好的方程进行拟合优度的检验。由于建立的多元线性回归模型的拟合效果并不理想,因此我们重新引入随机森林算法对模型进行优化,当模型改进后,使用随机森林预测未来产品质量时,拟合优度明显比多元线性回归高,拟合效果比多元线性回归更好。
对于问题二,在已知原矿参数与产品目标质量的情况下,预测所对应的系统温度,我们使用决策树对其进行预测。同时,为了验证方法的准确度,同时也使得预测的系统温度达到最大值,我们这里不仅仅是求解上述建立的决策树模型,还需要求解建立多元线性回归模型和随机森林模型进行比较。
对于问题三,首先进行数据预处理,删除缺失值,对异常值进行修改,同时统一时间间隔,以记录产品质量数据的时间间隔为标准,使用vlookup函数使产品质量与系统温度一一对应,建立的模型为随机森林模型和决策树模型,以系统Ⅰ和Ⅱ温度、原矿参数和过程参数为自变量,以产品质量指标ABCD为因变量,对此分别建立随机森林模型和决策树模型,可以得出合格数和产品总数,然后将附件2导入python软件,根据随机森林模型和决策树模型,调用库函数得到的预测结果,该预测值再与产品销售条件进行对比,即可检验生产的产品是否合格。
对于问题四,通过将历史时间的数据当作训练集,以4.17之前的数据原矿参数和过程数据为自变量,系统温度为因变量,进行随机森林预测,可以得出预测的系统温度并进行比对,得到的数值可信度比较高,用之预测4.10和4.11的系统设定温度,再次建立随机森林模型,得出产品合格数计算预测的合格率,并判断能否达到设定合格率,结果显示两天都不能达到设定的合格率。
一、问题重述
加工矿石过程中,系统温度直接影响矿石产品的质量,而原矿参数则是反映矿石本身的质量,过程数据则是在加工过程时产生的,一定程度上也可以反映原矿石的质量。已知在不同时间记录不同变量的数据,需要预测不同环境下的系统温度和产品质量,详细的如下列问题:
问题一:已知生产车间2022-01-13至01-22的生产加工数据,需要我们建立数学模型利用系统温度预测产品质量。由于存在不确定因素的,在相近的系统温度下生产出来的产品质量可能有比较大的差别,在这种情况下请预测可能性最大的产品指标填入表5中;
问题二:问题1的基础上,我们需要建立数学模型预测产品目标质量所对应的系统温度,并将预测得到的结果放入表10中;
问题三:已知该生产车间2022-01-25至04-07的生产加工数据及过程数据和销售条件,需要根据指标判断是否是合格产品,合格率=合格产品数/产品总数,建立数学模型,在给出的指定系统设定温度下,预测矿石产品合格率的方法,给出合格率预测结果,填入表14中,并建立数学模型对给出的合格率的准确性进行评价。
问题四:根据预测的合格率,利用已知原矿参数和过程数据,建立数学模型分析在指定合格率的条件下,如何设定系统温度的方法,判断能否达到给出的2022-04-10和2022-04-11产品合格率80%和99%的要求,如果可以达到,给出系统设定温度,并进行适当的敏感性分析和对结果准确性的分析。
二、问题分析
考虑到数据量较大,而且数据有缺失值,我们首先需要对原件的附件1、附件 2进行数据预处理,将后续程序中需要用到的数据另存为后缀为附件1和附件2。
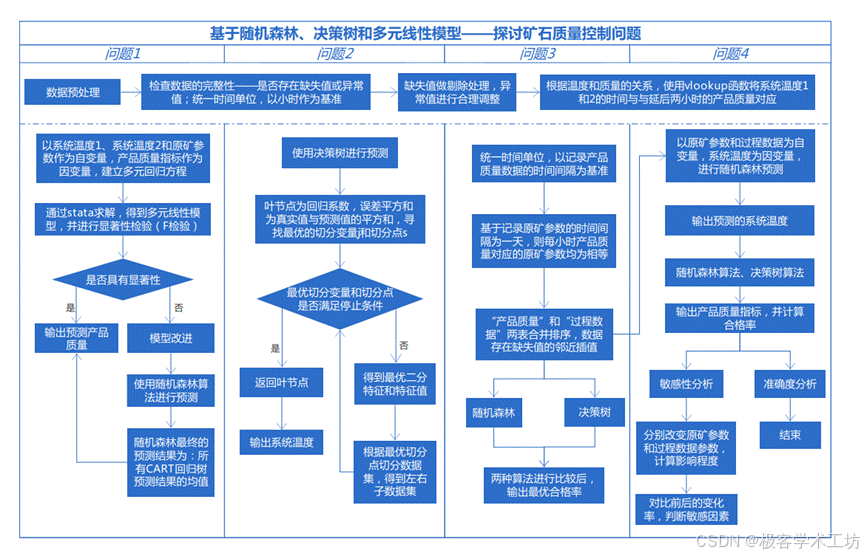
图1



DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 16
16 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)