多模态目标检测模型DQ-DETR论文详解——来自2023年AAAI
一. 论文梗概
《DQ-DETR: Dual Query Detection Transformer for Phrase Extraction and Grounding》提出了一种新任务框架 短语提取与定位(Phrase Extraction and Grounding, PEG),旨在同时从文本中提取短语并定位图像中的相关目标对象。为了解决多模态对齐(图像与文本)中的挑战,作者设计了一种基于双查询机制的模型 DQ-DETR,该模型引入双查询来探测图像和文本的不同特征,用于对象预测和短语掩码预测。每一对双查询都被设计为具有共享的位置部分,但不同的内容部分。这样的设计有效地缓解了图像和文本之间模态对齐的困难(与单一查询设计相比),并Transformer解码器能够利用短语掩码引导的注意力来提高性能。将短语提取视为 1D 文本分割任务,与目标检测的边界框回归结合在同一框架中。
DQ-DETR 的核心创新包括:
1.双查询设计:通过为文本短语和图像目标分别设计查询,减小模态对齐的难度,加速收敛并提高性能。
2.文本掩码引导注意力:约束模型关注文本中相关片段,提高短语定位精度。
3.新评价指标 CMAP(跨模态平均精度):克服传统 Recall@1 在多目标短语场景中的模糊性,全面衡量短语提取与目标定位的能力。
实验结果表明,我们的PEG预训练DQ-DETR在所有具有ResNet-101主干的视觉接地基准上建立了新的最先进的结果。例如,使用ResNet-101骨干网的RefCOCO测试a和测试b的召回率分别达到了91.04%和83.51%,验证了其在 PEG 和下游任务(短语定位、目标检测)中的高效性与适应性。
二. 四种任务及其区别
本篇论文中反复提到了visual grounding视觉接地这一概念。
对于视觉接地(Visual Grounding)的理解:
视觉接地(Visual Grounding)是一种在计算机视觉与自然语言处理交叉领域的任务,其核心目标是让模型能够将 语言表达(如文本或短语)与 视觉信息(如图像或视频中的目标)对应起来,找到语言描述的目标在图像中的位置。
为了便于理解,可以用类比和场景来形象化这个概念:
想象你正在玩一个“寻宝游戏”:
- 游戏规则:有人给你一段提示(如“找出那只躺在草地上的猫”)。
- 你的任务:在一幅复杂的图像中找到这只猫并指出它的位置。
对于计算机来说,视觉接地就是完成这样的任务:根据语言提示在图像中定位目标。它要求模型理解语言的含义、图像的内容,并建立它们之间的联系。
视觉接地在学术研究中表现为多个子任务,这也是接下来我们讲解的四个任务:
- 目标检测(Object Detection):仅通过视觉识别图像中的所有目标。
- 指代表达理解(Referring Expression Comprehension, REC):根据描述找到图像中特定的目标。
- 短语定位(Phrase Grounding):将一段文本中的短语与图像区域一一对应。
- 短语提取与定位(PEG):同时提取文本中的相关短语并在图像中找到对应位置。
本文提出了一个新的任务名为Phrase Extraction and Grounding (PEG) ,短语提取和接地。下图是论文中提到的四种目标检测任务。
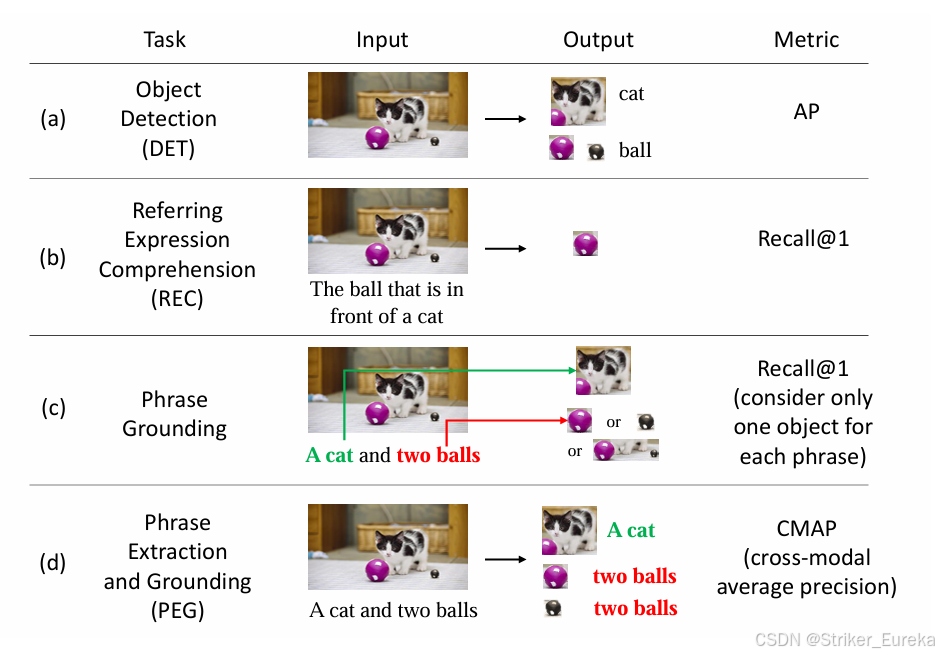
1.DET
给定图像,目标检测(DET)是在预定义的类别中定位目标。DET最流行的指标是mAP 。
任务定义:
- 输入:一张图像。
- 输出:图像中所有目标的边界框和类别(从预定义的类别集合中选择)。
例子:
- 输入:一张包含猫和球的图片。
- 输出:
- 边界框1:[猫,坐标]
- 边界框2:[球,坐标]
区别:
- 完全基于视觉信息,不涉及文本。
- 输出的类别集合是固定的,不能根据文本灵活变化。
2.REC
引用表达式理解(REC)旨在定位输入文本所描述的对象。它的表现通常是通过回忆最自信的输出来评估的。论文中提到部分作品认为视觉接地、参考表达理解(REC)和短语接地Phrase Grounding是可以互换的。然而,它们有细微的差别。REC和Phrase Grounding都是视觉基础的子任务。
REC定位具有自由格式引导文本的对象,如上图(b)所示。根据引用表达式的要求,REC只检测一类对象,而短语基础需要找到标题中提到的所有对象,如上图(c)所示。
任务定义:
- 输入:一张图像和一段指代表达(描述单个目标的句子)。
- 输出:目标的边界框。
例子:
- 输入:
- 图像:包含两只猫和一个球。
- 文本:
"the cat that is sitting on the left"。
- 输出:
- 边界框1:
"the cat that is sitting on the left"→ [左边猫的坐标]
- 边界框1:
区别:
- 文本仅描述一个目标,输出也是单个边界框。
- 不需要处理复杂的短语提取或多个目标的匹配问题。
3.Phrase Grounding
短语接地需要对图像中短语所描述的空间区域进行接地。大多数方法将此任务视为排序问题,并通过召回率对其进行评估。在推理过程中,通常假定句子中的短语是已知的。
任务定义:
- 输入:一张图像和一段包含短语的文本(短语已知)。
- 输出:每个短语对应的图像区域(边界框)。
例子:
- 输入:
- 图像:包含一只猫和两个球。
- 文本:
"a cat and two balls"。
- 输出:
- 边界框1:
"a cat"→ [猫的坐标] - 边界框2:
"two balls"→ [两个球的坐标]
- 边界框1:
区别:
- 假设测试时短语已知。
- 任务的重点是找到文本中的短语与图像目标的空间对应关系。
4.PEG
我们在本文中再次强调了短语提取和接地(PEG)设置。与短语接地相比,一个关键的区别是PEG中的短语在测试中是未知的。我们提出了一个用于PEG任务的CMAP(跨模态平均精度)度量,类似于用于DET的mAP。在本文中,我们将术语“视觉接地”用于所有三个任务:REC、短语接地和PEG。
任务定义:
- 输入:一张图像和一段包含多个短语的文本(短语未知)。
- 输出:提取出所有相关短语并找到它们对应的图像区域。
例子:
- 输入:
- 图像:包含一只猫和两个球。
- 文本:
"a cat and two balls are in the scene"。
- 输出:
- 短语1:
"a cat"→ [猫的坐标] - 短语2:
"two balls"→ [两个球的坐标]
- 短语1:
区别:
- 不同于短语定位,PEG 假设测试时短语未知,因此模型需要从文本中自动提取短语。
- 同时需要完成短语提取(从文本中找出相关部分)和目标定位(在图像中找到目标)。
- 综合了 NLP 和视觉任务的双重挑战。
PEG 与其他任务的关键区别总结:
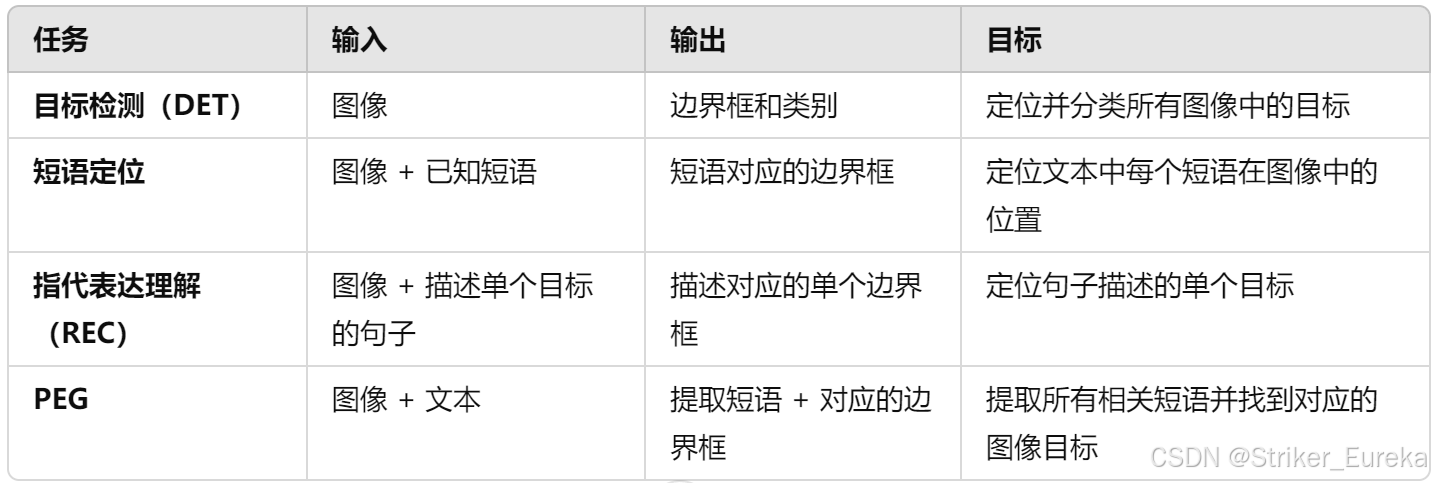
5.PEG和Phrase Grounding主要区别
Phrase Grounding
- 目标:将文本中 已知短语 与图像中对应的目标区域匹配。
- 任务设定:
- 输入:一段包含多个短语的文本和一幅图像(短语已知)。
- 输出:每个短语对应的图像区域(边界框或掩码)。
- 任务特点:
- 假设测试时短语已知,因此模型不需要从文本中提取短语。
- 模型的重点是解决短语和图像目标之间的对齐问题。
PEG
- 目标:在图像中 同时提取短语并定位目标区域。
- 任务设定:
- 输入:一段描述图像的完整文本和一幅图像(短语未知)。
- 输出:
- 提取出的短语。
- 每个短语对应的图像区域(边界框或掩码)。
- 任务特点:
- 短语在测试时未知,因此模型需要完成两个任务:
- 从文本中自动提取与图像相关的短语。
- 在图像中定位这些短语对应的目标。
- 短语在测试时未知,因此模型需要完成两个任务:
Phrase Grounding:就像有人给你一个地图和一份地点清单,你只需要在地图上找到清单中的地点。
PEG:就像有人给你一幅描述地图的文字,你需要从文字中找出地点名称,并在地图上标出它们的位置。
PEG 更灵活、实用,但同时对模型能力提出了更高要求。
6.不同模型Query的比较
这里的“Query”是指Transformer解码器的输入。
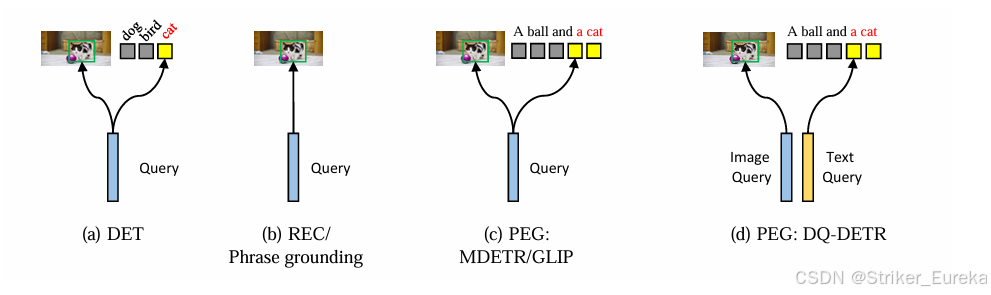
(a) DET模型中的每个查询对应一个对象和一个类标签id。
(b) REC/Phrase grounding模型中的每个查询只预测一个对象。
(c)以前一些适合PEG的工作,如MDETR使用相同的查询执行框定位和短语提取。
(d)我们建议在我们的DQ-DETR中将单个查询解耦为两个任务:对象定位和短语提取,这两个任务适用于两种不同的模式。
三. PEG & CMAP
让我们根据论文中的图像再次对这两个论文中提出的关键概念进行理解。

给定一个图像-文本对作为输入,PEG需要一个模型从输入的图像和文本对中预测区域-短语对,如上图所示。PEG任务可以看作是图像盒检测和文本掩码分割的双重检测问题,因为名词短语提取可以解释为一维文本分割问题。
对CMAP的理解:
1. CMAP 的核心思想
CMAP 借鉴了目标检测中广泛使用的 mAP(Mean Average Precision),但适配了多模态任务的需求。
- mAP(目标检测):通过计算预测的边界框与真实框之间的交集(IOU),评估边界框预测的准确性。
- CMAP(多模态 PEG):扩展 mAP 的概念,同时考虑目标的边界框和短语的文本匹配准确性,从而为每一对“短语-区域”生成一个跨模态的准确性评分。
2. 如何计算 CMAP?
(1) 双 IOU 计算(Dual IOU)
CMAP 使用 Dual IOU 来评估预测的“区域-短语”对是否与真实对匹配:
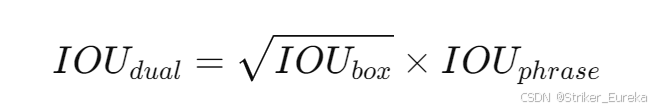
- IOUbox:预测边界框与真实边界框的交集比。
- IOUphrase:预测文本短语与真实短语的文本匹配程度(如基于字符串的重叠率)。
(2) 评估正负样本
- 如果 IOUdual≥0.5,预测的“区域-短语”对被认为是正样本。
- 根据正样本的精确率和召回率绘制 P-R 曲线(Precision-Recall Curve)。
(3) 计算平均精度(AP)
通过计算 P-R 曲线下的面积,得到平均精度(AP)。对每个短语-区域对计算 AP,然后取多个测试样本的平均值,得到 CMAP。
形象说明
CMAP 实际上将两个任务(目标检测中的框定位和文本理解中的短语匹配)融合为一个双任务评价指标。模型需要同时:
- 正确预测图像中目标的边界框。
- 准确匹配短语与目标之间的关联。
3. CMAP 的改进点
(1) 解决 Recall@1 的不足
Recall@1 仅考虑预测置信度最高的一个区域(最多匹配一个目标),在多目标场景下无法全面衡量模型性能。而 CMAP 鼓励模型找到所有相关目标和短语对,避免遗漏。
(2) 处理多目标对应问题
在实际应用中,一个短语可能对应多个目标(如“两个熊猫”)。传统评估方法可能只评估其中一个目标,而 CMAP 则对所有可能的目标进行全面评估。
(3) 一体化评价
CMAP 将文本提取和目标定位的评价标准融合为一个指标,使得多模态任务的模型评估更加统一和直观。
4. 图示化理解
假设一幅图像中有“两个熊猫躺在树枝上”的描述,CMAP 的评价流程如下:

- 输入:图像 + 文本。
- 模型输出:
- 两个边界框预测出两个熊猫的位置。
- 短语预测输出“两个熊猫”。
- CMAP 计算:
- 分别计算两个熊猫的预测框与真实框的 IOU。
- 计算预测短语与真实短语的文本匹配度。
- 根据 Dual IOU(边界框 IOU 和短语 IOU),评估正负样本并绘制 P-R 曲线。
- 最终通过 P-R 曲线下的面积计算出平均精度(AP)。
四.原来的模型的缺点(例如MDETR)
关于MDETR的详细讲解,大家可以去看看我的这篇博客:多模态经典之作MDETR论文详细解读——来自2021年ICCV
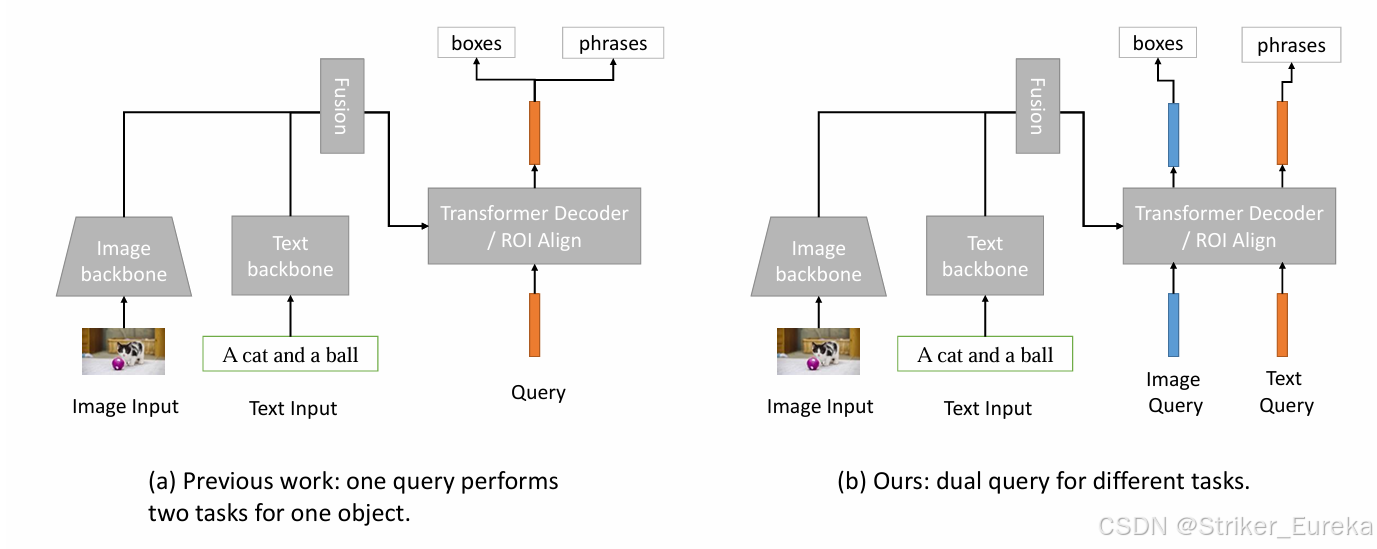
传统的视觉-语言模型(如 MDETR)通常使用 单一查询(Single Query)来同时处理短语定位和目标边界框预测。然而,这种方法面临以下问题:
- 模态对齐困难:图像和文本之间的特征分布差异大,单一查询需要同时对齐图像和文本特征,任务冲突导致性能受限。
- 任务需求不同:
(1) 短语提取需要聚焦于文本的语义内容。
(2)目标定位需要捕捉图像中的空间和视觉特征。 单一查询难以高效地同时满足这两种需求。
单查询和双查询结构对比:
五. 模型架构
整体框架:
DQ-DETR 是基于 Transformer 的编码-解码架构,包含以下模块:
- 图像骨干网络(如 ResNet-101):提取图像特征。
- 文本骨干网络(如 RoBERTa):提取文本特征。
- 多层 Transformer 编码器:整合图像与文本的多模态特征。
- 多层 Transformer 解码器:通过双查询机制生成边界框和文本掩码。
- 预测头:分别预测目标的边界框和对应的文本掩码。
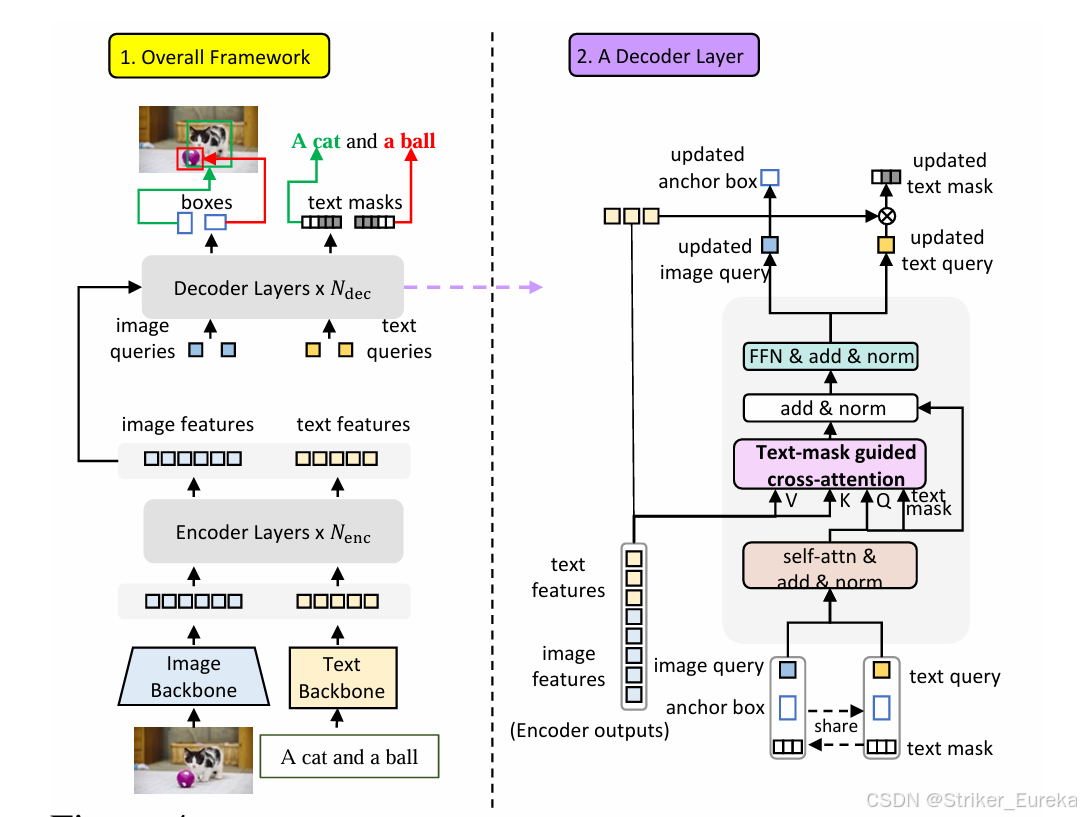
给定一对输入(图像,文本),我们分别使用图像主干和文本主干提取图像特征和文本特征。图像和文本特征被平面化、连接,然后输入到Transformer编码器层中。然后,我们对解码器层使用可学习的双重查询,从连接的多模态特征中探测所需的特征。图像查询和文本查询将分别用于框回归和短语本地化,如下图所示。
1.使用解耦查询用于图像框预测和文本掩码预测的关键原因
解耦查询(Dual Queries)用于图像框预测和文本掩码预测的核心原因在于,这两个任务的特性和需求存在明显差异,直接使用单一查询会带来对齐困难和任务冲突。
核心思路:
- 任务解耦:边界框预测和短语定位本质上是两个不同的任务,将其解耦后可以更专注地优化每个任务的特征学习。
- 共享位置信息:通过共享位置部分,保证图像区域和文本短语之间的对齐一致性。
- 独立内容部分:图像查询和文本查询的内容部分独立优化,分别处理图像和文本特征。
(1) 任务性质的不同
1.1 图像框预测的需求
- 目标:在图像中找到目标对象的准确位置(边界框)。
- 关键特征:
- 强调图像中的 空间信息(如位置、大小、形状)。
- 依赖视觉特征来进行边界框的回归。
- 不需要直接关注文本的具体语义信息。
1.2 文本掩码预测的需求
- 目标:在文本中提取与图像目标对应的短语(文本掩码)。
- 关键特征:
- 强调文本中的 语义信息(如短语的含义和上下文)。
- 需要从文本特征中提取短语的范围,类似 1D 文本分割任务。
- 不需要直接处理图像的视觉特征。
任务冲突
图像框预测和文本掩码预测对 特征表征 和 对齐方式 的要求截然不同:
- 图像框预测需要聚焦图像的视觉特征,而文本掩码预测需要聚焦文本的语义特征。
- 单一查询需要同时捕捉这两种信息,导致学习的特征不够专注,从而降低模型性能。
(2) 实验验证
论文中通过多项实验对比,证明了解耦查询的优越性:
![]()
2.1 边界框预测性能(如 L1 损失):
解耦查询的 DQ-DETR 比单一查询的 MDETR 收敛速度更快,且边界框误差更低。
图中显示,DQ-DETR 的 L1 损失下降速度显著高于 MDETR。
2.2 短语定位和目标检测的综合性能(如 CMAP50):
DQ-DETR 在 Flickr30k 数据集上的 CMAP50 指标比 MDETR 提升了 5.8%,验证了解耦设计在复杂任务中的效果。
2.双查询机制
双 Queries 机制 是 DQ-DETR 的核心创新点,它通过将 短语提取 和 目标定位 的任务解耦,分别使用两种查询(Queries)进行处理,图像查询专注于边界框的回归,文本查询用于定位目标短语在文本中的范围,从而提升多模态任务中图像-文本对齐的效率与准确性。
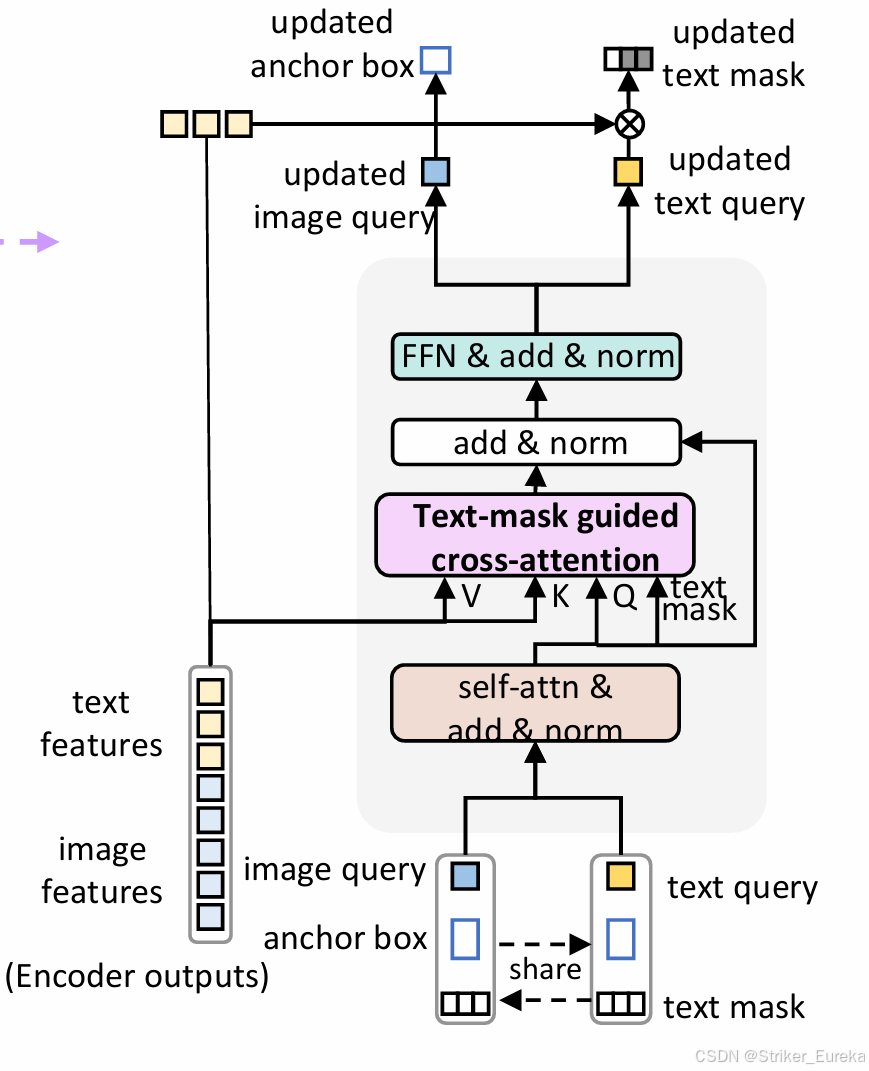
(1) 双 Queries 的组成
双 Queries 的每一对查询由 位置部分(Positional Part) 和 内容部分(Content Part) 构成:
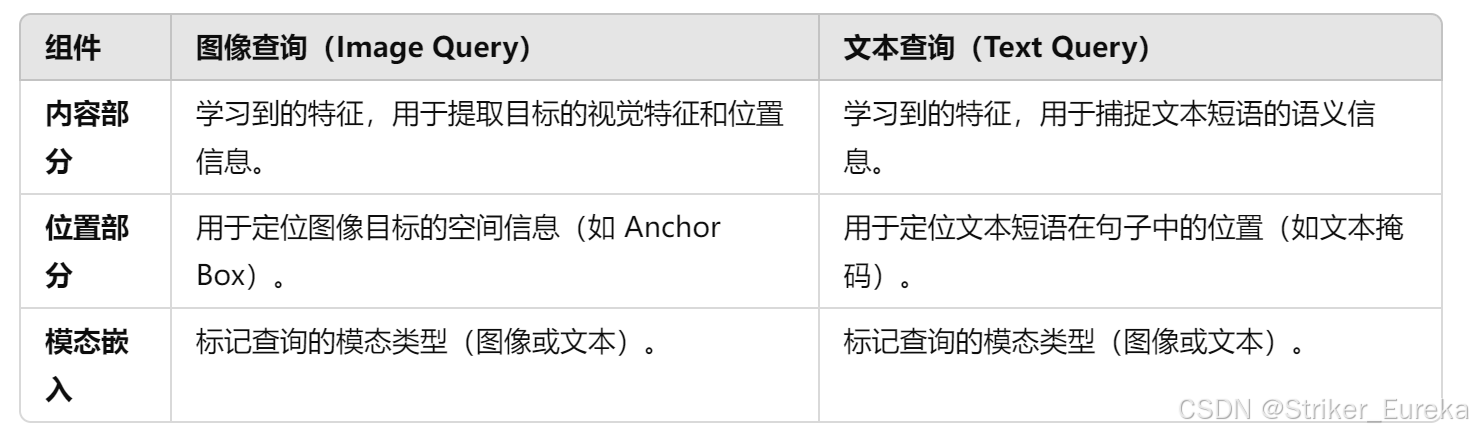
上图是我自己的解释,下图是官方论文中的解释,论文中给出的位置部分不仅有图像位置部分还有文本位置部分。
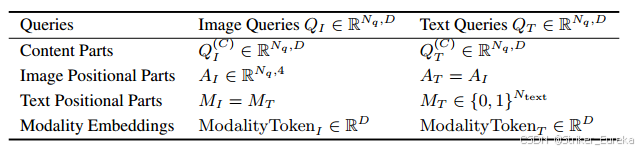
每对双查询共享位置部分,但内容部分不同。图像查询专注于边界框的回归,文本查询用于定位目标短语在文本中的范围。
(2) 双 Queries 的具体工作原理
2.1 查询生成
- 输入图像和文本后,模型通过 编码器(Encoder) 提取多模态特征。
- 解码器(Decoder)中,模型初始化 双 Queries:
- 图像查询(Image Query):关注图像特征,用于目标边界框的预测。
- 文本查询(Text Query):关注文本特征,用于短语的提取和匹配。
2.2 查询共享位置部分
- 图像查询和文本查询共享相同的 位置部分,确保两者专注于同一目标的图像区域和对应的短语位置。
- 图像位置部分:Anchor Boxes,定义图像中的候选目标区域。
- 文本位置部分:文本掩码,定义候选短语在句子中的位置范围。
2.3 查询内容独立
- 查询的内容部分分开设计,使得每种查询可以专注于各自的任务:
- 图像查询内容部分:学习视觉特征,进行边界框回归。
- 文本查询内容部分:学习文本语义特征,进行短语提取和匹配。
3.文本掩码引导注意力
首先我们来说一下为什么需要文本掩码引导注意力?
(1)短语提取的挑战
- 短语提取的目标:从输入文本中定位出描述图像目标的短语(如 “a cat” 或 “two balls”)。
- 文本中的信息往往冗杂,只有一部分短语与目标有关,而其他内容可能是无关的。
- 如果没有掩码约束,模型的注意力可能分散在整个文本上,导致短语提取不够准确。
(2) 动态优化需求
- 每一层解码器的输出都会更新预测结果,因此需要一种机制将这些预测反馈到下一层,逐步优化模型对文本的关注。
文本掩码引导注意力 是 DQ-DETR 模型中的一个逐层动态引导机制,通过限制解码器的注意力分布,帮助模型在解码过程中引导 文本查询(Text Queries) 聚焦于文本中与目标相关的短语位置。这种机制通过动态生成和更新 文本二值掩码(标记相关位置为“1”,无关位置为“0”),逐层限制注意力范围,使模型逐步聚焦于关键短语,提高短语提取和匹配的精度。
可以将文本掩码引导注意力理解为一种“动态高亮标记”机制:
- 初始状态:所有文本都是高亮的(全“1”掩码),允许查询关注整个文本。
- 逐层更新:随着每一层解码器的运行,模型逐步筛选出与目标相关的短语,并“熄灭”无关文本的高亮(将掩码置为“0”)。
- 最终输出:最终,只有与图像目标对应的短语被高亮并输出,表示提取的目标短语。
短语定位中的 1D 分割方式需要一个文本 mask 引导的注意力机制,使得 queries 关注到感兴趣的短语 tokens,类似Mask2Former 中的 mask 注意力。每个文本 query 中包含一个文本位置查询,本质是一个与文本特征相同长度的二值 mask。相应地使用编码器输出的图文拼接特征作为跨模态注意力的 keys 和 values。二值化 masks 用于拼接文本特征后的注意力 mask。如果文本特征对应的 mask 值存在,则采用,否则 mask 掉。而预测的 mask 将进行逐层更新来接近 GT masks。所有的 masks 作为第一解码器层的输入,其他层利用前一层的预测 masks,最终更新的 mask 为短语定位的输出。
4.损失函数
查询匹配策略
在计算损失之前,模型使用 匈牙利算法(Hungarian Matching)将预测的查询(包括图像查询和文本查询)与真实目标进行一一匹配:根据 双 IOU(Dual IOU),综合边界框和短语掩码的匹配程度选择最优匹配。

最终的损失函数可以分为图像的框损失和文本的短语损失。我们使用L1损失和GIOU损失进行边界盒回归。对于短语定位,我们使用对比softmax损失。
模型的整体损失函数是 边界框损失 和 短语匹配损失 的加权和:
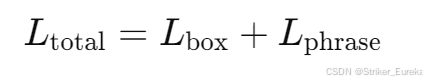
边界框损失公式如下:
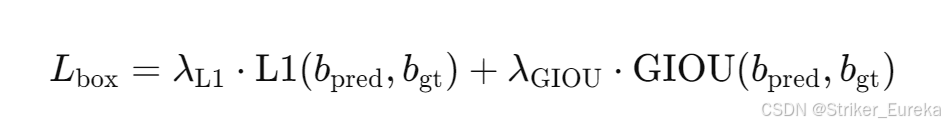
和
分别为预测框和真实框的坐标。
短语匹配损失 公式如下:
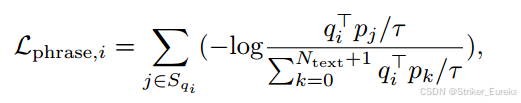
公式含义:
:第i个文本查询的特征向量。
:真实短语对应的文本特征。
:第i个查询匹配的真实短语索引集合。
:温度参数,用于调整预测分布的平滑程度,实验设为 0.07 。
:文本特征数量(包括无匹配短语的“无短语”特征)。
六. 实验结果
使用MDETR 作为基线,我们的模型在Flickr30k实体上的表现优于MDETR,只需要一半的训练epoch。它比MDETR的CMAP50高出5.8,证明了图像和文本查询解耦的有效性。

同时在官方给出的示例中,可以看到检测的效果非常的好,例如在下面的第一张图中只检测出了caption中对应的上面的猫,由此可以看出模型对语言的理解非常不错。



Flickr30k实体的短语接地任务结果:
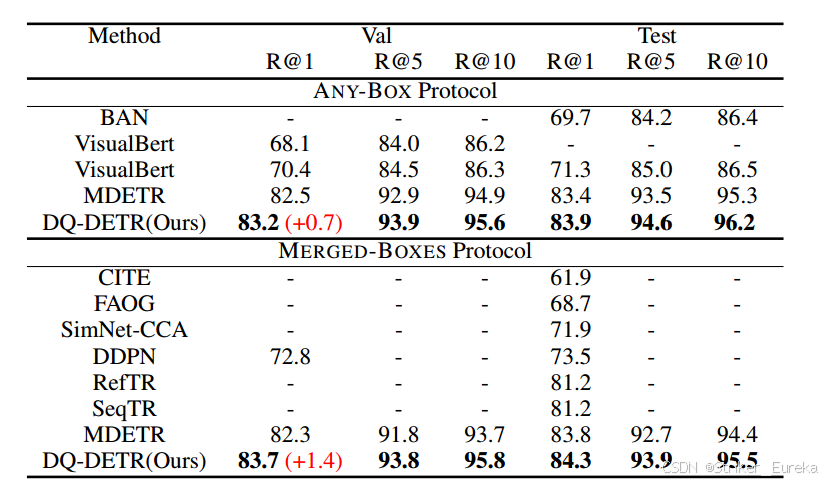
其他任务结果大家可以去查看原论文: DQ-DETR: Dual Query Detection Transformer for Phrase Extraction and Grounding

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 33
33 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)