【机器学习实战】对加州住房价格数据集进行数据探索(读书笔记)
·
1. 数据集描述及获取
- 数据集下载地址:housing.csv
- 数据集的结构:
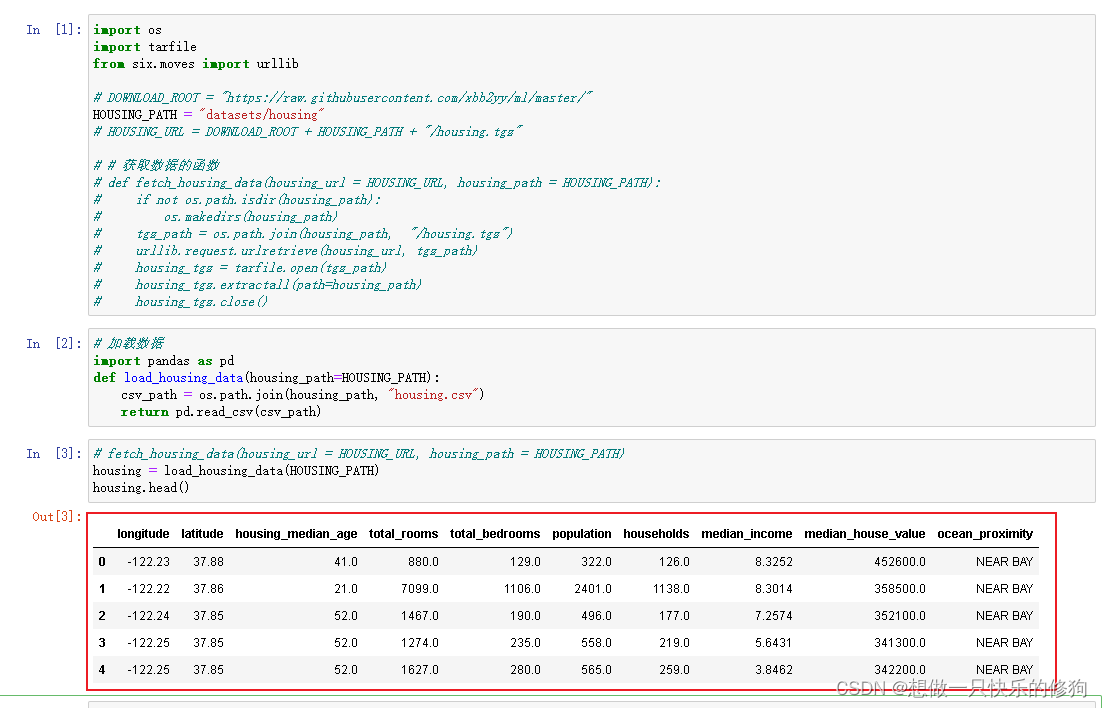
其中数据集有10个属性,分别为经度、纬度、housing_median_age、房间总数、卧室总数、人口数、家庭数、收入中位数、房价中位数、ocean_proximity。
2. 对数据集进行探索
2.1 获取数据集的简单描述
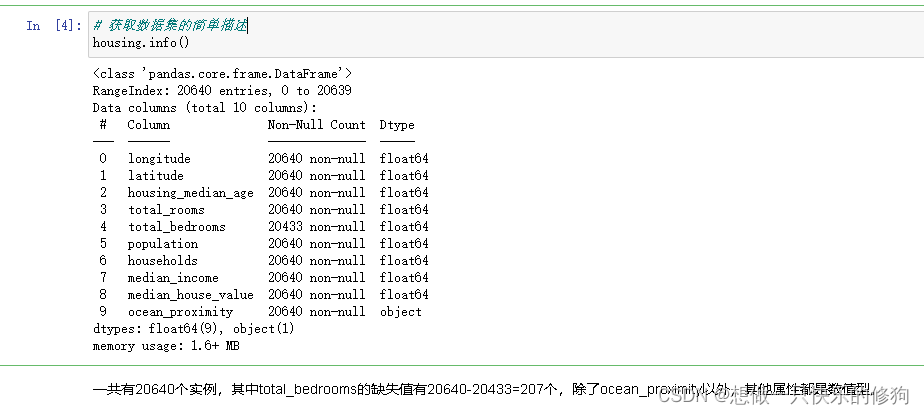 一共有20640个实例,其中total_bedrooms的缺失值有20640-20433=207个,除了ocean_proximity以外,其他属性都是数值型。
一共有20640个实例,其中total_bedrooms的缺失值有20640-20433=207个,除了ocean_proximity以外,其他属性都是数值型。
2.2 查看ocean_proximity有多少种分类存在

2.3 显示数值属性的摘要
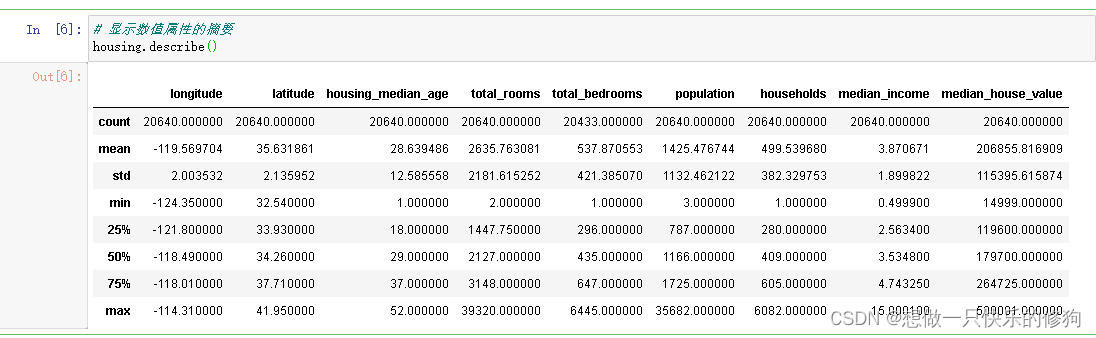
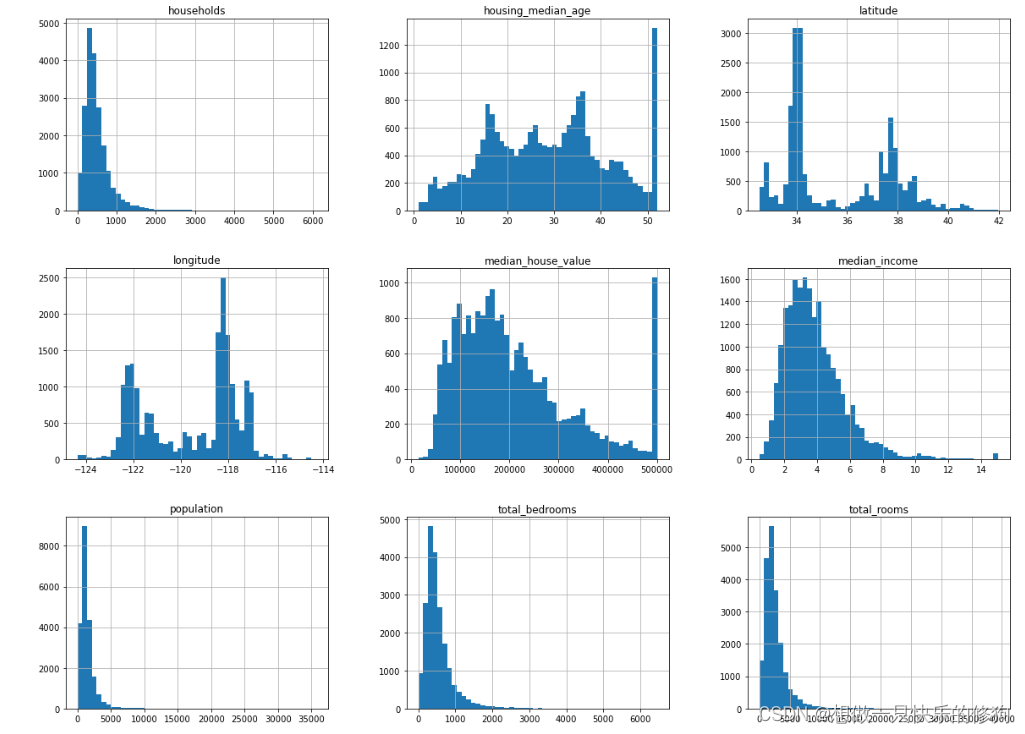
2.4 绘制所有数值属性的直方图
# 绘制所有数值属性的直方图
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20, 15))
plt.show()
3. 划分数据集(分层抽样)
# 分层抽样
import numpy as np
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
start_train_set = housing.loc[train_index]
start_test_set = housing.loc[test_index]
housing["income_cat"].value_counts() / len(housing)
整个数据集的分布: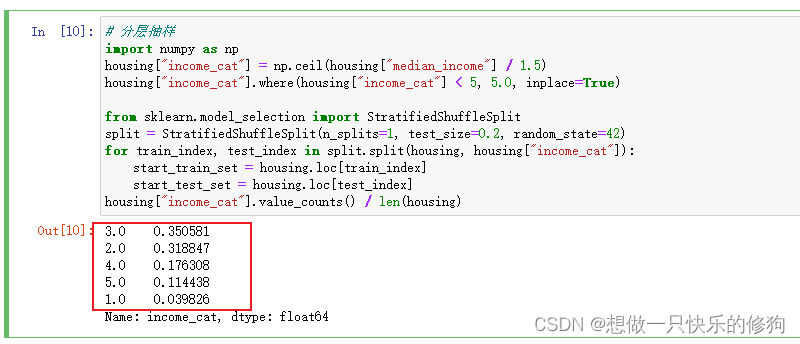
分层采样完测试集的分布:
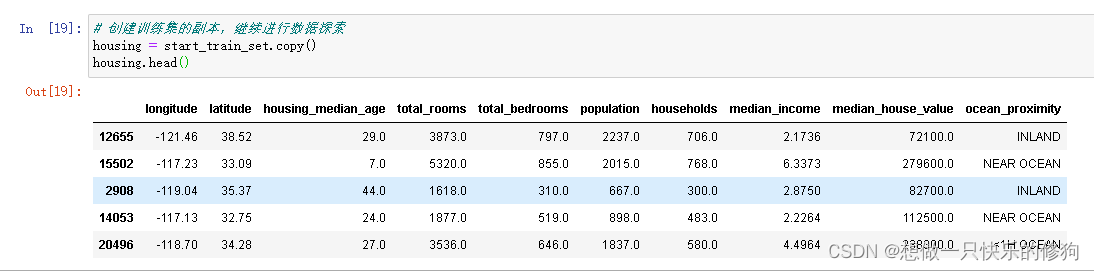
4. 创建训练集的副本,继续进行数据探索
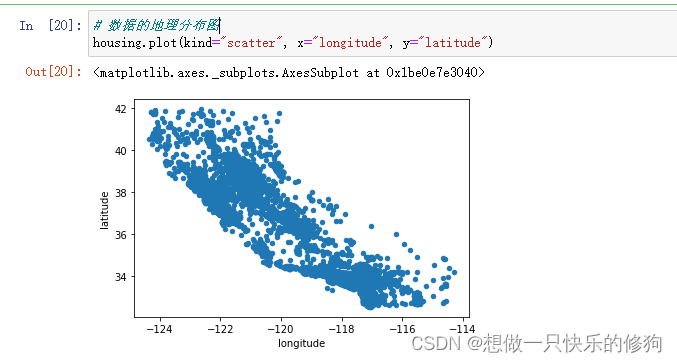
4.1 数据的地理分布图
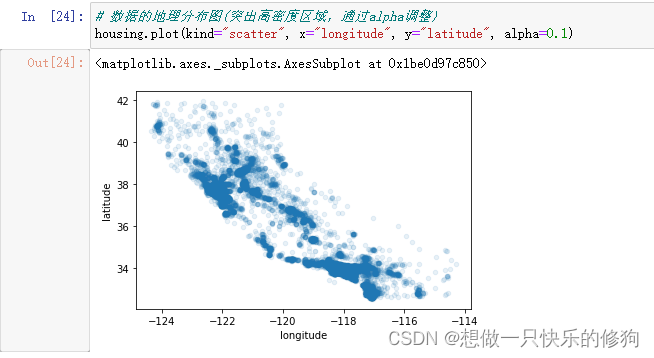
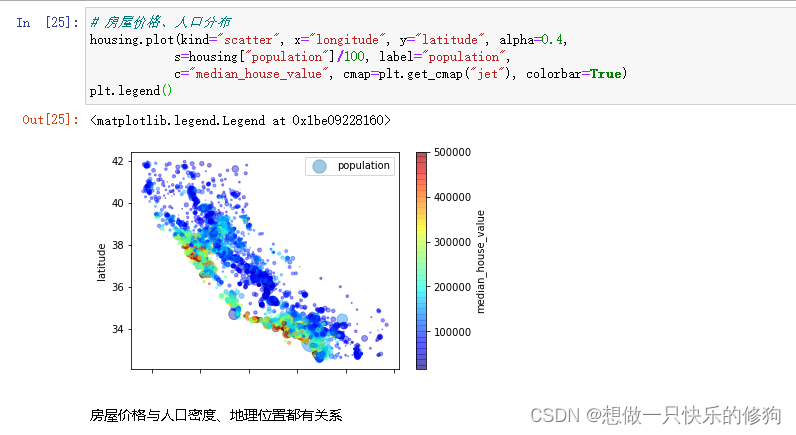
4.2 房屋价格、人口分布
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True)
plt.legend()
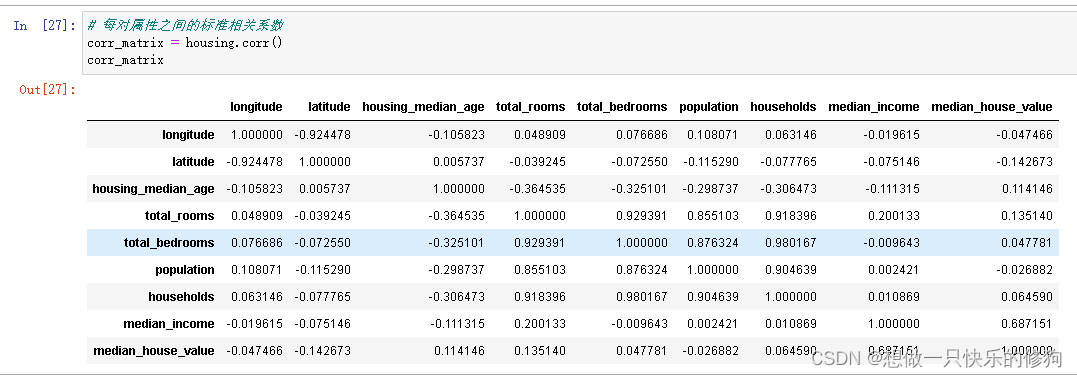
4.3 属性相关性探索
4.3.1 所有属性的
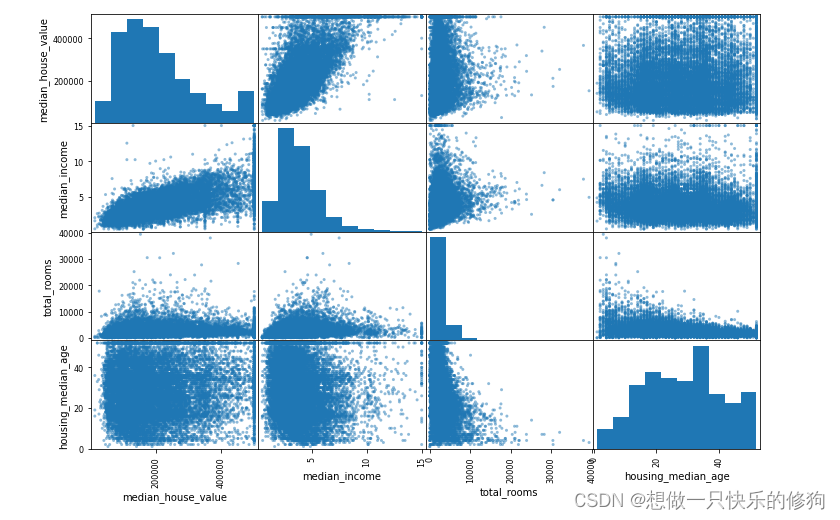
4.3.2 每个属性和median_house_value的相关性(降序)

# 绘制每个数值属性相对于其他数值属性的相关性(取相关性前4个)
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
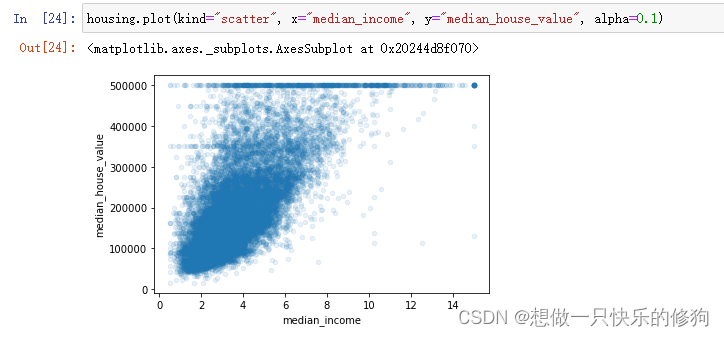
- 最有潜力预测房价中位数的属性是:median_income
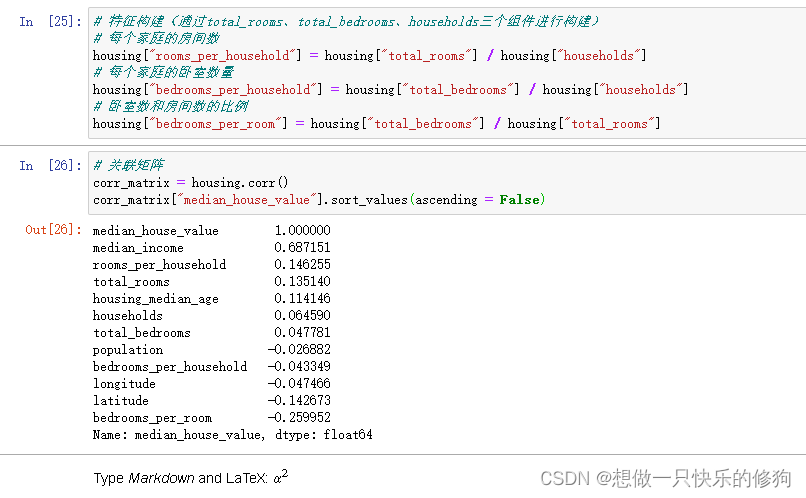
5. 特征构建
# 特征构建(通过total_rooms、total_bedrooms、households三个组件进行构建)
# 每个家庭的房间数
housing["rooms_per_household"] = housing["total_rooms"] / housing["households"]
# 每个家庭的卧室数量
housing["bedrooms_per_household"] = housing["total_bedrooms"] / housing["households"]
# 卧室数和房间数的比例
housing["bedrooms_per_room"] = housing["total_bedrooms"] / housing["total_rooms"]
# 关联矩阵
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending = False)
P.S.这是我看《机器学习实战:基于Scikit-Learn和TensorFlow》的读书笔记,代码都是跟着书上一步步自己敲得,如果需要代码,可以私信我。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)