计算机毕业设计之基于Spark的图书销售数据分析与可视化实现
摘要
本研究旨在基于Spark技术,实现图书销售数据的深入分析与可视化展示。随着大数据时代的到来,图书销售数据呈现出海量、复杂的特点,传统分析方法难以满足需求。Spark作为高效的大规模数据计算引擎,为本研究提供了强大的技术支持。本研究首先构建了高效的数据处理流程,利用Spark的分布式计算能力,实现了对海量图书销售数据的快速清洗、整合和分析。
系统运用数据分析方法,对图书销售数据进行了多维度、深层次的挖掘,揭示了市场规律和潜在价值。在数据可视化方面,设计并实现了一个功能完善、交互友好的数据可视化面板,通过直观的图表和图形展示数据分析结果,为用户提供了便捷的数据洞察方式。本研究提升了图书销售企业的数据分析和决策能力,为其他类似行业提供了借鉴。然而,仍存在部分分析方法优化和可视化效果提升等不足,未来将继续深化研究。,具有显著的理论意义和实践价值,推动了大数据技术在图书销售领
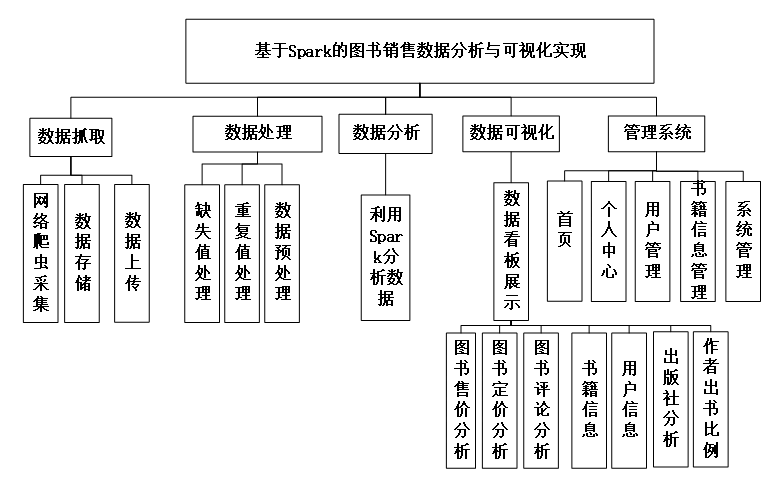
功能需求分析
系统使用收集图书的图书售价分析,图书定价分析,图书评论分析,书籍信息,用户信息,出版社分析,作者分析,作者出书比例等行为数据的公开数据集,来构建图书的数据分析。用户可以通过查询条件的方式,让系统实现对相关数据的筛选和查询,并将查询结果在前端以图表的可视化方式展示出来,进而帮助用户理解数据。
系统通过对用户数据的分析与挖掘,实现了对于图书信息的解析和分类,系统提供了直观的当当网图书数据展示界面,查看到相应的分析结果。数据采集功能实现对当当网平台公共数据的采集,识别数据来源、区分数据类型,并进行数据完整性的验证,确保数据的准确性以及可靠性。分布式存储功能实现对已经处理过的数据进行分布式存储,采用MySQL、HDFS进行对数据的存储,以及支持异构端存储和具备高容错性,高可用性以及易扩展性。
数据分析功能基于Spark分布式计算框架,实现对存储的数据进行了数据分析和挖掘。数据可视化功能使用ECharts、Vue、BootStrap等前端技术,对数据分析结果进行了可视化展示,以图表等可视化方式将数据展示,方便了用户分析和观察。域的应用,为企业发展注入了新活力。
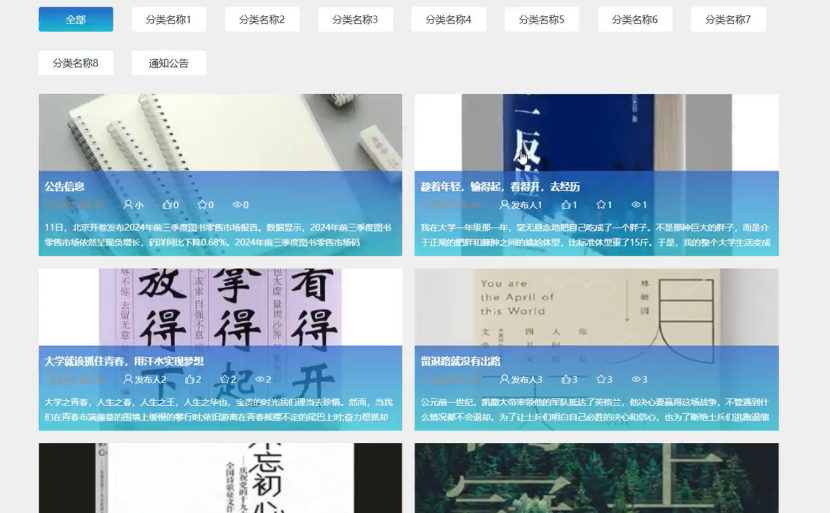
用户在图书资讯模块可以查看到系统展示的所有资讯信息详情,可以通过分类来对资讯信息进行筛选,点击资讯信息详情,可以对资讯信息进行点赞和收藏的操作。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)