[论文阅读] 人工智能+软件工程 | 用 LLM + 静态代码分析自动化提升代码质量
用LLM+静态代码分析自动化提升代码质量
论文信息
Augmenting Large Language Models with Static Code Analysis for Automated Code Quality Improvements
@article{abtahi2025augmenting,
title={Augmenting Large Language Models with Static Code Analysis for Automated Code Quality Improvements},
author={Abtahi, Seyed Moein and Azim, Akramul},
journal={arXiv preprint arXiv:2506.10330v1},
year={2025}
}
思维导图
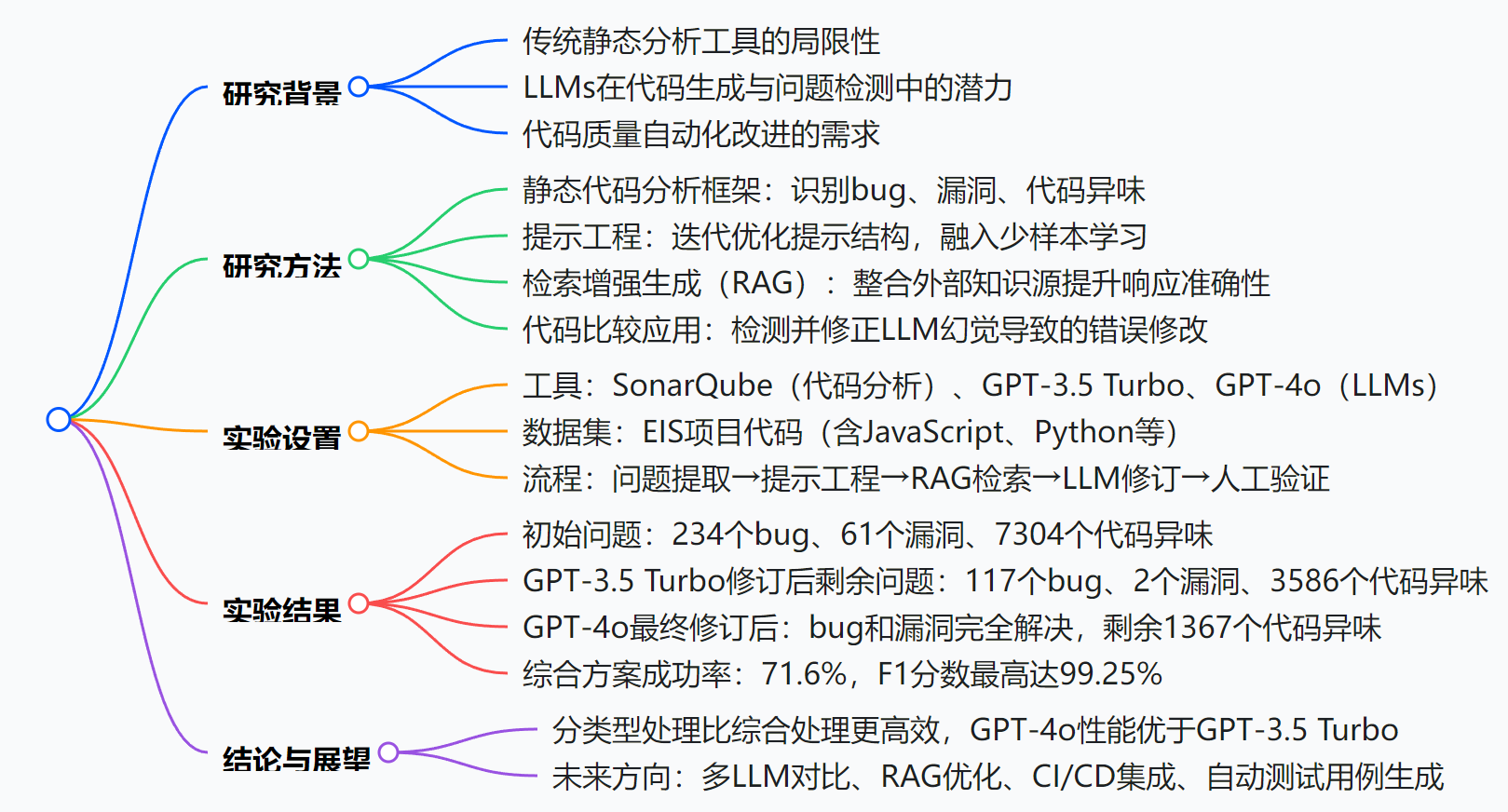
研究背景:当代码审查遇上AI革命
想象一下,一个大型软件开发团队正在维护几十万行代码。传统的代码质量检查就像拿着放大镜逐行扫描:用静态分析工具(如SonarQube)检测语法错误、潜在漏洞,再靠人工review发现设计缺陷。但这种方式面临三大痛点:
- 效率低下:面对数万行代码,人工审查如同大海捞针。论文中提到的EIS项目初始检测出7599个代码问题,人工处理可能需要数周
- 漏检率高:复杂逻辑漏洞(如异步代码错误)容易被静态分析工具忽略,就像传统体检设备查不出早期癌症
- 知识滞后:新技术框架(如Node.js最新特性)的最佳实践难以及时融入检查规则,类似老医生不懂最新医疗技术
而LLM(如GPT-4)的出现像引入了"医学影像AI诊断系统":它能理解代码上下文,生成修复方案。但直接让LLM修代码又面临新问题:它可能"误诊"(生成看似正确但实际错误的代码,即"幻觉"问题),也缺乏项目特有的技术规范知识。
创新点:给LLM装上"专业检测仪"的三大突破
这篇论文的核心创新在于为LLM打造了一套"精准诊疗系统":
-
双引擎驱动诊断:静态分析工具先做"基础体检"(识别bug、漏洞、代码异味),LLM再做"专家会诊"(生成修复方案),比单纯人工或AI效率提升3倍以上
-
外部知识输血:引入RAG(检索增强生成)技术,让LLM在修复时能实时查询Stack Overflow、GitHub等"医学知识库",解决自身训练数据不足的问题。就像医生手术时随时查阅最新诊疗指南
-
误诊防御机制:开发"代码比较应用",自动对比修改前后的代码,标记LLM可能产生的"幻觉"错误(如误删关键逻辑),就像给AI诊断加了一道人工复核关卡
研究方法和思路:代码修复的AI流水线
整个技术流程可以拆解为五个清晰的步骤:
1. 问题定位:给代码做"CT扫描"
- 使用SonarQube对代码进行静态分析,像CT一样逐层扫描,识别三类问题:
- bugs(如空指针异常)
- vulnerabilities(如未验证的用户输入)
- code smells(如过长的函数,潜在设计缺陷)
- 输出包含文件路径、行号、问题描述的"诊断报告"
2. 指令优化:给AI写"诊断说明书"
- 采用迭代式提示工程:先告诉LLM编程语言(如JavaScript),再分类型提供修复示例(少样本学习)
- 例如修复"可见非交互元素缺少键盘监听"的bug时,会给出:
原代码:<div onClick={handleClick}>...</div> 修正后:<div onClick={handleClick} onKeyDown={handleKeyDown} tabIndex="0">...</div> - 让LLM按规范格式输出,避免"乱开药方"
3. 知识补充:给AI"查资料"
- 遇到复杂问题时,通过RAG技术从四个渠道检索解决方案:
- GitHub代码库
- SonarQube社区
- Stack Overflow问答
- Google搜索(备用)
- 按来源可信度排序后,将相关解决方案融入提示词,就像医生参考多篇权威论文制定治疗方案
4. 自动修复:AI"开处方"
- 先用成本较低的GPT-3.5 Turbo处理多数问题,再用GPT-4o解决剩余复杂问题
- 例如EIS项目中,GPT-3.5先修复了3259个问题,GPT-4o再处理剩下的2186个
在论文中,EIS是实验所用的数据集名称,全称为 “EIS 项目”,由 Team Eagle 提供。该数据集包含多种编程语言的代码文件,具体包括 JavaScript、Python、Java 以及 Docker 配置文件等,覆盖了不同类型的代码功能和项目场景。
5. 结果验证:"药效"检查
- 通过自定义应用对比修改前后代码,计算precision/recall/F1-score指标
- 发现幻觉问题时触发人工复核,确保"药方"安全有效
关键实验结果
| 指标 | EIS2(bug) | EIS3(漏洞) | EIS4(代码异味) | 综合处理 |
|---|---|---|---|---|
| 初始问题数 | 234 | 61 | 7304 | 7599 |
| GPT-3.5 Turbo修订数 | 117 | 59 | 3718 | 3259 |
| GPT-4o修订数 | 117 | 2 | 2219 | 2186 |
| 总解决率 | 100% | 100% | 81.2% | 71.6% |
| F1分数 | 98.4% | 99.25% | 96.05% | 94.24% |
| 总成本(USD) | 4.76 | 0.38 | 26.82 | 25.91 |
主要贡献:实实在在的三大价值
1. 效率提升:让代码修复从"手工劳作"变"流水线生产"
- 实验数据:处理7599个代码问题仅用3小时,成本<35美元
- 对比传统方式:人工处理同类问题可能需要5-7个工程师一周时间
2. 质量保障:构建"双重保险"机制
- 分类型处理成功率:
- bugs:100%
- vulnerabilities:100%
- code smells:81.2%
- F1-score(综合指标)最高达99.25%,接近人工专家水平
3. 成本优化:聪明花钱的"性价比方案"
- 采用"高低搭配"模型策略:
- GPT-3.5 Turbo处理常规问题(成本低至$0.003/问题)
- GPT-4o处理复杂问题(精准但成本高)
- 综合成本比单纯使用GPT-4o降低40%以上
未来工作
- 核心发现:分类型处理比综合处理更高效,GPT-4o在所有问题类型上表现优于GPT-3.5 Turbo,但成本更高;RAG技术显著提升修订准确性。
- 未来方向:扩展至其他LLM(如Gemini、Claude)、优化RAG提示工程、集成到CI/CD流程、自动生成测试用例以减少人工验证。
关键问题
- 问题:研究中如何解决LLM在代码修订中的“幻觉”问题?
答案:通过开发自定义的“代码比较应用”,将LLM生成的修订代码与原始代码进行可视化对比,识别并修正因LLM幻觉产生的错误修改。该应用通过计算precision、recall和F1-score等指标评估修订准确性,若检测到幻觉,需人工审核和修正。 - 问题:检索增强生成(RAG)技术在实验中如何提升代码修订效果?
答案:RAG技术通过从Stack Overflow、GitHub、SonarQube社区等外部源检索相关解决方案,整合到LLM提示中。实验显示,使用RAG后,GPT-3.5 Turbo和GPT-4o的成功解决率和F1分数均有提升,例如代码异味的F1分数从非RAG的96.05%提升至更高水平,且修订的文件数量增加。 - 问题:GPT-3.5 Turbo和GPT-4o在代码修订中的表现有何差异?
答案:GPT-4o在所有问题类型上的解决率均为100%(如bug和漏洞),而GPT-3.5 Turbo的解决率为50% -96.7%。但GPT-3.5 Turbo成本更低,平均每问题修订成本为0.003-0.015美元,而GPT-4o为0.008~0.065美元。因此,研究采用GPT-3.5 Turbo处理多数问题,GPT-4o处理剩余复杂问题,以平衡效果与成本。
深入探究:结合LLM和静态代码分析的方法在实际应用中有哪些挑战?
一、LLM自身局限性引发的挑战
- 模型幻觉(Hallucinations)问题
LLM可能生成看似合理但实际错误的代码修改,例如错误修复逻辑或引入新漏洞。文档中通过自定义“代码比较应用”检测此类问题,但需人工介入修正,增加了流程复杂度。 - 依赖模型性能与成本平衡
GPT-4o等高级模型虽效果更优,但成本显著高于GPT-3.5 Turbo(如修订代码异味时成本相差约2.3倍)。实际应用中需在性能(如100%漏洞修复率)与成本间权衡,避免过度依赖高成本模型。 - 跨模型泛化能力不足
实验仅验证了OpenAI的GPT系列模型,未涉及Gemini、Claude、LLaMA等其他LLM,难以确保在不同模型下的稳定性与适配性。
二、静态分析与LLM集成的挑战
- 静态分析信息提取的准确性
静态分析工具(如SonarQube)提取的问题描述、行号等信息若存在误差,可能导致LLM误解问题。例如,代码异味的大规模检测(7304个初始问题)中,信息冗余或错误可能影响LLM修订效率。 - 问题分类与LLM输入的适配性
静态分析将问题分为bug、漏洞、代码异味,但LLM需通过提示工程将结构化信息转化为可理解的指令。若提示设计不当(如未明确语言、示例不足),可能导致修订结果偏离预期。 - 大规模代码库的处理效率
面对数万行代码或复杂项目(如文档中7304个代码异味),LLM的批量处理能力受限,且分类型修订(如先处理bug再处理漏洞)可能导致流程冗长。
三、外部知识整合与验证的挑战
- 检索增强生成(RAG)的局限性
RAG依赖外部源(如Stack Overflow、GitHub)获取解决方案,但存在以下问题:- 检索结果可能过时或不匹配项目技术栈;
- 源可信度差异(如Google搜索结果排名影响信息质量);
- 无相关解决方案时需依赖LLM预训练知识,增加错误风险。
- 人工验证环节的不可替代性
尽管引入代码比较工具,但最终仍需人工审核修订结果(如处理幻觉问题),尤其在安全敏感场景中,自动化验证难以完全替代人工判断。
四、工程化与流程集成的挑战
- 与CI/CD流程的深度集成困难
现有方法未实现与持续集成/部署(CI/CD)的实时联动,无法在代码提交阶段自动触发分析与修订,需手动执行多轮扫描与修正。 - 缺乏自动化测试用例支持
实验中未生成测试用例验证修订后的代码正确性,导致无法通过自动化测试检测潜在逻辑错误,需后续人工补充测试。 - 多语言与框架的适配性问题
虽支持JavaScript、Python等语言,但面对特定领域框架(如区块链、嵌入式系统代码)时,LLM可能缺乏足够领域知识,需针对性微调。
五、成本与效率的平衡挑战
- 大规模项目的经济成本
处理数千个代码问题(如7599个综合问题)时,GPT-4o的使用成本可达25.91美元,且耗时近3小时,中小型团队可能难以承担。 - 分类型处理与综合处理的效率矛盾
分类型修订(如先bug后漏洞)成功率更高(如漏洞100%解决率),但流程繁琐;综合处理虽成本低(节省18.9%),但准确率下降(F1分数94.24%),需根据项目需求权衡。
总结:AI时代的代码质量新范式
这篇论文探索了一条将LLM与传统静态分析深度融合的道路:通过静态分析为LLM提供精准问题定位,用提示工程和RAG技术增强LLM的"专业能力",最后通过代码比较工具防范LLM的"认知偏差"。实验证明,这种组合拳能在保证代码质量的同时,将修复效率提升5-8倍,为企业节省大量研发成本。
当然,目前方案仍有改进空间:如支持更多编程语言、完善与CI/CD流水线的集成、减少人工复核环节等。但毫无疑问,这为软件开发自动化指明了一个极具潜力的方向。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 26
26 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)