传统机器学习-Logistic回归(吴恩达机器学习笔记)
逻辑回归:我们期望得到值域在[0,1]之间的预测值。逻辑回归天然的是用来处理二分类的情况的,至于多分类的情况会要稍微处理一下。在逻辑回归中,我们通常将正例的标签标为1,负例的标签标为0。逻辑回归的输出值(即预测值),表示的是预测为正例(即标签为1)的概率。
目录
模型定义
若将y视为样本作为正例的可能性,则1-y就是其反例的可能性,两者比值
称为“几率”,反映了
作为正例的相对可能性,对几率取对数则得到“对数几率”
。我们用线性回归来拟合对数几率,即
。
,可以令:
,
,此时
又可以写成
。
,其中g(z)又被称为sigmoid函数。
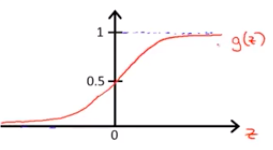
对该模型的解释,
预测的是对每一个样本得到标签是1(即正例)的概率。

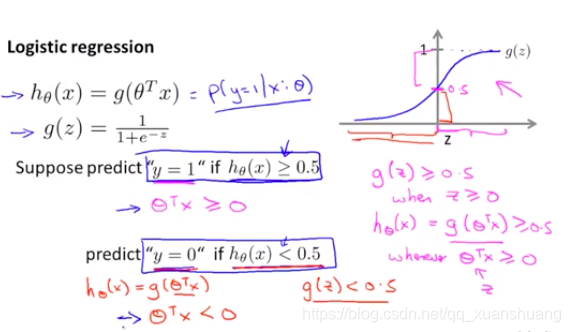
决策边界:是假设函数及其参数的属性,不是训练集的属性。用训练集拟合参数,参数一旦确定,决策边界即确定。


模型定义有了之后,我们要做的就是通过训练集来得到一组合适的参数。
损失函数

若在Logistic回归中采用线性回归的损失函数(平方和函数)作为损失函数,由于sigmoid函数是一个复杂的非线性函数,则会导致损失函数非凸,会产生很多局部最小值,这会使梯度下降法不易找到全局最小值。我们期待选择一个凸函数作为损失函数。同时我们期待标签与预测值相差较大时损失函数较大,当标签与预测值相近时,损失函数较小,即我们期待:
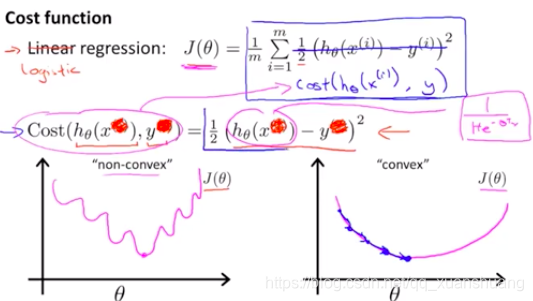
Logistic回归的损失函数
,其中
对该损失函数的直观解释如下,其中y是真实标签,是预测值。
- 当样本是正例,即y=1时,此时代价函数为
- 若预测值接近1,则
- 若预测值接近0,则
- 若预测值接近1,则
- 当样本时负例,即y=0时,,此时代价函数为
- 若预测值接近1,则
- 若预测值接近0,则
- 若预测值接近1,则

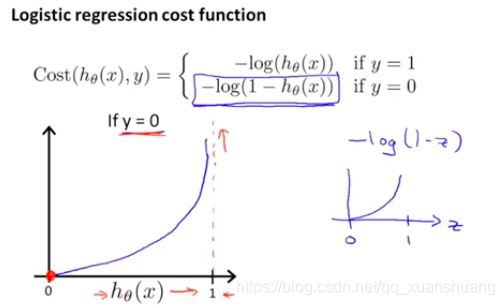
我们之前的代价函数是分正例和负例两种情况给出的,由于数据集中y非0即1,我们可以把代价函数直接用一个简化版的表达式表示,这样也方便后续实施梯度下降法,Logistic函数中的这个代价函数的理论依据是极大似然法,且这个代价函数是凸函数,可以放心使用。此时可以看出若y=1是下面表达式的第一部分,y=0是下面表达式的第二部分。
我们用极大似然估计来推导一下损失函数
1、由于模型定义中
和特征
的情况下,预测值为1(即正例)的概率,固有:
2、将上面两个公式写紧凑成为一个公式
3、求其极大似然函数,需要寻找一组参数,使得给定样本的观测值的概率最大

4、求其对数似然函数

梯度下降法求解参数
目标:
梯度下降法的执行过程
Gradient descent
Repeat{
}(同时更新
)
我们会发现Logistic回归跟线性回归中使用梯度下降算法得到的参数迭代方程形式上是一样的。但是假设函数却不一样!
线性回归:,logistic回归
。
多分类
多项逻辑回归
假设每个样本属于不同标签的概率服从几何分布,使用多项逻辑回归(softmax Regression)来进行分类。
,其中
为模型的参数,而
可以看做是对概率的归一化。一般来说,多项逻辑回归具有参数冗余的特点,即将
同时加减一个向量后预测结果不变,特别的当类别参数为2时,
,利用冗余特性,我们将所有参数减去
则变为
,其中
,整理后的式子与逻辑回归一致。
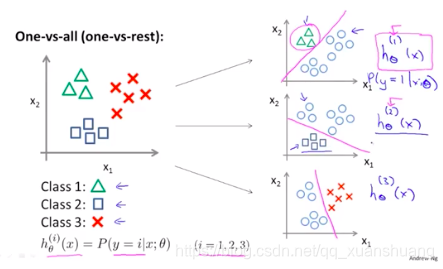
多元分类:一对多
我们可以将一个多分类问题,转换成多个独立的二分类问题,则对于每个独立的二分类问题我们均可以使用逻辑回归。我们为每一个类别i都训练一个逻辑回归分类器,用来预测y=i的概率,在面对一个新样本时,我们取
作为最后的输出。
例如:可以将如下的三分类问题,看成三个独立的二分类问题,从而拟合出三个分类器,来尝试估计给定和
时
的概率。
逻辑回归 VS 线性回归
- 二者都使用了极大似然估计来对训练样本进行建模
- 线性回归使用最小二乘法,实际上就是在自变量x与超参数
确定,因变量y服从正态分布的假设下,使用极大似然估计的一个化简
- 逻辑回归通过对似然函数的学习得到最佳参数
- 线性回归使用最小二乘法,实际上就是在自变量x与超参数
参考:吴恩达的机器学习视频
周志华:机器学习
百面机器学习

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)