机器学习-线性回归
自己做笔记用,后续可能会继续添加内容。
线性回归是一种用于建模和分析变量之间关系的统计方法,尤其适用于连续型目标变量的预测。以下是线性回归的详细介绍:
一、理论部分
1. 基本概念
线性回归假设因变量(目标变量)与一个或多个自变量(特征)之间存在线性关系,通过拟合一条直线(或超平面)来预测因变量的值。
2. 多元线性回归
当有多个自变量时,称为多元线性回归,模型表示为:
-
:多个自变量
-
:各自变量的系数
或者用向量形式表示:
3. 模型评估指标与损失函数
模型评估指标是用于衡量和评价机器学习、数据挖掘等模型性能优劣的量化标准和工具。
线性回归模型通常使用最小二乘法估计,通过最小化残差平方和(SSE,Sum of Squared Errors)来找到最佳拟合线,评估模型的拟合性能:
-
:实际值
-
:预测值
损失函数(Loss Function)是机器学习和统计学中用于衡量模型预测结果与真实结果之间差异的函数。SSELoss的基本计算过程和SSE一致,只不过SSELoss中带入的是模型参数,而SSE带入的是确定参数值之后的计算结果,因此我们也可以认为对于SSELoss和SSE来说,一个是带参数的方程,一个是确定方程参数之后的计算结果。
损失函数与模型评估指标密切相关,但并不完全相同。损失函数主要用于模型训练过程中的参数优化,是模型内部的一个优化目标。而模型评估指标则是在模型训练完成后,用于全面评估模型在不同方面的性能,如准确率、召回率、F1 值等。虽然有些评估指标可能与损失函数有相似的计算原理,但它们的侧重点和应用场景有所不同。例如,在分类问题中,交叉熵损失可以作为模型训练的优化目标,而准确率、召回率等指标则用于评估模型在测试集上的分类效果,帮助人们更直观地了解模型的性能表现。
| 特性 | 损失函数 | 模型评估指标 |
|---|---|---|
| 目的 | 用于模型训练,指导模型进行参数优化。 | 用于模型评估,衡量整体性能。 |
| 使用阶段 | 训练阶段。 | 验证或测试阶段。 |
| 优化目标 | 通常需要可微,便于梯度下降等优化算法。 | 不一定可微,更关注实际业务需求。 |
| 范围 | 通常针对单个样本或小批量样本。 | 针对整个数据集或验证集。 |
| 常见形式 | 连续函数,如均方误差、交叉熵。 | 可以是连续或离散,如准确率、F1分数。 |
| 与业务目标关系 | 不一定直接反映业务目标。 | 通常与业务目标紧密相关。 |
除了SSE以外,常用的回归类问题的评估指标还有MSE(均方误差)和RMSE(均方根误差):
4. 优缺点
优点:
-
简单易实现,计算效率高。
-
结果易于解释。
缺点:
-
对非线性关系建模效果差。
-
对异常值敏感。
-
多重共线性可能导致模型不稳定。
5.补充说明-SSE和RSS
-
SSE 和 RSS(Residual Sum of Squares) 的区别:
-
名称和上下文不同,但公式和本质相同。
-
SSE 更常用于机器学习,RSS 更常用于统计学。
-
-
如何选择:
-
如果你在机器学习领域工作,通常使用 SSE。
-
如果你在统计学领域工作,通常使用 RSS。
-
-
公式:
二、代码部分
需要提前安装SKlearn库和matplotlib库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 生成一些随机数据
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
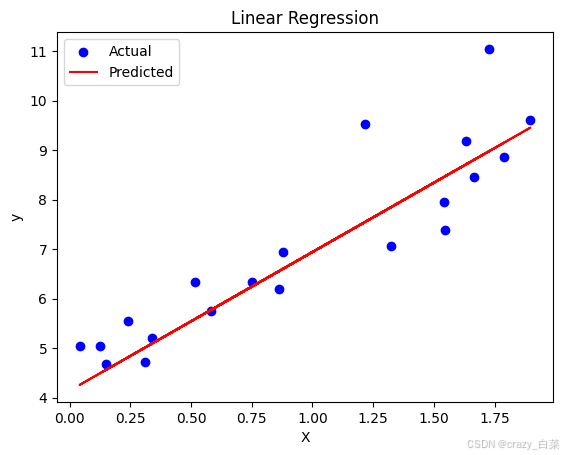
# 可视化结果
plt.scatter(X_test, y_test, color='blue', label='Actual')
plt.plot(X_test, y_pred, color='red', label='Predicted')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Linear Regression')
plt.legend()
plt.show()Mean Squared Error: 0.6536995137170021

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 41
41 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)