Pandas 数据分析入门:从数据结构到实战绘图
前言
在数据科学日益普及的今天,高效地处理、清洗和分析结构化数据已成为一项核心技能。而 Pandas 正是 Python 生态中解决这一需求的不二之选。
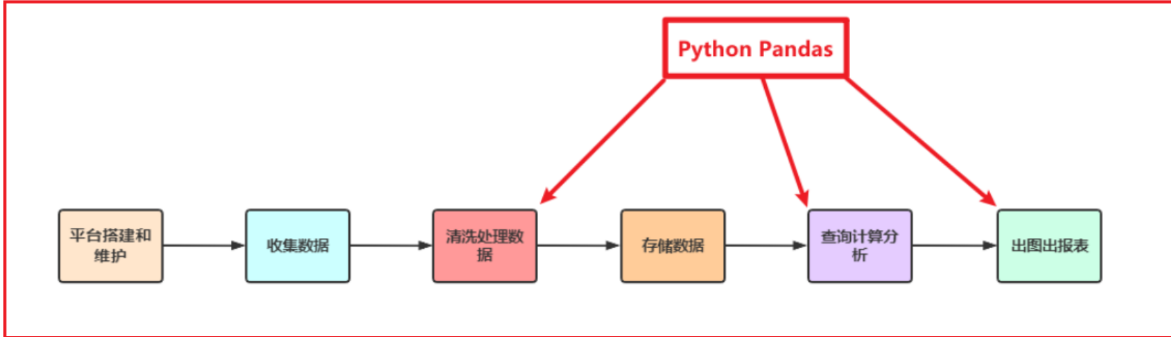
Pandas框架概述
Python在数据处理上独步天下:代码灵活、开发快速;尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势:
- Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析
- Pandas在数据处理上具有独特的优势:
- 底层是基于Numpy构建的,所以运行速度特别的快
- 有专门的处理缺失数据的API
- 强大而灵活的分组、聚合、转换功能
适用场景:
- 数据量大到Excel严重卡顿,且又都是单机数据的时候,我们使用Pandas
- Pandas用于处理单机数据(小数据集(相对于大数据来说))
- 在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用Pandas
Pandas初体验
创建python脚本, 导入pandas库
import pandas as pd
基于pandas加载数据
data = pd.read_csv("./1960-2019全球GDP数据.csv",encoding='gbk')
# 设置显示的最大行数和列数为None
pd.set_option(‘display.max_rows’, None)
pd.set_option(‘display.max_columns’, None)
# 恢复显示的最大行数到默认值
pd.reset_option(‘display.max_rows’) # 恢复显示的最大列数到默认值 pd.reset_option(‘display.max_columns’)
# 恢复所有选项到默认值 pd.reset_option(‘all’)
基于pandas完成相关查询:
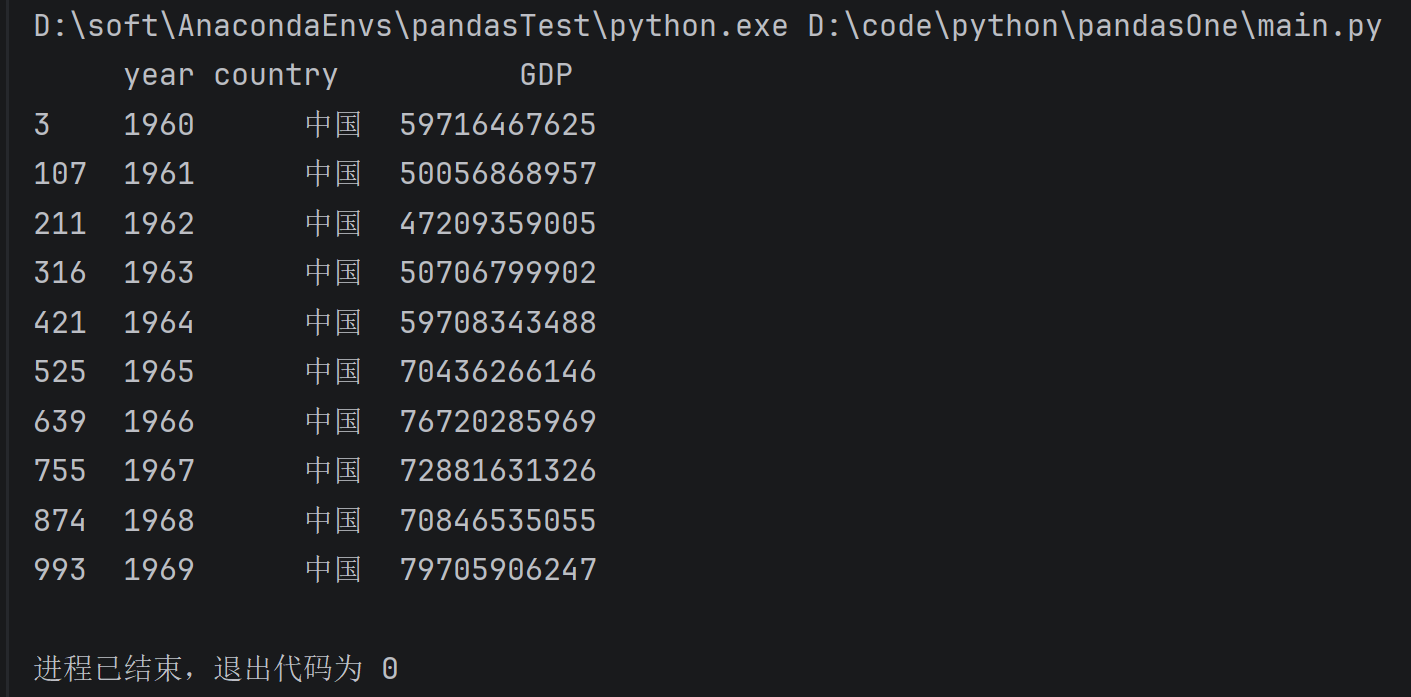
# 查中国的gdp
china_gdp = data[data.country=='中国']
print(china_gdp.head(10))
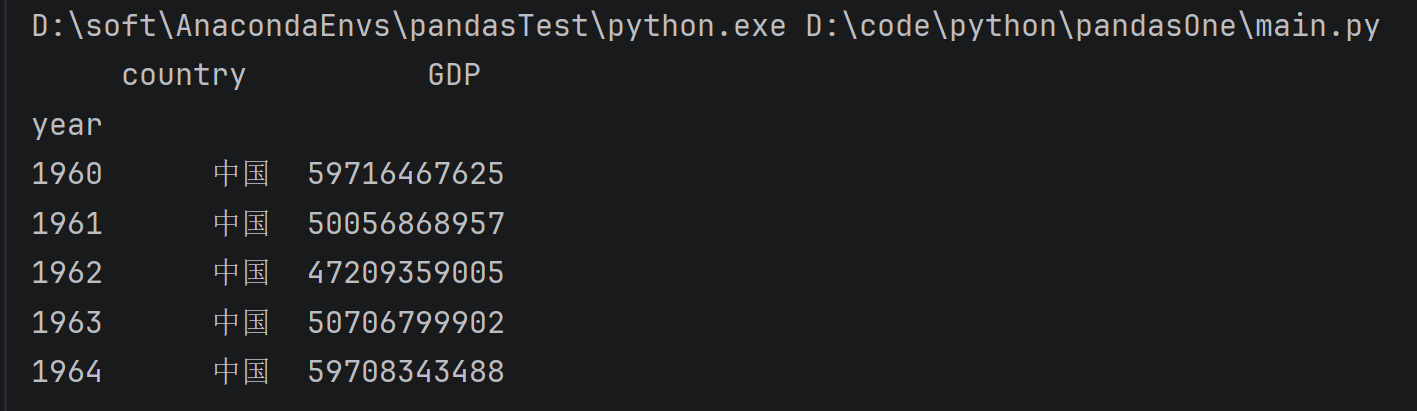
将year年份设置为索引
china_gdp = data[data.country=='中国']
china_gdp = chain_gdp.set_index('year')
print(china_gdp.head(5))
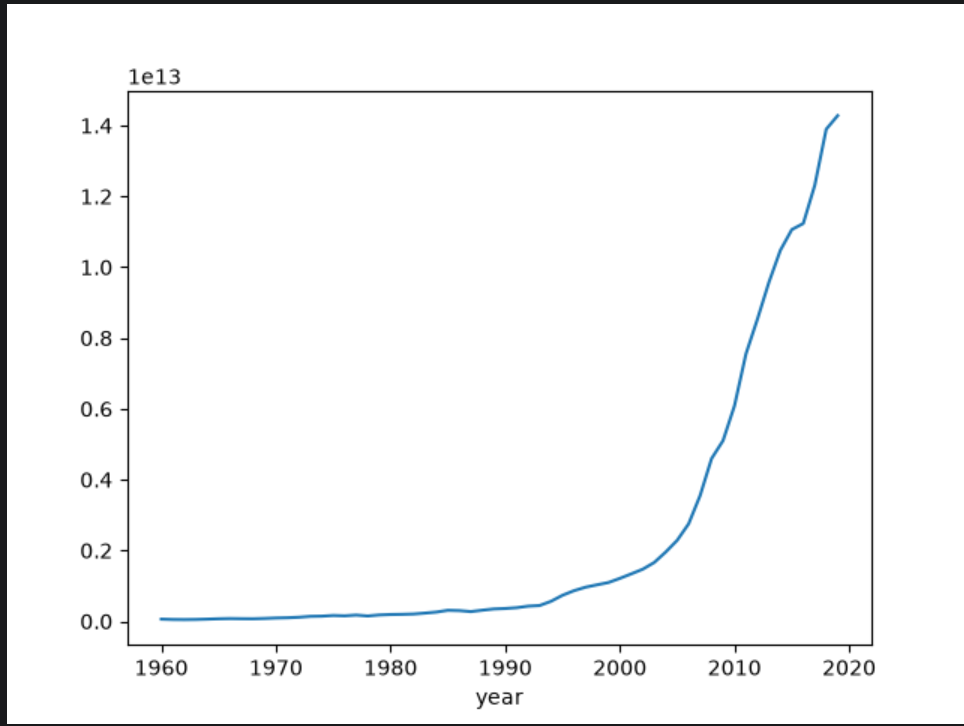
画出GDP逐年变化的曲线图
china_gdp.GDP.plot()
安装了 matplotlib
import matplotlib.pyplot as plt#显示图形
plt.show()
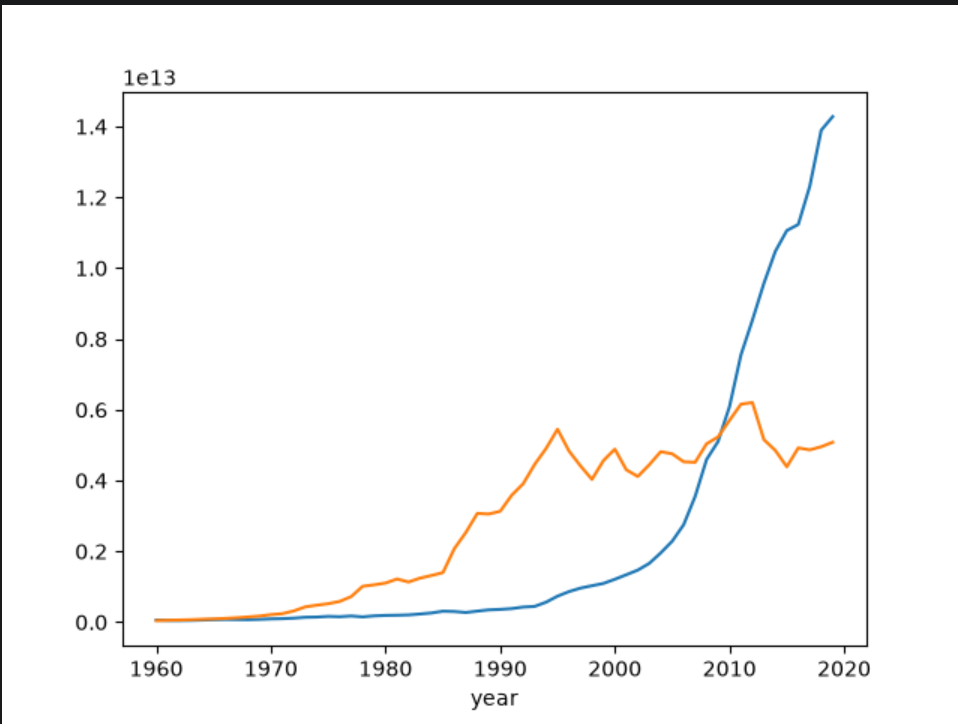
使用同样的方法画出日本的GDP变化曲线,和中国的GDP变化曲线进行对比
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("./1960-2019全球GDP数据.csv",encoding='gbk')
# 查中国的gdp
china_gdp = data[data.country=='中国']
china_gdp = china_gdp.set_index('year')
china_gdp.GDP.plot()
jp_gdp = data[data['country'] == '日本'].set_index('year').sort_index()
jp_gdp.GDP.plot()
plt.show()
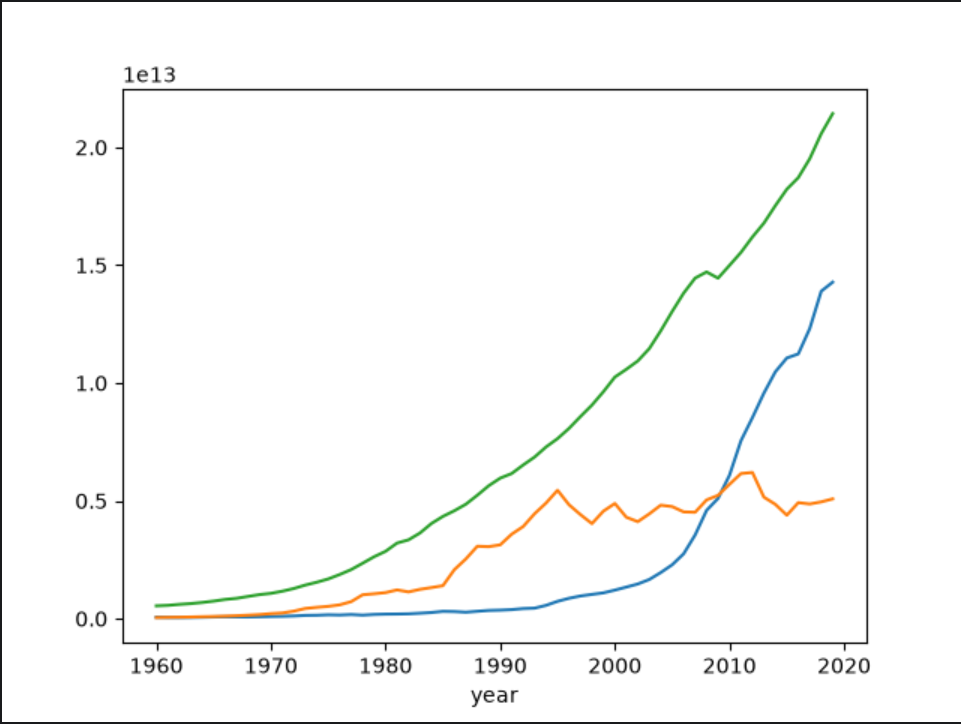
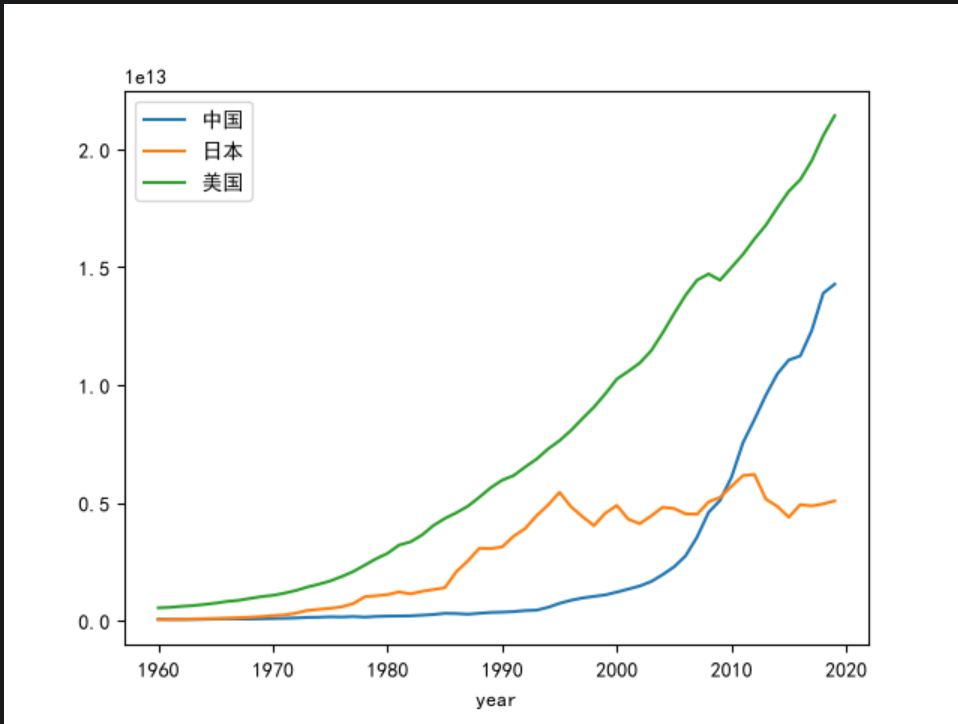
分别查询中国、美国、日本三国的GDP数据,并绘制GDP变化曲线、进行对比
# 查中国的gdp
china_gdp = data[data.country=='中国']
china_gdp = china_gdp.set_index('year').sort_index()
china_gdp.GDP.plot()
jp_gdp = data[data['country'] == '日本'].set_index('year').sort_index()
jp_gdp.GDP.plot()
am_gdp = data[data['country'] == '美国'].set_index('year').sort_index()
am_gdp.GDP.plot()
plt.show()
设置图例
# 按条件选取数据
china_gdp = china_gdp.set_index('year').sort_index()
jp_gdp = data[data['country'] == '日本'].set_index('year').sort_index()
am_gdp = data[data['country'] == '美国'].set_index('year').sort_index()
# 出图并添加图里
china_gdp.GDP.plot(legend=True)
jp_gdp.GDP.plot(legend=True)
am_gdp.GDP.plot(legend=True)
plt.show()
legend=True:告诉 Pandas 在画这张图时,要显示图例(右上角的小方框)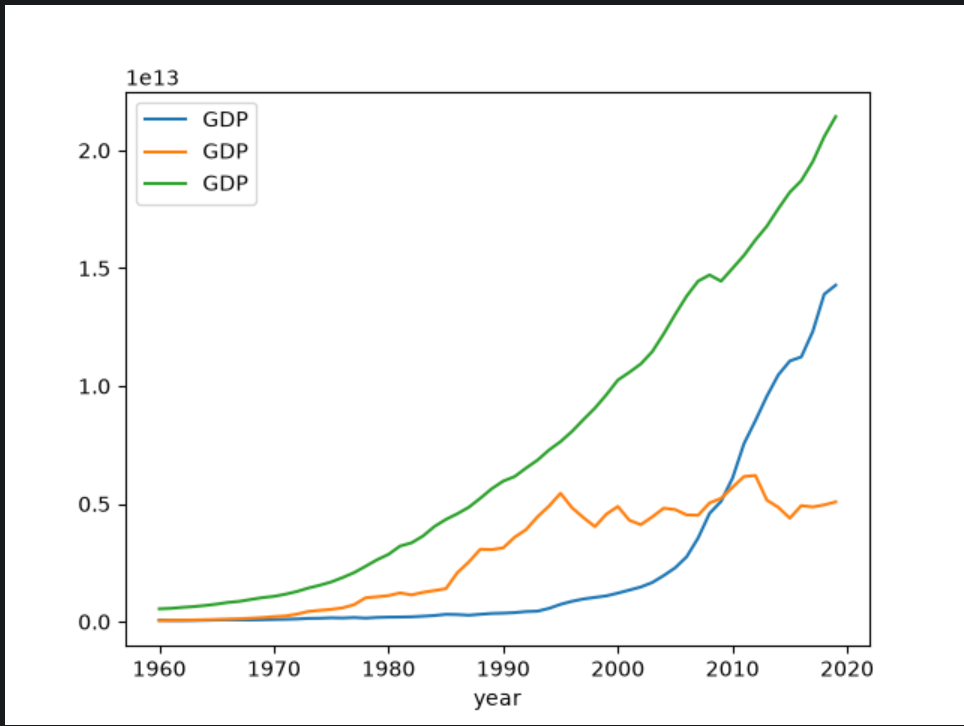
修改列名使图例显示为各国名称
# 按条件选取数据
china_gdp = china_gdp.set_index('year').sort_index()
jp_gdp = data[data['country'] == '日本'].set_index('year').sort_index()
am_gdp = data[data['country'] == '美国'].set_index('year').sort_index()
#对指定列修改列名
china_gdp.rename(columns={'GDP': 'china'},inplace=True)
jp_gdp.rename(columns={'GDP': 'japan'},inplace=True)
am_gdp.rename(columns={'GDP': 'usa'},inplace=True)
# 出图并添加图里
china_gdp.china.plot(legend=True)
jp_gdp.japan.plot(legend=True)
am_gdp.usa.plot(legend=True)
plt.show()
rename:用于修改轴标签(行索引或列名)。
columns={‘GDP’: ‘china’}:告诉 Pandas,把列名从 ‘GDP’ 改为 ‘china’(这是一个字典映射,键是原名,值是新名)。
inplace=True:原地修改。意思是直接在 china_gdp 这个 DataFrame 本体上把列名改掉,不生成新的副本,也不需要用等号赋值。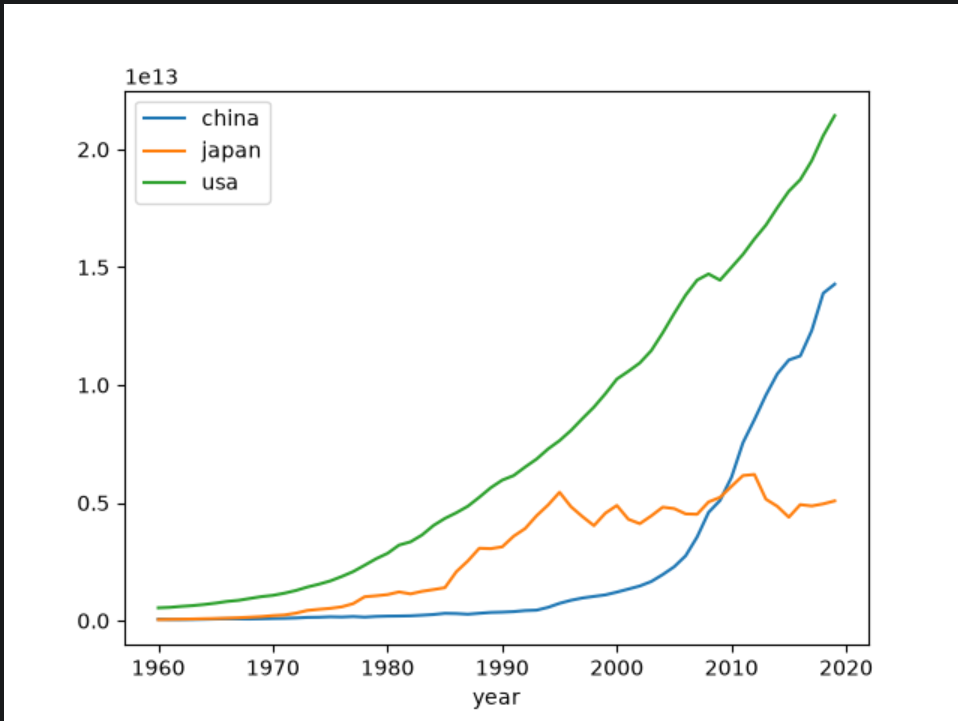
解决中文不能在图表中正常显示的问题
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("./1960-2019全球GDP数据.csv",encoding='gbk')
# 按条件选取数据
china_gdp = data[data.country=='中国'].set_index('year').sort_index()
jp_gdp = data[data['country'] == '日本'].set_index('year').sort_index()
am_gdp = data[data['country'] == '美国'].set_index('year').sort_index()
#对指定列修改列名
china_gdp.rename(columns={'GDP': '中国'},inplace=True)
jp_gdp.rename(columns={'GDP': '日本'},inplace=True)
am_gdp.rename(columns={'GDP': '美国'},inplace=True)
# 出图并添加图里
china_gdp['中国'].plot(legend=True)
jp_gdp['日本'].plot(legend=True)
am_gdp['美国'].plot(legend=True)
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.show()
Pandas数据结构与数据类型

DataFrame
- Series
- 索引列
- 索引名、索引值
- 索引下标、行号
- 数据列
- 列名
- 列值,具体的数据
- 索引列
Series对象
Series也是Pandas中的最基本的数据结构对象,下文中简称s对象;是DataFrame的列对象,series本身也具有索引。
Series是一种类似于一维数组的对象,由下面两个部分组成:
- values:一组数据(numpy.ndarray类型)
- index:相关的数据索引标签;如果没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
创建Series对象
导入pandas
import pandas as pd
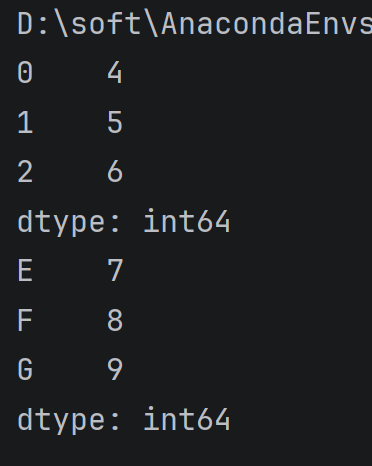
通过list列表来创建
serviceOne = pd.Series([4,5,6])
print(serviceOne)
serviceTwo = pd.Series([7,8,9],index=['E','F','G'])
print(serviceTwo)
使用字典或元组创建series对象
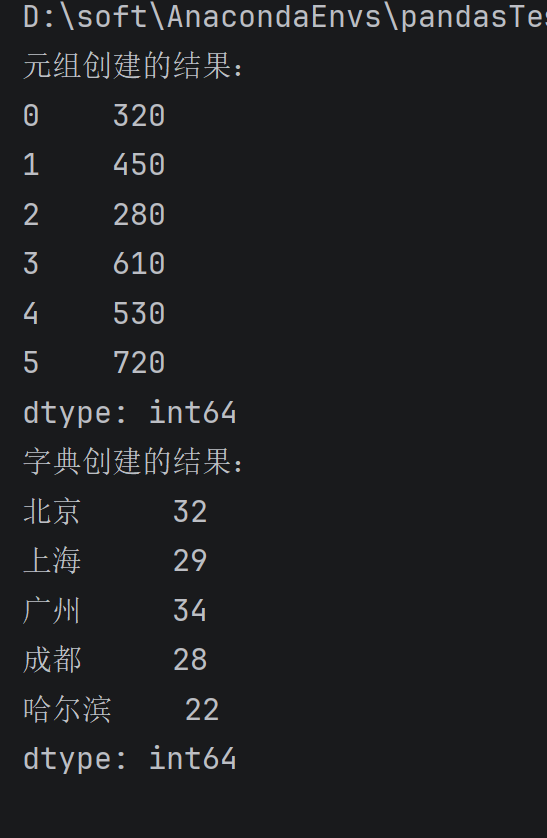
#使用元组(数据是某产品的月销量)
monthly_sales = (320, 450, 280, 610, 530, 720)
sales_series = pd.Series(monthly_sales)
print("元组创建的结果:")
print(sales_series)
# 使用字典(键为城市名,值为对应的日最高气温)
city_temps = {'北京': 32, '上海': 29, '广州': 34, '成都': 28, '哈尔滨': 22}
temp_series = pd.Series(city_temps)
print("字典创建的结果:")
print(temp_series)
使用numpy创建series对象
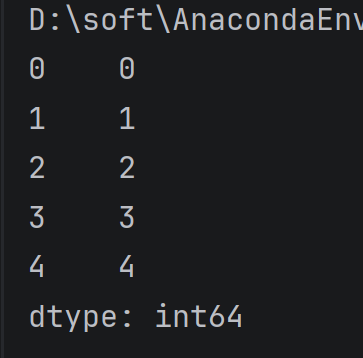
import pandas as pd
import numpy as np
print(pd.Series(np.arange(5)))
Series对象属性
series对象常用属性
serviceOne = pd.Series([4,5,6],index=['D','F','G'])
print(serviceOne.index)
print(serviceOne.values)
print(serviceOne['F'])
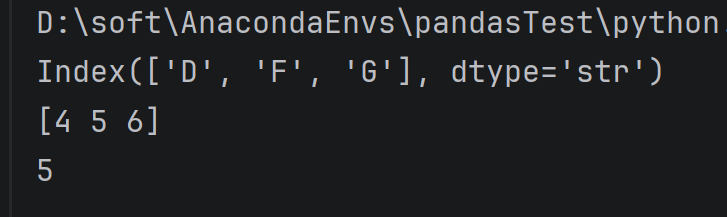
serviceOne.index
serviceOne.values
也可以通过索引来获取数据
serviceOne['F']
DataFrame
创建DataFrame对象
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
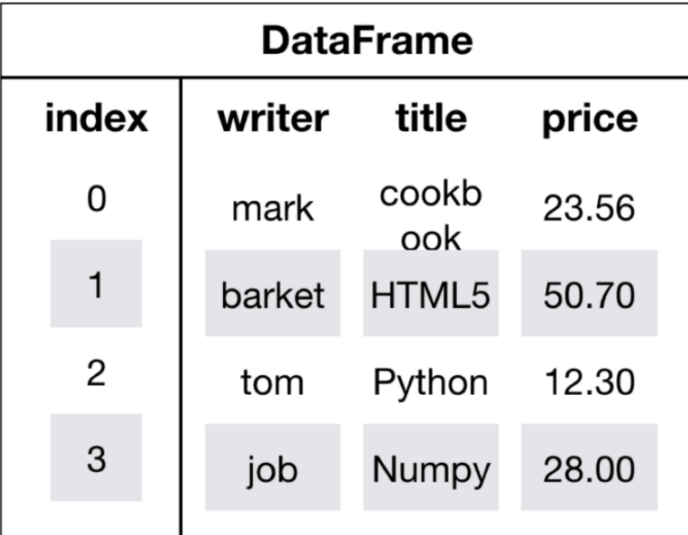
DataFrame的创建有很多种方式
读取文件数据返回df:在之前的学习中我们使用了pd.read_csv('csv格式数据文件路径')的方式获取了df对象
使用字典、列表、元组创建df:接下来就展示如何使用字典、列表+元组、numpy创建df对象
使用字典加列表创建df,使默认自增索引
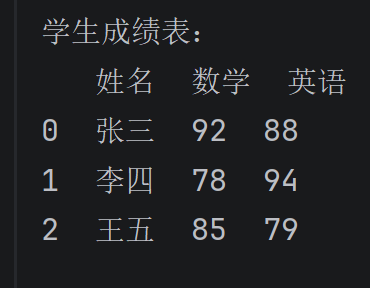
# 定义学生成绩数据(字典形式)
student_scores = {
'姓名': ['张三', '李四', '王五'],
'数学': [92, 78, 85],
'英语': [88, 94, 79]
}
# 创建 DataFrame
score_df = pd.DataFrame(data=student_scores)
print("学生成绩表:")
print(score_df)
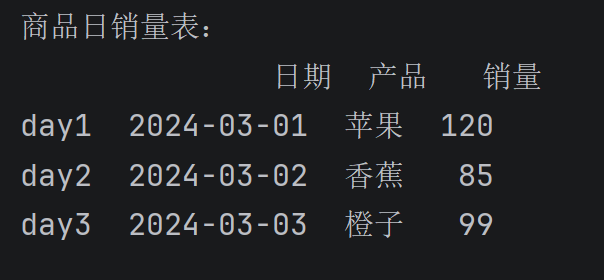
使用列表加元组创建df,并自定义索引
# 定义商品销售数据(元组列表形式)
sales_data = [
('2024-03-01', '苹果', 120),
('2024-03-02', '香蕉', 85),
('2024-03-03', '橙子', 99)
]
# 创建 DataFrame,手动指定列名和索引
sales_df = pd.DataFrame(
data=sales_data,
columns=['日期', '产品', '销量'],
index=['day1', 'day2', 'day3'] # 自定义行索引
)
print("商品日销量表:")
print(sales_df)
使用numpy创建df
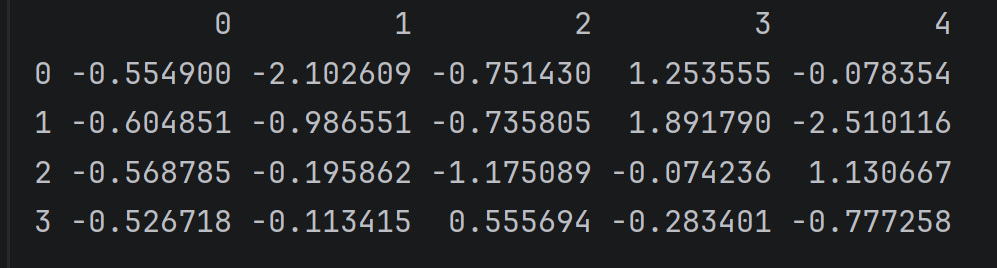
print(pd.DataFrame(np.random.randn(4,5)))
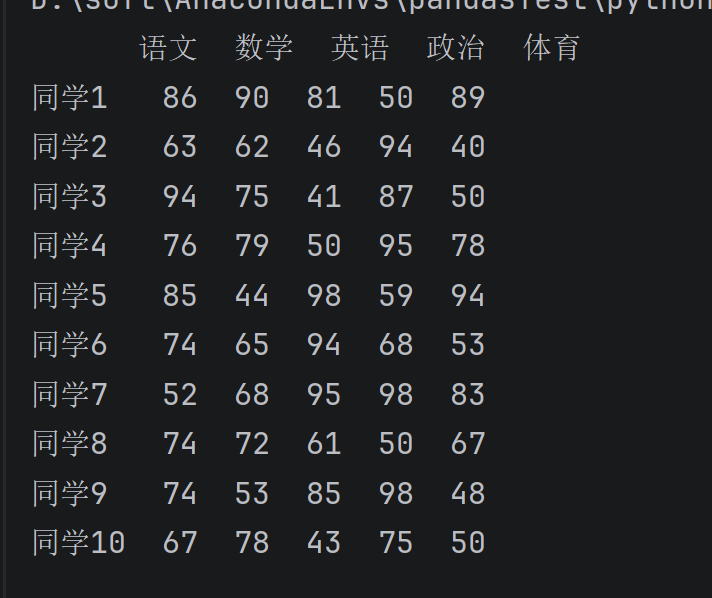
import numpy as np
import pandas as pd
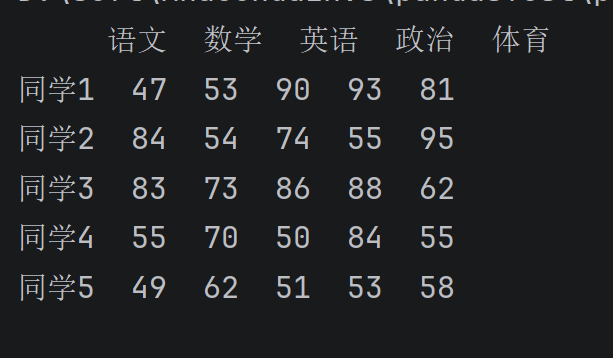
# 1. 生成 10名同学,5门功课的成绩(40-100分)
score = np.random.randint(40, 100, (10, 5))
score_desk = pd.DataFrame(data=score)
# 2. 构建列索引(科目名)
subjects = ["语文", "数学", "英语", "政治", "体育"]
# 3. 构建行索引(同学名)
# 注意:为了让名字从 同学1 开始(而不是同学0),这里建议 +1
stu = ['同学' + str(i) for i in range(1, score_desk.shape[0] + 1)]
# 4. 【关键补充】把行列索引贴到表格上!
score_desk.columns = subjects # 设置列名
score_desk.index = stu # 设置行名
print(score_desk)
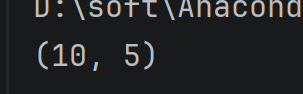
DataFrame 中的 shape 是一个非常基础且极其重要的属性,它用来查看数据表格的“尺寸”——即这个表格有多少行(Row)和多少列(Column)。
在 Pandas 中,shape 返回一个元组(Tuple),格式为 (行数, 列数)。
DataFrame对象属性
属性
shape属性
data.shape
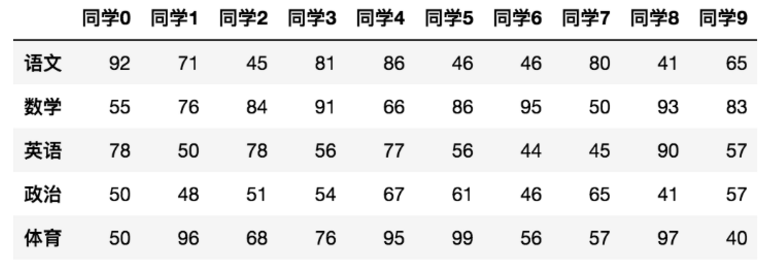
index属性
DataFrame的行索引列表
data.index
columns
DataFrame的列索引列表
data.columns
values
直接获取其中array的值
data.values
T
转置
data.T
DataFrame对象方法
head(n)
显示前n行内容
data.head(5)
tail(n)
显示后n行内容
如果不补充参数,默认5行。填入参数n则显示后n行
data.tail(5)
DatatFrame索引的设置
修改行列索引值
stu = ["学生_" + str(i) for i in range(score_df.shape[0])]
# 必须整体全部修改
data.index = stu
注意:以下修改方式是错误的
# 错误修改方式 data.index[3] = '学生_3'
重设索引
- reset_index(drop=False)
- 设置新的下标索引
- drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
生成一个全新的 DataFrame(新表),但如果你不把它赋值给变量,这个新表会“当场丢失”,原数据 data 不会发生任何变化
# 重置索引,drop=False
data.reset_index()
# 重置索引,drop=True
data.reset_index(drop=True)
以某列值设置为新的索引
- set_index(keys, drop=True)
- keys : 列索引名成或者列索引名称的列表
- drop : boolean, default True.当做新的索引,删除原来的列
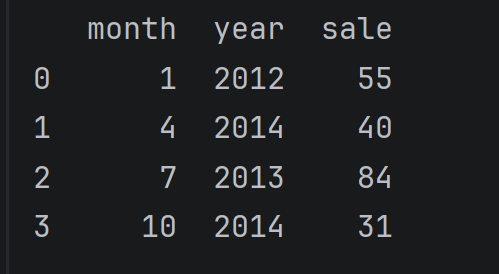
创建
data = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
以月份设置新的索引
new_data = data.set_index('month')
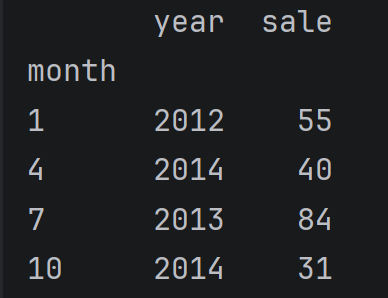
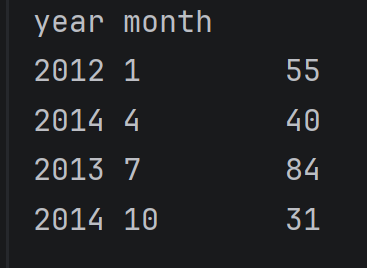
设置多个索引,以年和月份
new_data = data.set_index(['year','month'])
Pandas的数据类型
datetime类型
# 创建一个datetime类型的Series
date = pd.to_datetime(['2026-10-01', '2025-01-01', '2025-07-21'])
print(date)

timedelta类型
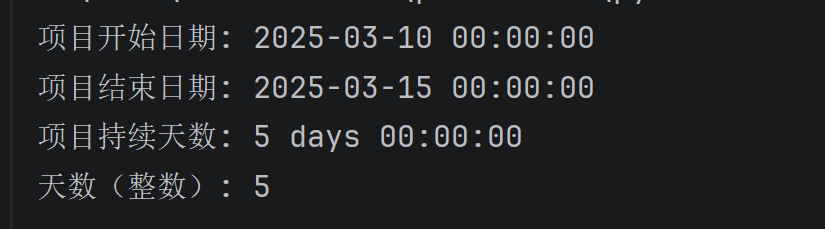
# 计算项目持续天数(两个日期之间的间隔)
project_start = pd.to_datetime('2025-03-10')
project_end = pd.to_datetime('2025-03-15')
duration = project_end - project_start
print("项目开始日期:", project_start)
print("项目结束日期:", project_end)
print("项目持续天数:", duration)
print("天数(整数):", duration.days) # 直接获取数字天数
category类型
类型用于表示分类数据,通常用于有限集合中的数据类型,例如性别、颜色、产品类型等。这种类型的优点在于占用更少的内存,并且对分类数据的操作更快。
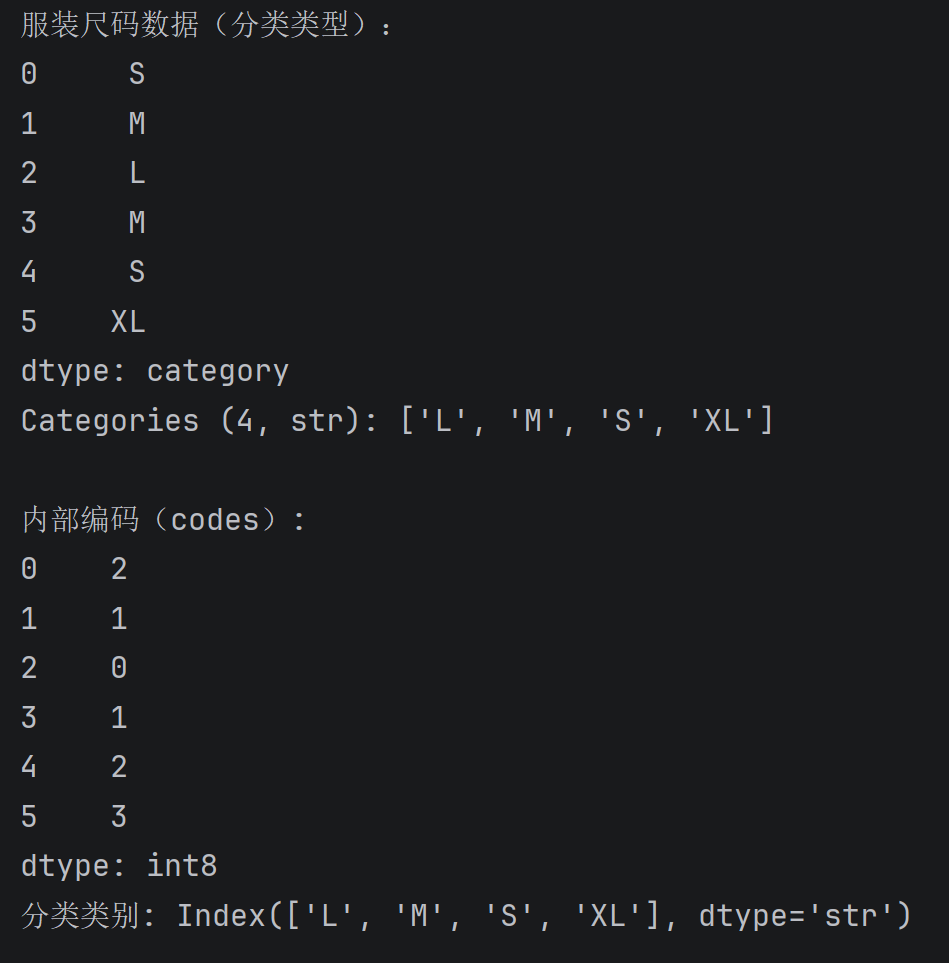
# 创建一个分类(category)类型的 Series,用于存储服装尺码
size_series = pd.Series(['S', 'M', 'L', 'M', 'S', 'XL'], dtype='category')
print("服装尺码数据(分类类型):")
print(size_series)
# 额外演示:查看内部编码(将类别转化为数字代号)
print("\n内部编码(codes):")
print(size_series.cat.codes)
print("分类类别:", size_series.cat.categories)
总结
希望这篇博客能成为你 Pandas 学习之路上的第一块垫脚石。当你面对一份陌生数据不再慌张,而是从容地敲下 data.head() 和 data.shape 时,你就已经迈过了数据分析最重要的门槛。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)