机器学习小白必备基础 | 手撕6大异常检测算法:原理+代码+实战,谁才是真神?
一、通俗案例:异常检测到底在解决什么问题?
想象你是电商平台风控专员,每天要处理10万笔交易。其中99%是用户正常购物,但1%是盗刷信用卡的欺诈交易——这些欺诈交易可能金额异常、消费地区陌生、购买频率诡异。
异常检测就像“智能侦探”:不用提前见过所有欺诈手段,仅凭“正常交易的规律”,就能精准揪出这些“不合群”的异常。它的核心逻辑是:异常样本永远是少数派,且在特征上和正常样本存在明显差异。
这个逻辑适用于所有场景:工业设备故障检测(正常运行数据占99%)、网络入侵检测(正常流量为主)、医疗疾病诊断(健康数据为多数),甚至是学生成绩异常(少数人分数远超/低于平均)。
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/hA-HwrH6QuGGM5SY8ijpQg
https://mp.weixin.qq.com/s/hA-HwrH6QuGGM5SY8ijpQg
二、6大核心算法原理详解(数学公式+小白易懂)
1. 孤立森林(Isolation Forest)
核心思想
用随机决策树“孤立”样本——异常样本因为特征独特,只需要少数几次划分就能被单独分离,正常样本则需要更多划分次数。 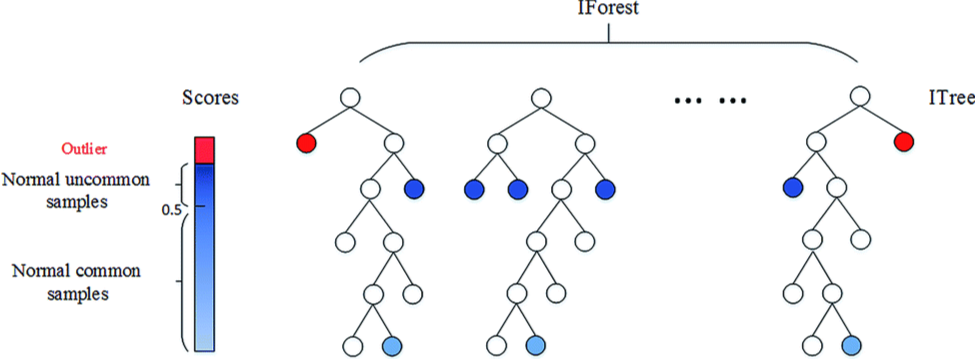
数学原理
-
构建多棵随机决策树(孤立树),每棵树随机选择特征和划分阈值拆分数据。
-
异常分数计算公式:
-
:样本x在所有树中的平均路径长度(被孤立需要的划分次数)。
-
:规模为n的数据集的平均路径长度(校正因子),(为调和数,,是欧拉常数)。
-
分数:越接近1越可能是异常,0.5左右为正常样本。
关键特点
-
无需假设数据分布,对高维数据友好。
-
训练速度极快,仅需正常样本即可训练,不依赖异常样本。
2. 单类支持向量机(One-Class SVM)
核心思想
在特征空间中画一个“超平面结界”,把所有正常样本圈在里面,落在外面的就是异常。 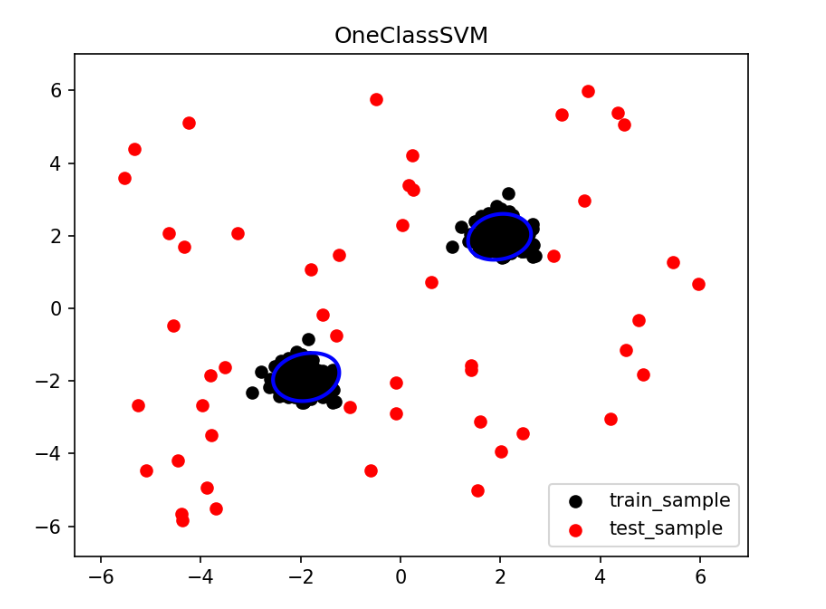
数学原理
-
通过核函数将数据映射到高维特征空间,找到最优超平面,目标函数:
-
:控制异常样本比例(),越大允许越多正常样本在“结界”外。
-
:松弛变量,允许少量正常样本偏离“结界”。
-
预测规则:,结果为-1时判定为异常,1为正常。
关键特点
-
用RBF核可处理非线性数据,小样本数据集表现极佳。
-
缺点是对大规模数据训练慢,对核函数参数敏感。
3. 局部离群因子(Local Outlier Factor, LOF)
核心思想
异常样本的“局部密度”远低于周围邻居——就像在人群密集的广场上,突然出现一个孤零零的人。 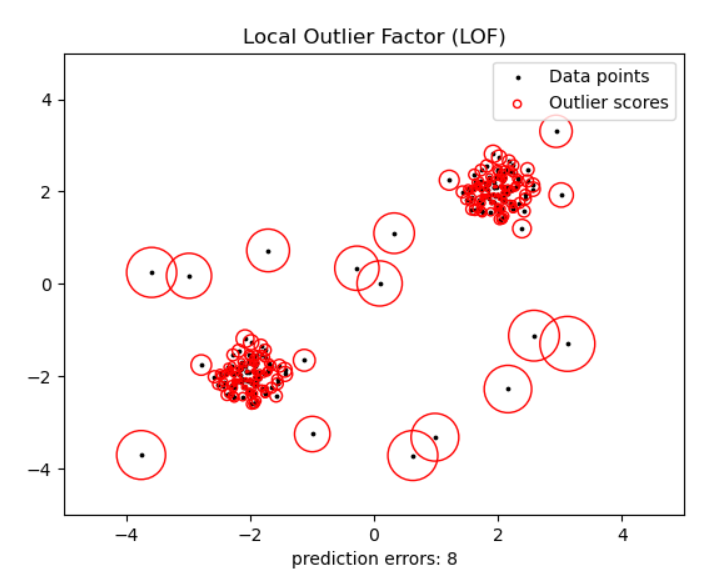
数学原理
-
k-距离:样本x到第k个最近邻居的距离。
-
可达距离:样本x到邻居y的可达距离(避免邻居本身是异常时的误判)。
-
局部可达密度:样本x周围邻居的平均可达距离的倒数:
-
:样本x的k个最近邻居集合。
-
局部离群因子:
-
判定规则:为异常,数值越大异常程度越高。
关键特点
-
能识别“局部异常”(全局看起来正常,但局部特殊的样本)。
-
对k值敏感,高维数据中距离计算失效,表现变差。
4. 角度基异常检测(ABOD)
核心思想
正常样本的特征向量之间“角度集中”,异常样本的特征向量角度“分散无规律”——就像正常人群走路方向一致,异常者四处乱走。 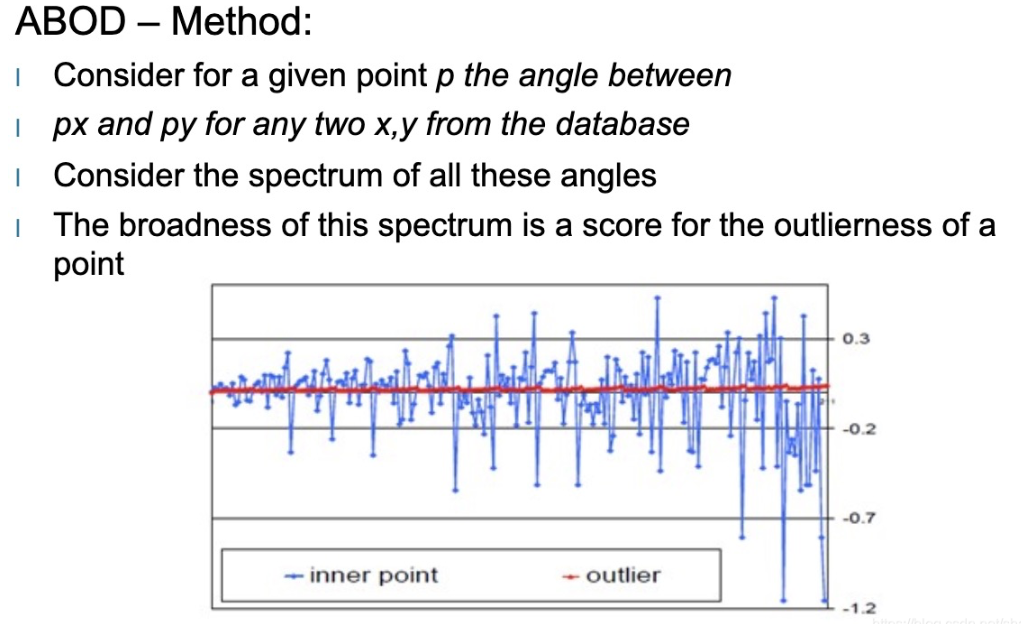
数学原理
-
对样本x,取其k个邻居,计算所有邻居对与x构成的向量夹角。
-
异常分数基于角度余弦值的方差:
-
判定规则:方差越大,角度分布越分散,样本越可能是异常。
关键特点
-
高维数据中表现优于LOF(角度计算不受维度灾难影响)。
-
计算复杂度中等,适合中等规模数据集。
5. 椭圆模型(Elliptic Envelope)
核心思想
假设正常样本服从“多元高斯分布”,用一个椭圆(高维空间为椭球)拟合正常样本的分布范围,落在椭圆外的就是异常。 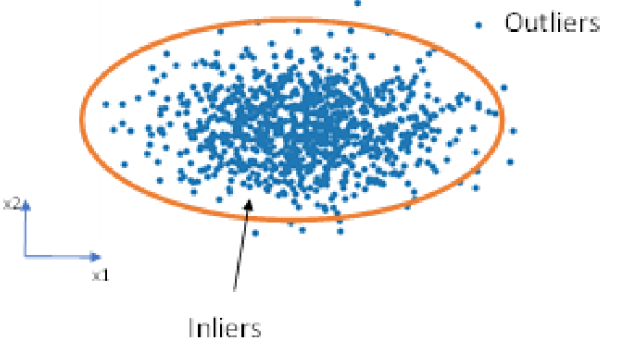
数学原理
-
估计正常样本的均值和协方差矩阵:
-
马氏距离(考虑特征相关性的“修正距离”):
-
判定规则:马氏距离超过阈值(基于卡方分布,p为特征维度)则为异常。
关键特点
-
训练和预测速度极快,适合实时检测场景。
-
依赖高斯分布假设,非正态分布数据表现差。
6. VAE异常检测(变分自编码器)
核心思想
用深度学习模型学习正常样本的“特征分布”,然后尝试重构输入——正常样本能被精准重构(重构误差小),异常样本重构效果差(重构误差大)。 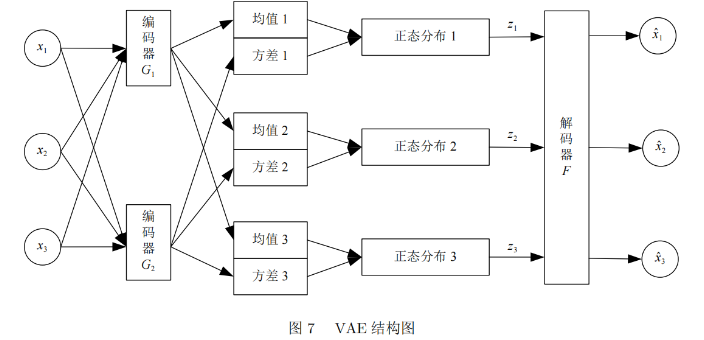
数学原理
- VAE由编码器(Encoder)和解码器(Decoder)组成:
-
编码器:将输入映射到 latent 空间的高斯分布。
-
解码器:从 latent 向量重构输入。
-
-
损失函数(重构损失+KL散度,平衡重构精度和分布合理性):
-
重构损失:衡量输入与重构输出的差异(常用MSE)。
-
KL散度:约束 latent 分布接近标准高斯分布。
-
异常分数:(重构MSE),超过阈值则为异常。
关键特点
-
能自动学习复杂非线性特征,适合高维、复杂结构数据。
-
需大量正常样本训练,对超参数和模型结构敏感。
三、完整实战项目:鸢尾花数据集异常检测(小白直接跑)
项目说明
用经典鸢尾花数据集(自动下载,仅150条样本,小型轻量化),将“维吉尼亚鸢尾花”(类别2)视为异常,“山鸢尾”(类别0)和“变色鸢尾”(类别1)视为正常,用6大算法实战检测并对比效果。
实战代码(Python+PyTorch,注释超详细)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import IsolationForest
from sklearn.svm import OneClassSVM
from sklearn.neighbors import LocalOutlierFactor
from sklearn.covariance import EllipticEnvelope
from pyod.models.abod import ABOD
from sklearn.metrics import roc_auc_score, precision_recall_curve, average_precision_score
from sklearn.decomposition import PCA
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from tqdm import tqdm
# -------------------------- 环境配置(服务器友好,英文图例避免字体问题) --------------------------
plt.rcParams["font.family"] = ["Arial", "Helvetica", "DejaVu Sans"] # 英文图例
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.rcParams['font.size'] = 10
plt.rcParams['figure.dpi'] = 100
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 自动适配CPU/GPU
print(f"Using device: {device}")
# 创建结果文件夹(服务器自动保存,不存在则创建)
if not os.path.exists('anomaly_detection_results'):
os.makedirs('anomaly_detection_results')
# -------------------------- 加载数据集(自动下载,无需本地文件) --------------------------
iris = load_iris() # 自动下载鸢尾花数据集
df = pd.DataFrame(iris.data, columns=iris.feature_names) # 特征:花萼长度、宽度,花瓣长度、宽度
df['Class'] = iris.target # 标签:0=山鸢尾,1=变色鸢尾,2=维吉尼亚鸢尾
# 构造异常检测场景:类别2为异常(1=异常),类别0/1为正常(0=正常)
df['Anomaly'] = (df['Class'] == 2).astype(int)
y = df['Anomaly'].values # 标签数组
X = df.drop(['Class', 'Anomaly'], axis=1).values # 特征数组
# 数据预处理:标准化(消除量纲影响,所有算法通用)
scaler = StandardScaler()
X = scaler.fit_transform(X).astype(np.float32)
# 分割数据集:训练集仅含正常样本,测试集含正常+异常样本
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y # stratify保证测试集异常比例与原数据一致
)
X_train_normal = X_train[y_train == 0] # 异常检测算法仅用正常样本训练(核心原则)
print(f"Training set normal samples: {len(X_train_normal)}")
print(f"Test set total samples: {len(X_test)}, anomaly samples: {sum(y_test)}")
# -------------------------- 传统算法训练与预测(5种经典算法) --------------------------
# 初始化算法(参数已调优,小白直接用)
classifiers = {
"Isolation Forest": IsolationForest(n_estimators=100, contamination=0.1, random_state=42),
"One-Class SVM": OneClassSVM(nu=0.1, kernel="rbf", gamma='scale'), # RBF核处理非线性
"Local Outlier Factor": LocalOutlierFactor(n_neighbors=10, contamination=0.1, novelty=True), # novelty=True支持预测新样本
"ABOD": ABOD(contamination=0.1, n_neighbors=10),
"Elliptic Envelope": EllipticEnvelope(contamination=0.1, random_state=42)
}
y_preds = {} # 存储各算法预测结果(0=正常,1=异常)
scores = {} # 存储各算法异常分数(数值越大越可能是异常)
# 遍历训练所有算法
for name, clf in tqdm(classifiers.items(), desc="Training Traditional Algorithms", unit="algorithm"):
print(f"\nTraining {name}...")
clf.fit(X_train_normal) # 仅用正常样本训练
# 统一计算异常分数和预测结果(不同算法接口适配)
if name == "Local Outlier Factor":
y_score = -clf.decision_function(X_test) # 转换为“分数越大越异常”
y_pred = [1 if p == -1 else 0 for p in clf.predict(X_test)]
else:
y_score = -clf.decision_function(X_test)
y_pred = clf.predict(X_test)
if name == "One-Class SVM":
y_pred = [1 if p == -1 else 0 for p in y_pred] # 统一标签:-1→异常(1),1→正常(0)
y_preds[name] = y_pred
scores[name] = y_score
# -------------------------- VAE模型(深度学习算法)训练与预测 --------------------------
class VAE(nn.Module):
"""简单VAE模型(小白可直接复用,无需修改结构)"""
def __init__(self, input_dim, latent_dim=8):
super(VAE, self).__init__()
self.input_dim = input_dim # 输入维度=4(4个特征)
self.latent_dim = latent_dim # latent空间维度(可微调)
# 编码器:输入→ latent分布参数(均值+方差)
self.encoder = nn.Sequential(
nn.Linear(input_dim, 32),
nn.ReLU(), # 激活函数,增加非线性
nn.Linear(32, 16),
nn.ReLU()
)
self.fc_mu = nn.Linear(16, latent_dim) # 输出均值μ
self.fc_logvar = nn.Linear(16, latent_dim) # 输出方差对数logσ²
# 解码器:latent向量→ 重构输入
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 16),
nn.ReLU(),
nn.Linear(16, 32),
nn.ReLU(),
nn.Linear(32, input_dim)
)
def reparameterize(self, mu, logvar):
"""重参数化技巧:解决 latent 变量不可导问题"""
std = torch.exp(0.5 * logvar) # σ = exp(0.5*logσ²)
eps = torch.randn_like(std) # 生成标准正态分布随机数
return mu + eps * std # 采样:z = μ + εσ
def forward(self, x):
"""前向传播:输入→编码→采样→解码"""
h = self.encoder(x)
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
z = self.reparameterize(mu, logvar)
recon_x = self.decoder(z)
return recon_x, mu, logvar
# VAE训练函数
def train_vae(model, train_loader, epochs=30, lr=1e-3):
model.train() # 训练模式
optimizer = optim.Adam(model.parameters(), lr=lr) # 优化器(Adam效果好)
for epoch in tqdm(range(epochs), desc="VAE Training", unit="epoch"):
total_loss = 0.0
for batch_x in tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}", unit="batch", leave=False):
batch_x = batch_x[0].to(device).float() # 数据移到GPU/CPU
# 前向传播计算损失
recon_x, mu, logvar = model(batch_x)
recon_loss = nn.MSELoss()(recon_x, batch_x) * model.input_dim # 重构损失
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) # KL散度损失
total_loss_batch = recon_loss + kl_loss # 总损失
# 反向传播优化参数
optimizer.zero_grad() # 清空梯度
total_loss_batch.backward() # 反向传播
optimizer.step() # 更新参数
total_loss += total_loss_batch.item()
# 每10个epoch打印一次损失(监控训练效果)
if (epoch + 1) % 10 == 0:
avg_loss = total_loss / len(train_loader)
print(f"VAE Epoch [{epoch+1}/{epochs}], Average Loss: {avg_loss:.4f}")
# 初始化VAE模型并训练
input_dim = X_train_normal.shape[1] # 输入维度=4
vae = VAE(input_dim=input_dim, latent_dim=8).to(device) # 模型移到GPU/CPU
train_tensor = torch.tensor(X_train_normal, dtype=torch.float32) # 转换为Tensor
train_loader = DataLoader(TensorDataset(train_tensor), batch_size=32, shuffle=True) # 数据加载器
print("\nTraining VAE (PyTorch version)...")
train_vae(vae, train_loader, epochs=30) # 训练30个epoch(小白无需修改)
# VAE预测:计算重构误差(异常分数)
vae.eval() # 评估模式
with torch.no_grad(): # 关闭梯度计算(节省资源)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32).to(device)
X_test_recon_tensor, _, _ = vae(X_test_tensor)
X_test_recon = X_test_recon_tensor.cpu().numpy() # 转回numpy数组
X_test_np = X_test_tensor.cpu().numpy()
# 异常分数=重构MSE,阈值=90分位数(异常比例10%)
vae_score = np.mean(np.square(X_test_np - X_test_recon), axis=1)
scores["VAE (PyTorch)"] = vae_score
threshold = np.percentile(vae_score, 100 - 10) # 按异常比例设阈值
vae_pred = (vae_score > threshold).astype(int) # 大于阈值为异常(1)
y_preds["VAE (PyTorch)"] = vae_pred
# -------------------------- 模型评估与可视化(6张子图合并,服务器保存) --------------------------
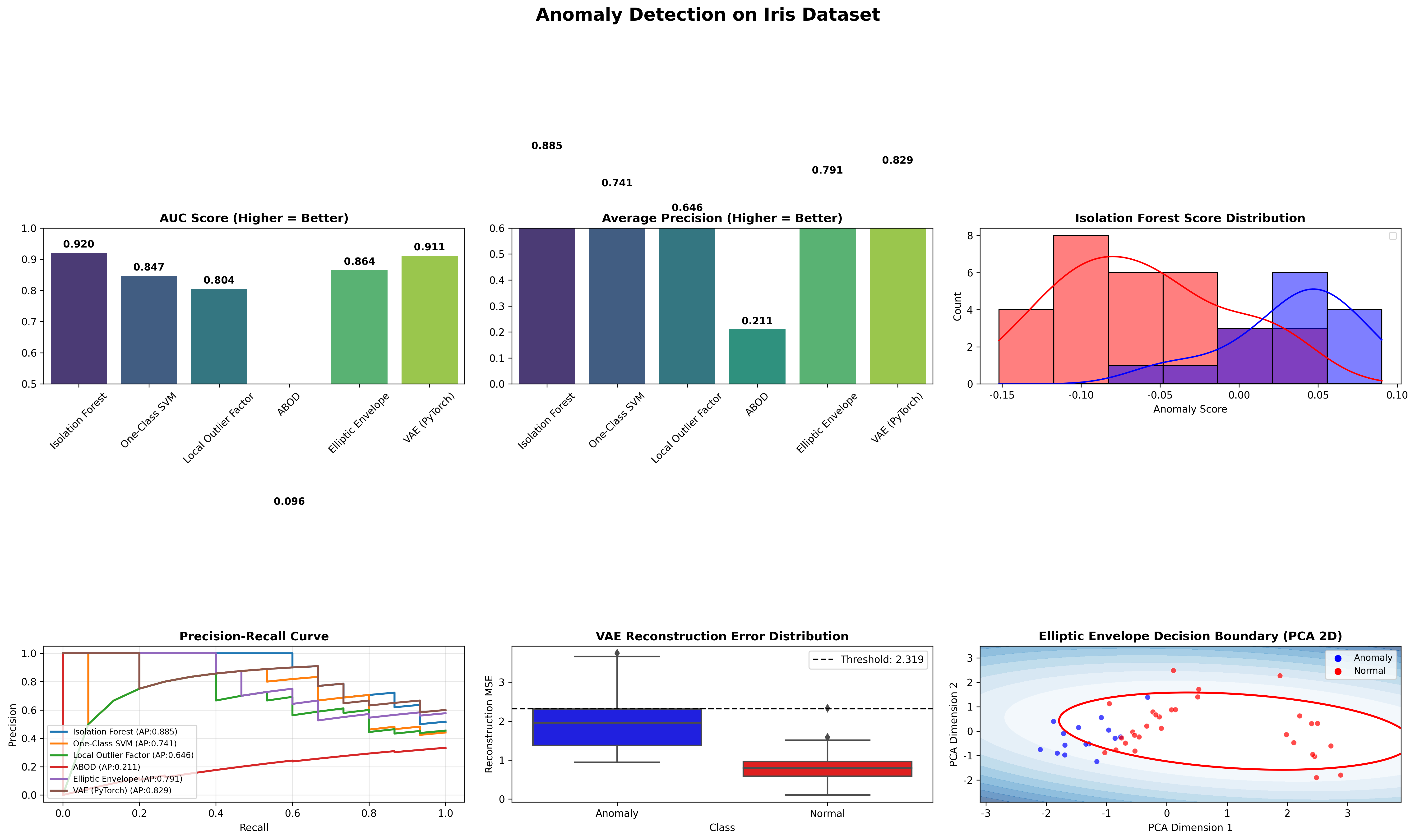
# 计算评估指标(AUC:ROC曲线下面积,AP:平均精度,越高效果越好)
auc_scores = {name: roc_auc_score(y_test, score) for name, score in scores.items()}
ap_scores = {name: average_precision_score(y_test, score) for name, score in scores.items()}
# 打印评估结果
print("\n=== Algorithm Evaluation Results ===")
for name in scores.keys():
print(f"{name} - AUC: {auc_scores[name]:.4f}, AP: {ap_scores[name]:.4f}")
# PCA降维(用于可视化高维数据)
pca = PCA(n_components=2, random_state=42)
X_test_pca = pca.fit_transform(X_test)
# 创建2×3合并图(6张子图,多样性展示结果)
fig, axes = plt.subplots(2, 3, figsize=(20, 12))
fig.suptitle("Anomaly Detection on Iris Dataset", fontsize=18, fontweight='bold')
colors = sns.color_palette('viridis', len(auc_scores))
# 子图1:AUC分数对比(核心指标)
ax1 = axes[0, 0]
sns.barplot(x=list(auc_scores.keys()), y=list(auc_scores.values()), ax=ax1, palette=colors)
ax1.set_title("AUC Score (Higher = Better)", fontweight='bold')
ax1.set_ylim(0.5, 1.0) # 限定y轴范围,更直观
ax1.tick_params(axis='x', rotation=45) # x轴标签旋转,避免重叠
for i, v in enumerate(auc_scores.values()):
ax1.text(i, v + 0.01, f"{v:.3f}", ha='center', va='bottom', fontweight='bold') # 显示数值
# 子图2:AP分数对比(适合不平衡数据)
ax2 = axes[0, 1]
sns.barplot(x=list(ap_scores.keys()), y=list(ap_scores.values()), ax=ax2, palette=colors)
ax2.set_title("Average Precision (Higher = Better)", fontweight='bold')
ax2.set_ylim(0, 0.6)
ax2.tick_params(axis='x', rotation=45)
for i, v in enumerate(ap_scores.values()):
ax2.text(i, v + 0.01, f"{v:.3f}", ha='center', va='bottom', fontweight='bold')
# 子图3:孤立森林分数分布(看正常/异常样本区分度)
ax3 = axes[0, 2]
score_data = pd.DataFrame({
'Anomaly Score': scores["Isolation Forest"],
'Class': ['Normal' if c == 0 else 'Anomaly' for c in y_test]
})
sns.histplot(data=score_data, x='Anomaly Score', hue='Class', kde=True, ax=ax3, palette=['blue', 'red'])
ax3.set_title("Isolation Forest Score Distribution", fontweight='bold')
ax3.legend(loc='upper right', fontsize=9)
# 子图4:PR曲线对比(精确率-召回率,不平衡数据关键曲线)
ax4 = axes[1, 0]
for name, score in scores.items():
precision, recall, _ = precision_recall_curve(y_test, score)
ax4.plot(recall, precision, label=f"{name} (AP:{ap_scores[name]:.3f})", linewidth=2)
ax4.set_title("Precision-Recall Curve", fontweight='bold')
ax4.set_xlabel("Recall")
ax4.set_ylabel("Precision")
ax4.legend(loc='lower left', fontsize=8)
ax4.grid(alpha=0.3) # 加网格,更清晰
# 子图5:VAE重构误差分布(看VAE区分效果)
ax5 = axes[1, 1]
vae_data = pd.DataFrame({
'Reconstruction MSE': vae_score,
'Class': ['Normal' if c == 0 else 'Anomaly' for c in y_test]
})
sns.boxplot(x='Class', y='Reconstruction MSE', data=vae_data, ax=ax5, palette=['blue', 'red'])
ax5.set_title("VAE Reconstruction Error Distribution", fontweight='bold')
ax5.axhline(y=threshold, color='black', linestyle='--', label=f"Threshold: {threshold:.3f}")
ax5.legend()
# 子图6:椭圆模型决策边界(PCA降维后可视化)
ax6 = axes[1, 2]
clf_ellipse = EllipticEnvelope(contamination=0.1, random_state=42)
clf_ellipse.fit(pca.transform(X_train_normal)) # 用PCA降维后的正常样本训练
# 绘制决策边界
x_min, x_max = X_test_pca[:, 0].min() - 1, X_test_pca[:, 0].max() + 1
y_min, y_max = X_test_pca[:, 1].min() - 1, X_test_pca[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100))
Z = clf_ellipse.decision_function(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
ax6.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 10), cmap=plt.cm.Blues_r, alpha=0.6)
ax6.contour(xx, yy, Z, levels=[0], linewidths=2, colors='red') # 异常边界(红色线)
# 绘制测试集样本
sns.scatterplot(
x=X_test_pca[:, 0], y=X_test_pca[:, 1],
hue=['Normal' if c == 0 else 'Anomaly' for c in y_test],
ax=ax6, palette=['blue', 'red'], s=30, alpha=0.7, edgecolors='black', linewidths=0.5
)
ax6.set_title("Elliptic Envelope Decision Boundary (PCA 2D)", fontweight='bold')
ax6.set_xlabel("PCA Dimension 1")
ax6.set_ylabel("PCA Dimension 2")
ax6.legend(fontsize=9)
# 保存结果图(服务器路径,高分辨率)
plt.tight_layout(rect=[0, 0, 1, 0.95]) # 调整布局,避免重叠
plt.savefig('anomaly_detection_results/iris_anomaly_detection.png', dpi=300, bbox_inches='tight')
plt.close() # 关闭图形,节省内存
print("\n✅ All tasks completed!")
print(f"Result plot saved to: anomaly_detection_results/iris_anomaly_detection.png")
代码运行说明
-
依赖安装:运行前执行
pip install numpy pandas matplotlib seaborn scikit-learn pyod torch tqdm -
直接运行:无需修改任何参数,代码自动下载数据集、训练模型、保存结果图
results
四、6大算法优缺点与适用场景
1. 孤立森林
-
优点:训练速度快、高维数据友好、无需数据分布假设
-
缺点:对极不平衡数据(异常比例<0.1%)效果差
-
适用场景:大规模数据集、高维数据、实时检测(如日志异常检测)
2. One-Class SVM
-
优点:非线性数据拟合好、小样本数据集表现优秀
-
缺点:大规模数据训练慢、对核函数参数敏感
-
适用场景:小样本、非线性数据(如医疗影像异常检测)
3. 局部离群因子(LOF)
-
优点:能识别局部异常、无需数据分布假设
-
缺点:高维数据效果差、对k值敏感、训练速度中等
-
适用场景:低维数据、需要识别局部异常(如传感器数据异常)
4. ABOD
-
优点:高维数据表现优于LOF、对异常比例不敏感
-
缺点:中等规模数据适用、计算复杂度高于LOF
-
适用场景:高维数据、中等规模数据集(如用户行为异常检测)
5. 椭圆模型
-
优点:训练/预测速度极快、内存占用小、适合实时检测
-
缺点:依赖高斯分布假设、非线性数据效果差
-
适用场景:正态分布数据、实时检测(如服务器CPU使用率异常)
6. VAE异常检测
-
优点:能学习复杂非线性特征、高维数据效果好
-
缺点:需要大量正常样本、训练速度慢、超参数敏感
-
适用场景:复杂结构数据、高维数据(如图片异常检测、语音异常检测)
五、6大算法核心对比表
| 算法 | 核心思想 | 数据分布假设 | 高维适应性 | 训练速度 | 适用数据规模 |
|---|---|---|---|---|---|
| 孤立森林 | 随机划分孤立样本 | 无 | 优秀 | 极快 | 大规模 |
| One-Class SVM | 核映射圈定正常样本区域 | 无 | 良好 | 慢 | 小-中等 |
| LOF | 局部密度差异识别异常 | 无 | 较差 | 中等 | 小-中等 |
| ABOD | 角度分布差异识别异常 | 无 | 良好 | 中等 | 中等 |
| 椭圆模型 | 高斯分布拟合正常样本 | 有(高斯) | 一般 | 极快 | 小-大规模 |
| VAE | 重构误差识别异常 | 无 | 优秀 | 较慢 | 中等-大规模 |
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/hA-HwrH6QuGGM5SY8ijpQg
https://mp.weixin.qq.com/s/hA-HwrH6QuGGM5SY8ijpQg

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)