Python朴素贝叶斯算法邮件分类检测系统 Django框架 垃圾邮件分类 机器学习算法 大数据 计算机✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Django框架、朴素贝叶斯算法、数据分析、HTML
使用朴素贝叶斯编写的垃圾邮件分类系统;
使用的数据集来自于https://github.com;
分类正确率在95%左右;
normal文件夹中是健康邮件, 大约7000多份;
spam文件夹中是垃圾邮件, 大约7000多份;
test是测试集, 大约400份, 编号1-200的是健康邮件, 7801-8000是垃圾邮件;
2、项目界面
(1)邮件分类管理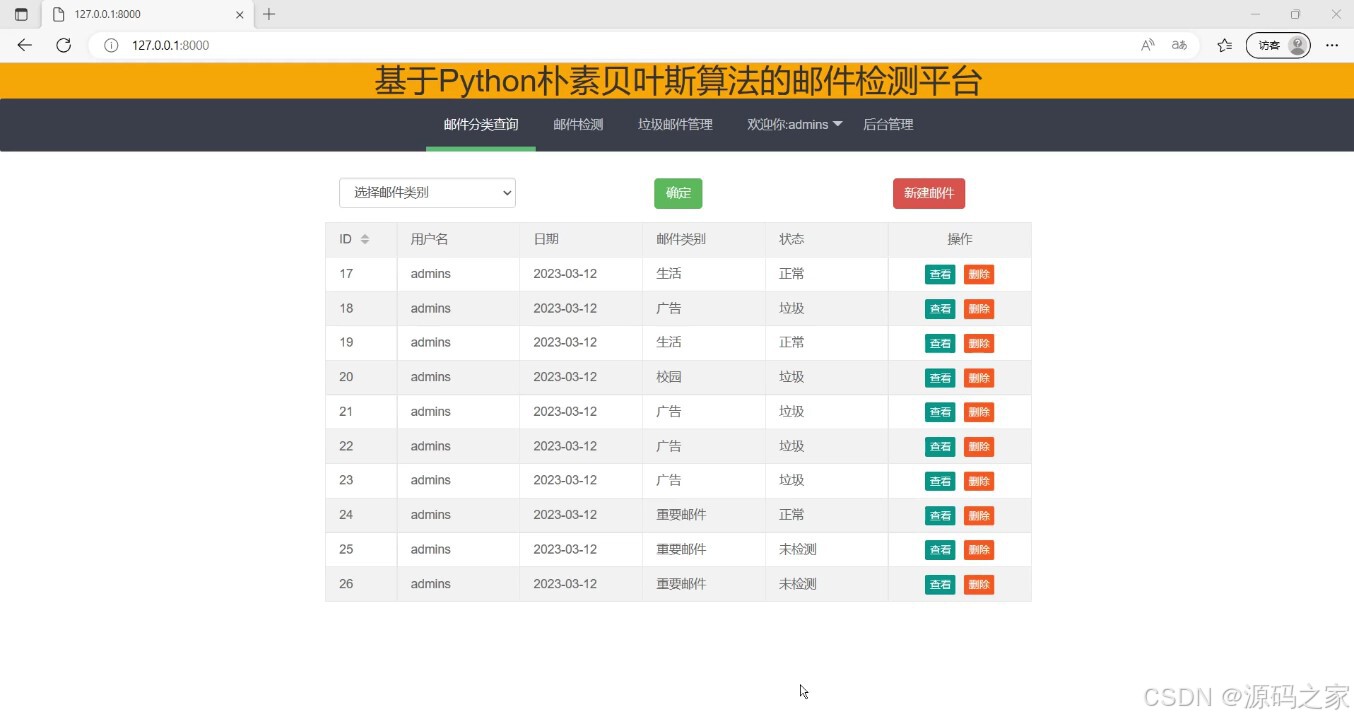
(2)邮件分类检测
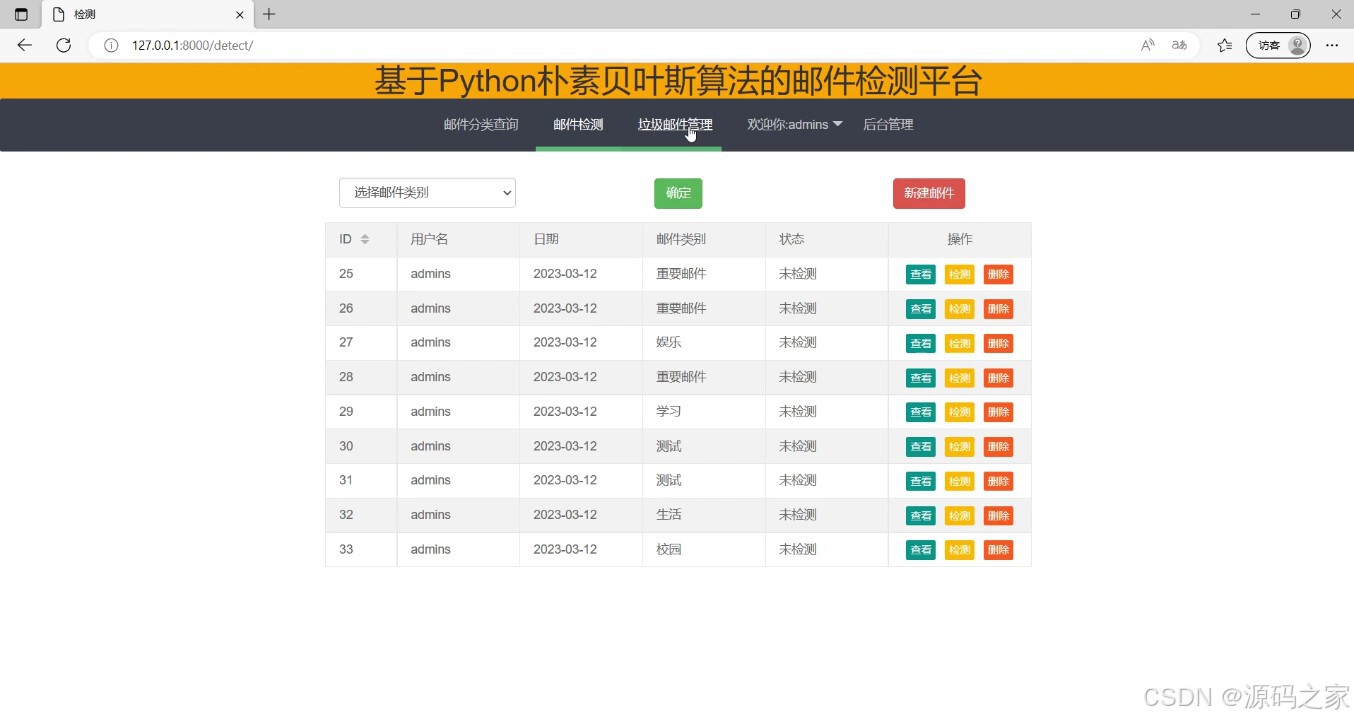
(3)邮件信息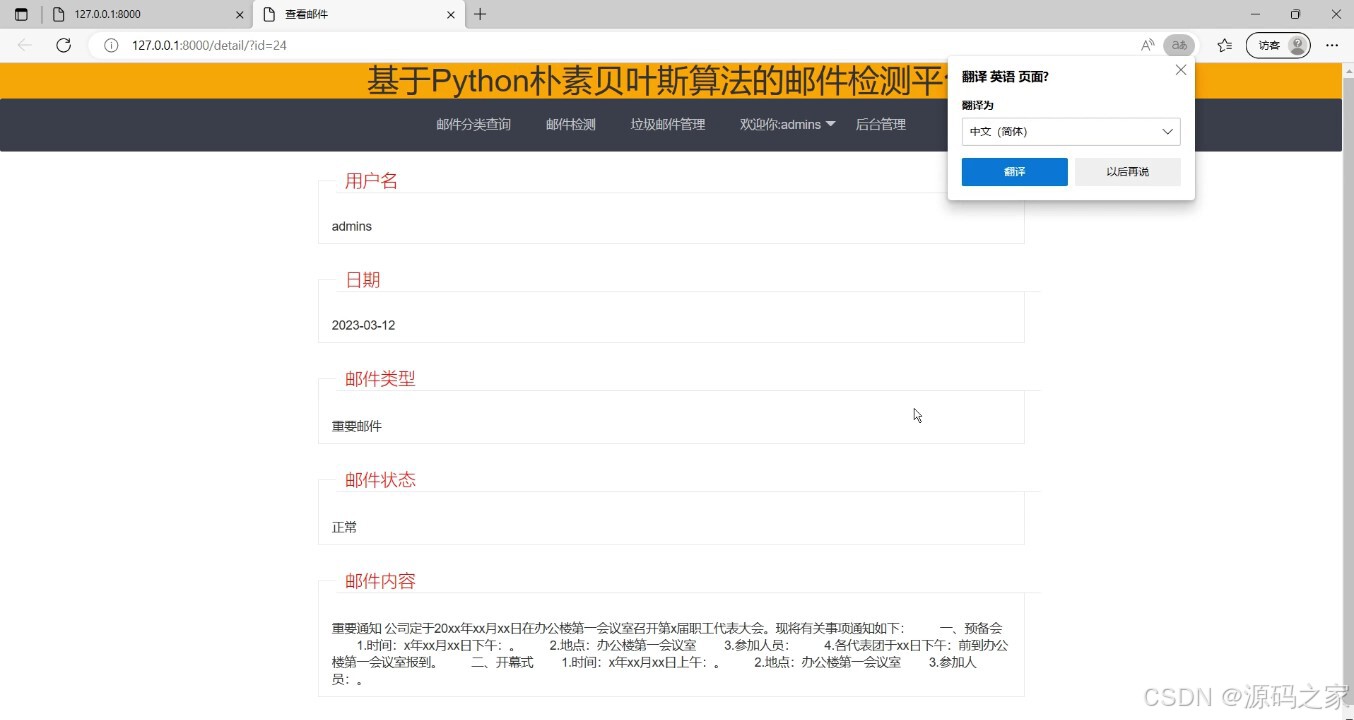
(4)邮件分类检测------------朴素贝叶斯算法
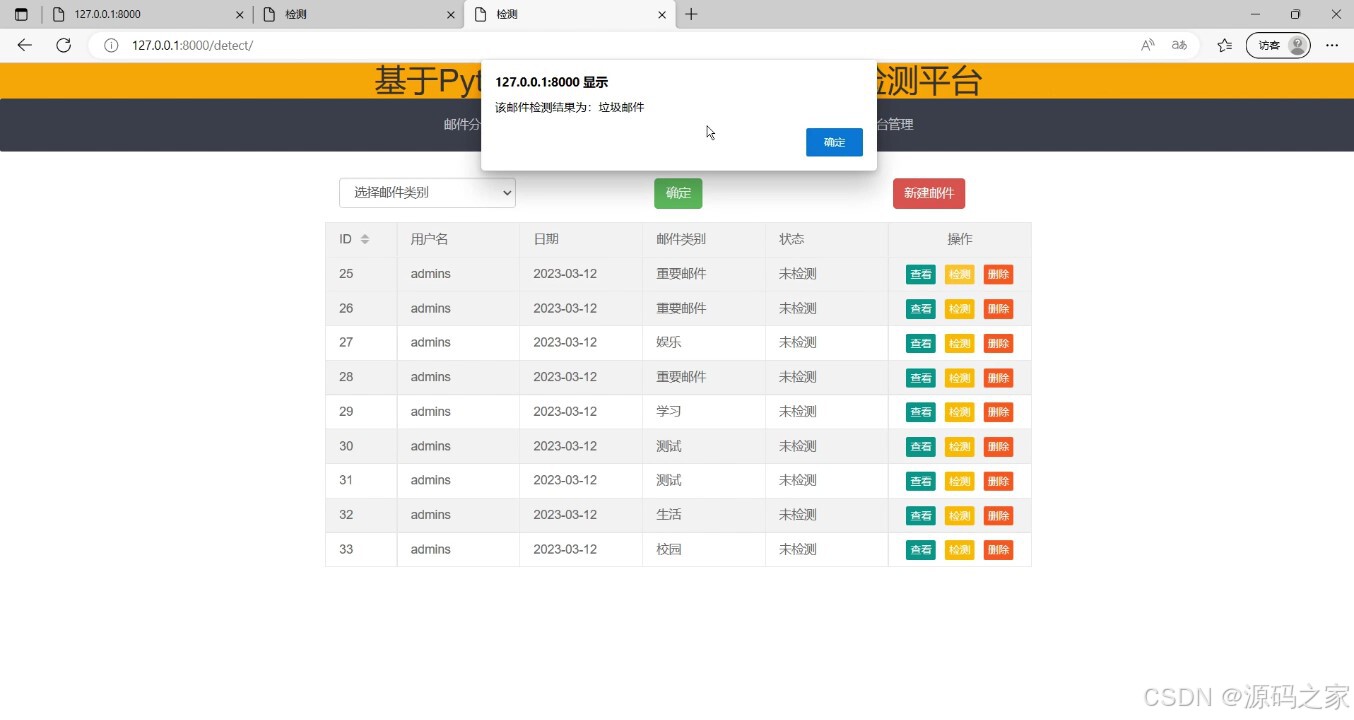
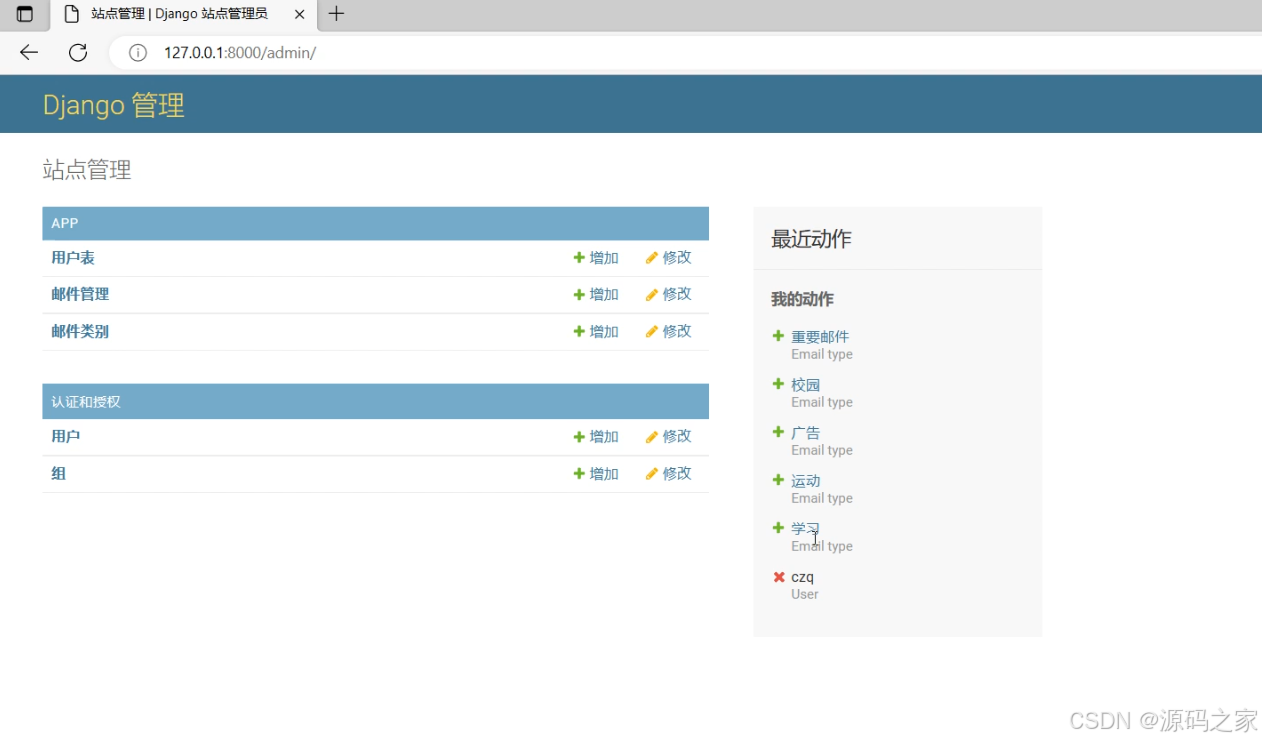
(5)后台管理
(6)注册登录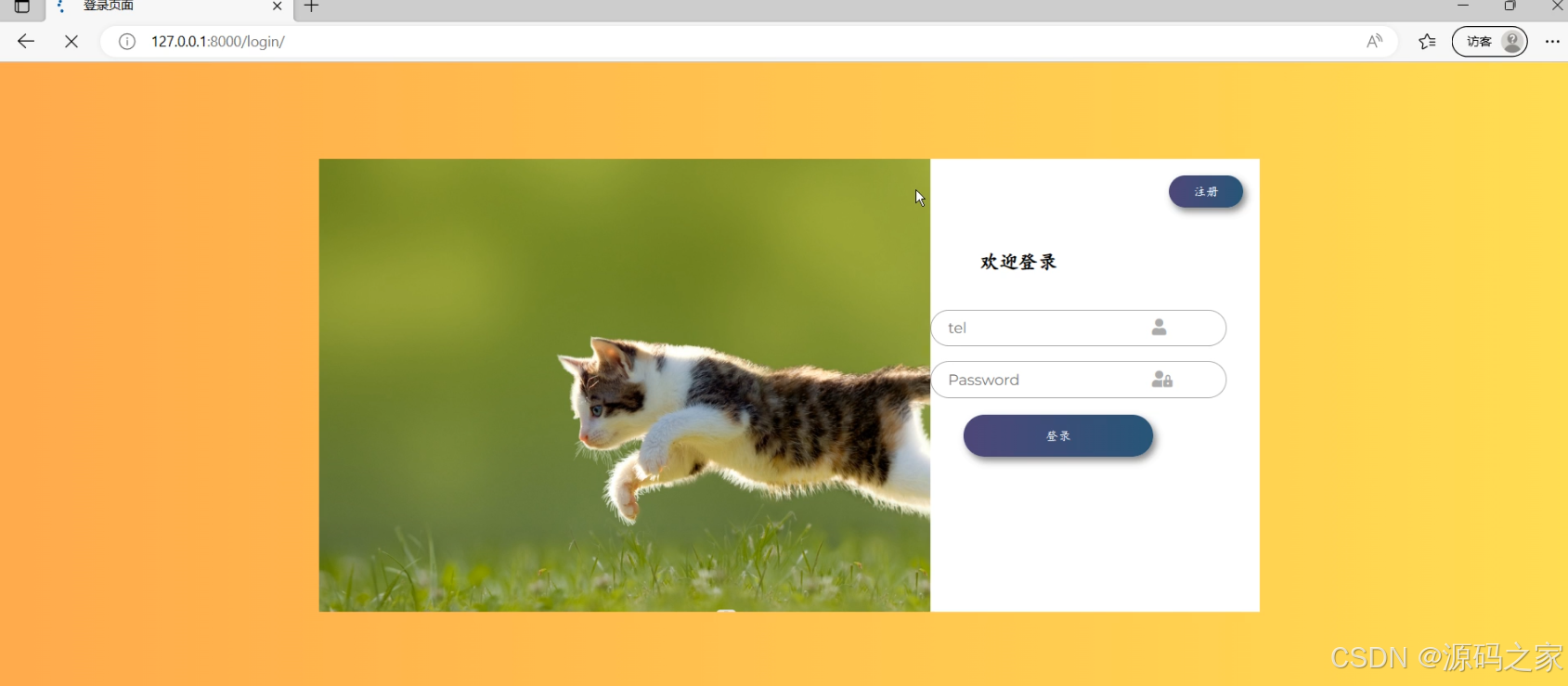
3、项目说明
随着电子邮件的广泛使用,大量的垃圾邮件随之产生。日益增加的垃圾邮件不仅占用内存,而且还会影响人们的正常生活。因此,研究邮件分类系统问题有着重大的现实意义。目前的垃圾邮件分类方法有很多,其中最典型的方法是基于贝叶斯算法的垃圾邮件分类模型。
本文实现了一个基于Python的邮件分类系统,该系统首先对中文文本进行预处理后进行特征提取,该系统的核心部分是邮件分类是基于朴素贝叶斯算法设计的,此邮件分类系统可以很好的拦截垃圾邮件。
关键词:贝叶斯算法;垃圾邮件;文本预处理;特征提取
随着信息化时代的发展,电子邮件得到广泛应用的同时垃圾邮件的数目越来越大,垃圾邮件分类已经成为全世界关注的问题。本文运用了朴素贝叶斯算法对邮件进行分类,将邮件分为垃圾邮件和正常邮件。在邮件分类前应先对文本进行预处理,然后进行特征提取,最后选取部分邮件进行训练,得到先验概率,紧接着就可以对新邮件进行分类。通过贝叶斯算法减少垃圾邮件对人们的影响,在本文的研究中包含以下几个方面的内容。
首先,对于邮件分类研究的背景及意义做阐述,目前的邮件分类技术的研究现状,及各种邮件分类算法的研究现状,最终选取了最典型的朴素贝叶斯算法作为该系统的核心算法。
其次,对本文涉及到的相关知识及技术进行了详细说明。包括了Python的介绍、MySQL数据库及数据库管理工具的介绍、Django框架的介绍、jieba库的介绍以及各种邮件分类算法的阐述,尤其详细介绍了朴素贝叶斯算法,为论文后面的系统设计打下基础。
再次,对系统进行可行性分析,分析其在经济、技术、操作等方面的可行性,紧接着对系统的性能及功能进行分析为后面的系统设计奠定基础。根据系统的需求分析进行系统的总体设计和详细设计。
最后,分析系统需求,根据需求介绍邮件分类系统的总体设计及各功能模块的详细设计,并根据邮件分类系统的详细设计来实现系统,并实现系统的可视化。
4、核心代码
import os
import re
import jieba
import copy
# 垃圾邮件和健康邮件的先验概率
from FirstByesSpam.src import train
p_s = 0.5
p_h = 0.5
conditional_hw_and_sw = []
conditional_wh_and_ws = []
word_to_id_map = {}
# 计算词汇表中所有单词的条件概率P(s|w),即已知该邮件有单词w, 则这篇邮件是spam的概率
# 计算词汇表中所有单词的条件概率P(h|w)
def calculate_conditional_hw_and_sw(conditional_wh_and_ws):
for i in range(0, len(conditional_wh_and_ws)):
p_ws = conditional_wh_and_ws[i][1]
p_wh = conditional_wh_and_ws[i][0]
p_sw = (p_ws * p_s) / (p_ws * p_s + p_wh * p_h)
p_hw = (p_wh * p_h) / (p_wh * p_h + p_ws * p_s)
# 把词汇表里所有单词都转换成相应的条件概率的形式
# 其实就少量的短文本而言, 事先把词汇表中的全部单词都转换一遍, 或许比不上现用再转换更快
# 但是这里我想输出一遍条件概率, 看一下单词对分类的影响;
conditional_hw_and_sw.append([p_hw, p_sw])
# 计算一篇邮件中的P(s|W)和P(h|W), 并返回;
def calculate_conditional_sW(file):
with open(file, 'r', encoding='gbk') as reader:
# 过滤掉非中文字符
rule = re.compile(r"[^\u4e00-\u9fa5]")
line = reader.read()
content = rule.sub('', line)
initial_words = jieba.lcut(content) # jieba分词获得初始文字列表
processed_words = train.remove_stop_words(initial_words) # 删除停用词
words = list(set(processed_words)) # 去掉列表中的重复值
p_sW = 1 # 代表的是P(s|w_1, w_2, .......,w_n)
p_Ws = 1 # 代表, P(w_1, w_2,......, w_n | s)
p_Wh = 1
for i in range(0, len(words)):
# id的转换
if words[i] in word_to_id_map.keys():
id = word_to_id_map[words[i]]
p_Ws *= conditional_wh_and_ws[id][1] # 朴素贝叶斯模型, 假设变量的各特征是相互独立的
p_Wh *= conditional_wh_and_ws[id][0] # 所以, P(w_1,w_2,.....,w_n|s) = P(w_1|s)*P(w_2|s)*....*P(w_n|s)
else:
p_Ws *= 0.4 # 如果一个单词之前从没出现过, 无法从历史资料中获取P(w|s), 假定其等于0.4,
p_Wh *= 0.6 # 因为垃圾邮件用的往往是固定的词语, 如果这个单词从没出现过, 那它多半是正常的词
# p_sW = (p_Ws * p_s) / (p_Ws * p_s + p_Wh * p_h)
# p_hW = (p_Wh * p_h) / (p_Ws * p_s + p_Wh * p_h)
p_sW = (p_Ws * p_s) # 因为分母一样, 所以只考虑分子最大化
p_hW = (p_Wh * p_h)
return p_sW, p_hW
# 从指定文件夹下读取全部文件,进行条件概率P(s|W)的运算
def read_files_to_predict(path):
files = os.listdir(path)
category = {} # 记录分类
for name in files:
file = os.path.join(path, name)
(p_sW, p_hW) = calculate_conditional_sW(file)
if p_sW > p_hW:
category[name] = 1 # 1表示垃圾邮件
else:
category[name] = 0 # 0表示健康邮件
print("哈哈",category)
return category
# 计算并输出准确率
def show_result(category):
accuracy = 1 # 准确率
correct_quantity = 0 # 被正确分类的数目
for name in category.keys():
if int(name) >= 200: # 则应该是垃圾邮件
if category[name] == 1:
correct_quantity += 1
else: # 应该是健康邮件
if category[name] == 0:
correct_quantity += 1
accuracy = correct_quantity / len(category.keys())
print("精确率为: "+ str(accuracy))
# 从持久化的文件中读取模型的参数, 填充给相应变量
def read_model_from_file():
file_vocabulary = 'FirstByesSpam/data/file_vocabulary.txt'
file_id_map = 'FirstByesSpam/data/file_id_map.txt'
print(os.path.abspath(os.path.curdir))
with open(file_vocabulary, 'r', encoding='utf-8') as reader:
for line in reader.readlines():
list = line.strip().split('\t')
if len(list) == 2:
conditional_wh_and_ws.append([float(list[0]), float(list[1])])
with open(file_id_map, 'r', encoding='utf-8') as reader:
for line in reader.readlines():
list = line.strip().split('\t')
if len(list) == 2:
word_to_id_map[list[0]] = int(list[1])
def predict_text(reader):
"""
预测一个文本
:param content:
:return:
"""
read_model_from_file()
# 转换词汇表中全部
calculate_conditional_hw_and_sw(conditional_wh_and_ws)
# (p_sW, p_hW) = calculate_conditional_sW("../data/test/1")
# print(p_sW)
# 过滤掉非中文字符
rule = re.compile(r"[^\u4e00-\u9fa5]")
line = reader
content = rule.sub('', line)
initial_words = jieba.lcut(content) # jieba分词获得初始文字列表
processed_words = train.remove_stop_words(initial_words) # 删除停用词
words = list(set(processed_words)) # 去掉列表中的重复值
p_sW = 1 # 代表的是P(s|w_1, w_2, .......,w_n)
p_Ws = 1 # 代表, P(w_1, w_2,......, w_n | s)
p_Wh = 1
for i in range(0, len(words)):
# id的转换
if words[i] in word_to_id_map.keys():
id = word_to_id_map[words[i]]
p_Ws *= conditional_wh_and_ws[id][1] # 朴素贝叶斯模型, 假设变量的各特征是相互独立的
p_Wh *= conditional_wh_and_ws[id][0] # 所以, P(w_1,w_2,.....,w_n|s) = P(w_1|s)*P(w_2|s)*....*P(w_n|s)
else:
p_Ws *= 0.4 # 如果一个单词之前从没出现过, 无法从历史资料中获取P(w|s), 假定其等于0.4,
p_Wh *= 0.6 # 因为垃圾邮件用的往往是固定的词语, 如果这个单词从没出现过, 那它多半是正常的词
# p_sW = (p_Ws * p_s) / (p_Ws * p_s + p_Wh * p_h)
# p_hW = (p_Wh * p_h) / (p_Ws * p_s + p_Wh * p_h)
p_sW = (p_Ws * p_s) # 因为分母一样, 所以只考虑分子最大化
p_hW = (p_Wh * p_h)
if p_sW > p_hW:
return 1 # 1表示垃圾邮件
else:
return 0 # 0表示健康邮件
if __name__ == '__main__':
# 这里需要注意小数相乘的精度损失, 如果有必要的话, 可以将连乘转换成对数相加比较大小;
# 词集模式, 只关心某个单词是否出现在邮件中, 至于出现次数>1, 并不关心;
# 词袋模式, 不仅关心单词是否出现, 还关心单词出现的次数;
# train.read_file_to_train('../data/normal', 0)
# train.read_file_to_train('../data/spam', 1)
# train.calculate_occurrence_frequency()
# conditional_wh_and_ws = copy.deepcopy(train.vocabulary)
# word_to_id_map = copy.deepcopy(train.word_to_id_map)
read_model_from_file()
# 转换词汇表中全部
calculate_conditional_hw_and_sw(conditional_wh_and_ws)
# (p_sW, p_hW) = calculate_conditional_sW("../data/test/1")
# print(p_sW)
category = read_files_to_predict('FirstByesSpam/data/test')
print(category)
show_result(category)
import jieba
import re
import numpy as np
import os
# 是一个二维列表, vocabuary[i][x, y]表示第i个单词, 在健康邮件中出现的次数(或者说出现有该单词的健康邮件的数目)为x, 在垃圾邮件中出现的次数是y
vocabulary = [] # 维持一个词汇表, 存储训练语料库里所有的单词, 以及它们分别在healthy email和spam的出现次数
word_to_id_map = {}
quantity_email = [0, 0] # 一维列表, q[0]是训练集中健康邮件的数量, q[1]是训练集中垃圾邮件的数量
# 获取停用词列表
def get_stop_words():
stop_words = []
with open('FirstByesSpam/data/中文停用词表.txt', 'r', encoding='gbk') as reader:
for word in reader.readlines():
stop_words.append(word.strip())
return stop_words
# 对输入的文档, 删除掉停用词
def remove_stop_words(pre_list):
after_result = []
stop_words = get_stop_words() # 停用词列表;
for w in pre_list:
if w not in stop_words:
after_result.append(w)
# print(after_result)
return after_result
# 读取指定文件夹下所有文件, 进行训练过程
# path = '../data/normal' or 'spam'
# sign = 0 or 1, 0对应的是健康邮件, 1代表spam
def read_file_to_train(path, sign):
files = os.listdir(path)
# 记录两类邮件数
quantity_email[sign] = len(files)
for name in files:
file = os.path.join(path, name) # 单个文件的完整路径
calculate_occurrence_count(file, sign)
# 该篇邮件中所有出现的单词, 在该分类下的出现次数都加1
def calculate_occurrence_count(file, sign):
with open(file, 'r', encoding='gbk') as reader:
# 过滤掉非中文字符
rule = re.compile(r"[^\u4e00-\u9fa5]")
line = reader.read()
content = rule.sub('', line)
initial_words = jieba.lcut(content) # jieba分词获得初始文字列表
processed_words = remove_stop_words(initial_words) # 删除停用词
words = list(set(processed_words)) # 去掉列表中的重复值
for w in words:
if w not in word_to_id_map.keys():
vocabulary.append([0, 0]) # 在词汇表中新增一个位置记录两个频数
word_to_id_map[w] = len(vocabulary)-1 # 在映射map里记录好单词w和id的对应关系
vocabulary[word_to_id_map[w]][sign] +=1 # 当前单词在sign分类下频数+1
# print(vocabulary)
# print(word_to_id_map)
# 结合输出vocabulary和word_to_id_map
def try_show():
for w in word_to_id_map.keys():
id = word_to_id_map[w]
print(w + '\t' + str(vocabulary[id][0]) + '\t' + str(vocabulary[id][1]))
# 将频数转换成频率
def calculate_occurrence_frequency():
for i in range(0, len(vocabulary)):
vocabulary[i][0] = vocabulary[i][0] / quantity_email[0]
vocabulary[i][1] = vocabulary[i][1] / quantity_email[1]
if vocabulary[i][0] == 0.0: # 如果一个词在健康邮件中出现次数为0, 为了避免概率为0, 影响连乘计算, 我们就假定它在正常邮件中出现的频率是0.01
vocabulary[i][0] = 0.01
if vocabulary[i][1] == 0.0:
vocabulary[i][1] = 0.01
# 将模型的参数保存到本地, 实现持久化
# vocabulary, word_to_id_map
def write_model_to_file():
file_vocabulary = '../data/file_vocabulary.txt'
with open(file_vocabulary, 'w') as writer: # open, 若不存在, 自动会新建
for i in range(0, len(vocabulary)):
writer.write(str(vocabulary[i][0]) + '\t' + str(vocabulary[i][1]) + '\n')
file_id_map = '../data/file_id_map.txt'
with open(file_id_map, 'w') as writer:
for key, value in word_to_id_map.items():
writer.write(str(key) + '\t' + str(value) + '\n')
if __name__ == "__main__":
read_file_to_train('../data/normal', 0)
read_file_to_train('../data/spam', 1)
calculate_occurrence_frequency()
write_model_to_file()
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 22
22 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)