从零开始的机器学习之路(十二)---- Optional Lab 18-20 Sklearn实现逻辑回归&过拟合&正则化
·
前引
还有三篇 一个Lab 好吧
今晚之前都要把这些lab写完 学一下
从零开始的机器学习之路(十二)---- Optional Lab 18-20 Sklearn实现逻辑回归&过拟合&正则化
1、 Optional Lab 18 Sklearn实现逻辑回归
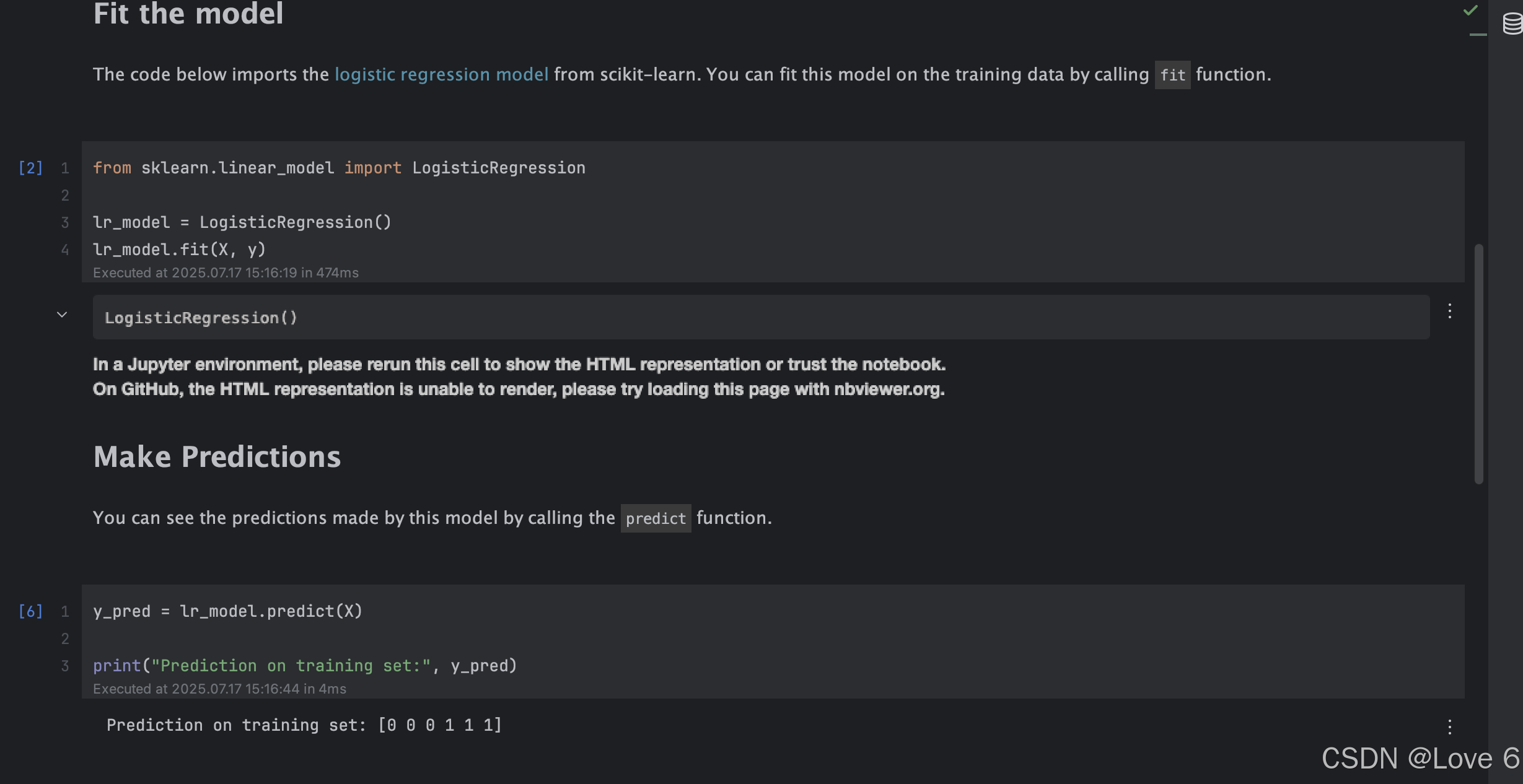
1、Logistic Regression using Scikit-Learn Start
本质上这个也比较简单 两个函数调用一下 fit predict
一张图概括下面的lab LogisticRegression生成model 确实很方便很好用 😃
predict 则是我们可以根据现在的值给出具体结果 就这么简单~
2、Optional Lab 19 过拟合
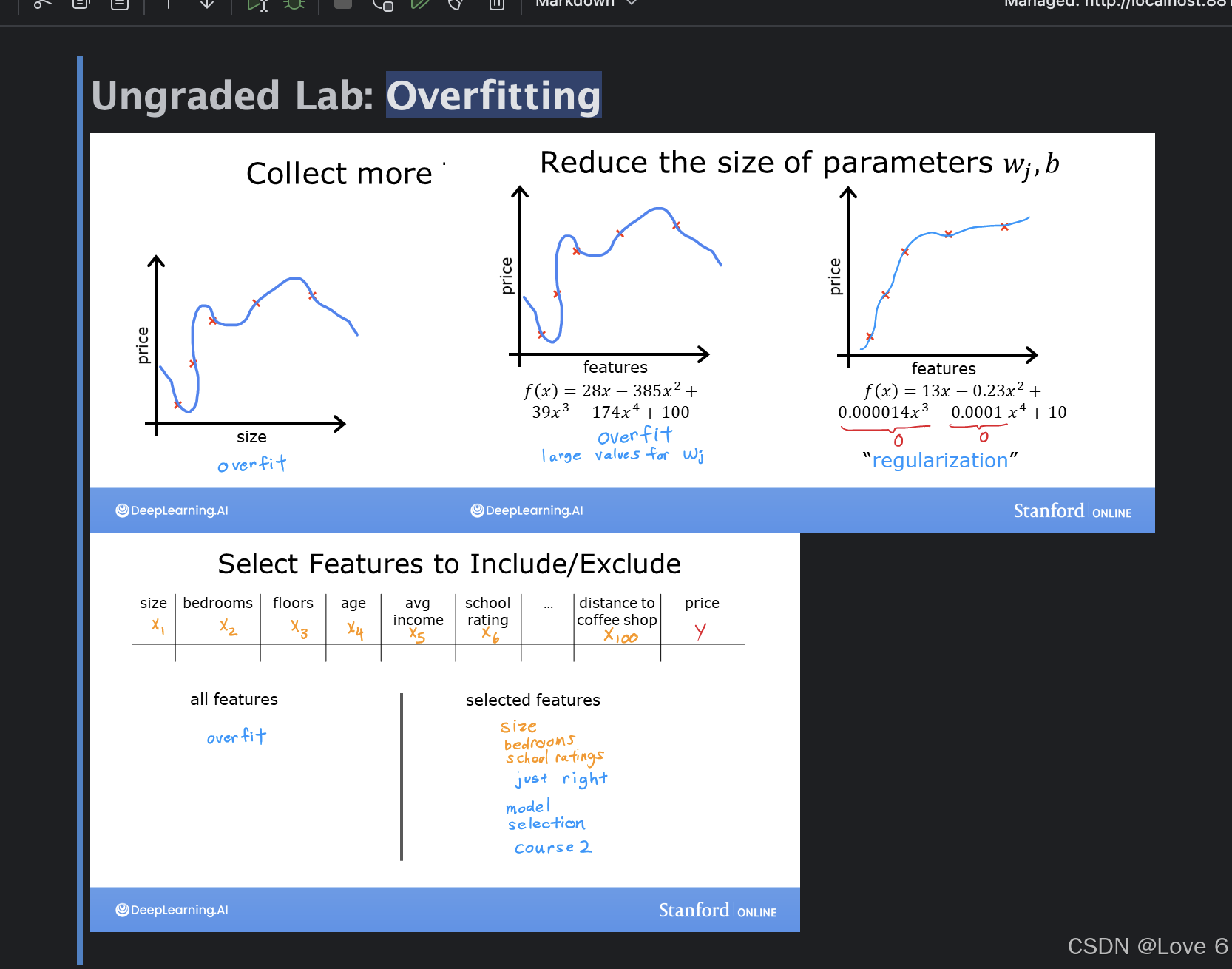
1、Overfitting Start
其实这里就是简单的展示过拟合的情况 很简单
简单说一下概念 也就是 模拟情况 训练模型对于数据过于拟合 或者 紧凑 那对于后续新的数据 或者 需要得到预期结果的数据 是没有办法预测出来的 一张图就可以展示这一节的内容
但由于最下面的展示 展示不出来 这一涨就先略过吧。。。
3、Optional Lab 20 正则化
1、Regularized Cost and Gradient Start
其实这一章最主要就在介绍正则化 参数惩罚 这样对于部分复杂的参数类型 可以用正则化的方式来对部分w惩罚 来达到平和化每个参数
2、Cost functions with regularization
正则化 其实后面就是对数据进行 一个lambda_ 乘上我们的w 其实可以参考视频
也就是每一次我们的w 都是乘上一个小于1的数 其实本质上就是这样进行的

3、Comupte Cost With Regularization
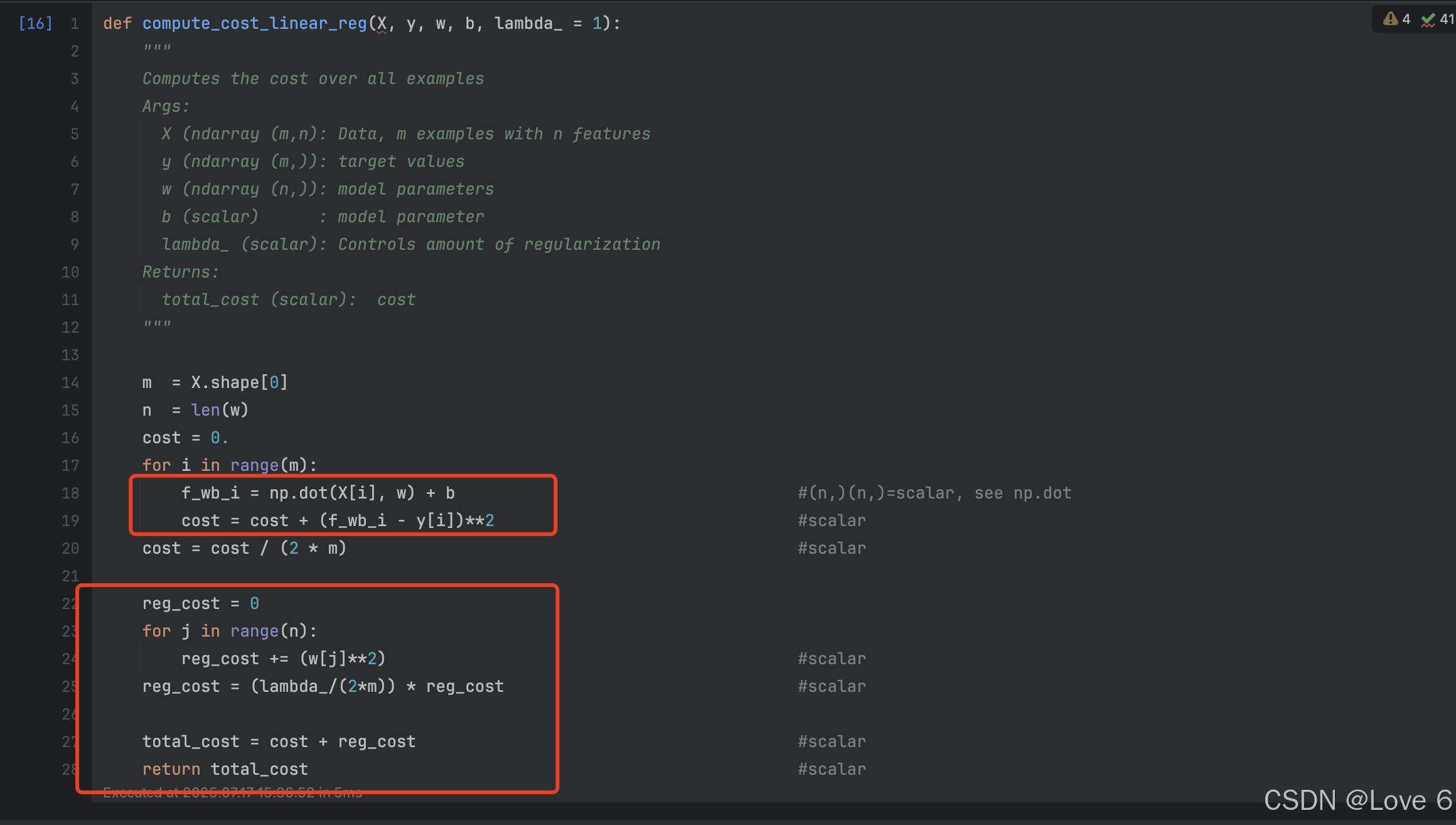
1、线性回归
实际代码实现去计算我们的开销函数
def compute_cost_linear_reg(X, y, w, b, lambda_ = 1):
"""
Computes the cost over all examples
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
lambda_ (scalar): Controls amount of regularization
Returns:
total_cost (scalar): cost
"""
m = X.shape[0]
n = len(w)
cost = 0.
for i in range(m):
f_wb_i = np.dot(X[i], w) + b #(n,)(n,)=scalar, see np.dot
cost = cost + (f_wb_i - y[i])**2 #scalar
cost = cost / (2 * m) #scalar
reg_cost = 0
for j in range(n):
reg_cost += (w[j]**2) #scalar
reg_cost = (lambda_/(2*m)) * reg_cost #scalar
total_cost = cost + reg_cost #scalar
return total_cost #scalar
2、逻辑回归
下面其实按照公式走的
def compute_cost_logistic_reg(X, y, w, b, lambda_ = 1):
"""
Computes the cost over all examples
Args:
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
lambda_ (scalar): Controls amount of regularization
Returns:
total_cost (scalar): cost
"""
m,n = X.shape
cost = 0.
for i in range(m):
z_i = np.dot(X[i], w) + b #(n,)(n,)=scalar, see np.dot
f_wb_i = sigmoid(z_i) #scalar
cost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i) #scalar
cost = cost/m #scalar
reg_cost = 0
for j in range(n):
reg_cost += (w[j]**2) #scalar
reg_cost = (lambda_/(2*m)) * reg_cost #scalar
total_cost = cost + reg_cost #scalar
return total_cost #scalar
4、梯度下降
参考下面的函数
1、线性回归
def compute_gradient_linear_reg(X, y, w, b, lambda_):
"""
Computes the gradient for linear regression
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
lambda_ (scalar): Controls amount of regularization
Returns:
dj_dw (ndarray (n,)): The gradient of the cost w.r.t. the parameters w.
dj_db (scalar): The gradient of the cost w.r.t. the parameter b.
"""
m,n = X.shape #(number of examples, number of features)
dj_dw = np.zeros((n,))
dj_db = 0.
for i in range(m):
err = (np.dot(X[i], w) + b) - y[i]
for j in range(n):
dj_dw[j] = dj_dw[j] + err * X[i, j]
dj_db = dj_db + err
dj_dw = dj_dw / m
dj_db = dj_db / m
for j in range(n):
dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j]
return dj_db, dj_dw
2、逻辑回归
def compute_gradient_logistic_reg(X, y, w, b, lambda_):
"""
Computes the gradient for linear regression
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
lambda_ (scalar): Controls amount of regularization
Returns
dj_dw (ndarray Shape (n,)): The gradient of the cost w.r.t. the parameters w.
dj_db (scalar) : The gradient of the cost w.r.t. the parameter b.
"""
m,n = X.shape
dj_dw = np.zeros((n,)) #(n,)
dj_db = 0.0 #scalar
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b) #(n,)(n,)=scalar
err_i = f_wb_i - y[i] #scalar
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j] #scalar
dj_db = dj_db + err_i
dj_dw = dj_dw/m #(n,)
dj_db = dj_db/m #scalar
for j in range(n):
dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j]
return dj_db, dj_dw

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)