机器学习-分类之支持向量机(SVM)原理及实战
支持向量机(SVM)
简介
支持向量机(Support Vector Machine,SVM),是常见的一种判别方法。在机器学习领域,是一个监督学习模型,通常用来进行模式识别、分类及回归分析。与其他算法相比,支持向量机在学习复杂的非线性方程时提供了一种更为清晰、更加强大的方式。
支持向量机是20世纪90年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,也能获得良好统计规律的目的。
通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
原理
几个概念
线性可分
如图,数据之间分隔得足够开,很容易在图中画出一条直线将这一组数据分开,这组数据就被称为线性可分数据。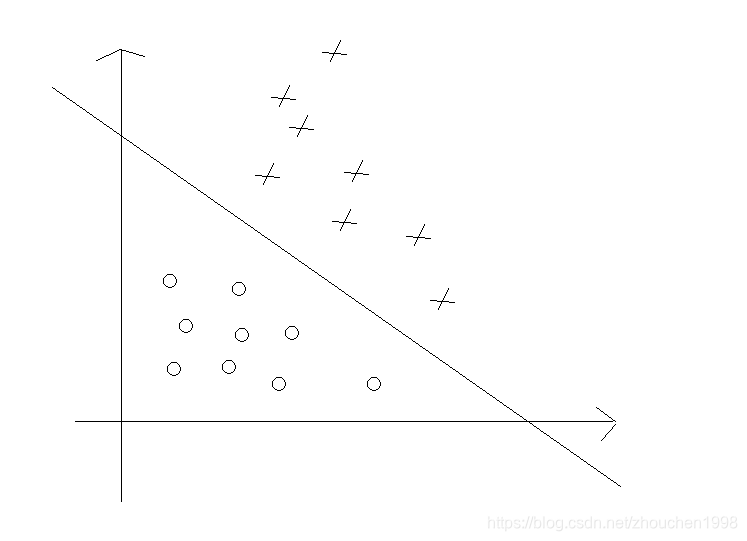
分隔超平面
上述将数据集分隔开来的直线称为分隔超平面,由于上面给出的数据点都在二维平面上,所以此时的分隔超平面是一条直线。如果给出的数据集点是三维的,那么用来分隔数据的就是一个平面。因此,更高维的情况可以以此类推,如果数据是100维的,那么就需要一个99维的对象来对数据进行分隔,这些统称为超平面。
间隔
如图片所示,这条分隔线的好坏如何呢?我们希望找到离分隔超平面最近的点,确保它们离分割面的距离尽可能远。在这里点到分隔面的距离称为间隔。间隔尽可能大是因为如果犯错或在有限数据上训练分类器,我们希望分类器尽可能健壮。
支持向量
离分隔超平面最近的那些点是支持向量。
求解
接下来就是要求解最大支持向量到分隔面的距离,需要找到此类问题的求解方法。如图,分隔超平面可以写成 w T x + b w^Tx+b wTx+b。要计算距离,值为 ∣ w T A + b ∣ ∣ ∣ w ∣ ∣ \frac{|w^TA+b|}{||w||} ∣∣w∣∣∣wTA+b∣。这里的向量w和常数b一起描述了所给数据的超平面。
对 w T x + b w^Tx+b wTx+b使用单位阶跃函数得到 f ( w T x + b ) f(w^Tx+b) f(wTx+b),其中当 u < 0 u<0 u<0时, f ( u ) f(u) f(u)输出-1,反之则输出+1。这里使用-1和+1是为了教学上的方便处理,可以通过一个统一公式来表示间隔或数据点到分隔超平面的距离。间隔通过 l a b e l × ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ label\times{|w^Tx+b| \over ||w||} label×∣∣w∣∣∣wTx+b∣来计算。如果数据处在正方向(+1)类里面且离分隔超平面很远的位置时, w T x + b w^Tx+b wTx+b是一个很大的正数。同时 l a b e l × ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ label\times{|w^Tx+b| \over ||w||} label×∣∣w∣∣∣wTx+b∣也会是一个很大的正数。如果数据点处在负方向(-1)类且离分隔超平面很远的位置时,由于此时类别标签为-1, l a b e l × ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ label\times{\frac{|w^Tx+b|}{||w||}} label×∣∣w∣∣∣wTx+b∣仍然是一个很大的正数。
为了找到具有最小间隔的数据点,就要找到分类器中定义的 w w w和 b b b,最小间隔的数据点也就是支持向量。一旦找到支持向量,就需要对该间隔最大化,可以写作 max w , b ( min n ( l a b e l × ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ ) ) \max_{w,b}\left(\min_n(label\times{|w^Tx+b| \over ||w||})\right) w,bmax(nmin(label×∣∣w∣∣∣wTx+b∣))
但是直接求解上述问题是非常困难的,所以这里引入拉格朗日乘子法,可以把表达式写成下面的式子:
max _ α [ ∑ _ i = 1 m α 1 2 ∑ _ i , j = 1 m l a b e l ( i ) × α _ i × α _ j ( x ( i ) , x ( j ) ) ] {\max\_{\alpha}}\left[\sum\_{i=1}^m\alpha \frac{1}{2}\sum\_{i,j=1}^mlabel^{(i)}\times \alpha\_i\times\alpha\_j{(x^{(i)},x^{(j)})} \right] max_α[∑_i=1mα21∑_i,j=1mlabel(i)×α_i×α_j(x(i),x(j))]
其中 × \times ×表示,两个向量的内积。约束条件为 C ≥ α ≥ 0 C\geq\alpha\geq0 C≥α≥0 ∑ i − 1 m α _ i × l a b e l ( i ) = 0 \sum_{i-1}^m \alpha\_i\times label^{(i)}=0 i−1∑mα_i×label(i)=0
这里的常数C用于控制最大化间隔和保证大部分点的函数间隔小于1.0这两个目标的权重。因为所有数据都可能有干扰数据,所以通过引入所谓的松弛变量,允许有些数据点可以处于分隔面错误的一侧。
根据上式可知,只要求出所有的 α \alpha α,那么分隔面就可以通过 α \alpha α来表达,SVM的主要工作就是求 α \alpha α。这样一步步解出分隔面,那么分类问题游刃而解。
算法优势
- 泛化错误率低,具有良好的学习能力。
- 几乎所有分类问题都可以使用SVM解决。
- 节省内存开销。
实战
实现手写识别系统
为了简单起见,这里的手写识别只针对0到9的数字,为了方便,图像转为了文本。目录trainingDigits中含有2000个例子,用于训练,目录testDigits含有900个例子,用于测试。
虽然手写识别可以用KNN实现而且效果不错,但是KNN毕竟太占内存了,而且要保证性能不变的同时使用较少的内存。而对于SVM,只需要保留很少的支持向量就可以实现目标效果。
- 流程
- 准备数据
- 分析数据
- 使用SMO算法求出 α \alpha α和 b b b
- 训练算法
- 测试算法
- 使用算法
代码实现
# -*- coding=UTF-8 -*-
from numpy import *
def clipAlpha(aj, H, L):
'''
辅助函数,调整a的范围
:param aj:
:param H:
:param L:
:return:
'''
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def kernelTrans(X, A, kTup):
'''
修改kernel
:param X:
:param A:
:param kTup:
:return:
'''
m, n = shape(X)
K = mat(zeros((m, 1)))
if kTup[0] == 'lin':
K = X * A.T
elif kTup[0] == 'rbf':
for j in range(m):
deltaRow = X[j, :] - A
K[j] = deltaRow*deltaRow.T
# numpy中除法意味着对矩阵展开计算而不是matlab的求矩阵的逆
K = exp(K/(-1*kTup[1]**2))
# 如果遇到无法识别的元组,程序抛出异常
else:
raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
return K
class optStruct:
'''
保存所有重要值,实现对成员变量的填充
'''
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #误差缓存
self.K = mat(zeros((self.m,self.m)))
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def calcEk(oS, k):
'''
计算E值 计算误差
:param oS:
:param k:
:return:
'''
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJrand(i, m):
'''
:param i: a的下标
:param m: a的总数
:return:
'''
j = i
while (j == i):
# 简化版SMO,alpha随机选择
j = int(random.uniform(0, m))
return j
def selectJ(i, oS, Ei):
'''
选择第二个a的值以保证每次优化的最大步长(内循环)
:param i:
:param oS:
:param Ei:
:return:
'''
maxK = -1
maxDeltaE = 0
Ej = 0
oS.eCache[i] =[1, Ei]
validEcacheList = nonzero(oS.eCache[:, 0].A)[0]
if(len(validEcacheList)) > 1:
for k in validEcacheList:
if k == i:
continue
Ek = calcEk(oS, k)
deltaE = abs(Ei-Ek)
if(deltaE > maxDeltaE):
maxK = k
maxDeltaE = deltaE
Ej = Ek
return maxK, Ej
else:
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEk(oS, k):
'''
计算误差值并存入缓存中
:param oS:
:param k:
:return:
'''
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
def innerL(i, oS):
'''
选择第二个a
:param i:
:param oS:
:return:
'''
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j, Ej = selectJ(i, oS, Ei)
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy()
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H:
print("L==H")
return 0
eta = 2.0 * oS.K[i, j] - oS.K[i, i] - oS.K[j, j]
if eta >= 0:
print("eta>=0")
return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
updateEk(oS, j)
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
print ("j not moving enough")
return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
updateEk(oS, i)
b1 = oS.b - Ei - oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i, i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i, j]
b2 = oS.b - Ej - oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i, j] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j, j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
oS.b = b2
else:
oS.b = (b1 + b2)/2.0
return 1
else:
return 0
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)):
'''
实现platt smo算法
:param dataMatIn:
:param classLabels:
:param C:
:param toler:
:param maxIter:
:param kTup:
:return:
'''
oS = optStruct(mat(dataMatIn), mat(classLabels).transpose(), C, toler, kTup)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i, oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
iter += 1
else:
nonBoundIs = nonzero((oS.alphas.A > 0) *
(oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i, oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
iter += 1
if entireSet:
entireSet = False
elif (alphaPairsChanged == 0):
entireSet = True
print("迭代次数: %d" % iter)
return oS.b, oS.alphas
def img2vector(filename):
'''
二值化图像转为向量
32*32转为1*1024
:param filename: 文件名
:return: 向量
'''
returnVect = zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32*i+j] = int(lineStr[j])
return returnVect
def loadImages(dirName):
'''
导入数据集
:param dirName:
:return:
'''
from os import listdir
hwLabels = []
trainingFileList = listdir(dirName)
m = len(trainingFileList)
trainingMat = zeros((m, 1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
# 这里是二分类问题,只分类数字1和9,数字分类结果为9时返回-1
if classNumStr == 9:
hwLabels.append(-1)
else:
hwLabels.append(1)
trainingMat[i, :] = img2vector('%s/%s' % (dirName, fileNameStr))
return trainingMat, hwLabels
def testDigits(kTup=('rbf', 10)):
'''
测试算法,使用smop训练
:param kTup: 核函数
:return:
'''
dataArr, labelArr = loadImages('data/trainingDigits')
b, alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, kTup)
datMat = mat(dataArr)
labelMat = mat(labelArr).transpose()
svInd = nonzero(alphas.A > 0)[0]
sVs = datMat[svInd]
labelSV = labelMat[svInd]
print("有 %d 支持向量" % shape(sVs)[0])
m, n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs, datMat[i, :], kTup)
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
if sign(predict) != sign(labelArr[i]):
errorCount += 1
print("训练数据错误率是: %f" % (float(errorCount)/m))
dataArr, labelArr = loadImages('data/testDigits')
errorCount = 0
datMat = mat(dataArr)
labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs, datMat[i, :], kTup)
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
if sign(predict) != sign(labelArr[i]):
errorCount += 1
print("测试数据错误率是: %f" % (float(errorCount)/m))
def loadDataSet(filename):
'''
加载数据集
:param filename: 文件名
:return:
'''
dataMat = []
labelMat = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
if __name__ == '__main__':
testDigits(('rbf', 20))
补充说明
参考书《Python3数据分析与机器学习实战》,具体数据集和代码可以查看我的GitHub,欢迎star或者fork。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 1
1 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)