《统计学习方法》之朴素贝叶斯方法结合python实现
·
文章目录
在机器学习中,贝叶斯优化(Bayesian Optimization)是一种智能的调参方法,在尽可能少的试验次数下找到最好的参数组合;文本分类、故障医疗诊断、图像识别与计算机视觉中贝叶斯算法利用概率来量化不确定性,现有知识(先验)和新数据(似然) 来更新对世界的认知(后验)。这使得它在人工智能、机器学习、统计学、工程学、医学、经济学等众多领域都成为不可或缺的工具。
在最近看完了李航老师的《统计学习方法》中第四章的朴素贝叶斯法,结合书中理论和python代码实践,总结及积累一下知识。
1. 基本理论
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法,对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入 x x x,利用贝叶斯定理求出后验概率最大的输出 y y y。
总结核心思想就是:在给定特征条件下,计算一个样本属于某个类别的后验概率,并选择后验概率最大的类别作为该样本的预测类别。
先回顾一下贝叶斯定理
贝叶斯定理是朴素贝叶斯分类器的核心思想,它描述了在已知某些条件下,事件发生的概率。
1.1 朴素贝叶斯基本方法介绍
关于朴素贝叶斯基本方法的理论理解也可以参考这些优秀文章
手把手带你推导“朴素贝叶斯分类”核心公式
朴素贝叶斯深度解码:从原理到深度学习应用

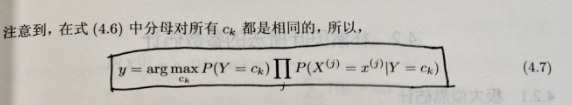
1.2 后验概率最大化

1.3 参数估计
1.3.1 极大似然估计

1.3.2 贝叶斯估计

1.4 朴素贝叶斯算法总结

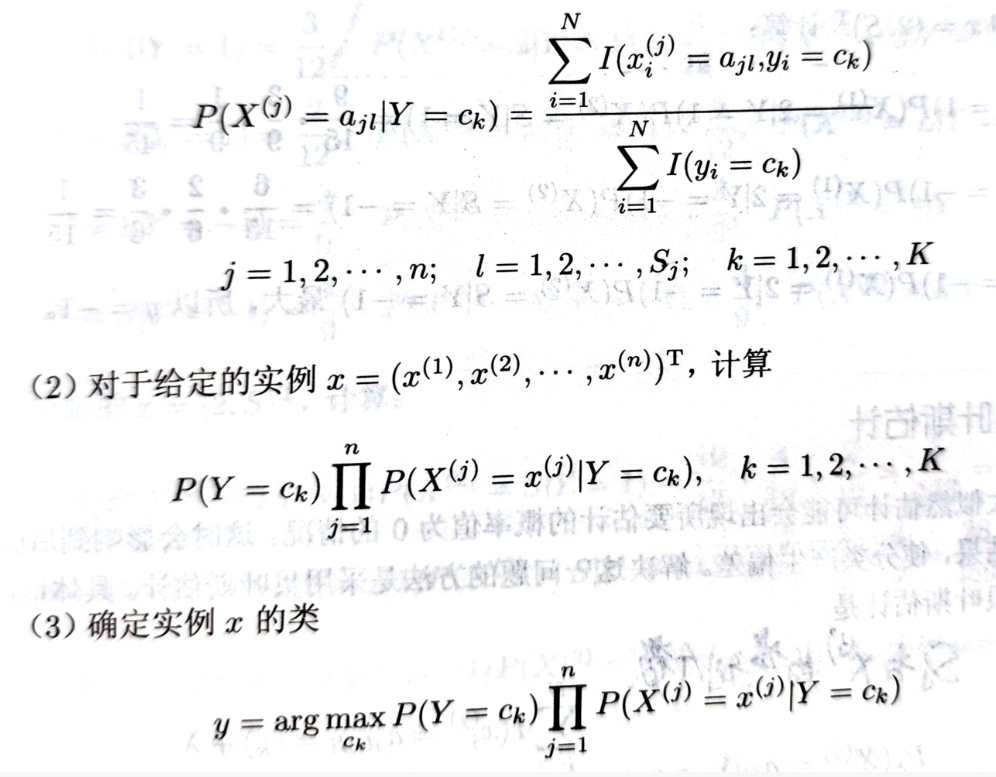
1.5 计算案例
每次公式推导感觉理解比较抽象的时候,可以直接看例题,回过头再看案例,感觉很帮助理解。
1.5.1 案例1——极大似然估计参数

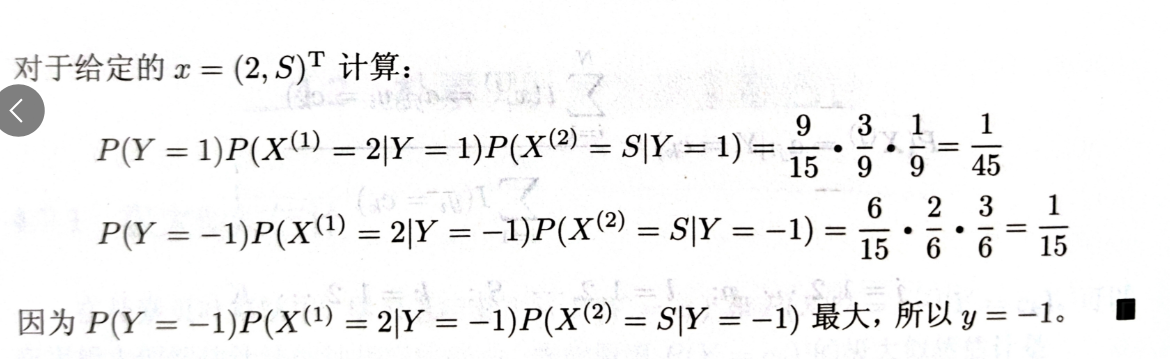
1.5.2 案例2——贝叶斯估计参数


2. 朴素贝叶斯方法分类
根据特征(属性)的不同类型和分布假设,朴素贝叶斯主要有以下几种分类(变体)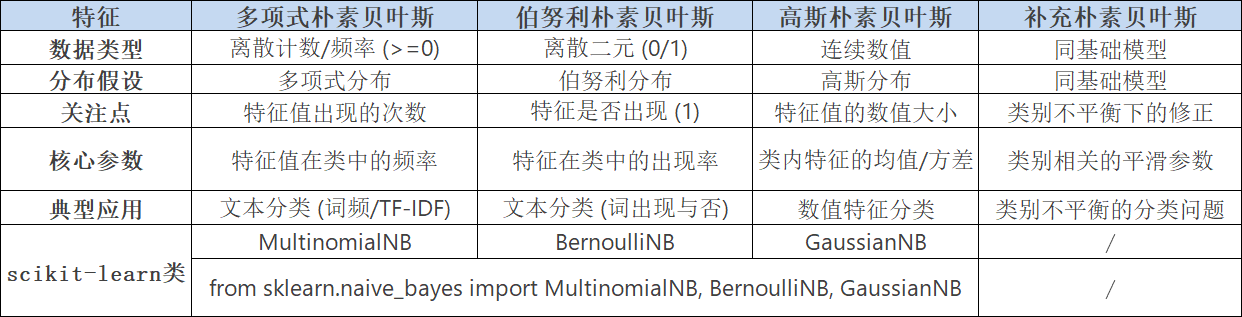



3. python代码实现
3.1 高斯朴素贝叶斯实现鸢尾花分类——GaussianNB
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 加载 Iris 数据集
iris = datasets.load_iris()
X, y = iris.data, iris.target # X 为特征, y 为标签
feature_names = iris.feature_names
class_names = iris.target_names
# 选择前两个特征用于可视化
X_vis = X[:, :2] # 选择前两个特征 (sepal length, sepal width)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_vis, y, test_size=0.2, random_state=42)
# 初始化高斯朴素贝叶斯分类器
gnb = GaussianNB()
# 训练模型
gnb.fit(X_train, y_train)
# 进行预测
y_pred = gnb.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
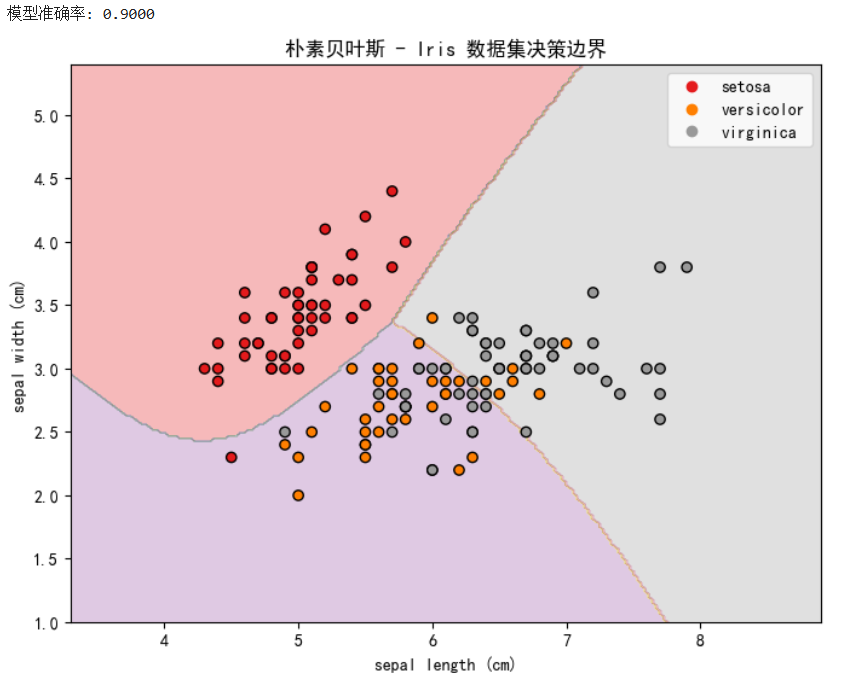
print(f"模型准确率: {accuracy:.4f}")
# 绘制决策边界
def plot_decision_boundary(X, y, model, title="决策边界可视化"):
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200), np.linspace(y_min, y_max, 200))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Set1)
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', cmap=plt.cm.Set1)
# 添加图例
legend_labels = [class_names[i] for i in range(len(class_names))]
handles, _ = scatter.legend_elements()
plt.legend(handles, legend_labels, loc="upper right")
plt.xlabel(feature_names[0])
plt.ylabel(feature_names[1])
plt.title(title)
plt.show()
def CONF_matrix(y_test, y_pred):
conf_matrix = metrics.confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="Blues", xticklabels=iris.target_names, yticklabels=iris.target_names)
plt.xlabel('预测')
plt.ylabel('实际')
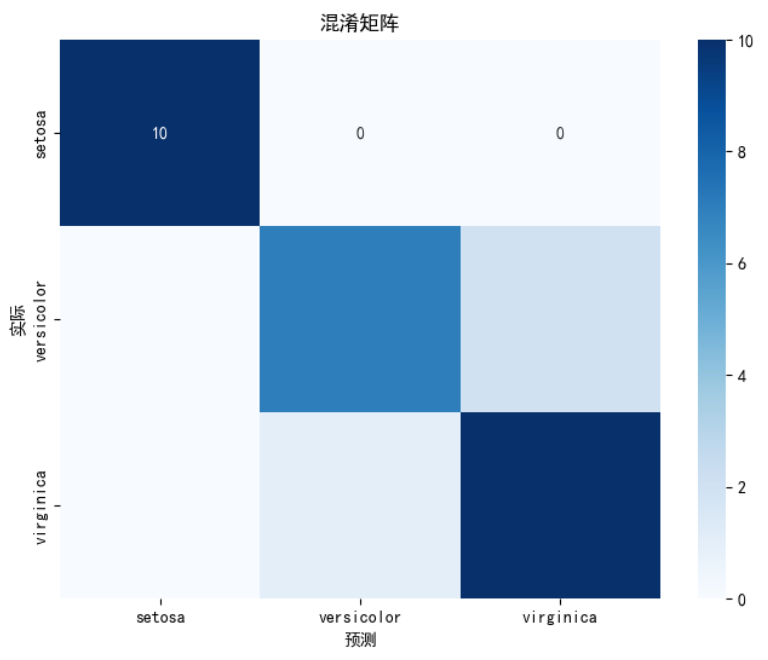
plt.title('混淆矩阵')
plt.show()
# 显示决策边界
plot_decision_boundary(X_vis, y, gnb, title="朴素贝叶斯 - Iris 数据集决策边界")
# 混淆矩阵
CONF_matrix(y_test, y_pred)
3.2 多项式朴素贝叶斯——MultinomialNB
# 导入所需库
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
import seaborn as sns
import matplotlib.pyplot as plt
# 1. 加载数据集(选择两个类别作为示例)
categories = ['sci.space', 'comp.graphics']
newsgroups_train = fetch_20newsgroups(subset='train', categories=categories, remove=('headers', 'footers', 'quotes'))
newsgroups_test = fetch_20newsgroups(subset='test', categories=categories, remove=('headers', 'footers', 'quotes'))
# 2. 创建文本处理管道(TF-IDF向量化 + 多项式朴素贝叶斯)
model = make_pipeline(
TfidfVectorizer(stop_words='english', max_features=10000), # 限制特征数量
MultinomialNB(alpha=0.1) # 拉普拉斯平滑参数
)
# 3. 训练模型
model.fit(newsgroups_train.data, newsgroups_train.target)
# 4. 预测测试集
predicted = model.predict(newsgroups_test.data)
# 5. 评估模型
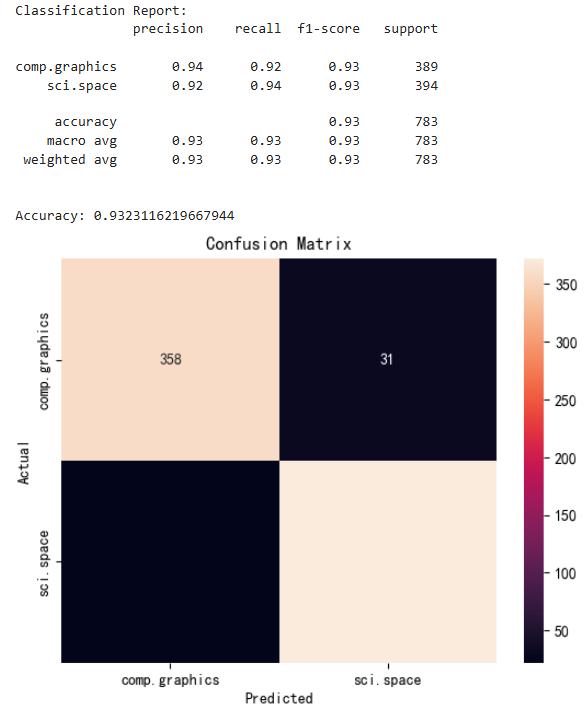
print("Classification Report:")
print(classification_report(newsgroups_test.target, predicted, target_names=newsgroups_test.target_names))
print("\nAccuracy:", accuracy_score(newsgroups_test.target, predicted))
# 6. 可视化混淆矩阵
conf_mat = confusion_matrix(newsgroups_test.target, predicted)
sns.heatmap(conf_mat, annot=True, fmt='d',
xticklabels=newsgroups_test.target_names,
yticklabels=newsgroups_test.target_names)
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.title('Confusion Matrix')
plt.show()

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)