面向非结构化扫描PDF的大语言模型知识图谱生成框架
导读:
本文提出一种融合多模态大语言模型与图像增强技术的知识图谱生成框架,旨在解决非结构化扫描版数学教材处理中的三大核心难题:低质量文本识别、数学符号语义解析及知识体系结构化建模。针对扫描PDF图像模糊、公式识别困难等问题,设计多阶段图像增强流程,显著提升文本提取置信度。创新采用双模型协同架构:智谱清言模型负责增强图像的内容提取,DeepSeek模型完成实体关系抽取与三元组构建。通过章节节点动态容器化、游离节点三级消解策略,在Neo4j中实现数学概念的逻辑化存储与可视化关联网络。
作者信息:
刘建民, 肖维维:北方工业大学理学院,北京
论文详情
本文主要是通过LLM与知识图谱结合的方式处理非结构化扫描PDF的《数学分析》教材。
知识图谱(Knowledge Graph)于2012年由谷歌公司提出并快速发展,它是一种以结构化形式组织和表达知识的语义网络,其核心逻辑是通过“实体–关系–实体”的三元组(如<爱因斯坦,提出,相对论>)构建关联网络,这种图结构将碎片化信息转化为具有逻辑关联的知识体系,使机器能够理解数据背后的含义,并让原本孤立的知识点建立起联系,使得抽象复杂的关系可视化、清晰化。
由于非结构化扫描PDF的页面属性是图像,且绝大多数图像上的文本信息是比较模糊或者低对比度字体,在进行图像增强的基础上,使用PyMuPDF、OCR (EasyOCR, Tesseract OCR)等工具进行文本内容提取,效果很差。
因此,在图像增强后,本文利用智谱清言的Glm-4.1V-Thinking-Flashx模型提取文本内容,置信度为75.52%~90.62%,平均置信为85.19%,CER为7.63%,WER为9.8%。不使用增强置信度为68.49%~88.56%,平均置信为81.56%,CER为40.91%,WER为47.76%。并可以去除文本中的例题、习题、解、证等内容,以免无关内容对后续实体和关系的提取产生干扰,然后使用DeepSeek的DeepSeek-Chat模型进行实体和关系的提取以及知识图谱的构建,流程如图1所示。
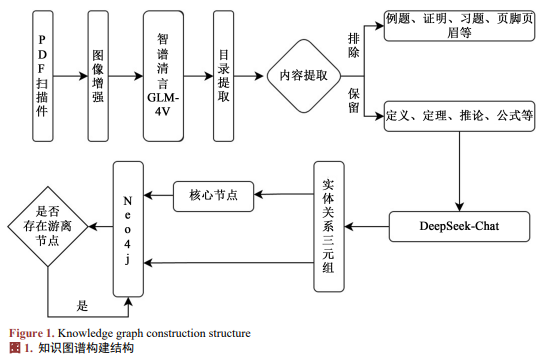
针对扫描版PDF中普遍存在的图像模糊、字体对比度低等问题,本文设计了多阶段的图像增强流程。具体算法如下:

目录和文本内容提取:在程序运行后,将手动输入正文起始页码(正文起始页在PDF中的页码)和目录起始页码,并自动计算偏移量(在PDF中的页码和实际页面标注的页码之间的差值),智谱清言大模型提取目录页范围后,自动识别并提取章节信息(章节编号、标题、起始页码),处理非章节条目(如附录、索引等),通过提取到的章节信息和偏移量计算每一章的起止页码,并根据第一个非章节条目的页码或总页数来确定最后一章的结束页码。
提取实体和关系内容:由于经过API时文本容量有限制,首先需要将每一章的提取内容进行分块,本文采取的是根据提取到的文本内容按4页分块,并且除本章的第一块外,后续分块都包含上一块的最后一页,以保持语义文本的连贯性。然后用DeepSeek根据提示词要求对每一章的文本进行实体提取和关系生成,为了避免出现某一概念在不同章节出现而创建出同一名称的实体,导致知识图谱结构混乱,本文采取只将第一次遇到某一概念创建为实体(如确界定理在“第一章 实数集与函数”和“第七章 实数的完备性”中都有提及),后续再出现这一概念时,将页码等信息重新整理到创建的节点属性中。
图3为提取实体与关系时的提示词。

知识图谱构建:针对游离节点问题,本文主要采取三级解决方案:(1) 关系创建时动态更新节点状态;(2) 基于文本嵌入的余弦相似度计算关联核心概念;(3) 建立章节点兜底机制。最终构建的知识图谱包含完整的概念层级体系和语义关系网络,为数学知识推理奠定基础。其兜底机制代码如下:


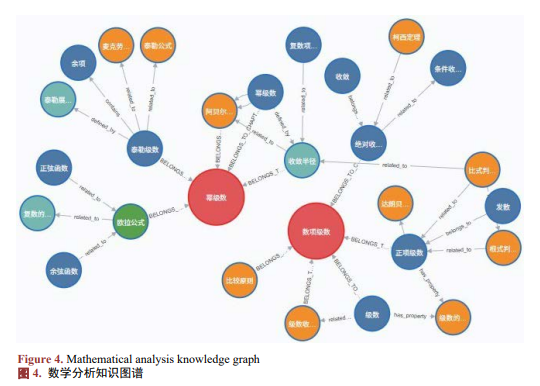
图4为生成的数学分析知识图谱的部分展示。
错误分析
(1) 在目录提取中,有时会出现将小节标题识别为章标题,或者将非章节标题识别为章标题,可能原因有“第x章”与小节标题的序号都是使用中文数字一、二、三等,导致模型识别时出现混乱,图像增强无法完全解决字体大小、排版相似的识别问题,智谱清言模型对二级标题的理解不准确,未完全排除非章节部分,特别是在目录换页后未识别出非章节标题;
(2) 在实体过程中,会出现如“定理1.1”的名称,但在经过标准化后有时出现没有重新命名的情况,成为游离节点且无法被连接,可能原因有正则化后DeepSeek未能从节点描述中总结出该节点名称;
(3) 有的节点及关系描述很短,起不到说明作用,可能原因有网络波动导致提取的文本不够完整,DeepSeek API的max_tokens = 4000可能限制了详细描述的生成,温度参数temperature = 0.2设置较低,可能导致描述过于保守和简短,缺乏重新生成或补充的机制;
(4) 有些游离节点在经过兜底处理后会与其他游离节点相连接,但不与章节点、核心节点及其子节点相连接,可能原因有游离节点之间可能因为描述中的常见词而产生虚假相似度,关键词的匹配无法理解深层的数学逻辑关系,嵌入模型可能无法准确捕捉数学概念间的语义关系。
结论
本文构建的数学知识图谱系统,通过创新性融合多模态大模型与图像增强技术,主要解决了扫描版数学教材处理的三大难题:(1) 低质量图像的字符识别,(2) 数学符号的语义解析,(3) 知识体系的结构化建模。系统采用的双阶段处理架构(GLM-4V内容提取 + DeepSeek知识抽取),其性能和效率相较于传统OCR方案和人工标注方案具有一定的优势,其层次化实体关系模型有效捕捉了数学概念的逻辑关联,为智能教育应用提供了帮助。
然而,本文模型由于采用无监督方式,因此在建立完知识图谱之后仍需要人工校验,在未来可以构建基于知识一致性的动态校验系统,通过数学公理库等方式实时检测实体矛盾,结合上下文感知技术自动修正描述偏差,提升知识图谱的逻辑严谨性。开发多模态融合算法,集成版面分析、字体特征聚类和语义理解,实现全自动目录解析,消除当前人工输入起始页的交互瓶颈。使用更智能的模型,研发数学专业领域微调模型,强化对复杂推理链的语义解析,进一步提高知识图谱建立的质量。
原文链接:

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 28
28 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)