李沐《动手学深度学习v2》64-67注意力机制总结
一、注意力机制
1. 什么是注意力机制?
注意力机制(Attention Mechanism)是深度学习中的一种重要技术,最初应用于自然语言处理领域,后来被广泛扩展到计算机视觉、语音识别等多个领域。
在课程中提到“心理学”知识去理解“注意力”,动物需要在复杂环境下有效关注值得注意的点,人类会根据随意线索和不随意线索选择注意点(这里的“随意”指的是按照主观意愿)。例如,在一堆物品中,按照“不随意线索”也就是无目标性地看过去,通常会先注意到颜色最鲜艳的物品。但按照“随意线索”也就是想看到自己需要看到的东西,例如“书”,我们就会注意到书。
那么注意力机制的核心思想是让模型能够动态地关注输入数据中与当前任务最相关的部分,从而提高模型的性能和解释性。
之前学习的卷积、全连接、池化层都只考虑“不随意线索”,注意力机制则考虑“随意线索”,随意线索被称之为查询(query),也就是当前需要处理的任务(如翻译中的目标词)。每个输入是一个值(value)和不随意线索(key)的对,通过注意力池化层来有偏向性的选择选择某些输入。而key就代表输入数据的特征表示(如源语言词的编码),Value通常与Key相同,是实际用于生成输出的信息。注意力权重通过Query和Key的相似度计算,然后加权求和Value得到输出。
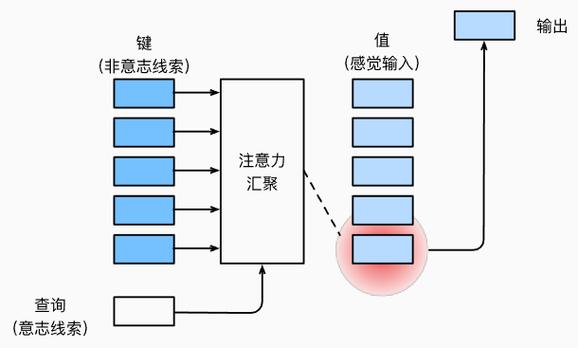
非参注意力池化层即该层不学习参数,给定数据(xi,yi), i = 1,...,n
最简单的方案是平均池化:f(x) = ΣYi/n,更好的方案是60年代提出的Nadaraya-Watson核回归,可认为K是衡量x和xi之间距离的函数,除之后变为概率,每一项拿到它相对的重要性,然后用这个东西加权与yi求和,找相近的数据。
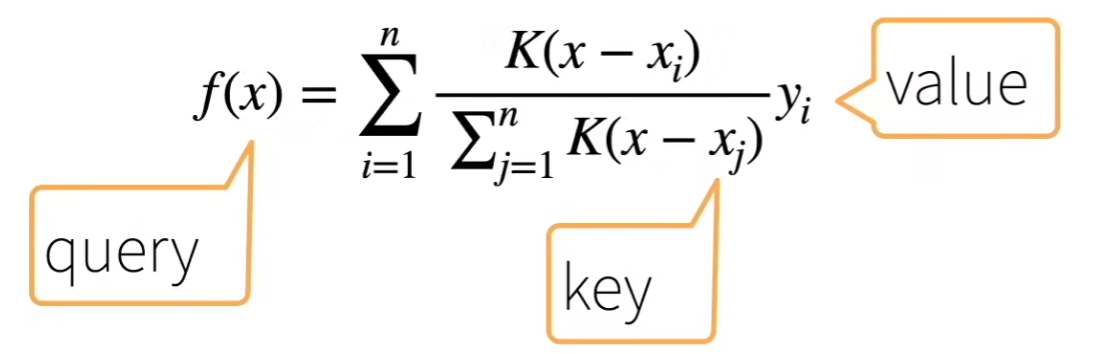
该方法选择使用高斯核![]() 带入刚才的式子中得到:
带入刚才的式子中得到:
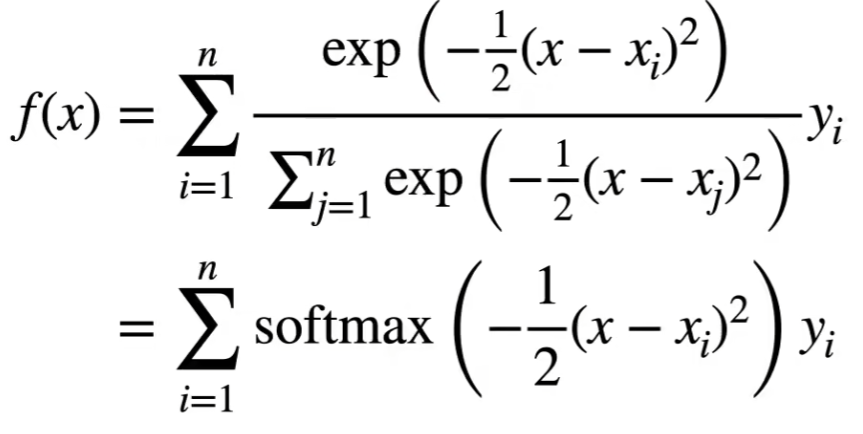
参数化的注意力机制,也就是加入可以学习参数w:
![]()
之后会介绍多个不同的权重设计。
2. 代码实现
注意力汇聚:Nadaraya-Waston核回归的实现。
定义了一个真实函数 f(x) 去拟合它,训练集是0-5之间随机生成50个数并排序,现在任务是给定x_test去预测y_truth.
import torch
from torch import nn
from d2l import torch as d2l
n_train = 50 # 训练样本数量为50
x_train, _ = torch.sort(torch.rand(n_train) * 5) # 生成50个随机数并排序
def f(x):
return 2 * torch.sin(x) + x**0.8 # 定义非线性函数,由正弦函数和幂函数组成,用于生成真实的标签
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 生成带噪声的训练标签
x_test = torch.arange(0, 5, 0.1) # 生成测试数据,测试数据从0到5,步长0.1(共50个点)
y_truth = f(x_test) # 测试集的真实标签(无噪声)
n_test = len(x_test) # 测试样本数量(50)
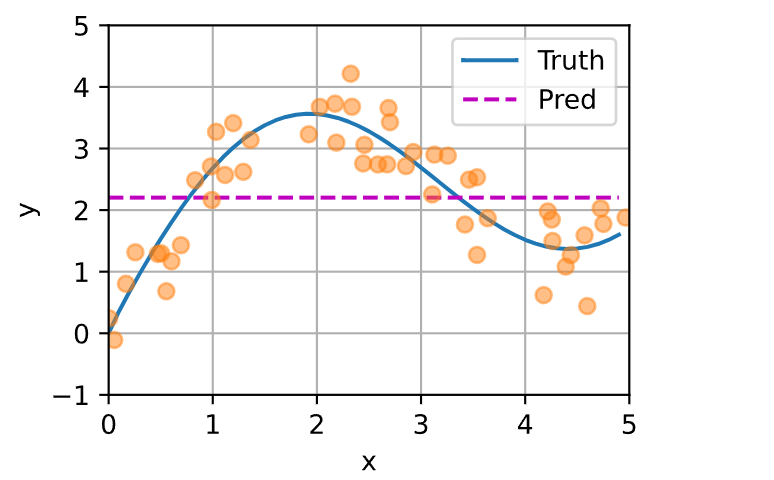
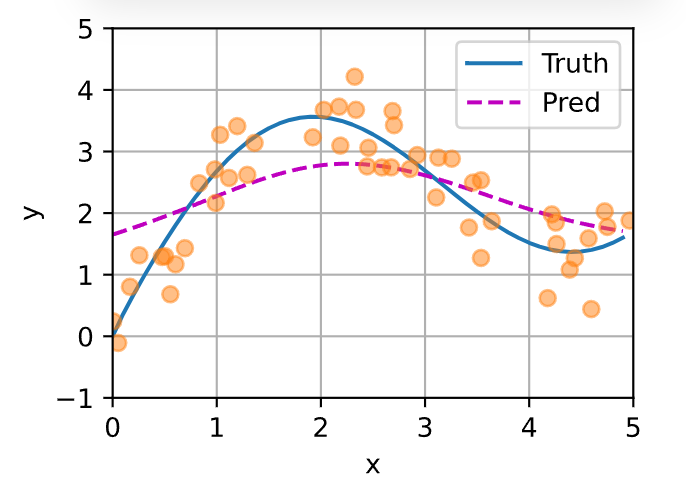
n_test如图所示,黄色的点是训练的点,xy_train均是随机的,蓝色的线是真实的y值。如果用最简单的平均,仅对y作均值,那么预测结果就是红色的线,当然这样是不靠谱的。
def plot_kernel_reg(y_hat): # 绘图函数
d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth','Pred'],
xlim=[0,5], ylim=[-1,5])
d2l.plt.plot(x_train, y_train, 'o',alpha=0.5);
y_hat = torch.repeat_interleave(y_train.mean(), n_test) # 基线预测
plot_kernel_reg(y_hat) # 可视化基线预测结果运行:
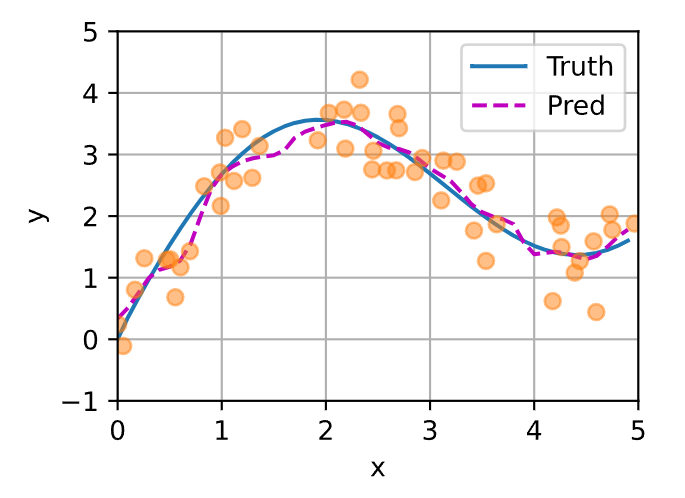
非参数注意力汇聚,首先将测试数据重复化,重复次数用n_train控制,每个点之间做减法再平方除以2丢到softmax中(对应简介中的公式),得到权重weight之后,y_train按照权重得到预测。意思就是找附近较近的点给予较大的权重,将y值汇聚在一起。能够看到预测线在考虑点时有取舍,并不是完全拟合,与之前的图像比,预测曲线更加平滑,做了一个平滑的加权回归。但真实值的曲线变化比较大,该线过于平滑,所以还是不适合预测,非参在机器学习里用的不那么多。
# 基于注意力机制的非参数回归模型(Nadaraya-Watson核回归)
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train)) # 准备测试数据的重复矩阵,将每个测试点与所有训练点计算相似度。
attention_weight = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1) # 计算注意力权重(高斯核)
y_hat = torch.matmul(attention_weight, y_train) # 加权预测
plot_kernel_reg(y_hat) # 可视化结果运行:
接下来,训练带参数注意力汇聚,在之前的基础上加了w,用于控制高斯核窗口的大小,可以控制得不那么平滑,我们希望通过学习一个w使得曲线平滑与否。
class NWKernelRegression(nn.Module): # 类定义与初始化
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values): # 前向传播
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
# 扩展 queries以匹配 keys的维度
# 计算注意力权重(高斯核)
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# 加权求和
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)
# 将训练数据集转换为键和值
X_tile = x_train.repeat((n_train, 1)) # 重复训练数据
Y_tile = y_train.repeat((n_train, 1))
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none') # 损失函数
trainer = torch.optim.SGD(net.parameters(), lr=0.5) # 优化器
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5])
for epoch in range(5): # 训练循环
trainer.zero_grad()
l = loss(net(x_train, keys, values), y_train)
l.sum().backward()
trainer.step()
print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')
animator.add(epoch + 1, float(l.sum())) # 可视化工具
# 绘制结果
keys = x_train.repeat((n_test, 1))
values = y_train.repeat((n_test, 1))
y_hat = net(x_test, keys, values).unsqueeze(1).detach()
plot_kernel_reg(y_hat)直接看最后训练结果,发现拟合得更好,曲线不那么平滑了,确实有点噪音使曲线抖动。
现在再看看权重分布图,更加集中,每一行集中在的对应位置给权重,其他几乎没有给。
d2l.show_heatmaps(
net.attention_weights.unsqueeze(0).unsqueeze(0),
xlabel='Sorted training inputs',ylabel='Sorted testing inputs') 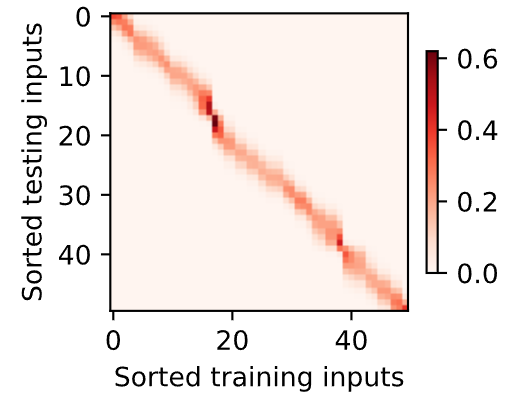
二、注意力分数
1. 什么是注意力分数?
上节课讲的使用高斯核来建立query和keys之间的关系函数,现在将query和keys放入注意力评分函数(Attention scoring function)中,然后将该函数的输出结果放入softmax函数中。这样我们可以得到注意力权重,最后注意力权重的值的加权和作为输出。原理图如下:
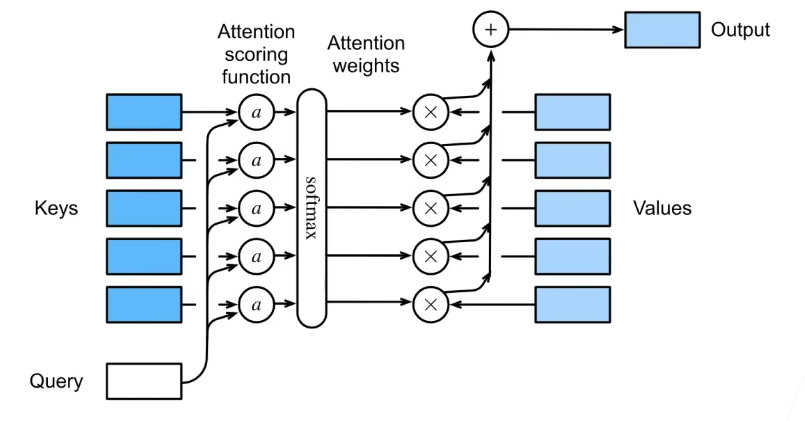
首先,将key-value扩展到高维度,也就是将注意力汇聚函数就被表示成值的加权和:
![]()
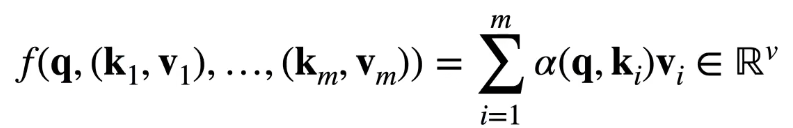
其中查询q和ki的注意力权重是通过注意力评分函数a将两个向量映射成标量,再经过softmax运算得到的,softmax的展开如下图所示:

那么如何确定这个“a”注意力评分函数?有两个思路。
1.1 可加性注意力Additive Attention
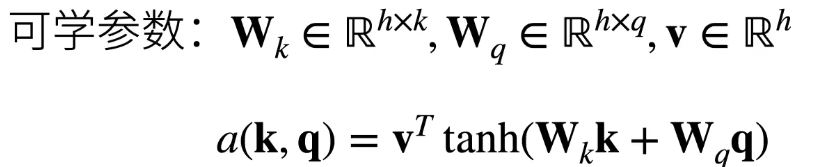
k和q分别与Wk和Wq相乘得到长为h的两个向量,加起来放在激活函数tanh中,得到一个长为h的向量,再与v转置想乘得到一个在值。
等价于将query(长为q的向量)与key(长为k的向量)合并起来得到一个长为q+k的向量后放入一个隐藏层大小为h,输出大小为1的单隐藏层MLP。
1.2 缩放点积注意力Scaled Dot-Product Attention
如果query和key都是同样的长度,那么可以![]() 。
。
向量化版本:
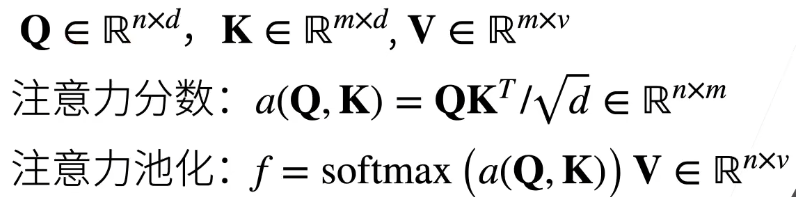
1.3 小总结
注意力分数是query和key的相似度,注意力权重是分数softmax的结果。
两种常见的计算:将query和key合并起来进入一个单输出隐藏层的MLP;
直接将query和key做内积。
2. 代码实现
仅展示核心代码不进行运行演示。
2.1 遮蔽softmax操作
由于某些情况下,并不是所有的值都应该被纳入到注意力汇聚中,遮蔽 softmax 通过数学手段(掩码)强制模型忽略无效或不应关注的数据部分,从而保证模型的正确性、效率和泛化能力。这是序列建模任务中必不可少的技术。这里 softmax 操作主要用于处理序列数据中填充部分的注意力权重计算:
import torch
import d2l.torch
import math
from torch import nn
def masked_softmax(X,valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
shape = X.shape
if valid_lens is None: # 如果valid_lens为None,直接对X执行标准的softmax
return nn.functional.softmax(X,dim=-1)
else:
if valid_lens.dim() == 1:
# 如果valid_lens是1D张量,将其扩展为与X的第二维(num_queries)相同长度,表示所有查询位置的有效长度相同
valid_lens = torch.repeat_interleave(valid_lens,shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 如果是2D张量,将其展平,表示每个查询位置可能有不同的有效长度。
X = d2l.torch.sequence_mask(X.reshape(-1,shape[-1]),valid_lens,value=-1e6)
return nn.functional.softmax(X.reshape(shape),dim=-1)
# 掩码操作:通过sequence_mask函数将无效位置(填充部分)的值替换为一个极小的数(-1e6),这样在softmax后这些位置的权重会趋近于0
2.2 实现可加性注意力
加性注意力通过将查询(Query)和键(Key)映射到同一高维空间后相加,再经过非线性激活tanh和线性变换计算注意力分数,上面介绍过其计算公式。
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self,key_size,query_size,num_hiddens,dropout):
super(AdditiveAttention,self).__init__()
self.W_q = nn.Linear(query_size,num_hiddens,bias=False) # 映射query
self.W_k = nn.Linear(key_size,num_hiddens,bias=False) # 映射key
self.W_v = nn.Linear(num_hiddens,1,bias=False) # 生成注意力分数
self.dropout = nn.Dropout(dropout) # 防止过拟合
def forward(self,queries,keys,values,valid_lens):
queries = self.W_q(queries)
keys = self.W_k(keys) # 将query和key分别线性映射到num_hiddens维空间
features = queries.unsqueeze(2)+keys.unsqueeze(1) # 广播相加
features = torch.tanh(features) # 应用非线性tanh函数
scores = self.W_v(features) # 计算注意力分数
scores = scores.squeeze(-1)
self.attention_weights = masked_softmax(scores,valid_lens)
# 使用masked_softmax遮蔽无效位置
return torch.bmm(self.dropout(self.attention_weights),values)
# torch.bmm批量矩阵乘法,将注意力权重与values相乘,得到加权后的输出,dropout防止过拟合
2.3 实现缩放点积注意力
点积注意力通过计算查询(Query)和键(Key)的点积得到注意力分数,再通过缩放和 softmax 归一化权重。
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self,dropout):
super(DotProductAttention,self).__init__()
self.dropout = nn.Dropout(dropout) # 对注意力权重应用的丢弃率,防止过拟合。
def forward(self,queries,keys,values,valid_lens):
d = queries.shape[-1] # 获取查询和键的维度d
scores = torch.bmm(queries,keys.transpose(1,2))/math.sqrt(d)
# torch.bmm批量矩阵乘法,计算query和key的点积。缩放:除以根号d防止点积结果方差过大
self.attention_weights = masked_softmax(scores,valid_lens)
# 对分数进行softmax归一化,并屏蔽无效位置
return torch.bmm(self.dropout(self.attention_weights),values)
# 将注意力权重与values相乘,得到加权输出总之,两种注意力机制的本质目标相同——动态计算权重并聚焦关键信息,但通过不同的数学形式权衡了表达能力和计算效率。在实际应用中,缩放点积注意力因其高效性成为主流,而加性注意力仍在特定场景中发挥作用。
三、使用注意力机制的seq2seq
1. 动机与原理
传统的seq2seq模型(如基于RNN的模型)通过编码器将整个输入序列压缩为一个固定长度的上下文向量(context vector),再由解码器基于该向量生成输出序列。但这种方式存在两个主要问题:信息瓶颈(长输入序列的信息难以完全编码到固定长度的向量中)和长距离依赖丢失(解码器无法灵活捕捉输入序列中不同位置的关键信息)。
而基于注意力机制的seq2seq模型是一种改进的编码器-解码器架构,主要用于解决传统seq2seq模型在处理长序列时出现的问题。其核心思想是让解码器在生成输出序列的每一步时,动态地关注输入序列中最相关的部分。
加入注意力之后的原理图如下:
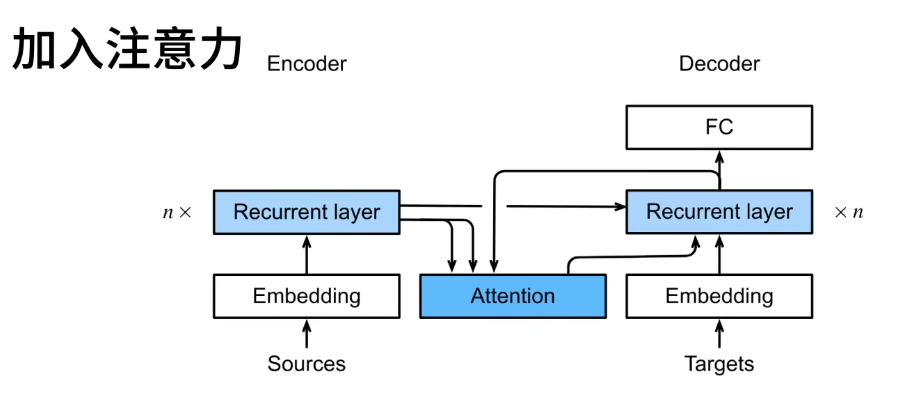
编码器对每次词的输入作为key和value,也就是编码器处理输入序列;
解码器RNN对上一个词的输出是query,也就是解码器生成输出时的注意力计算,其步骤包括计算注意力权重(Attention Weights)、归一化为概率分布(Attention Distribution)、生成上下文向量(Context Vector)和解码器生成输出,注意力的输出和下一个词的词嵌入合并进入RNN。
总之,注意力机制可以根据解码器RNN的输出来匹配到合适的编码器RNN的输出来更有效的传递信息。
2. 代码实现
首先,定义AttentionDecoder类为带有注意力机制解码器的基本接口。
import torch
import d2l.torch
from torch import nn
class AttentionDecoder(d2l.torch.Decoder):
"""带有注意力机制解码器的基本接口"""
def __init__(self):
super(AttentionDecoder,self).__init__()
@property
def attention_weights(self):
raise NotImplementedError
核心实现如下,实现带有注意力机制的循环神经网络解码器。
class Seq2SeqAttentionDecoder(AttentionDecoder):
# 初始化方法
def __init__(self,vocab_size,embed_size,num_hiddens,num_layers,dropout=0):
super(Seq2SeqAttentionDecoder,self).__init__()
self.embedding = nn.Embedding(vocab_size,embed_size)
# 词嵌入层,将输入的词索引映射为稠密向量。
self.rnn = nn.GRU(embed_size+num_hiddens,num_hiddens,num_layers,dropout=dropout)
# 循环神经网络,输入维度为embed_size+num_hiddens(拼接了嵌入向量和注意力上下文),输出维度为 num_hiddens,层数为 num_layers。
self.dense = nn.Linear(num_hiddens,vocab_size)
# 全连接层,将输出映射到词汇表大小,用于生成预测词的概率分布。
self.additiveAttention = d2l.torch.AdditiveAttention(key_size=num_hiddens,query_size=num_hiddens,num_hiddens=num_hiddens,dropout=dropout)
# 加性注意力机制,用于计算编码器输出和解码器隐藏状态之间的注意力权重。
# 初始化解码器的初始状态
def init_state(self, enc_outputs, enc_valid_lens,*args): # 输入为编码器的输出、编码器各时间步的有效长度(用于掩码无效部分)。
outputs,hidden_states = enc_outputs
return (outputs.permute(1,0,2),hidden_states,enc_valid_lens)
# 输出为返回一个元组(outputs, hidden_states, enc_valid_lens),其中outputs调整维度为 (seq_len, batch_size, num_hiddens)
# 前向传播方法
def forward(self,X,states):
enc_outputs,hidden_states,enc_valid_lens = states
X = self.embedding(X).permute(1,0,2)
# 将输入X转换为嵌入向量,并调整维度为 (seq_len, batch_size, embed_size)
outputs = []
self._attention_weights = []
for x in X: # 循环处理每个时间步,注意力计算,拼接输入与上下文
query = torch.unsqueeze(hidden_states[-1],dim=1)
context = self.additiveAttention(queries=query,keys=enc_outputs,values=enc_outputs,valid_lens=enc_valid_lens)
x_context = torch.cat((context,torch.unsqueeze(x,dim=1)),dim=-1)
# 通过循环神经网络计算输出和更新状态
output,hidden_states = self.rnn(x_context.permute(1,0,2),hidden_states)
outputs.append(output) # 记录输出和注意力权重
self._attention_weights.append(self.additiveAttention.attention_weights)
# 生成预测
outputs = self.dense(torch.cat(outputs,dim=0))
return outputs.permute(1,0,2),[enc_outputs,hidden_states,enc_valid_lens]
# 注意力权重属性,返回注意力权重的历史记录(用于可视化)
@property
def attention_weights(self):
return self._attention_weights
测试注意力编码器,使用包含7个时间步的4个序列输入的小批量进行测试。
encoder = d2l.torch.Seq2SeqEncoder(vocab_size=10,embed_size=8,num_hiddens=16,num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10,embed_size=8,num_hiddens=16,num_layers=2)
decoder.eval()
X = torch.zeros(size=(4,7),dtype=torch.long)
states = decoder.init_state(encoder(X),None)
outputs,states = decoder(X,states)
outputs.shape,len(states),states[0].shape,len(states[1]),states[1].shape,states[1][0].shape
'''
输出结果:(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([4, 16]))
'''
指定超参数,开始训练。
embed_size,num_hiddens,num_layers,dropout = 32,32,2,0.1
batch_size,num_steps = 64,10
lr=0.005
device = d2l.torch.try_gpu()
num_epochs = 250
train_iter,src_vocab,tgt_vocab = d2l.torch.load_data_nmt(batch_size,num_steps)
encoder = d2l.torch.Seq2SeqEncoder(len(src_vocab),embed_size,num_hiddens,num_layers,dropout)
decoder = Seq2SeqAttentionDecoder(len(tgt_vocab),embed_size,num_hiddens,num_layers,dropout)
net = d2l.torch.EncoderDecoder(encoder,decoder)
d2l.torch.train_seq2seq(net,train_iter,lr,num_epochs,tgt_vocab,device)
训练结果如下:
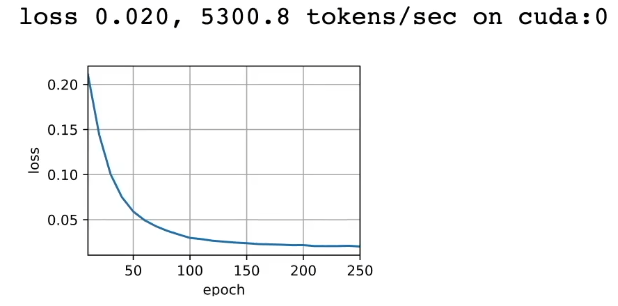
模型训练之后,尝试使用它将几个英语句子翻译成法语并计算BLUE分数(一种广泛用于评估机器翻译质量的自动评价指标,通常为0~1的范围,分数越高表示生成质量越好。)
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng,fra in zip(engs,fras):
translations,dec_attention_weights = d2l.torch.predict_seq2seq(net,eng,src_vocab,tgt_vocab,num_steps,device,save_attention_weights=True)
print('eng:',eng,'==>','translations:',translations,'==> bleu:',d2l.torch.bleu(translations,fra,k=2))
'''
输出结果如下:
eng: go . ==> translations: va ! ==> bleu: 1.0
eng: i lost . ==> translations: j'ai perdu . ==> bleu: 1.0
eng: he's calm . ==> translations: il est bon . ==> bleu: 0.6580370064762462
eng: i'm home . ==> translations: je suis chez moi . ==> bleu: 1.0
'''四、自注意力
1. 什么是自注意力?
自注意力(Self-Attention) 是注意力机制(Attention Mechanism)的一种特殊形式,主要用于捕捉序列内部元素之间的依赖关系。它是 Transformer 模型的核心组件,也被广泛应用于自然语言处理(NLP)、计算机视觉(CV)等领域。
自注意力通过计算序列中每个元素与其他所有元素的关联权重(即“注意力分数”),动态地为每个元素生成一个加权上下文表示。与传统的注意力机制(如 Seq2Seq 中的编码器-解码器注意力)不同,自注意力是序列内部的注意力,不依赖外部信息。也就是说,自注意力之所以叫做自注意力,是因为 key,value,query 都是来自于自身,xi 既作为 key ,又作为 value ,同时还作为 query。

2. 与CNN、RNN对比
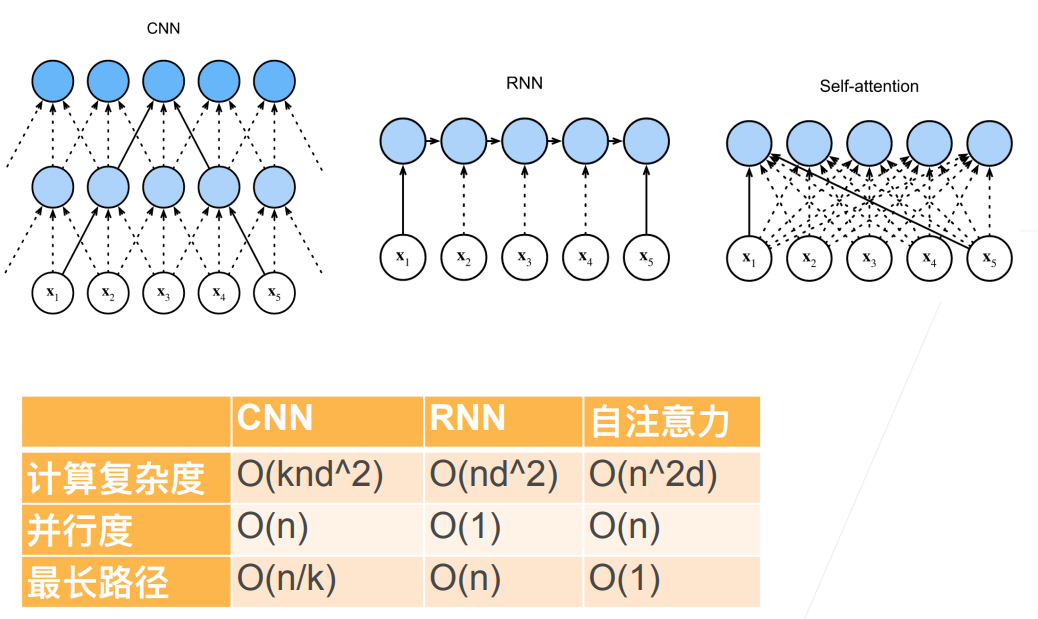
CNN做序列的话,就当作一维输入,经过一个一维的卷积(只有宽没用高)实现处理文本序列,它的计算复杂度中的k就是窗口的大小,n为序列长度,d为dimension是每个x的维度(长度)。
并行度:GPU有大量的并行单元,每个输出yi都可以自己并行(同时)做运算,并行度越大,计算速度越快。最长路径:指从输入层到输出层经过最多层的路径。假设有一个长序列的信息要传递到很后的地方,那这个信息怎么传过去,对于CNN来由于kernel一次性看到一些信息,所以一层一层传上去,最长路径就是n/k。(对应于计算机视觉中感受野的概念,每一个神经元的输出对应图片中的视野)
可以看到,CNN和自注意力都具有并行计算的优势,自注意力的最长路径长度最短。
自注意力适合处理比较长的文本,是因为它的设计使看到的信息比较宽(无视距离)。
3. 位置编码
由于自注意力机制本身没有位置信息的概念,需要额外添加位置编码来让模型感知输入序列中单词的位置关系。这种特定的正弦/余弦编码方式可以让模型更容易学习到相对位置信息,并且能够处理比训练时更长的序列。
比如,自注意力分不清“我爱你”和“你爱我”这样的句子,如果不加入位置编码,自注意力只看内容不看顺序,会以为它两是一样的。加入位置编码后,“我”在位置 0,"爱" 在位置 1,"你" 在位置 2,就能知道顺序啦。
传统的CNN/RNN/LSTM,这些模型是按顺序处理输入的,因此天然地包含了位置信息,自注意力并没有记录位置信息。CNN从输出可以反推出输入所在窗口的信息,因此窗口大小可以看成位置信息,而RNN/LSTM本身就是序列相关的。
为了使自注意力拥有序列的顺序信息,添加位置编码将位置信息注入到输入里。
假设长度为n的序列是X∈Rn*d,那么使用位置编码矩阵P∈Rn*d来输出X+P作为自编码输入,使用正弦(sin)和余弦(cos)函数的组合来生成位置编码,公式如下:
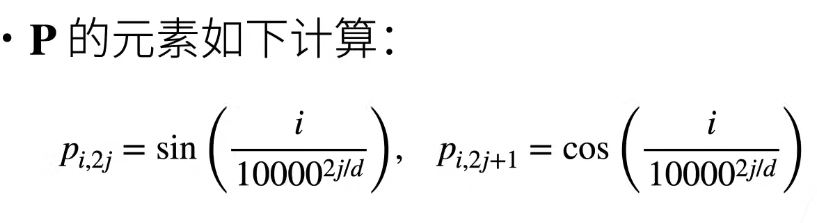
4. 代码实现
实现位置编码,初始化参数之后相当于把公式输入进去。
import torch
import d2l.torch
from torch import nn
class PositionalEncoding(nn.Module):
"""位置编码"""
# 初始化,构造函数接收三个参数:num_hiddens编码的维度、dropout用于正则化、max_len预设的最大序列长度,默认为1000
def __init__(self,num_hiddens,dropout,max_len=1000):
super(PositionalEncoding,self).__init__()
self.dropout = nn.Dropout(dropout) # 初始化了一个dropout层
self.P = torch.zeros(size=(1,max_len,num_hiddens)) # 创建了一个全零张量P,用于存储位置编码
# 计算位置编码
X = torch.arange(max_len,dtype=torch.float32).reshape(-1,1)/torch.pow(1000,torch.arange(0,num_hiddens,2,dtype=torch.float32)/num_hiddens)
# 交替使用正弦和余弦函数
self.P[:,:,0::2] = torch.sin(X)
self.P[:,:,1::2] = torch.cos(X)
# 前向传播
def forward(self,X):
X = X+self.P[:,:X.shape[1],:].to(X.device)
return self.dropout(X)接下来可视化位置编码,直观展示位置编码在不同位置、不同维度上的变化规律,帮助理解 sin/cos 编码的特性。
encoding_dim,num_steps = 32,60 # 位置编码的维度、要生成的位置编码的最大长度(即序列长度)
pos_encoding = PositionalEncoding(encoding_dim,0) # 初始化位置编码层
pos_encoding.eval() # 设置为评估模式
X = pos_encoding(torch.zeros(size=(1,num_steps,encoding_dim))) # 生成位置编码
P = pos_encoding.P[:,:X.shape[1],:] # 提取位置编码
# 可视化部分维度
d2l.torch.plot(torch.arange(num_steps),Y=P[0,:,6:10].T,xlabel='Row (position)',figsize=(6,2.5),legend=['Column %d' %d for d in torch.arange(6,10)])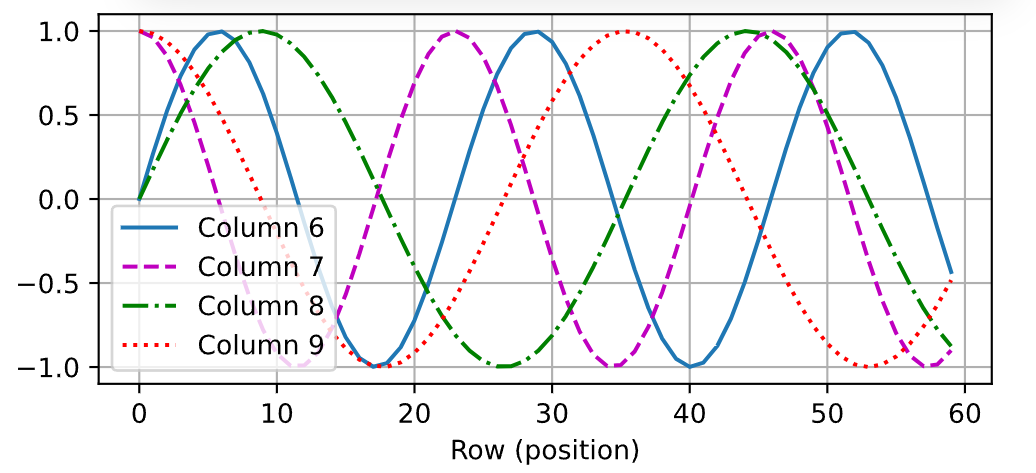
运行后,你会看到4条曲线,分别代表:维度 6(sin或cos函数,取决于它是偶数还是奇数维度)。维度 7(与维度 6 交替的cos或sin)。维度8(下一个sin)。维度 9(下一个cos)。这些曲线展示了:不同位置(0~59)的位置编码值。不同维度(6~9)的变化模式:低维度(如 6、7)变化较快(高频)。高维度(如 8、9)变化较慢(低频)。
使用热力图显示每一个样本序列的位置编码,在编码维度上降低频率。X 轴表示特征,Y 轴表示样本,可以认为是对每一行的位置信息进行了编码,将第i个样本用一个长为d的向量进行编码。
P = P[0,:,:].unsqueeze(0).unsqueeze(0)
d2l.torch.show_heatmaps(P,xlabel='Column(encoding dimension)',ylabel='Row (position)',figsize=(3.5,4),cmap='Blues')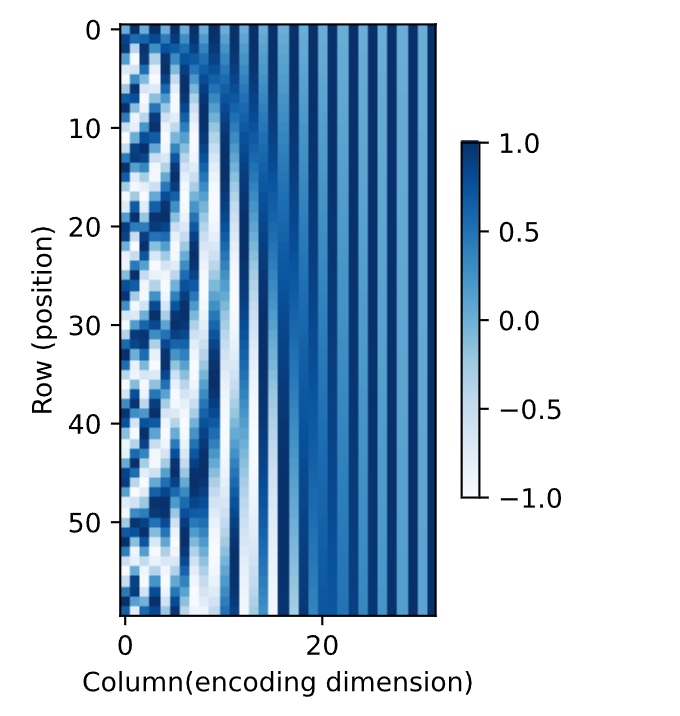
5. 相对位置信息
在自然语言处理(NLP)中,相对位置信息指的是一个词(token)相对于另一个词的位置关系,而不是它们的绝对位置(如“第5个词”)。这种信息让模型能够更好地理解词与词之间的局部依赖关系。
前面介绍的位置编码的位置是绝对位置,每个词在序列中的固定位置(如“我爱你”中“我”是第0个词,“爱”是第1个词)。而相对位置就是词与词之间的相对距离(如“爱”在“我”的右边1个位置,“你”在“爱”的右边1个位置)。这样更符合语言规律(比如动词和宾语的关系通常与绝对位置无关),能更好地处理长文本(因为相对距离通常有界,比如窗口大小为10)。
![]()

五、总结
本文将课程的64-68注意力机制、注意力分数、使用注意力机制的seq2seq、自注意力这几节课做了总结笔记,供本人复习和理解,谢谢阅读。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)