机器学习-模型效果评价
1. 混淆矩阵 (Confusion Matrix)
概念:评估分类模型性能的表格,展示预测结果与真实标签的对应关系
作用:
-
量化模型的分类准确性
-
识别错误类型(假阳性/假阴性)
-
计算多种评估指标的基础
关键参数:
-
TP (True Positive):正确预测的正例
-
FP (False Positive):错误预测的正例
-
FN (False Negative):错误预测的负例
-
TN (True Negative):正确预测的负例
-
公式:
confusionMatrix(predicted, actual, positive = "阳性类别")
衍生指标:
-
准确率 (Accuracy) = (TP+TN)/(TP+FP+FN+TN)
-
精确率 (Precision) = TP/(TP+FP)
-
召回率 (Recall/Sensitivity) = TP/(TP+FN)
-
F1值 = 2×(Precision×Recall)/(Precision+Recall)
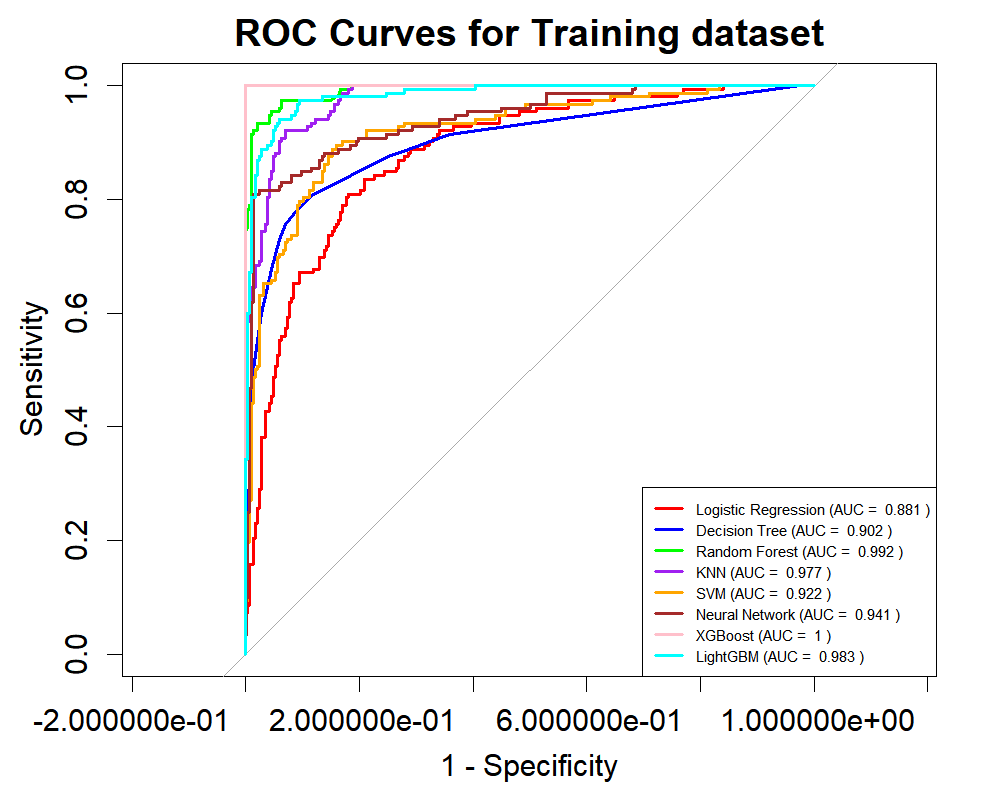
2. ROC曲线与AUC值
概念:
-
ROC曲线:展示不同阈值下真阳性率(TPR)与假阳性率(FPR)的关系
-
AUC值:曲线下面积,衡量模型区分能力
作用:
-
评估模型整体区分能力
-
不受分类阈值影响
-
比较不同模型性能
关键函数:
roc(response, predictor) # 创建ROC对象
auc(roc_object) # 计算AUC值
ci.auc(roc_object) # 计算AUC置信区间解读:
-
AUC=0.5:无区分能力
-
0.7≤AUC<0.8:一般区分能力
-
0.8≤AUC<0.9:良好区分能力
-
AUC≥0.9:优秀区分能力
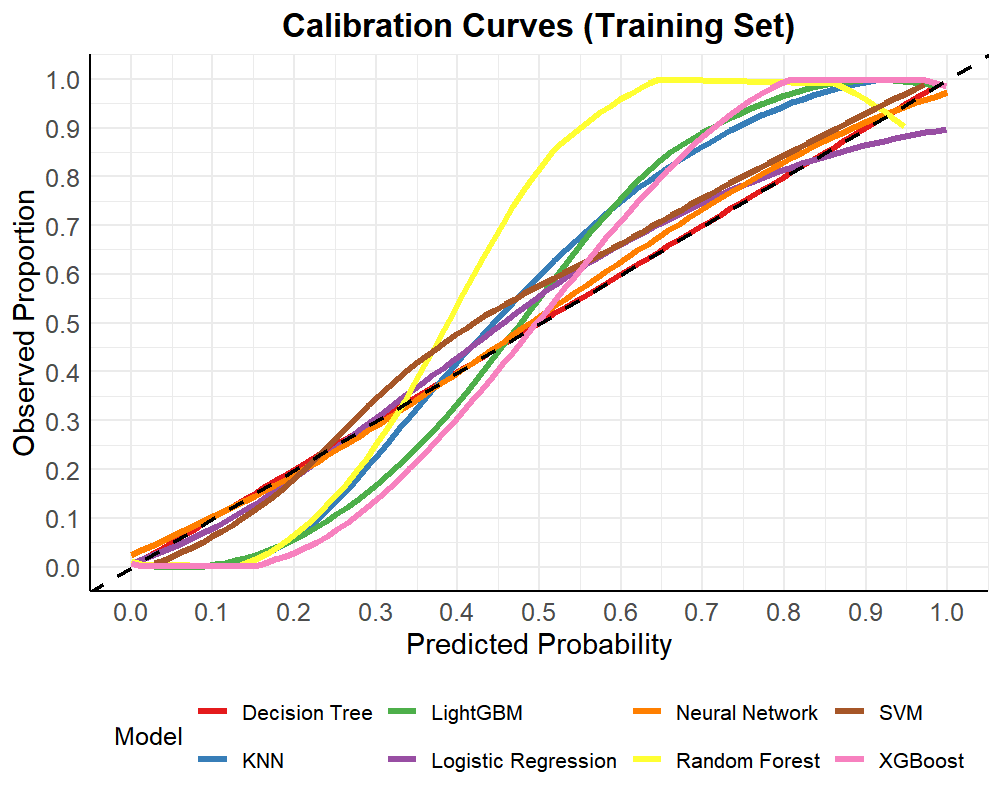
3. 校准曲线 (Calibration Curve)
概念:评估预测概率与实际概率一致性的图表
作用:
-
检验概率预测的可靠性
-
识别过度自信/保守的预测
-
诊断模型校准质量
实现方法:
ggplot(data, aes(x=预测概率, y=实际概率)) +
geom_smooth() + # 拟合曲线
geom_abline() # 理想参考线解读:
-
曲线接近对角线:校准良好
-
曲线上方:预测概率低估实际风险
-
曲线下方:预测概率高估实际风险
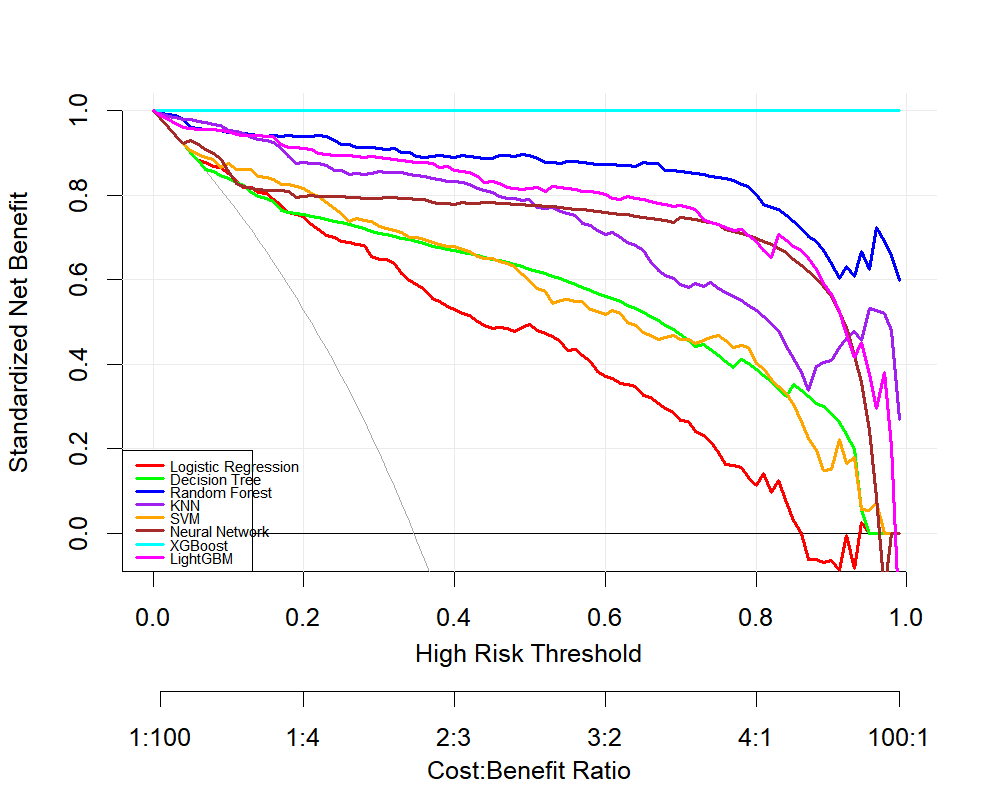
4. 决策曲线分析 (Decision Curve Analysis, DCA)
概念:评估临床决策价值的分析方法
作用:
-
量化模型临床实用性
-
比较不同干预策略的净获益
-
确定最佳决策阈值范围
关键函数:
decision_curve(formula, data) # 计算决策曲线
plot_decision_curve() # 可视化结果核心指标:
-
阈值概率 (Threshold Probability):采取干预措施的临界概率
-
净获益 (Net Benefit) = (TP - FP×权重)/N
-
权重 = 阈值概率/(1-阈值概率)
解读:
-
曲线越高表示临床价值越大
-
"All"线:干预所有患者的策略
-
"None"线:不干预任何患者的策略
综合评价框架
-
区分能力:ROC/AUC评估模型区分不同类别能力
-
校准度:校准曲线评估概率预测准确性
-
临床效用:DCA评估实际临床应用价值
-
分类精度:混淆矩阵提供详细分类性能
5.R语言实践
####################1.加载包####################################
# 加载所有必需的R包
library(caret) # 机器学习工具包
library(rpart) # 决策树
library(partykit) # 决策树可视化
library(randomForest) # 随机森林
library(xgboost) # XGBoost
library(lightgbm) # LightGBM
library(e1071) # SVM
library(nnet) # 神经网络
library(neuralnet) # 神经网络(另一种实现)
library(kknn) # KNN
library(pROC) # ROC曲线分析
library(ggplot2) # 数据可视化
library(ggthemes) # 额外的ggplot2主题
library(rms) # 列线图
library(rmda) # 决策曲线分析
library(dplyr) # 数据处理
library(tidyr) # 数据整理
library(Matrix) # 稀疏矩阵处理
library(regplot)
####################2.加载数据####################################
# 读取数据
tlog <- read.csv("tlog.csv", row.names = 1)
# 定义筛选特征集合
selected_vars <- c("exercise", "hyperlip", "pregnant",
"age", "glucose", "bmi", "pedigree")
selected_vars_scaled <- c("exercise", "hyperlip", "pregnant", "age_scaled",
"glucose_scaled", "bmi_scaled", "pedigree_scaled")
# 将结局变量因子化
tlog$diabetes <- factor(tlog$diabetes, levels = c(0, 1), labels = c("No", "Yes"))
valdata <- read.csv("valdata.csv",row.names = 1)
valdata$diabetes <- factor(valdata$diabetes, levels = c(0, 1), labels = c("No", "Yes"))
####################3.二分类机器学习模型建模####################################
# 基于训练集构建模型
###### 3.1 Logistic模型 #########
# 拟合模型
lr_model<- glm(diabetes ~ exercise+hyperlip+pregnant+age+glucose+bmi+pedigree,
data = tlog,
family ="binomial" #使用二项分布,适用于二分类因变量
)
# 显示模型信息
print(lr_model)
## 绘制列线图
regplot(lr_model,
title = "Nomogram",
points = TRUE, # 显示每个变量的点数贡献
axis.text.size = 12, # 调整刻度字体大小
title.text.size = 14) # 调整标题字体大小
################3.2 决策树:分类回归树########################################
# 构建基础CART模型:利用默认参数建模
tree_model1 <- rpart(diabetes ~ exercise+hyperlip+pregnant+age+glucose+bmi+pedigree,
data = tlog,
method = "class") # 分类问题,使用分类树算法来构建决策树
tree_model1$cptable # 返回模型剪枝的复杂度表
# 设置控制参数
control <- trainControl(method="cv", number=10)
# 定义参数网格
param_grid <- expand.grid(cp = seq(0.001, 0.3, by = 0.002)) #cp:CART模型的复杂度参数,控制模型的剪枝过程
# 使用train函数进行交叉验证和模型调优
set.seed(111)
fit_cv_rpart <- train(diabetes ~ exercise+hyperlip+pregnant+age+glucose+bmi+pedigree,
data = tlog,
method = "rpart", # 使用 rpart算法来训练模型
trControl = control,
tuneGrid = param_grid)
fit_cv_rpart $bestTune # 查看最优参数
# 使用最佳参数构建决策树模型
tree_model <- rpart(diabetes ~ exercise+hyperlip+pregnant+age+glucose+bmi+pedigree,
data = tlog,
method = "class",
cp=fit_cv_rpart$bestTune)
# 查看控制参数
print(tree_model$control)
# 画决策树图
plot(as.party(tree_model))
# 显示模型信息
print(tree_model)
###################3.3 随机森林(RF)模型##########################
# 构建默认参数,构建基础随机森林模型
rf_model0 <- randomForest(diabetes ~ exercise+hyperlip+pregnant+age+glucose+bmi+pedigree,
data = tlog,
importance=TRUE) # 利用默认参数建模
print(rf_model0)
## 最佳模型参数:超参数调节、网格搜索、交叉验证
# 定义训练控制参数
set.seed(123)
ctrl <- trainControl(method = "cv",
number = 10, # 10折交叉验证
search = "grid") # 网格搜索
# 定义超参数mtry搜索范围(mtry表示每棵树随机选择的特征数)
tuneGrid <- expand.grid(mtry = c(1:sqrt(7))) # 从1到数据集中特征数的平方根的整数值
# 超参数调优
rf_model1 <- train(diabetes ~ exercise+hyperlip+pregnant+age+glucose+bmi+pedigree,
data = tlog,
method = "rf", # 指定使用 rf
trControl = ctrl, # 指定训练控制参数 ctrl
tuneGrid = tuneGrid # 指定要调优的超参数网格
)
# 输出最佳模型参数
print(rf_model1)
rf_model1 $ bestTune
# 设置树的数量ntree范围
ntree_values <- seq(50, 1000, by = 50)
# 创建一个向量,存储每个 ntree 值对应的 OOB 错误率
oob_error_rates <- numeric(length(ntree_values))
# 训练多个模型并记录OOB误差率
for (i in 1:length(ntree_values)) { # for循环:使用不同的ntree训练多个模型
rf_model2 <- randomForest(diabetes ~ exercise+hyperlip+pregnant+age+glucose+bmi+pedigree,
data = tlog,
mtry = rf_model1$bestTune$mtry,
ntree = ntree_values[i],
importance = TRUE,
oob.prox = TRUE)
# 找出OOB误差率最低的树的数量
oob_error_rates[i] <- rf_model2$err.rate[ntree_values[i]]
}
# 找出OOB误差率最低的树的数量
best_ntree <- ntree_values[which.min(oob_error_rates)]
print(paste("最佳树的数量:", best_ntree))
# 使用最佳参数重构建模型
rf_model <- randomForest(diabetes ~ exercise+hyperlip+pregnant+age+glucose+bmi+pedigree,
data = tlog,
ntree = best_ntree,
mtry = rf_model1$bestTune$mtry,
importance = TRUE)
# 显示模型信息
print(rf_model)
########3.4 Xgboost模型################################
## 因变量需为数值型变量
tlog$diabetes <- as.numeric(tlog$diabetes) - 1
valdata$diabetes <- as.numeric(valdata$diabetes) - 1
# 设置XGBoost的训练和验证数据集
train_matrix <- xgb.DMatrix(data = as.matrix(tlog[, selected_vars]),
label = tlog$diabetes) # label指定模型结局变量
val_matrix <- xgb.DMatrix(data = as.matrix(valdata[, selected_vars]),
label = valdata$diabetes)
# 基于默认参数,构建基础 Xgboost模型
xgb_model0 <- xgb.train(data = train_matrix, nrounds=100) # 100次迭代
# 超参数调优
param_grid <- expand.grid(
objective = "binary:logistic", # 二分类任务,预测类别概率
max_depth = c(2, 3, 4, 5), # 树的最大深度,控制模型的复杂度
eta = c(0.01, 0.1, 0.2), # 学习率,决定每一轮迭代中模型更新的步伐大小
nrounds = c(50, 100, 150) # 训练轮数,每轮会调整树的参数
)
# 初始化最佳 AUC 和参数
best_auc <- 0
best_params <- list() # 存储最优超参数组合
# 超参数调优的循环
for (i in 1:nrow(param_grid)) {
param <- list(
objective = "binary:logistic",
eval_metric = "auc",
max_depth = param_grid$max_depth[i],
eta = param_grid$eta[i]
)
xgb_model_0 <- xgb.train(params = param, data = train_matrix,
nrounds = param_grid $ nrounds[i])
# 评估每个模型的 AUC
pred_probs <- predict(xgb_model_0, train_matrix)
roc_curve <- roc(tlog$diabetes, pred_probs)
auc_value <- roc_curve$auc
# 选择最优模型
if (auc_value > best_auc) {
best_auc <- auc_value
best_params <- c(param, nrounds = param_grid$nrounds[i])
}
}
# 输出最佳参数和AUC
print(best_params) # 输出最优的超参数组合
cat("最佳AUC: ", best_auc, "\n")
# 使用最佳超参数训练模型
xgb_model <- xgb.train(params = best_params, data = train_matrix,
nrounds = best_params$nrounds)
#显示模型信息
print(xgb_model)
#######################3.5 LightGBM模型#############################
# 设置LightGBM 的训练和验证数据集
lgbtlog <- lgb.Dataset(as.matrix(tlog[,selected_vars]),
label = tlog$diabetes) # 创建LightGBM所需的训练数据格式
lgbvaldata <- lgb.Dataset.create.valid(lgbtlog,
as.matrix(valdata[,selected_vars]),
label = tlog$diabetes) # 创建验证集,用于模型的验证过程
# 基于默认参数,构建基础 LightGBM 模型
lightgbm_model0 <- lgb.train(data = lgbtlog)
# 设置超参数搜索网格
param_grid <- expand.grid(
num_leaves = c(15, 31), # 树的叶子数
max_depth = c(-1, 1, 3), # 树的最大深度
learning_rate = c( 0.1, 0.2), # 学习率,控制每一轮迭代时模型更新的步伐
n_estimators = c(50), # 训练轮数(树的数量)
min_data_in_leaf = c(30), # 每棵树叶子节点最少样本数
lambda_l1 = c(0, 1), # L1 正则化参数
lambda_l2 = c(0, 1) # L2 正则化参数
)
# 准备一个空的数据框来保存结果
results <- data.frame()
# 超参数调优与交叉验证
for (i in 1:nrow(param_grid)) {
# 获取当前的参数组合
params <- list(
objective = "binary",
metric = "auc",
learning_rate = param_grid$learning_rate[i],
num_leaves = param_grid$num_leaves[i],
max_depth = param_grid$max_depth[i],
n_estimators = param_grid$n_estimators[i],
min_data_in_leaf = param_grid$min_data_in_leaf[i]
)
# 进行交叉验证
cv_results <- lgb.cv(
params = params,
data = lgbtlog,
nrounds = 10,
nfold = 5,
early_stopping_rounds = 10,
verbose = -1 # -1 表示不输出训练过程的详细信息
)
# 保存当前的参数和其对应的auc
results <- rbind(results,data.frame(param_grid[i, ],
auc=max(cv_results$record_evals$valid[['auc']]$data)))
}
# 找到最优参数
best_params <- results[which.max(results$auc), ]
print(best_params)
# 用最佳参数构建模型
best_params_list <- list( #超参数配置列表
objective = "binary",
metric = "auc",
learning_rate = best_params$learning_rate,
num_leaves = best_params$num_leaves,
max_depth = best_params$max_depth,
n_estimators = best_params$n_estimators,
min_data_in_leaf = best_params$min_data_in_leaf
)
lightgbm_model <- lgb.train(
params = best_params_list,
data = lgbtlog,
nrounds = best_params$n_estimators
)
#显示模型信息
print(lightgbm_model)
########################3.6 knn 模型###########################
# 将结局变量因子化
tlog$diabetes <- factor(tlog$diabetes,levels = c(0,1),labels = c('No','Yes'))
# 基于默认参数,构建基础 knn 模型
knn_model0 <- train(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
method = "kknn" # 指定使用加权K近邻算法
)
# 设置交叉验证控制
train_control <- trainControl(method = "cv", number = 5)
# 设置超参数网格,核函数和 k 值
tune_grid<-expand.grid(kmax = seq(1, 20, by = 2), # 调整 k 值
distance = 2, # Minkowski距离,2表示欧几里得距离
kernel=c("rectangular","triangular","gaussian")) # 核函数,计算邻居的权重
# 训练 KNN 模型并调优
set.seed(123)
kknn_model <- train(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
method = "kknn",
trControl = train_control,
tuneGrid = tune_grid)
# 查看调参结果
print(kknn_model)
# 提取最佳参数组合
best_params <- kknn_model$bestTune
print(best_params)
# 绘制可视化调参结果
ggplot(kknn_model) +
theme_minimal() +
ggtitle("KNN 超参数调整结果")
# 使用最佳参数构建最终模型
knn_model <- train(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
method = "kknn",
trControl = train_control,
tuneGrid = expand.grid(kmax = best_params$kmax,
distance = best_params$distance,
kernel = best_params$kernel))
# 查看最终模型
print(knn_model)
#########################3.7 支持向量机(SVM)#######################################################
##基于标准化后的数据建模
# 参数调整
set.seed(11)
tune_result <- tune.svm(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
kernel = "radial", # 径向核函数RBF
cost = 10^(-1:3), # cost:惩罚参数,用于控制分类错误的惩罚程度
gamma = 10^(-3:1), # gamma:核函数的参数,定义单个训练样本影响的范围
tunecontrol=tune.control(sampling = "cross",cross = 5), #交叉验证
probability = TRUE)
# 查看最佳参数
best_model <- tune_result$best.model
print(tune_result)
# 使用最佳参数拟合SVM模型
svm_model <- svm(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
kernel = "radial",
cost = best_model$cost,
gamma = best_model$gamma,
probability = TRUE) # 启用概率
print(svm_model)
#########################3.8 神经网络(nnet)#######################################################
# 构建神经网络模型的函数
build_nn_model <- function(hidden_layers) {
formula <- as.formula("diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled")
model <- neuralnet(formula, data = tlog, hidden = hidden_layers,
linear.output = FALSE) # 模型输出为分类概率(非线性激活)
return(model)
}
# 初始化变量
best_model_nnet <- NULL
best_auc <- 0
best_hidden_layers <- NULL # 保存最佳隐藏层组合
# 设置隐藏层组合
hidden_layer_combinations <- list(c(2),c(3),c(4), c(2, 1))
# 网格搜索
for (hidden in hidden_layer_combinations) { # 遍历每种隐藏层结构
set.seed(123) # 设置随机种子
nn_model <- build_nn_model(hidden)
# 进行预测
predictions_prob <- predict(nn_model, tlog)[,2] # 获取概率
predictions <- ifelse(predictions_prob > 0.5, "Yes", "No") # 将概率转为分类
# 计算AUC
roc_obj <- roc(tlog$diabetes, predictions_prob)
auc_value <- roc_obj$auc
# 更新最佳模型
if (auc_value > best_auc) {
best_auc <- auc_value
best_model_nnet <- nn_model
best_hidden_layers <- hidden # 保存最佳隐藏层组合
}
}
# 输出最佳模型和AUC值
cat("Best AUC:", best_auc, "\n")
cat("Best Hidden Layer Configuration:", paste(unlist(best_hidden_layers), collapse = ", "), "\n")
nnet_model <- best_model_nnet
#显示模型信息
summary(nnet_model )
#############4.训练集模型效果评价##############################################
######4.1 模型预测结果####
# Logistic模型
train_prob_lr <- predict(lr_model, newdata = tlog,
type = 'response') # 指定预测输出为概率,预测Yes的概率
train_prob_lr
train_pred_lr <- factor(ifelse(train_prob_lr > 0.5,'Yes','No')) # 预测分类
train_pred_lr
# 决策树模型
train_pred_tree <- predict(tree_model,
newdata = tlog,
type = "class") # 预测分类
train_pred_tree
train_prob_tree <- predict(tree_model, newdata = tlog,
type = "prob")[, 2] # 预测Yes的概率
train_prob_tree
# 随机森林
train_pred_rf <- predict(rf_model, newdata = tlog) # 预测分类
train_pred_rf
train_prob_rf <- predict(rf_model, newdata = tlog,
type = "prob")[, 2] # 预测Yes的概率
train_prob_rf
# Xgboost模型
train_prob_xgb <- predict(xgb_model, train_matrix) # 预测Yes的概率
train_prob_xgb
train_pred_xgb <- factor(ifelse(train_prob_xgb > 0.5,'Yes','No')) # 预测分类
train_pred_xgb
# LightGBM模型
train_prob_lightgbm <- predict(lightgbm_model,
newdata = as.matrix(tlog[, selected_vars]),
type = 'prob') # 预测Yes的概率
train_prob_lightgbm
train_pred_lightgbm <- predict(lightgbm_model,
newdata = as.matrix(tlog[, selected_vars]),
type = 'class') # 预测分类
train_pred_lightgbm <- factor(train_pred_lightgbm,levels = c(0,1),labels = c('No','Yes'))
train_pred_lightgbm
# knn 模型
train_pred_knn <- predict(knn_model, newdata = tlog) # 预测分类
train_pred_knn
train_prob_knn <- predict(knn_model, newdata = tlog, type = "prob")[,"Yes"] # 预测Yes的概率
train_prob_knn
# 支持向量机
train_pred_svm <- predict(svm_model, newdata = tlog) # 预测分类
train_pred_svm
train_prob_svm <- attr(predict(svm_model, newdata = tlog, probability = TRUE),
"probabilities")[, "Yes"] # 预测Yes的概率
train_prob_svm
# 神经网络
train_prob_nnet <- predict(nnet_model, tlog)[,2] # 预测Yes的概率
train_prob_nnet
train_pred_nnet <- factor(ifelse(train_prob_nnet > 0.5,'Yes','No')) # 预测分类
train_pred_nnet
#########4.2 混淆矩阵####
# Logistic模型
confusion_matrix_lr <- caret::confusionMatrix(train_pred_lr,
tlog$diabetes,
positive = "Yes")
print(confusion_matrix_lr)
# 决策树模型
confusion_matrix_tree <- caret::confusionMatrix(train_pred_tree,
tlog$diabetes,
positive = "Yes") # 训练集
print(confusion_matrix_tree)
# 随机森林
confusion_matrix_rf <- caret::confusionMatrix(train_pred_rf,
tlog$diabetes,
positive = "Yes")
print(confusion_matrix_rf)
# Xgboost模型
confusion_matrix_xgb <- caret::confusionMatrix(train_pred_xgb,
tlog$diabetes,
positive = "Yes")
print(confusion_matrix_xgb)
# LightGBM模型
confusion_matrix_lightgbm <- caret::confusionMatrix(train_pred_lightgbm,
tlog$diabetes,
positive = "Yes")
print(confusion_matrix_lightgbm)
# knn 模型
confusion_matrix_knn <- caret::confusionMatrix(train_pred_knn,
tlog$diabetes,
positive = "Yes")
print(confusion_matrix_knn)
# 支持向量机
confusion_matrix_svm <- caret::confusionMatrix(train_pred_svm,
tlog$diabetes,
positive = "Yes")
print(confusion_matrix_svm)
# 神经网络
confusion_matrix_nnet <- caret::confusionMatrix(train_pred_nnet,
tlog$diabetes,
positive = "Yes")
print(confusion_matrix_nnet)
#########4.3 ROC曲线####
## 计算ROC的auc值及95%CI
# (1) lr
roc_lr <- roc(tlog$diabetes, # 目标变量的真实标签
as.numeric(train_prob_lr) # 模型预测的概率值
)
auc_lr <- roc_lr$auc # AUC值
auc_lr
ci.auc(roc_lr) # AUC值的95%CI
# (2) tree
roc_tree <- roc(tlog$diabetes, as.numeric(train_prob_tree))
auc_tree <- roc_tree$auc
auc_tree
ci.auc(auc_tree)
# (3) rf
roc_rf <- roc(tlog$diabetes, as.numeric(train_prob_rf))
auc_rf <- roc_rf$auc
auc_rf
ci.auc(auc_rf)
# (4) xgboost
roc_xgb <- roc(tlog$diabetes, as.numeric(train_prob_xgb))
auc_xgb <- roc_xgb$auc
auc_xgb
ci.auc(auc_xgb)
# (5) lightgbm
roc_lightgbm <- roc(tlog$diabetes, as.numeric(train_prob_lightgbm))
auc_lightgbm <- roc_lightgbm$auc
auc_lightgbm
ci.auc(auc_lightgbm)
# (6) knn
roc_knn <- roc(tlog$diabetes, as.numeric(train_prob_knn))
auc_knn <- roc_knn$auc
auc_knn
ci.auc(auc_knn)
# (7) svm
roc_svm <- roc(tlog$diabetes, as.numeric(train_prob_svm))
auc_svm <- roc_svm$auc
auc_svm
ci.auc(auc_svm)
# (8) nnet
roc_nnet <- roc(tlog$diabetes, as.numeric(train_prob_nnet))
auc_nnet <- roc_nnet$auc
auc_nnet
ci.auc(auc_nnet)
# 绘制ROC曲线
plot(roc_lr,
col = "red", # 曲线颜色为红色
lwd = 2, # 曲线的线宽为 2
main = "ROC Curves for Training dataset", # 设置图的标题
xlab = "1 - Specificity", ylab = "Sensitivity", # 设置X轴和Y轴标签
legacy.axes = TRUE, # 使 X 轴范围从 0 到 1
cex.main = 1.5, # 设置标题字体大小
cex.lab = 1.2, cex.axis = 1.2 # 设置坐标轴标签和刻度字体大小
)
lines(roc_tree, col = "blue", lwd = 2)
lines(roc_rf, col = "green", lwd = 2)
lines(roc_knn, col = "purple", lwd = 2)
lines(roc_svm, col = "orange", lwd = 2)
lines(roc_nnet, col = "brown", lwd = 2)
lines(roc_xgb, col = "pink", lwd = 2)
lines(roc_lightgbm, col = "cyan", lwd = 2)
# 添加图例
legend("bottomright",
legend = c( # 创建每个模型的AUC文本
paste("Logistic Regression (AUC = ", round(auc_lr, 3), ")", sep = ""),
paste("Decision Tree (AUC = ", round(auc_tree, 3), ")", sep = ""),
paste("Random Forest (AUC = ", round(auc_rf, 3), ")", sep = ""),
paste("KNN (AUC = ", round(auc_knn, 3), ")", sep = ""),
paste("SVM (AUC = ", round(auc_svm, 3), ")", sep = ""),
paste("Neural Network (AUC = ", round(auc_nnet, 3), ")", sep = ""),
paste("XGBoost (AUC = ", round(auc_xgb, 3), ")", sep = ""),
paste("LightGBM (AUC = ", round(auc_lightgbm, 3), ")", sep = "") ),
col = c("red", "blue", "green", "purple", "orange",
"brown", "pink", "cyan"),
lty = 1, # 设置图例中线的样式为实线
lwd = 2, # 设置图例中线的宽度为 2
cex = 0.6) # 设置图例字体的缩放比例
#############4.4 校准曲线####
# 预测结果及真实标签汇总为一个数据框
calibration_data <- data.frame(
Model = c(rep("Logistic Regression", length(train_prob_lr)),# rep():重复指定字符串多次
rep("Decision Tree", length(train_prob_tree)),
rep("Random Forest", length(train_prob_rf)),
rep("KNN", length(train_prob_knn)),
rep("SVM", length(train_prob_svm)),
rep("Neural Network", length(train_prob_nnet)),
rep("XGBoost", length(train_prob_xgb)),
rep("LightGBM", length(train_prob_lightgbm))),
Probability = c(train_prob_lr,
train_prob_tree,
train_prob_rf,
train_prob_knn,
train_prob_svm,
train_prob_nnet,
train_prob_xgb,
train_prob_lightgbm),#将所有模型的预测概率按顺序拼接成一个向量
Actual = as.numeric(c(tlog$diabetes)) - 1 # 将因子转为数值
)
# 绘制光滑校准曲线
ggplot(calibration_data, aes(x = Probability, y = Actual, color = Model)) +
geom_smooth(method = "loess", se = FALSE, size = 1.5) + # 使用 LOESS 光滑曲线
geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black", size = 1) + # 理想参考线
scale_x_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.1)) +
scale_y_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.1)) +
labs(
title = "Calibration Curves",
x = "Actual Probability",
y = "Observed Proportion" ) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
legend.position = "bottom",
legend.title = element_text(size = 12),
legend.text = element_text(size = 10),
axis.line = element_line(colour = "black")) +
scale_color_brewer(palette = "Set1") # 使用醒目的配色方案
############4.5 决策曲线分析(DCA)曲线######
# 将模型的预测结果和真实标签组合成一个数据框
dca_tlog <- data.frame(diabetes = as.numeric(tlog$diabetes)-1,
train_prob_lr,
train_prob_tree,
train_prob_rf,
train_prob_knn,
train_prob_svm,
train_prob_nnet,
train_prob_xgb,
train_prob_lightgbm)
# Logistic 模型
dca.result_lr <- decision_curve(diabetes ~ train_prob_lr,
data = dca_tlog,
bootstraps = 10)
# 决策树
dca.result_tree <- decision_curve(diabetes ~ train_prob_tree,
data = dca_tlog,
bootstraps = 10)
# 随机森林
dca.result_rf <- decision_curve(diabetes ~ train_prob_rf,
data = dca_tlog,
bootstraps = 10)
# XGBoost
dca.result_xgb <- decision_curve(diabetes ~ train_prob_xgb,
data = dca_tlog,
bootstraps = 10)
# LightGBM
dca.result_lightgbm <- decision_curve(diabetes ~ train_prob_lightgbm,
data = dca_tlog,
bootstraps = 10)
# knn
dca.result_knn <- decision_curve(diabetes ~ train_prob_knn,
data = dca_tlog,
bootstraps = 10)
# 支持向量机(SVM)
dca.result_svm <- decision_curve(diabetes ~ train_prob_svm,
data = dca_tlog)
# 神经网络
dca.result_nnet <- decision_curve(diabetes ~ train_prob_nnet,
data = dca_tlog,
bootstraps = 10)
plot_decision_curve(
list(dca.result_lr, dca.result_tree, dca.result_rf,
dca.result_knn, dca.result_svm, dca.result_nnet,
dca.result_xgb, dca.result_lightgbm), # 传入包含决策曲线分析结果的列表
curve.names = c("Logistic Regression", "Decision Tree", "Random Forest",
"KNN", "SVM", "Neural Network", "XGBoost", "LightGBM"),
col = c("red", "green", "blue", "purple", "orange", "brown", "cyan", "magenta"),
lwd = 2, # 设置线宽
confidence.intervals = FALSE, # 禁用置信区间
legend.position = ("none")
)
# 手动添加图例
legend("bottomleft",
legend = c("Logistic Regression", "Decision Tree", "Random Forest",
"KNN", "SVM", "Neural Network", "XGBoost", "LightGBM"),
col = c("red", "green", "blue", "purple", "orange", "brown", "cyan", "magenta"),
lwd = 2,
cex = 0.6, # 调整cex改变字体大小
bty = "y", # 无边框
y.intersp = 0.8, # 调整条目之间的间距
x.intersp = 0.5, # 调整颜色线条与标签之间的水平间距
text.width = 0.1) # 自动调整宽度
##############################5.验证集模型效果评价##########################
######5.1 模型预测结果####
# 结局变量因子化
valdata$diabetes <- factor(valdata$diabetes,levels = c(0,1),labels = c('No','Yes'))
# Logistic模型
val_prob_lr <- predict(lr_model, newdata = valdata,
type = 'response') # 预测Yes的概率
val_prob_lr
val_pred_lr <- factor(ifelse(val_prob_lr > 0.5,'Yes','No')) # 预测分类
val_pred_lr
# 决策树模型
val_pred_tree <- predict(tree_model, newdata = valdata, type = "class") # 预测分类
val_pred_tree
val_prob_tree <- predict(tree_model, newdata = valdata,
type = "prob")[, 2] # 预测Yes的概率
val_prob_tree
# 随机森林
val_pred_rf <- predict(rf_model, newdata = valdata) # 预测分类
val_pred_rf
val_prob_rf <- predict(rf_model, newdata = valdata,
type = "prob")[, 2] # 预测Yes的概率
val_prob_rf
# Xgboost模型
val_prob_xgb <- predict(xgb_model, val_matrix) # 预测Yes的概率
val_prob_xgb
val_pred_xgb <- factor(ifelse(val_prob_xgb > 0.5,'Yes','No')) # 预测分类
val_pred_xgb
# LightGBM模型
val_prob_lightgbm <- predict(lightgbm_model,
newdata = as.matrix(valdata[,selected_vars]),
type = 'prob') # 预测Yes的概率
val_prob_lightgbm
val_pred_lightgbm <- predict(lightgbm_model,
newdata = as.matrix(valdata[,selected_vars]),
type = 'class') # 预测分类
val_pred_lightgbm <- factor(val_pred_lightgbm,
levels = c(0,1),labels = c('No','Yes'))
val_pred_lightgbm
# knn 模型
val_pred_knn <- predict(knn_model, newdata = valdata) # 预测分类
val_pred_knn
val_prob_knn <- predict(knn_model, newdata = valdata,
type = "prob")[,"Yes"] # 预测Yes的概率
val_prob_knn
# 支持向量机
val_pred_svm <- predict(svm_model, newdata = valdata) # 预测分类
val_pred_svm
val_prob_svm <- attr(predict(svm_model, newdata = valdata, probability = TRUE),
"probabilities")[, "Yes"] # 预测Yes的概率
val_prob_svm
# 神经网络
val_prob_nnet <- predict(nnet_model, valdata)[,2] # 预测Yes的概率
val_prob_nnet
val_pred_nnet <- factor(ifelse(val_prob_nnet > 0.5,'Yes','No')) # 预测分类
val_pred_nnet
#########5.2 混淆矩阵####
# Logistic模型
confusion_matrix_lr1 <- caret::confusionMatrix(
val_pred_lr, valdata$diabetes, positive = "Yes")
print(confusion_matrix_lr1)
# 决策树模型
confusion_matrix_tree1 <- caret::confusionMatrix(val_pred_tree,
valdata$diabetes,
positive = "Yes") # 训练集
print(confusion_matrix_tree1)
# 随机森林
confusion_matrix_rf1 <- caret::confusionMatrix(val_pred_rf,
valdata$diabetes,
positive = "Yes")
print(confusion_matrix_rf1)
# Xgboost模型
confusion_matrix_xgb1 <- caret::confusionMatrix(val_pred_xgb,
valdata$diabetes,
positive = "Yes")
print(confusion_matrix_xgb1)
# LightGBM模型
confusion_matrix_lightgbm1 <- caret::confusionMatrix(val_pred_lightgbm,
valdata$diabetes,
positive = "Yes")
print(confusion_matrix_lightgbm1)
# knn 模型
confusion_matrix_knn1 <- caret::confusionMatrix(val_pred_knn,
valdata$diabetes,
positive = "Yes")
print(confusion_matrix_knn1)
# 支持向量机
confusion_matrix_svm1 <- caret::confusionMatrix(val_pred_svm,
valdata$diabetes,
positive = "Yes")
print(confusion_matrix_svm1)
# 神经网络
confusion_matrix_nnet1 <- caret::confusionMatrix(val_pred_nnet,
valdata$diabetes,
positive = "Yes")
print(confusion_matrix_nnet1)
#########5.3 ROC曲线####
# 计算ROC的auc值及95%CI
roc_lr_val <- roc(valdata$diabetes, as.numeric(val_prob_lr))
auc_lr_val <- roc_lr_val$auc # AUC值
auc_lr_val
ci.auc(roc_lr_val) # AUC值的95%CI
roc_tree_val <- roc(valdata$diabetes, as.numeric(val_prob_tree))
auc_tree_val <- roc_tree_val $auc
auc_tree_val
ci.auc(auc_tree_val)
roc_rf_val <- roc(valdata$diabetes, as.numeric(val_prob_rf))
auc_rf_val <- roc_rf_val $auc
auc_rf_val
ci.auc(auc_rf_val)
roc_xgb_val <- roc(valdata$diabetes, as.numeric(val_prob_xgb))
auc_xgb_val <- roc_xgb_val $auc
auc_xgb_val
ci.auc(auc_xgb_val)
roc_lightgbm_val <- roc(valdata$diabetes, as.numeric(val_prob_lightgbm))
auc_lightgbm_val <- roc_lightgbm_val $auc
auc_lightgbm_val
ci.auc(auc_lightgbm_val)
roc_knn_val <- roc(valdata$diabetes, as.numeric(val_prob_knn))
auc_knn_val <- roc_knn_val $auc
auc_knn_val
ci.auc(auc_knn_val)
roc_svm_val <- roc(valdata$diabetes, as.numeric(val_prob_svm))
auc_svm_val <- roc_svm_val$auc
auc_svm_val
ci.auc(auc_svm_val)
roc_nnet_val <- roc(valdata$diabetes, as.numeric(val_prob_nnet))
auc_nnet_val <- roc_nnet_val $auc
auc_nnet_val
ci.auc(auc_nnet_val)
# 绘制ROC曲线
plot(roc_lr_val, col = "red", lwd = 2, main = "ROC Curves for val dataset",
xlab = "1 - Specificity", ylab = "Sensitivity", legacy.axes = TRUE,
cex.main = 1.6, cex.lab = 1.3, cex.axis = 1.2)
lines(roc_tree_val, col = "blue", lwd = 2)
lines(roc_rf_val, col = "green", lwd = 2)
lines(roc_knn_val, col = "purple", lwd = 2)
lines(roc_svm_val, col = "orange", lwd = 2)
lines(roc_nnet_val, col = "brown", lwd = 2)
lines(roc_xgb_val, col = "pink", lwd = 2)
lines(roc_lightgbm_val, col = "cyan", lwd = 2)
# 添加图例
legend("bottomright",
legend = c(
paste("Logistic Regression (AUC = ", round(auc_lr_val, 3), ")", sep = ""),
paste("Decision Tree (AUC = ", round(auc_tree_val, 3), ")", sep = ""),
paste("Random Forest (AUC = ", round(auc_rf_val, 3), ")", sep = ""),
paste("KNN (AUC = ", round(auc_knn_val, 3), ")", sep = ""),
paste("SVM (AUC = ", round(auc_svm_val, 3), ")", sep = ""),
paste("Neural Network (AUC = ", round(auc_nnet_val, 3), ")", sep = ""),
paste("XGBoost (AUC = ", round(auc_xgb_val, 3), ")", sep = ""),
paste("LightGBM (AUC = ", round(auc_lightgbm_val, 3), ")", sep = "") ),
col = c("red", "blue", "green", "purple", "orange",
"brown", "pink", "cyan"),
lty = 1, lwd = 2, cex = 0.6)
#############5.4 校准曲线####
# 预测结果及真实标签汇总为一个数据框
calibration_data1 <- data.frame(
Model = c(rep("Logistic Regression", length(val_prob_lr)),
rep("Decision Tree", length(val_prob_tree)),
rep("Random Forest", length(val_prob_rf)),
rep("KNN", length(val_prob_knn)),
rep("SVM", length(val_prob_svm)),
rep("Neural Network", length(val_prob_nnet)),
rep("XGBoost", length(val_prob_xgb)),
rep("LightGBM", length(val_prob_lightgbm))),
Probability = c(val_prob_lr,
val_prob_tree,
val_prob_rf,
val_prob_knn,
val_prob_svm,
val_prob_nnet,
val_prob_xgb,
val_prob_lightgbm),
Actual = as.numeric(c(valdata$diabetes)) - 1 ) # 将因子转为数值
# 绘制光滑校准曲线
ggplot(calibration_data1, aes(x = Probability, y = Actual, color = Model)) +
geom_smooth(method = "loess", se = FALSE, size = 1.5) + # 使用 LOESS 光滑曲线
geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black", size = 1) + # 理想参考线
scale_x_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.1)) +
scale_y_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.1)) +
labs(
title = "Calibration Curves",
x = "Actual Probability",
y = "Observed Proportion" ) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
legend.position = "bottom",
legend.title = element_text(size = 12),
legend.text = element_text(size = 10),
axis.line = element_line(colour = "black")) +
scale_color_brewer(palette = "Set1") # 使用醒目的配色方案
############5.5 DCA曲线######
dca_valdata <- data.frame(diabetes = as.numeric(valdata$diabetes)-1,
val_prob_lr,
val_prob_tree,
val_prob_rf,
val_prob_knn,
val_prob_svm,
val_prob_nnet,
val_prob_xgb,
val_prob_lightgbm)
# Logistic Regression
dca.result_lr1 <- decision_curve(diabetes ~ val_prob_lr,
data = dca_valdata,
bootstraps = 10)
# Decision Tree
dca.result_tree1 <- decision_curve(diabetes ~ val_prob_tree,
data = dca_valdata,
bootstraps = 10)
# Random Forest
dca.result_rf1 <- decision_curve(diabetes ~ val_prob_rf,
data = dca_valdata,
bootstraps = 10)
# XGBoost
dca.result_xgb1 <- decision_curve(diabetes ~ val_prob_xgb,
data = dca_valdata,
bootstraps = 10)
# LightGBM
dca.result_lightgbm1 <- decision_curve(diabetes ~ val_prob_lightgbm,
data = dca_valdata,
bootstraps = 10)
# KNN
dca.result_knn1 <- decision_curve(diabetes ~ val_prob_knn,
data = dca_valdata,
bootstraps = 10)
# SVM
dca.result_svm1 <- decision_curve(diabetes ~ val_prob_svm,
data = dca_valdata,
bootstraps = 10)
# Neural Network
dca.result_nnet1 <- decision_curve(diabetes ~ val_prob_nnet,
data = dca_valdata,
bootstraps = 10)
plot_decision_curve(
list(dca.result_lr1, dca.result_tree1, dca.result_rf1,
dca.result_knn1, dca.result_svm1, dca.result_nnet1,
dca.result_xgb1, dca.result_lightgbm1), # 传入包含决策曲线分析结果的列表
curve.names = c("Logistic Regression", "Decision Tree", "Random Forest",
"KNN", "SVM", "Neural Network", "XGBoost", "LightGBM"),
col = c("red", "green", "blue", "purple", "orange", "brown", "cyan", "magenta"),
lwd = 2, # 设置线宽
confidence.intervals = FALSE, # 禁用置信区间
legend.position = ("none")
)
# 手动添加图例
legend("bottomright",
legend = c("Logistic Regression", "Decision Tree", "Random Forest",
"KNN", "SVM", "Neural Network", "XGBoost", "LightGBM"),
col = c("red", "green", "blue", "purple", "orange", "brown", "cyan", "magenta"),
lwd = 2,
cex = 0.6, # 通过调整cex改变字体大小
bty = "y", # 无边框
y.intersp = 0.8, # 调整条目之间的间距
x.intersp = 0.5, # 调整颜色线条与标签之间的水平间距
text.width = 0.15) # 自动调整宽度
#################### 保存所有绘制的图片为PNG格式 ####################
###### 1. 列线图 (Nomogram) ######
png("nomogram.png", width=1000, height=800, res=150)
regplot(lr_model,
title = "Nomogram",
points = TRUE,
axis.text.size = 12,
title.text.size = 14)
dev.off()
###### 2. 决策树图 ######
png("decision_tree.png", width=1200, height=800, res=150)
plot(as.party(tree_model))
dev.off()
###### 3. 训练集ROC曲线 ######
png("train_roc_curves.png", width=1000, height=800, res=150)
plot(roc_lr,
col = "red", lwd = 2,
main = "ROC Curves for Training dataset",
xlab = "1 - Specificity", ylab = "Sensitivity",
legacy.axes = TRUE, cex.main = 1.5, cex.lab = 1.2, cex.axis = 1.2)
lines(roc_tree, col = "blue", lwd = 2)
lines(roc_rf, col = "green", lwd = 2)
lines(roc_knn, col = "purple", lwd = 2)
lines(roc_svm, col = "orange", lwd = 2)
lines(roc_nnet, col = "brown", lwd = 2)
lines(roc_xgb, col = "pink", lwd = 2)
lines(roc_lightgbm, col = "cyan", lwd = 2)
legend("bottomright",
legend = c(
paste("Logistic Regression (AUC = ", round(auc_lr, 3), ")"),
paste("Decision Tree (AUC = ", round(auc_tree, 3), ")"),
paste("Random Forest (AUC = ", round(auc_rf, 3), ")"),
paste("KNN (AUC = ", round(auc_knn, 3), ")"),
paste("SVM (AUC = ", round(auc_svm, 3), ")"),
paste("Neural Network (AUC = ", round(auc_nnet, 3), ")"),
paste("XGBoost (AUC = ", round(auc_xgb, 3), ")"),
paste("LightGBM (AUC = ", round(auc_lightgbm, 3), ")") ),
col = c("red", "blue", "green", "purple", "orange",
"brown", "pink", "cyan"),
lty = 1, lwd = 2, cex = 0.6)
dev.off()
###### 4. 训练集校准曲线 ######
png("train_calibration_curve.png", width=1000, height=800, res=150)
ggplot(calibration_data, aes(x = Probability, y = Actual, color = Model)) +
geom_smooth(method = "loess", se = FALSE, size = 1.5) +
geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black", size = 1) +
scale_x_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.1)) +
scale_y_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.1)) +
labs(title = "Calibration Curves (Training Set)",
x = "Predicted Probability",
y = "Observed Proportion") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
legend.position = "bottom",
legend.title = element_text(size = 12),
legend.text = element_text(size = 10),
axis.line = element_line(colour = "black")) +
scale_color_brewer(palette = "Set1")
dev.off()
###### 5. 训练集DCA曲线 ######
png("train_dca_curve.png", width=1000, height=800, res=150)
plot_decision_curve(
list(dca.result_lr, dca.result_tree, dca.result_rf,
dca.result_knn, dca.result_svm, dca.result_nnet,
dca.result_xgb, dca.result_lightgbm),
curve.names = c("Logistic Regression", "Decision Tree", "Random Forest",
"KNN", "SVM", "Neural Network", "XGBoost", "LightGBM"),
col = c("red", "green", "blue", "purple", "orange", "brown", "cyan", "magenta"),
lwd = 2,
confidence.intervals = FALSE,
legend.position = "none"
)
legend("bottomleft",
legend = c("Logistic Regression", "Decision Tree", "Random Forest",
"KNN", "SVM", "Neural Network", "XGBoost", "LightGBM"),
col = c("red", "green", "blue", "purple", "orange", "brown", "cyan", "magenta"),
lwd = 2, cex = 0.6, bty = "y", y.intersp = 0.8, x.intersp = 0.5, text.width = 0.1)
dev.off()
###### 6. 验证集ROC曲线 ######
png("validation_roc_curves.png", width=1000, height=800, res=150)
plot(roc_lr_val, col = "red", lwd = 2,
main = "ROC Curves for Validation Set",
xlab = "1 - Specificity", ylab = "Sensitivity",
legacy.axes = TRUE, cex.main = 1.6, cex.lab = 1.3, cex.axis = 1.2)
lines(roc_tree_val, col = "blue", lwd = 2)
lines(roc_rf_val, col = "green", lwd = 2)
lines(roc_knn_val, col = "purple", lwd = 2)
lines(roc_svm_val, col = "orange", lwd = 2)
lines(roc_nnet_val, col = "brown", lwd = 2)
lines(roc_xgb_val, col = "pink", lwd = 2)
lines(roc_lightgbm_val, col = "cyan", lwd = 2)
legend("bottomright",
legend = c(
paste("Logistic Regression (AUC = ", round(auc_lr_val, 3), ")"),
paste("Decision Tree (AUC = ", round(auc_tree_val, 3), ")"),
paste("Random Forest (AUC = ", round(auc_rf_val, 3), ")"),
paste("KNN (AUC = ", round(auc_knn_val, 3), ")"),
paste("SVM (AUC = ", round(auc_svm_val, 3), ")"),
paste("Neural Network (AUC = ", round(auc_nnet_val, 3), ")"),
paste("XGBoost (AUC = ", round(auc_xgb_val, 3), ")"),
paste("LightGBM (AUC = ", round(auc_lightgbm_val, 3), ")") ),
col = c("red", "blue", "green", "purple", "orange",
"brown", "pink", "cyan"),
lty = 1, lwd = 2, cex = 0.6)
dev.off()
###### 7. 验证集校准曲线 ######
png("validation_calibration_curve.png", width=1000, height=800, res=150)
ggplot(calibration_data1, aes(x = Probability, y = Actual, color = Model)) +
geom_smooth(method = "loess", se = FALSE, size = 1.5) +
geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black", size = 1) +
scale_x_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.1)) +
scale_y_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.1)) +
labs(title = "Calibration Curves (Validation Set)",
x = "Predicted Probability",
y = "Observed Proportion") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
legend.position = "bottom",
legend.title = element_text(size = 12),
legend.text = element_text(size = 10),
axis.line = element_line(colour = "black")) +
scale_color_brewer(palette = "Set1")
dev.off()
###### 8. 验证集DCA曲线 ######
png("validation_dca_curve.png", width=1000, height=800, res=150)
plot_decision_curve(
list(dca.result_lr1, dca.result_tree1, dca.result_rf1,
dca.result_knn1, dca.result_svm1, dca.result_nnet1,
dca.result_xgb1, dca.result_lightgbm1),
curve.names = c("Logistic Regression", "Decision Tree", "Random Forest",
"KNN", "SVM", "Neural Network", "XGBoost", "LightGBM"),
col = c("red", "green", "blue", "purple", "orange", "brown", "cyan", "magenta"),
lwd = 2,
confidence.intervals = FALSE,
legend.position = "none"
)
legend("bottomright",
legend = c("Logistic Regression", "Decision Tree", "Random Forest",
"KNN", "SVM", "Neural Network", "XGBoost", "LightGBM"),
col = c("red", "green", "blue", "purple", "orange", "brown", "cyan", "magenta"),
lwd = 2, cex = 0.6, bty = "y", y.intersp = 0.8, x.intersp = 0.5, text.width = 0.15)
dev.off()
###### 9. 保存KNN调参结果图 ######
png("knn_tuning_results.png", width=1000, height=800, res=150)
ggplot(kknn_model) +
theme_minimal() +
ggtitle("KNN Hyperparameter Tuning Results")
dev.off()6.图片展示

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)