3. 机器学习-线性回归
3. 机器学习-线性回归
1)是什么
线性回归是一种监督学习算法,用于建立输入特征与连续目标变量之间的线性关系模型。其核心假设是:输出 y 可以通过输入特征的加权和加上一个偏置项来近似表示。数学形式为:
✅ 小结:线性回归用一条“直线”(或超平面)拟合数据,目标是预测连续数值。
2)为什么
线性回归被广泛使用,不仅因为其实现简单,更因其具备良好的可解释性和坚实的统计理论基础。它能快速提供特征对结果的影响方向和强度(通过系数大小和符号),常被用作基准模型。此外,它是许多高级模型(如岭回归、Lasso、逻辑回归)的基础。
✅ 小结:线性回归简单、高效、可解释,是理解更复杂模型的起点。
3)什么时候用
当目标变量是连续值,且特征与目标之间存在近似线性关系时,线性回归非常适用。典型场景包括房价预测、销售额估算、温度建模等。它也适合需要透明决策过程的领域(如金融、医疗),以及作为初步探索性建模工具。
✅ 小结:适用于连续目标、线性关系、强调可解释性或作为基线模型的场景。
4)什么时候不用
若数据呈现明显非线性模式、存在大量异常值、特征高度相关(多重共线性),或任务本质是分类而非回归,则线性回归效果不佳。此外,在误差方差不恒定(异方差)或样本量极小时,其假设前提被破坏,结果不可靠。
✅ 小结:非线性、异常值多、共线性强、分类任务或违反基本假设时,应避免使用。
5)总结
线性回归是机器学习的基石之一,兼具实用性与教学价值。它在满足基本假设的前提下表现稳健,但面对复杂现实数据时可能力不从心。合理使用需结合数据探索、诊断检验(如残差分析)和模型对比。
✅ 最终小结:线性回归是“简单但不简陋”的工具——用得好,事半功倍;用得不当,误导结论。始终先验证假设,再决定是否采用。
概念
3.1 损失函数
损失函数用于量化模型预测值与真实值之间的误差,是优化过程的核心目标。不同的损失函数对误差的敏感程度不同,直接影响模型的行为。
小结 🎯:损失函数定义了“什么是好预测”,需根据数据特性和任务目标合理选择。
3.1.1 最小二乘法 LS
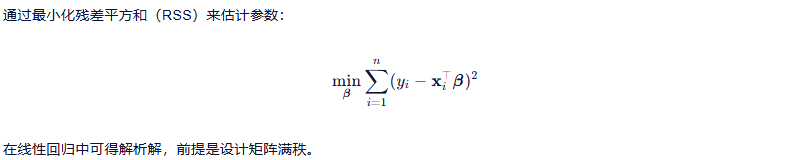
小结 🔹:理论扎实、计算直接,但对异常值敏感,适用于噪声较小的场景。
3.1.2 均方误差 MSE
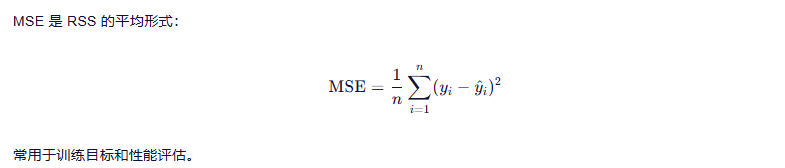
小结 🔸:放大较大误差,适合对严重偏差零容忍的任务,但易受离群点干扰。
3.1.3 平均绝对值误差 MAE
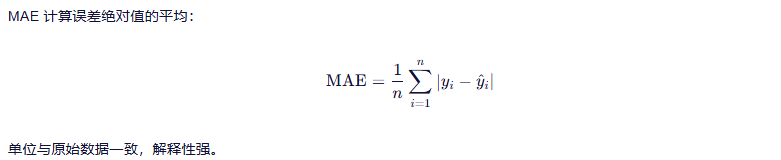
小结 🟢:稳健、直观,抗异常值能力强,但优化过程不如 MSE 光滑。
3.2 寻找最小损失函数
确定损失函数后,需通过优化方法求解最优参数。主要分为解析法和迭代法两类。
小结 ⚙️:方法选择取决于数据规模、特征维度和计算资源。
3.2.1 正规方程法(解析法)
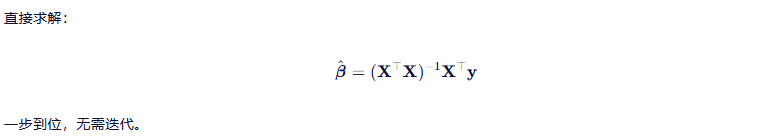
小结 🔷:高效精确,但仅适用于小规模、低维且无共线性的数据。
3.2.2 梯度下降法(迭代法)
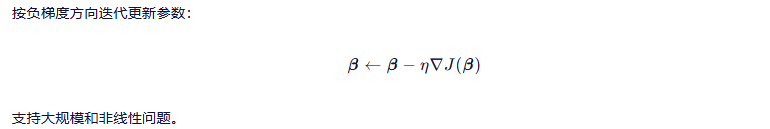
小结 🔄:通用性强,是现代机器学习的基础优化工具,需调好学习率并监控收敛。
3.3 回归模型评估方法
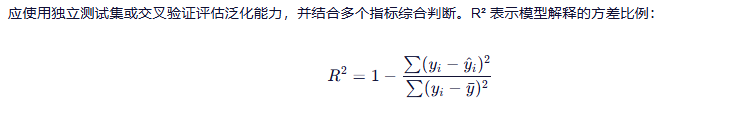
小结 📊:高训练分数 ≠ 好模型,泛化能力才是关键。
3.4 拟合问题
模型复杂度需与数据匹配:太简单 → 欠拟合;太复杂 → 过拟合。
小结 ⚖️:理想模型在偏差与方差之间取得平衡。
3.4.1 欠拟合
模型无法捕捉基本趋势,训练与测试误差均高。
小结 📉:表现“学不会”,可通过增强模型或增加有效特征改善。
3.4.2 过拟合
模型在训练集上表现极佳,但在新数据上大幅退步。
小结 📈:表现“死记硬背”,需简化模型或引入正则化。
3.4.3 正则化

小结 🛡️:有效控制模型复杂度,提升泛化能力,是应对过拟合的标准手段。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)