【ICCV 2025】遥感图像分割新SOTA——Dynamic Dictionary Learning for Remote Sensing Image Segmentation
🚀 Dynamic Dictionary Learning for Remote Sensing Image Segmentation
标题解析
标题“Dynamic Dictionary Learning for Remote Sensing Image Segmentation”其实就是在讲,作者用了一种可以动态变化的“语义字典”方法,来提升遥感图像分割的表现。所谓“动态”,就是说这个字典不是死的,每张图都会根据具体内容调整类别的表示方式,能更好地应对不同场景下那些长得很像、容易分错的地物。而“字典学习”本质上就是给每一类东西都分配一组向量,传统做法往往一开始就定死了,作者则是让它不断优化和更新,适应性更强。结合到遥感分割这个领域,这种方式能更好地区分难分的地物,比如区分细云和厚云、区分草地和农田等,所以这篇文章其实就是在解决遥感影像里“分不清楚谁是谁”这个老大难问题。
效果展示
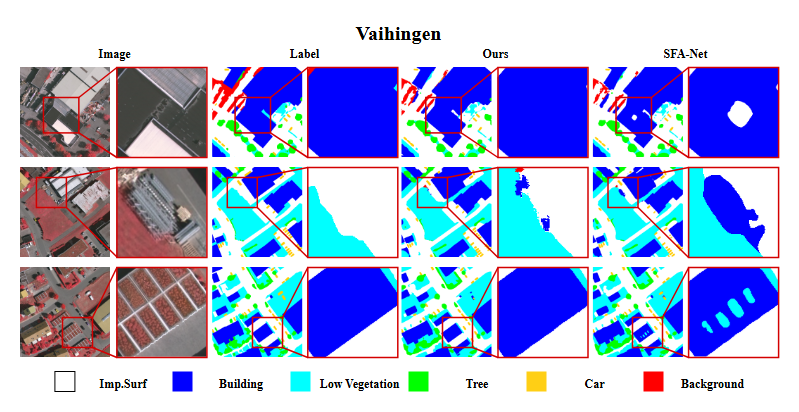
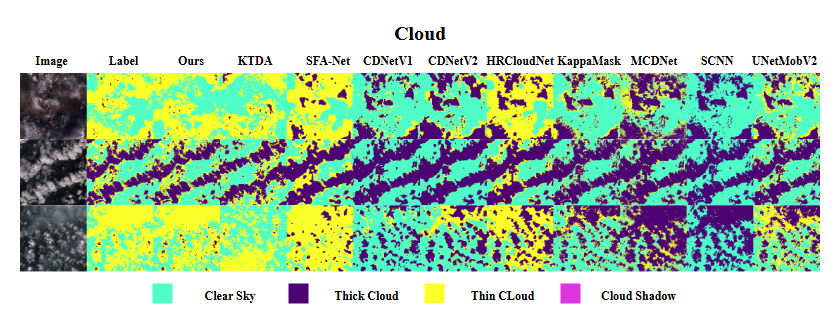
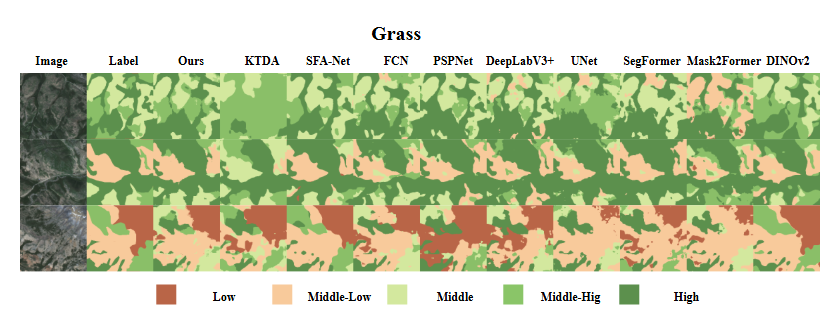
研究动机
遥感图像分割任务里,经常会遇到一些棘手的问题,比如说同一个类别内部差异很大、不同类别外观却很像(比如薄云和厚云、草地和农田傻傻分不清楚)。很多现有的方法都只是在特征层面做“隐式表示”,没有真正把每个类别的语义特征“显式”地区分开,这就导致模型在细粒度场景下表现一般,很容易混淆。为了解决这些痛点,作者希望能设计一种机制,让模型可以主动、动态地根据输入图像调整和优化每个类别的语义表示,从而更精准地区分复杂场景下的地物,尤其是在那些长得特别像的类别之间。正是带着这个想法,本文提出了动态字典学习的方法,目标就是让遥感图像分割在精细分类和泛化能力上都能更进一步。
本文方法
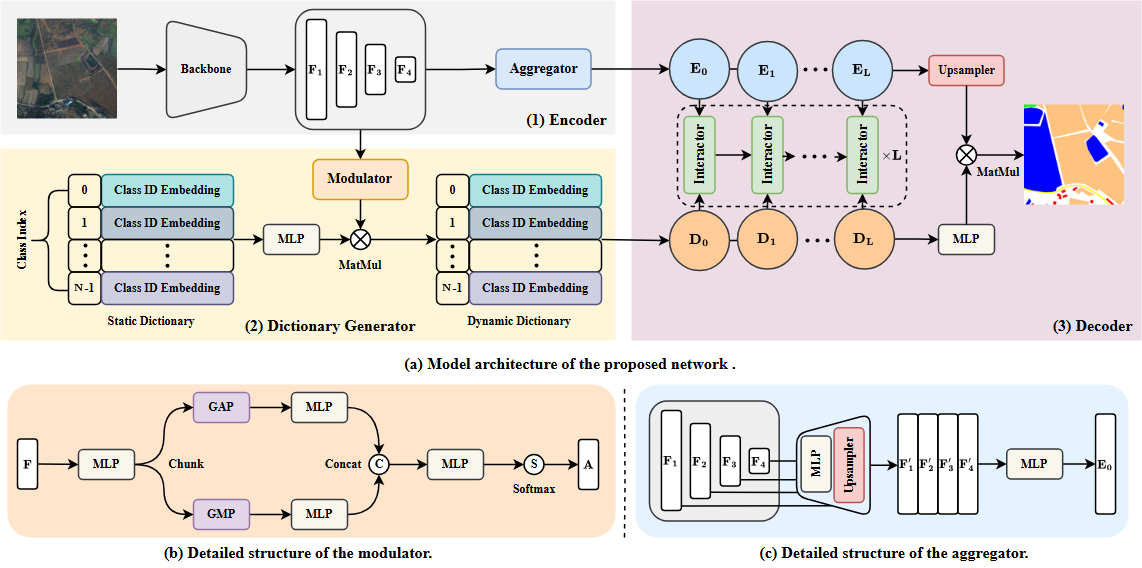
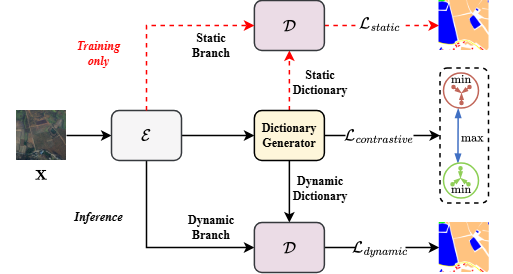
本文提出了一种面向遥感图像分割的动态字典学习方法(Dynamic Dictionary Learning),其核心思想是让模型能够根据每张输入遥感图像的具体内容,动态调整每个类别的语义表示,从而提升对外观相似或边界模糊地物的分割效果。整体框架如图所示,包含三大核心模块:编码器(Encoder)、字典生成器(Dictionary Generator)和解码器(Decoder)。
1. 编码器(Encoder)
首先,编码器部分(见图(1))接收输入遥感图像,利用 Backbone 网络提取多尺度特征 F 1 , F 2 , F 3 , F 4 F_1, F_2, F_3, F_4 F1,F2,F3,F4。这些特征随后经过 Aggregator(图©)进一步融合和重构,得到统一的语义特征表示 E 0 , E 1 , … , E L E_0, E_1, \ldots, E_L E0,E1,…,EL,为后续字典生成和分割做准备。
2. 字典生成器(Dictionary Generator)
在字典生成器模块(见图(2)),每个类别都对应一个可学习的 Class ID Embedding,初步构成静态字典。这里引入了创新性的 Modulator(图(b)):它对编码器输出特征进行全局平均池化(GAP)和最大池化(GMP),经过多层感知机(MLP)处理后,生成一组 Softmax 注意力权重 S S S。这些权重会对静态字典做自适应调制,最终得到针对当前输入图像“量身定制”的动态字典 D 0 , D 1 , … , D L D_0, D_1, \ldots, D_L D0,D1,…,DL。这种设计让每一类的表示都能根据实际图像内容灵活调整,极大提升了对地物类别边界模糊、外观相似等难题的适应能力。
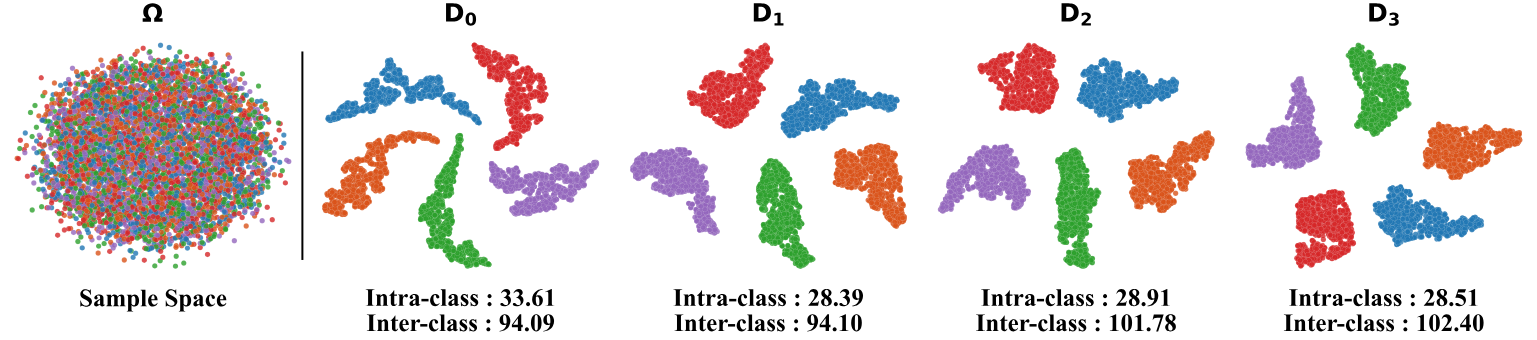
上图直观展示了动态字典学习对类别特征空间分布的优化效果。左侧 Ω \Omega Ω 为原始样本空间,可以看到各类别特征混杂在一起、分布较为散乱;而右侧 D 0 , D 1 , D 2 , D 3 D_0, D_1, D_2, D_3 D0,D1,D2,D3 分别为不同阶段的动态字典特征分布。随着动态调制的进行,同类样本聚集(Intra-class 距离减小)、异类样本分离(Inter-class 距离增大),类别边界更加清晰。这一现象也被量化为下方的 Intra-class 和 Inter-class 数值,说明动态字典有效提升了语义区分度,为后续高精度分割提供了坚实基础。
3. 解码器(Decoder)
在解码器阶段(见图(3)),特征 ( E ) 和动态字典 ( D ) 通过多层 Interactor(交叉注意力机制)进行深度交互,每一轮都让类别向量与特征相互融合和优化。这种动态交互过程重复 L 次,逐步增强类别与特征的耦合关系。最终,经过 MLP 处理和 Upsampler 上采样,将分割结果还原为高分辨率输出,实现精细的地物分割。
4. 训练策略与损失设计
在训练阶段,模型同时包含静态分支和动态分支。静态分支主要作为训练辅助和性能对比,动态分支用于最终的推理和实际应用。损失函数不仅包含常规的交叉熵和 Dice 损失,还特别引入了对比损失,用于拉近同类别向量、拉远异类别向量,从而进一步提升模型区分类似地物的能力。
5. 方法优势总结
通过 Encoder、Dictionary Generator 和 Decoder 三大模块协同优化,结合静态与动态字典的联合训练,这一动态字典学习方法能够有效提升遥感图像分割在城市地物、云层厚度、草地覆盖等多种复杂场景下的表现,无论粗粒度还是细粒度任务都能获得更加精准、鲁棒的分割结果。
数据集介绍
本文在六个具有代表性的遥感图像分割数据集上进行了实验,涵盖了从卫星到无人机的多尺度、多场景、多分辨率数据,既包含粗粒度的城市/土地覆盖分割,也涉及细粒度的云和草地类型区分,保证了方法评测的全面性和通用性。
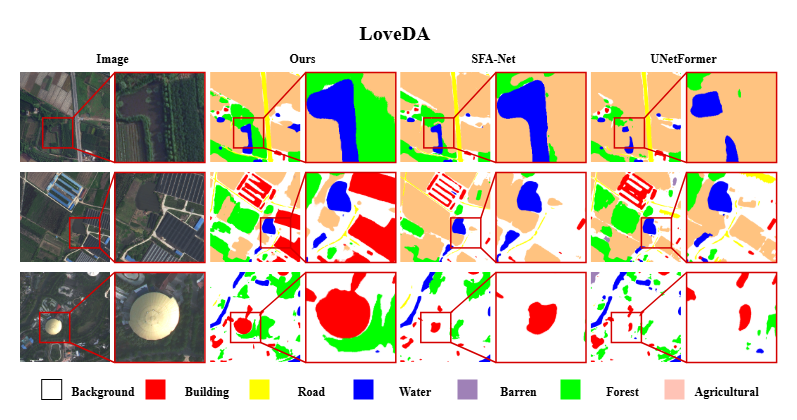
1. LoveDA
LoveDA 是一个面向城乡土地覆盖的高分辨率卫星影像分割数据集,空间分辨率为 0.3 米,总共包含 5987 幅 512×512 像素的图像,采集自中国南京、常州和武汉三座城市,覆盖城市和农村两种典型环境。类别包括:背景、建筑、道路、水体、荒地、森林、农业。LoveDA 的多样场景和复杂地物分布,非常适合评估模型在不同场景下的泛化能力。
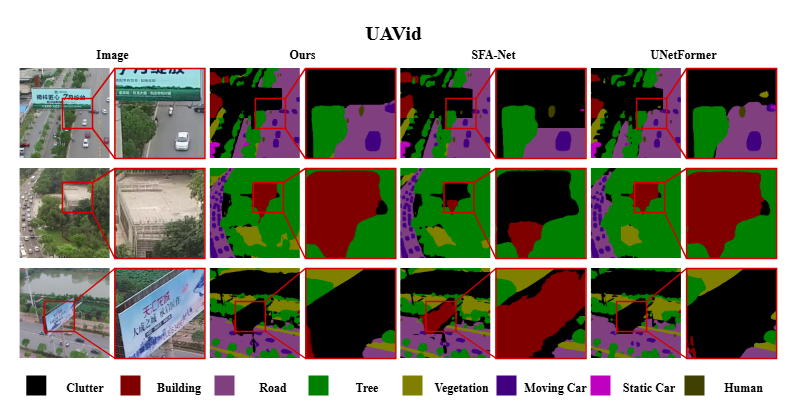
2. UAVid
UAVid 是专为城市环境语义分割设计的高分辨率无人机航拍数据集,由 42 段视频、420 幅图像组成,空间分辨率最高达 4096×2160。采集高度约 50 米,既包含俯视也有侧视角度,覆盖建筑、道路、树木、低矮植被、车辆、人类及城市杂物等多类目标。训练时将大图划分为 1024×1024 小块,适用于复杂城区的多目标、细节分割评估。
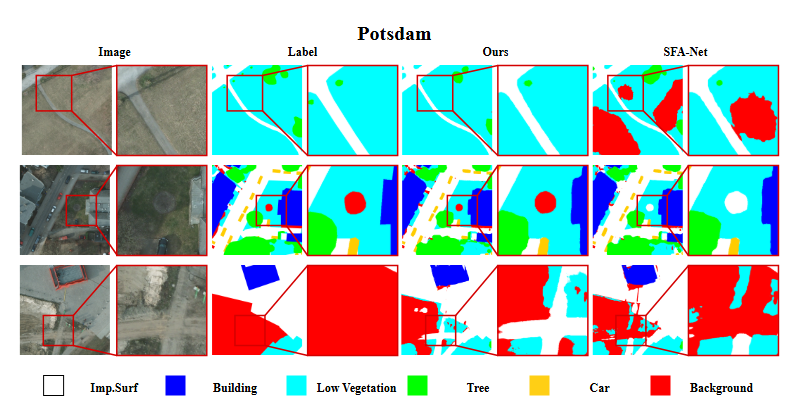
3. Potsdam
ISPRS Potsdam 数据集包含 38 幅无人机航拍图像,分辨率为 6000×6000 像素,地面分辨率 5cm,标注有6大类:不可渗透地表(如路面)、建筑物、低矮植被、树木、汽车、杂物。本文实验采用主 RGB 通道,并将图像切割为 1024×1024 区块。该数据集典型用于高分辨率城市遥感分割任务。
4. Vaihingen
ISPRS Vaihingen 数据集提供 33 幅分辨率 0.5 米的高分辨率城市影像,平均每幅图像为 2494×2064 像素,覆盖德国瓦兴根城区。标注类别同 Potsdam:不可渗透地表、建筑、低矮植被、树木、汽车、杂物。图像同样被裁剪为 1024×1024 以便模型训练和测试。该数据集以其复杂的城市结构和高质量标注被广泛用作遥感分割基准。
5. Cloud
Cloud 数据集专为细粒度云检测设计,来源于 Landsat 8 卫星 96 幅地形校正(Level-1T)场景,包含多种生态类型下的复杂云层。每幅影像被划分为 512×512 小块,类别涵盖:云影、晴空、薄云、厚云,并按 6:2:2 划分训练/验证/测试。Cloud 数据集的丰富云类型及像元级标注,极适合云分割、云检测等研究。
6. Grass
Grass 数据集基于中国玛多县(黄河源区)2019年高分二号/高分六号卫星数据构建,空间分辨率 8m。包含 1500 对 256×256 的高分辨率遥感影像与对应草地覆盖等级标注(五类:低、中低、中、中高、高),通过半自动与人工精修确保标注准确。该数据集特别适用于高原复杂地貌下细粒度草地分割和生态研究。
通过在这些多源异构且难度各异的数据集上验证,本文方法展现出了对粗粒度(如城市土地覆盖)与细粒度(如云类型、草地等级)遥感分割任务的卓越适应性和泛化能力。
实验结果
本文在六个公开遥感分割数据集上系统评估了动态字典学习方法(D2LS),并与多种主流 SOTA 算法进行了对比,具体实验结果如下:
LoveDA 数据集
| 方法 | Background | Building | Road | Water | Barren | Forest | Agriculture | mIoU |
|---|---|---|---|---|---|---|---|---|
| TransUNet | 43.0 | 56.1 | 53.7 | 78.0 | 9.3 | 44.9 | 56.9 | 48.9 |
| DC-Swin | 41.3 | 54.5 | 56.2 | 78.1 | 14.5 | 47.2 | 62.4 | 50.6 |
| UNetFormer | 44.7 | 58.8 | 54.9 | 79.6 | 20.1 | 46.0 | 62.5 | 52.4 |
| Hi-Resnet | 46.7 | 58.3 | 55.9 | 80.1 | 17.0 | 46.7 | 62.7 | 52.5 |
| AerialFormer | 47.8 | 60.7 | 59.3 | 81.5 | 17.9 | 47.9 | 64.0 | 54.1 |
| SFA-Net | 48.4 | 60.3 | 59.1 | 81.9 | 24.1 | 46.2 | 64.0 | 54.9 |
| D2LS | 47.6 | 61.2 | 59.1 | 81.6 | 23.8 | 48.8 | 64.8 | 55.3 |
提升分析:D2LS 的 mIoU 达到 55.3%,相比上一代 SOTA(SFA-Net,54.9%)提升 0.4 个百分点,特别在建筑、农业等复杂类别上表现更为突出。
UAVid 数据集
| 方法 | Clutter | Building | Road | Tree | Low Vegetation | Moving Car | Static Car | Human | mIoU |
|---|---|---|---|---|---|---|---|---|---|
| DANet | 64.9 | 58.9 | 77.9 | 68.3 | 61.5 | 59.6 | 47.4 | 9.1 | 60.6 |
| ABCNet | 67.4 | 86.4 | 81.2 | 79.9 | 63.1 | 69.8 | 48.4 | 13.9 | 63.8 |
| BANet | 66.7 | 85.4 | 80.7 | 78.9 | 62.1 | 69.3 | 52.8 | 21.0 | 64.6 |
| SegFormer | 66.6 | 86.3 | 80.1 | 79.6 | 62.3 | 72.5 | 52.5 | 28.5 | 66.0 |
| UNetFormer | 68.4 | 87.4 | 81.5 | 80.2 | 63.5 | 73.6 | 56.4 | 31.0 | 67.8 |
| SFA-Net | 70.2 | 89.0 | 82.7 | 80.8 | 64.6 | 77.5 | 67.5 | 30.7 | 70.4 |
| D2LS | 71.0 | 89.7 | 83.2 | 82.1 | 66.1 | 75.0 | 59.0 | 41.4 | 70.9 |
提升分析:在 UAVid 城市无人机场景,D2LS 的 mIoU 达 70.9%,相比 SFA-Net 提升 0.5 个百分点,对小目标(如人类、车辆)分割表现尤为突出。
Potsdam 数据集
| 方法 | mF1 |
|---|---|
| DANet | 88.9 |
| ABCNet | 92.7 |
| Segmenter | 89.2 |
| BANet | 92.5 |
| SwinUperNet | 92.2 |
| DC-Swin | 93.3 |
| UNetFormer | 93.5 |
| AerialFormer | 94.1 |
| SFA-Net | 93.5 |
| D2LS | 94.7 |
Vaihingen 数据集
| 方法 | mF1 |
|---|---|
| DANet | 79.6 |
| ABCNet | 89.5 |
| Segmenter | 84.1 |
| BANet | 89.6 |
| SwinUperNet | 89.8 |
| DC-Swin | 90.7 |
| UNetFormer | 90.4 |
| AerialFormer | 90.1 |
| SFA-Net | 91.2 |
| D2LS | 91.9 |
提升分析:在 Potsdam、Vaihingen 两个高分辨率城市数据集上,D2LS 的 mF1 分别提升 1.2 和 0.7 个百分点,对复杂城市场景下的边界细节表现尤为出色。
Grass 数据集
| 方法 | mF1 |
|---|---|
| FCN | 61.99 |
| PSPNet | 62.55 |
| DeepLabV3+ | 62.50 |
| UNet | 62.34 |
| SegFormer | 62.82 |
| Mask2Former | 58.91 |
| DINOv2 | 61.70 |
| KTDA | 65.01 |
| SFA-Net | 65.76 |
| D2LS | 66.27 |
提升分析:在高原草地分割任务中,D2LS 的 mF1 提升至 66.3%,超过 KTDA、SFA-Net 等基线,提升约 0.5 个百分点,五级草地覆盖区分能力更强。
Cloud 数据集
| 方法 | mF1 |
|---|---|
| MCDNet | 42.76 |
| SCNN | 52.41 |
| CDNetv1 | 45.80 |
| KappaMask | 68.47 |
| UNetMobv2 | 56.91 |
| CDNetv2 | 70.33 |
| HRCloudNet | 71.36 |
| KTDA | 60.08 |
| SFA-Net | 84.64 |
| D2LS | 89.65 |
提升分析:在细粒度云分割 Cloud 数据集上,D2LS 的 mF1 相比 SFA-Net 大幅提升 5.1 个百分点,薄云、云影等难区分类别表现尤为显著。
总体来看,D2LS 在各类型、各难度的遥感分割任务中均取得领先,尤其在细粒度场景中展现了更强的类别判别和边界细化能力,为复杂遥感任务提供了更具泛化性的新思路。
消融实验与模块贡献
为进一步探究模型各模块的作用,本文在 LoveDA、Vaihingen 和 Grass 数据集上分别移除 Modulator(调制器)、Aggregator(特征聚合器)、Interactor(交互器),观察性能变化。结果如下表所示:
| Modulator | Aggregator | Interactor | LoveDA (mIoU) | Vaihingen (mIoU) | Grass (mIoU) |
|---|---|---|---|---|---|
| × | ✓ | ✓ | 54.95 | 85.17 | 51.35 |
| ✓ | × | ✓ | 54.66 | 82.54 | 48.52 |
| ✓ | ✓ | × | 54.55 | 85.14 | 50.95 |
| ✓ | ✓ | ✓ | 55.27 | 85.27 | 51.96 |
结果分析:
- Modulator(调制器):去除后在城市场景和草地分割均有明显性能下降,显示其对输入特征自适应调制的重要性。
- Aggregator(特征聚合器):对 Grass 细粒度分割影响最大,说明多尺度特征聚合对边界复杂、异质性强的任务至关重要。
- Interactor(交互器):缺失后整体表现下降,证明多轮特征-字典交互能有效提升最终分割精度。
- 完整模型:三大模块协同作用实现了最优性能,模块设计优势得到验证。
结论:各模块均为不可或缺的关键设计,完整动态字典学习框架能够最大限度释放网络潜力,全面提升遥感图像分割的精度和鲁棒性。
读后感
整篇论文结构紧凑、论述清晰,方法创新性强。作者针对遥感图像分割中地物类别混淆、边界模糊等痛点,提出了动态字典学习框架,并将理论设计与实际需求结合得非常到位。从模块结构到消融实验,细节严谨,创新点突出。实验部分覆盖多类复杂数据集,结果全面优异,充分验证了方法的有效性和泛化能力。整体来看,这项工作不仅具备学术深度,也对实际遥感应用具有很高的参考价值,是值得推荐的高水平成果。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)