数据库面试必备:SQL查询关键字的执行顺序解析
MySQL面试题 - SQL中 select、from、join、where、group by、having、order by、limit 的执行顺序是什么?
回答重点
引言
在编写SQL查询时,了解各个关键字的执行顺序对于编写高效、正确的查询语句至关重要。许多SQL初学者往往按照查询语句的书写顺序来理解执行顺序,这可能导致对查询逻辑的误解。本文将详细解析SELECT、FROM、JOIN、WHERE、GROUP BY、HAVING、ORDER BY和LIMIT这些关键字的实际执行顺序,并通过流程图帮助您更好地理解。
SQL查询关键字的逻辑执行顺序
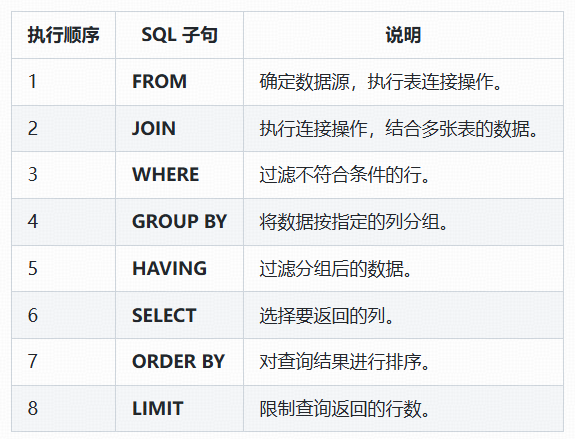
SQL查询的实际执行顺序与书写顺序并不相同。以下是它们的逻辑执行顺序:
- FROM 和 JOIN:确定数据来源表
- WHERE:过滤行数据
- GROUP BY:分组数据
- HAVING:过滤分组后的数据
- SELECT:选择要返回的列
- ORDER BY:排序结果
- LIMIT:限制返回的行数
各阶段详细解析
1. FROM 和 JOIN 阶段
这是查询处理的第一个阶段,数据库引擎首先确定要从哪些表中获取数据。
FROM table1
JOIN table2 ON table1.id = table2.table1_id
在这个阶段:
- 数据库识别所有涉及的表
- 执行表连接操作(如果有JOIN)
- 生成一个临时的虚拟表(中间结果)
2. WHERE 阶段
在确定了数据源后,WHERE子句对行进行过滤。
WHERE table1.column1 = 'value'
WHERE子句:
- 应用于FROM/JOIN生成的中间结果
- 过滤掉不满足条件的行
- 不能使用聚合函数(如COUNT, SUM等)
3. GROUP BY 阶段
如果查询包含GROUP BY子句,数据库将按照指定的列对数据进行分组。
GROUP BY table1.column2
GROUP BY:
- 将数据分成多个组
- 每组对应GROUP BY列中的唯一值组合
- 通常与聚合函数一起使用
4. HAVING 阶段
HAVING子句类似于WHERE,但它作用于分组后的数据。
HAVING COUNT(*) > 5
HAVING:
- 过滤GROUP BY产生的分组
- 可以使用聚合函数
- 只保留满足条件的分组
5. SELECT 阶段
在这一阶段,数据库确定最终结果集中包含哪些列。
SELECT column1, COUNT(*) as count
SELECT:
- 选择要返回的列
- 可以应用聚合函数
- 可以使用列别名
- 可以包含计算表达式
6. ORDER BY 阶段
ORDER BY对最终结果进行排序。
ORDER BY count DESC
ORDER BY:
- 对SELECT阶段的结果进行排序
- 可以使用列别名
- 可以指定升序(ASC)或降序(DESC)
7. LIMIT 阶段
最后,LIMIT限制返回的行数。
LIMIT 10
LIMIT:
- 限制结果集的大小
- 通常用于分页
- 在排序后应用
实际示例分析
让我们通过一个完整的查询示例来说明执行顺序:
SELECT
department,
COUNT(*) as employee_count,
AVG(salary) as avg_salary
FROM
employees
JOIN
departments ON employees.dept_id = departments.id
WHERE
hire_date > '2020-01-01'
GROUP BY
department
HAVING
COUNT(*) > 5
ORDER BY
avg_salary DESC
LIMIT 3;
执行顺序流程图:
flowchart TD
A[FROM employees JOIN departments] --> B[WHERE hire_date > '2020-01-01']
B --> C[GROUP BY department]
C --> D[HAVING COUNT(*) > 5]
D --> E[SELECT department, COUNT(*), AVG(salary)]
E --> F[ORDER BY avg_salary DESC]
F --> G[LIMIT 3]
- 首先从employees表和departments表获取数据并连接
- 然后过滤出2020年1月1日之后入职的员工
- 按部门分组
- 过滤出员工数大于5的部门
- 选择部门名称、员工数和平均工资
- 按平均工资降序排列
- 最后只返回前3条记录
常见误区与注意事项
-
WHERE vs HAVING:
- WHERE在分组前过滤行
- HAVING在分组后过滤组
- 错误地在WHERE中使用聚合函数是常见错误
-
SELECT中的别名使用:
- 在WHERE和GROUP BY中不能使用SELECT中定义的别名
- 在ORDER BY中可以使用SELECT中定义的别名
-
执行顺序影响性能:
- 尽早过滤数据(WHERE)可以提高查询效率
- 不必要的GROUP BY会增加处理负担
-
不同数据库的实现差异:
- 虽然逻辑顺序相同,但不同数据库可能有不同的优化策略
- 某些数据库可能重写查询以提高性能
总结
理解SQL查询关键字的执行顺序对于编写高效、正确的查询至关重要。记住这个顺序:FROM/JOIN → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT。这种理解可以帮助您:
- 更有效地优化查询性能
- 避免常见的逻辑错误
- 更好地理解复杂查询的执行过程
- 编写更清晰、更高效的SQL代码
通过本文的流程图和详细解释,希望您对SQL查询的执行顺序有了更清晰的认识,能够在实际工作中更好地应用这些知识。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 24
24 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)