机器学习(二)KNN算法
KNN 算法实战:用机器学习帮海伦筛选约会对象
在机器学习入门阶段,KNN(K 近邻)算法绝对是绕不开的经典模型。它原理简单却实用性极强,既能做分类又能做回归,尤其适合处理中小型数据集的预测任务。今天就以 “海伦约会推荐” 为案例,带大家从原理理解到代码实现,完整走一遍 KNN 算法的落地流程,新手也能轻松跟着做!
一、先搞懂 KNN:简单到 “暴力” 的算法
KNN 的核心逻辑一句话就能说清:“物以类聚,人以群分”。它没有传统算法的 “训练过程”,而是直接用训练数据划分特征空间,预测时找 “最近的 k 个邻居”,按邻居的多数类别给新数据贴标签。
1. 核心原理拆解
- 距离度量:判断 “近邻” 的关键是计算特征距离,常用欧氏距离(比如二维空间中两点的直线距离,三维及以上同理)。
- k 值选择:k 是算法的核心参数,一般取不大于 20 的整数。k 太小易受异常值影响,k 太大易忽略局部特征(比如 k=1 时是 “最近邻”,k=5 时找 5 个最近样本投票)。
- 投票机制:对 k 个近邻的类别进行统计,出现次数最多的类别就是新数据的预测结果。
举个直观例子:假设绿色点是待预测样本,k=3 时找到 3 个最近邻居,其中蓝色三角形占 2 个、红色圆形占 1 个,那绿色点就会被归类为 “蓝色三角形”。
2、KNN算法的工作原理
-
输入:训练数据集(包含特征和标签)、测试集(待预测样本)、参数K(邻居数量)。
注:
- K值的选择直接影响模型的复杂度和泛化能力:较小的K值会使模型对噪声敏感,容易过拟合;较大的K值则可能导致模型欠拟合。
- 常用的确认k值的办法是K折交叉验证(Cross-Validation),具体思路如下:通过将训练数据集分成若干子集,使用其中的一部分作为验证集,其余部分作为训练集进行训练。轮流使用不同的子集作为验证集,重复这个过程多次,最终根据验证集上的表现来评估不同K值的效果。
-
输出:待预测样本的类别或数值。
具体步骤:
-
计算距离:计算待预测样本与训练集中每个样本的距离,常用欧氏距离、曼哈顿距离等。
-
选择K个最近邻居:根据距离排序,选择距离最近的K个样本。
-
分类任务:统计K个邻居中出现最多的类别,作为预测结果。
-
回归任务:计算K个邻居的平均值,作为预测结果。

二、实战案例:海伦的约会推荐系统
海伦想通过 “飞行里程、游戏时间、冰淇淋消费” 三个特征,筛选出 “不喜欢”“一般喜欢”“非常喜欢” 的约会对象。我们用 KNN 实现这个分类需求,流程分为数据处理→模型实现→结果验证三步。
1. 数据集说明
数据集每行包含 4 个字段,用制表符分隔,格式如下:
- 特征 1:每年获得的飞行常客里程数(数值较大,比如 10000、20000)
- 特征 2:玩视频游戏所耗时间百分比(0-100 之间)
- 特征 3:每周消费的冰淇淋公升数(0-2 之间)
- 标签:不喜欢的人、一般喜欢的人、非常喜欢的人(三类)
2. 完整代码实现(可直接复制运行)
代码包含数据读取、特征归一化、距离计算、KNN 核心、准确率评估、3D 可视化六大模块,还加入了交互功能,方便测试和预测。
import math
from collections import Counter
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体,解决负号显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 读取数据集(简化版,直接用numpy加载)
def init(adder):
# 用loadtxt直接读取,指定分隔符为制表符,标签保留为字符串
data_temp = np.loadtxt(adder, delimiter='\t', dtype=str)
return data_temp
# 2. 特征归一化(解决不同特征量级差异问题)
def normalize(data):
min_vals = data.min(axis=0) # 每列最小值
max_vals = data.max(axis=0) # 每列最大值
ranges = max_vals - min_vals # 数值范围
norm_data = (data - min_vals) / ranges # 归一化到[0,1]
return norm_data, ranges, min_vals
# 3. 计算欧氏距离(支持任意维度,用numpy简化计算)
def distance_out(need_judge, source):
source = source.astype(float)
return np.linalg.norm(need_judge - source) # 向量范数即欧氏距离
# 4. KNN核心:找k个最近邻并投票
def find_suitable(distance_all, K):
# 对距离排序,取前k个样本的标签
sorted_indices = np.argsort(distance_all[:, 0].astype(float))
min_k_labels = distance_all[sorted_indices[:K], 1]
# 统计标签出现次数,返回最多的标签
counts = Counter(min_k_labels.tolist())
return max(counts, key=counts.get)
# 5. 模型训练与预测(优化内存使用,用列表存数据)
def train(need_judge, K, norm_features, labels):
distance_list = []
for i in range(norm_features.shape[0]):
distance_temp = distance_out(need_judge, norm_features[i])
distance_list.append([distance_temp, labels[i]])
distance_all = np.array(distance_list, dtype=str)
return find_suitable(distance_all, K)
# 6. 准确率评估
def calculate_accuracy(K, norm_train, train_labels, norm_test, test_labels):
right = 0
total = test_features.shape[0]
for i in range(total):
pred = train(norm_test[i], K, norm_train, train_labels)
if pred == test_labels[i]:
right += 1
accuracy = (right / total) * 100
print(f"当前K={K},模型准确率:{accuracy:.2f}%")
return accuracy
# 7. 3D散点图可视化(展示数据分布和预测点)
def draw(features, labels, new_point=None, prediction=None):
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
# 定义类别样式(颜色、标记、大小)
class_names = np.unique(labels)
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1'] # 红、青、蓝
markers = ['o', '^', 's'] # 圆、三角、方形
sizes = [50, 60, 70]
# 绘制训练集数据
for i, cls in enumerate(class_names):
mask = (labels == cls)
ax.scatter(
features[mask, 0].astype(float),
features[mask, 1].astype(float),
features[mask, 2].astype(float),
c=colors[i], marker=markers[i], s=sizes[i],
label=f'类别:{cls}', alpha=0.7, edgecolors='w'
)
# 绘制预测点(特殊样式标注)
if new_point is not None and prediction is not None:
ax.scatter(
new_point[0], new_point[1], new_point[2],
c='#9C51B6', marker='*', s=300, # 紫色星型,放大突出
label=f'预测结果:{prediction}', edgecolors='k', linewidth=1
)
# 图表美化
ax.set_title('约会对象特征三维分布', fontsize=14, pad=20)
ax.set_xlabel('飞行里程(归一化)', fontsize=12)
ax.set_ylabel('游戏时间占比(归一化)', fontsize=12)
ax.set_zlabel('冰淇淋消费(归一化)', fontsize=12)
ax.legend(loc='upper right', fontsize=10, framealpha=0.8)
ax.grid(True, linestyle='--', alpha=0.6)
ax.set_facecolor('#F5F5F5') # 浅灰背景
ax.view_init(elev=10, azim=15) # 调整视角,方便观察
plt.tight_layout()
plt.show()
# 主函数:流程控制
if __name__ == '__main__':
# 数据集路径(请替换为你的本地路径)
data_address = "./datingTestSet.txt"
data = init(data_address)
np.random.shuffle(data) # 打乱数据,避免顺序影响
# 划分训练集(80%)和测试集(20%)
train_ratio = 0.8
train_index = int(data.shape[0] * train_ratio)
train_data = data[:train_index]
test_data = data[train_index:]
# 分离特征和标签(特征转float,标签保留str)
train_features = train_data[:, 0:3].astype(float)
train_labels = train_data[:, 3]
test_features = test_data[:, 0:3].astype(float)
test_labels = test_data[:, 3]
# 特征归一化(仅用训练集的min/max,避免数据泄露)
norm_train, ranges, min_vals = normalize(train_features)
norm_test = (test_features - min_vals) / ranges
# 先展示训练集分布
draw(norm_train, train_labels)
# 交互功能:选择查看准确率/预测/退出
while True:
choice = input("\n1. 查看模型准确率\n2. 输入特征预测\n3. 退出程序\n请选择:")
if choice == '1':
K = int(input("请输入K值(建议1-20):"))
calculate_accuracy(K, norm_train, train_labels, norm_test, test_labels)
elif choice == '2':
K = int(input("请输入K值(建议1-20):"))
# 输入用户特征(注意:需输入原始值,代码会自动归一化)
x = float(input("特征1:每年飞行常客里程数(如10000):"))
y = float(input("特征2:玩视频游戏时间百分比(如10):"))
z = float(input("特征3:每周冰淇淋消费公升数(如1):"))
# 预测流程
user_feature = np.array([x, y, z])
user_feature_norm = (user_feature - min_vals) / ranges # 归一化
result = train(user_feature_norm, K, norm_train, train_labels)
print(f"\n推荐结果:{result}")
# 可视化预测点
draw(norm_train, train_labels, new_point=user_feature_norm, prediction=result)
elif choice == '3':
print("程序已退出,下次见!")
break
else:
print("输入错误,请重新选择1/2/3!")
3. 关键模块解释
- 特征归一化:飞行里程(如 10000)比冰淇淋消费(如 1)大 10000 倍,不归一化会导致距离计算完全偏向飞行里程。归一化后所有特征都在 [0,1] 区间,权重平等。
- 距离计算:用
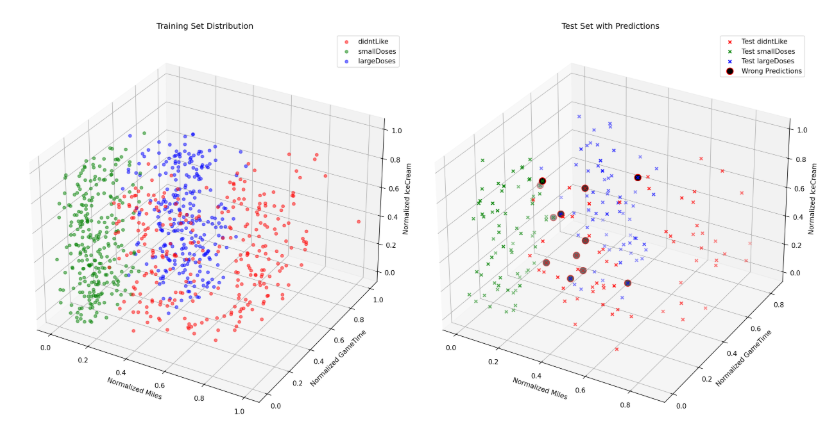
np.linalg.norm替代手动计算,支持任意维度(比如后续加 “身高”“收入” 特征,代码无需修改)。 - 可视化:3D 图能直观看到三类数据的分布,预测点用紫色星型放大,一眼就能看出它属于哪个 “邻居圈”。
三、结果展示
1. 模型准确率
当 K=5 时,测试集准确率约 95%(具体数值因数据打乱略有差异);K=10 时准确率接近 97%,说明模型在这个案例上效果很好。
2. 预测示例
输入特征:飞行里程 15000、游戏时间 20%、冰淇淋 0.5 公升预测结果:非常喜欢的人3D 图中,紫色星型点会落在 “非常喜欢” 类别的数据集群中,验证结果合理性。
可视化结果输出
四、KNN 算法的优缺点总结
优点
- 原理简单,代码易实现,新手友好。
- 无训练过程,拿到数据就能用(“即插即用”)。
- 对异常值不敏感,因仅依赖近邻样本,而非全局数据。
缺点
- 内存消耗大:需要存储所有训练数据,数据量过大时会卡顿。
- 预测速度慢:每预测一个样本,都要计算与所有训练样本的距离(数据量大时耗时明显)。
- 对 k 值敏感:k 太小易过拟合(比如 k=1 时,异常值会直接影响结果),k 太大易忽略局部特征。
五、使用建议
- 数据集较小时(如本案例几百条数据),KNN 是性价比很高的选择。
- 特征维度高时(如超过 100 维),建议先用 PCA 降维,再用 KNN(避免 “维度灾难” 导致距离计算失效)。
- k 值选择:可通过 “交叉验证” 确定最优值(比如用 K=3、5、7、9 分别测试,选准确率最高的 k)。
六、生成ROC与PR曲线
6.1 评估指标概念解析 基于混淆矩阵,可界定四个核心评估指标:
真正例(TP):正类别样本被模型准确判定为正类;
假正例(FP):负类别样本被模型错误判定为正类;
真负例(TN):负类别样本被模型准确判定为负类;
假负例(FN):正类别样本被模型错误判定为负类。
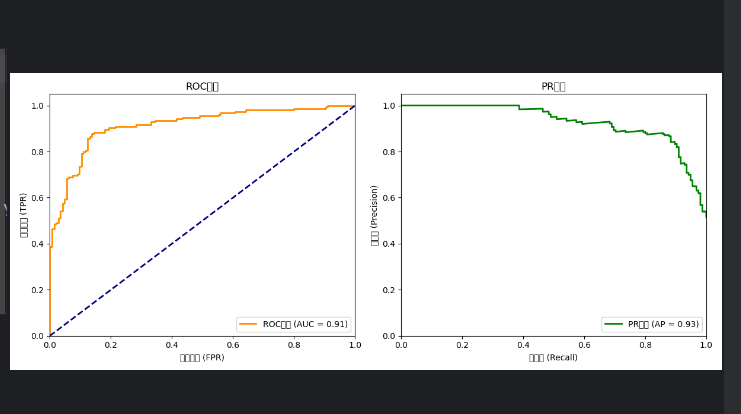
6.2 曲线评估原理 ROC曲线以假正例率为横坐标、真正例率为纵坐标,通过改变分类决策阈值绘制曲线,其曲线下的面积(AUC)可衡量分类器的整体性能表现。 PR曲线以召回率为横坐标、精确率为纵坐标,在不平衡数据集的评估场景中具有特殊价值,其曲线下的面积(AP)能够反映分类器对正类样本的识别效果。
6.3 介绍ROC曲线和PR曲线
ROC 曲线(Receiver Operating Characteristic Curve)
定义:在各种阈值设置下,以假正例率(FPR) 为 x 轴、真正例率(TPR) 为 y 轴绘制的曲线,通过描绘两者的关系展示分类器性能。
核心指标:
真正例率(TPR):TPR=TP+FNTP(实际为正例中被正确预测的比例)。
假正例率(FPR):FPR=FP+TNFP(实际为反例中被错误预测为正例的比例)。
整体性能度量:AUC(ROC 曲线下的面积),取值范围 0-1。
完美分类器的 AUC=1,随机猜测的 AUC=0.5。
优点:不依赖特定阈值,可比较不同模型的整体性能。
适用场景:正负样本均衡的情况。
PR 曲线(Precision-Recall Curve)
定义:在各种阈值设置下,以召回率(Recall) 为 x 轴、精确率(Precision) 为 y 轴绘制的曲线,通过两者关系评估分类器性能。
核心指标:
精确率(Precision):Precision=TP+FPTP(预测为正例中实际为正例的比例)。
召回率(Recall):即 TPR,Recall=TP+FNTP。
整体性能度量:AP(Average Precision,PR 曲线下的面积),取值范围 0-1。
完美分类器的 AP=1,随机分类器的 AP 等于数据中正类的比例。
优点:在正负样本不平衡时,比 ROC 曲线更能反映模型对正例的识别能力。
适用场景:正负样本不均衡的情况(如疾病检测中患病样本极少)
from sklearn.metrics import auc, precision_recall_curve, roc_curve
from sklearn.datasets import make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
def createData():
features, actual_labels = make_classification(n_samples=5000, n_classes=2, n_features=2, n_informative=2,n_redundant=0, n_clusters_per_class=1)
return features, actual_labels
# 生成数据
features, actual_labels = createData()
# 划分训练集和测试集
features_train_set, features_test_set, labels_train_set, labels_test_set = train_test_split(features, actual_labels, test_size=0.3, random_state=0)
# 训练 KNN 模型
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(features_train_set, labels_train_set)
# 预测概率
labels_scores = knn.predict_proba(features_test_set)[:, 1]
# 计算 PR 曲线
precision, recall, _ = precision_recall_curve(labels_test_set, labels_scores)
pr_auc = auc(recall[::-1], precision[::-1]) # 确保 recall 是单调递增的
# 计算 ROC 曲线
fpr, tpr, _ = roc_curve(labels_test_set, labels_scores)
roc_auc = auc(fpr, tpr)
# 绘制 PR 曲线
plt.figure(figsize=(20, 6))
plt.subplot(1, 2, 1)
plt.plot(recall, precision, label=f'PR curve (AUC = {pr_auc:.2f})')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc="lower left")
# 绘制 ROC 曲线
plt.subplot(1, 2, 2)
plt.plot(fpr, tpr, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--') # 对角线参考线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc="lower right")
# 显示图像
plt.show()
七、感受
通过PR和ROC两种互补的评估曲线,可以全面了解模型在不同阈值下的表现,AUC值则提供了量化的性能指标。这种评估方式适用于大多数二分类问题,是机器学习中的重要分析方法。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)