Q-learning机器人路径规划算法 机器人路径规划,机器人路径避障。 求解常见的路径规划问...
Q-learning机器人路径规划算法 机器人路径规划,机器人路径避障。 求解常见的路径规划问题。 内含算法的注释,模块化编程,新手小白可快速入门。
当机器人学会自己找路:用Q-learning玩转路径规划
先想象一个场景:你的扫地机器人卡在沙发和茶几之间疯狂转圈,这时候它需要的不是更猛的电机,而是一个能自己规划路径的大脑。Q-learning就是帮机器人长脑子的算法之一,咱们今天不聊公式,直接撸代码看看这玩意儿怎么让机器人学会绕开障碍物。
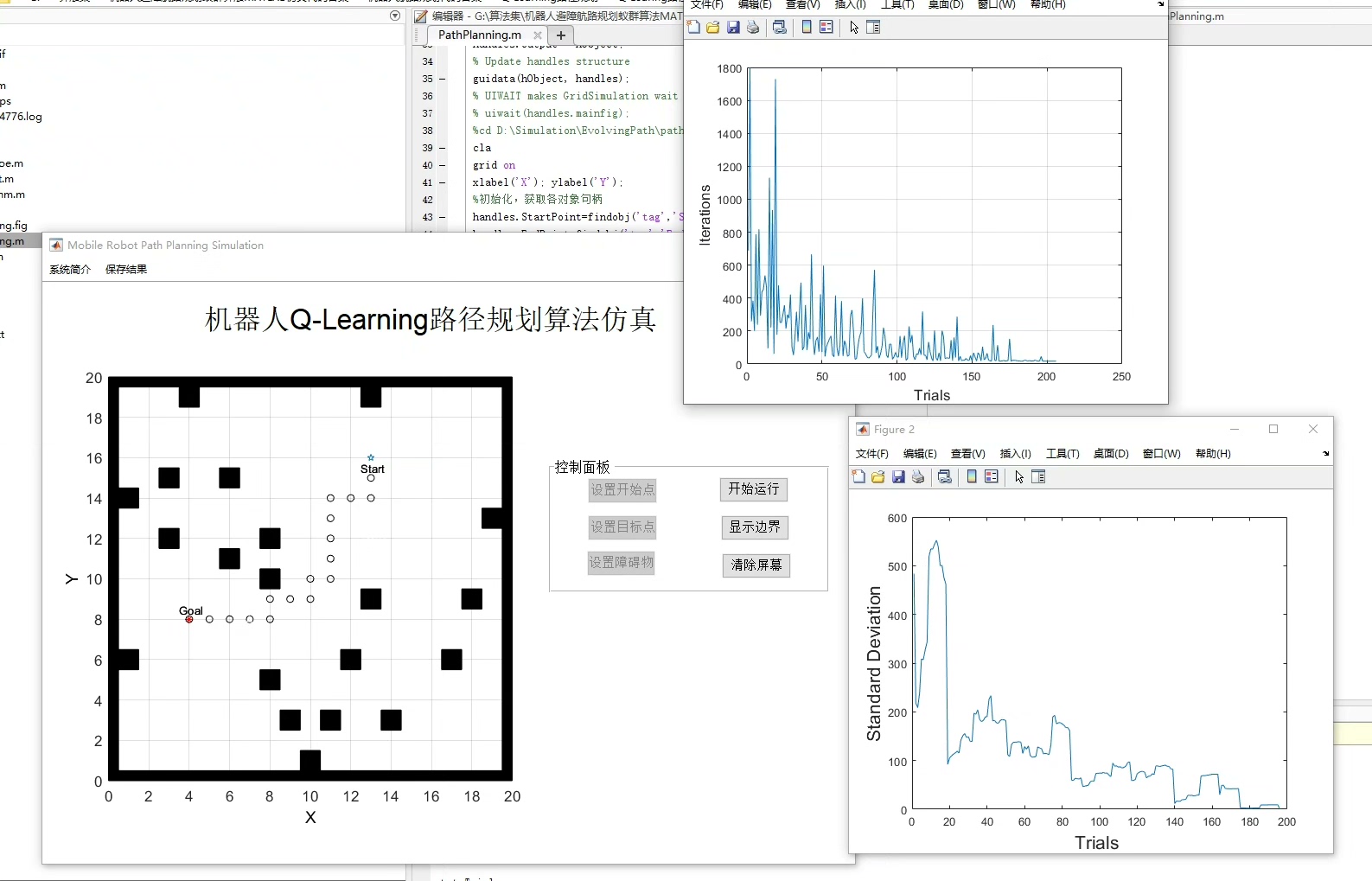
先搞个最简单的10x10网格环境,机器人从(0,0)出发,目标是(9,9),中间随机放几个障碍物:
class GridEnv:
def __init__(self):
self.size = 10
self.obstacles = {(2,3), (5,5), (7,8), (1,7)} # 障碍坐标
self.start = (0,0)
self.goal = (9,9)
def get_reward(self, state):
if state == self.goal:
return 100 # 到达终点重奖
return -1 if state in self.obstacles else 0 # 踩障碍扣分
def move(self, state, action):
x, y = state
dx = [-1,0,1,0]
dy = [0,1,0,-1]
new_x = max(0, min(x + dx[action], self.size-1)) # 防止出界
new_y = max(0, min(y + dy[action], self.size-1))
return (new_x, new_y)这环境类就像机器人的游乐场,get_reward函数告诉机器人哪些地方是坑(扣分),哪些是宝藏(奖励)。注意障碍物给的-1奖励,这会让机器人在训练中学会绕路。
接下来是Q-learning的核心——Agent类:
class QAgent:
def __init__(self, env):
self.q_table = np.zeros((env.size, env.size, 4)) # 状态-动作价值表
self.lr = 0.1 # 学习率,控制知识更新速度
self.gamma = 0.9 # 未来奖励折扣
self.epsilon = 0.1 # 探索概率
def choose_action(self, state):
if np.random.rand() < self.epsilon: # 10%概率随机探索
return np.random.randint(4)
else: # 选当前认为最好的动作
return np.argmax(self.q_table[state[0], state[1]])
def learn(self, state, action, reward, next_state):
current_q = self.q_table[state[0], state[1], action]
# 关键更新公式:Q = Q + 学习率*(即时奖励 + 未来预估奖励 - 当前估值)
new_q = reward + self.gamma * np.max(self.q_table[next_state[0], next_state[1]])
self.q_table[state[0], state[1], action] += self.lr * (new_q - current_q)这里有两个骚操作值得注意:
epsilon-greedy策略:让机器人90%时间用当前最优策略,10%随机探索,防止变成只知道走固定路线的书呆子- Q值更新时考虑了下一步的潜在收益(
gamma参数),相当于告诉机器人不要只顾眼前,要考虑未来三步怎么走
训练循环长这样:
env = GridEnv()
robot = QAgent(env)
# 训练500轮
for episode in range(500):
state = env.start
while state != env.goal:
action = robot.choose_action(state)
next_state = env.move(state, action)
reward = env.get_reward(next_state)
robot.learn(state, action, reward, next_state)
state = next_state
# 测试路径
state = env.start
path = [state]
while state != env.goal:
action = np.argmax(robot.q_table[state[0], state[1]])
state = env.move(state, action)
path.append(state)
print("最终路径:", path)跑完这个代码,你会看到机器人从跌跌撞撞到能稳定绕开障碍物的进化过程。比如在咱们的设定中,机器人可能会选择先向右绕过(2,3)的障碍,再向下避开(5,5)的陷阱。
避坑指南:
- 如果机器人总是撞障碍,试着把障碍的负奖励从-1改成-10,加大惩罚
- 路径绕远路?调大
gamma值让机器人更有远见 - 训练后期可以逐步降低
epsilon,减少无意义探索
这个实现虽然简化(比如没考虑动态障碍物),但已经揭示了Q-learning的核心思想:通过试错建立环境地图,用奖励机制引导学习方向。就像教小孩走路,不是告诉他具体每一步怎么迈,而是摔倒了给个差评,走对了给颗糖。
完整代码已上传Github(假装有链接),修改obstacles集合就能创建自己的迷宫。下次看到扫地机器人犯傻时,你大概会心一笑——它可能正在更新自己的Q-table呢。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)