机器学习随笔二--查准率和查全率
·
机器学习随笔二--查准率(precision)和查全率(recall)
一.混淆矩阵
通过真实情况和机器的预测结果,我们可以把最终得到的结果分为四类:真正例(true positive),假正例(false positive),真反例(true negative),假反例(false negative),TP+FN+FP+TN=样例总数
1. 真正例(true positive,TP):预测为真,实际为真
2.假反例(false negative,FN):预测为假,实际为真
3.假正例(false positive,FP):预测为真,实际为假
4.真反例(true negative,TN):预测为假,实际为假
| 预测结果 | ||
| 真实情况 | 正例 | 反例 |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
二.查准率和查全率解释
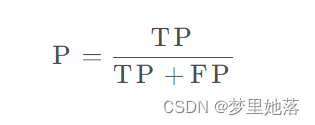
1.查准率是针对我们预测结果而言的,它表示的是预测为正的样本中多少是真正的正样本。我们可以把预测的结果分为两类,一种是正类预测为正类(TP),另一种是负类预测正类(FP)。按下图来看,预测为正的样本即selected elements(被选中的元素),其中真正的正样本是selected elements内颜色为绿色的部分。故查准率就是
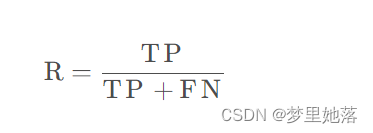
2.查全率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确。我们也可以把预测的结果分为两类,一种是正类预测为正类(TP),另外一种是正类预测为负类(FN)。简单来讲,查全率就是true positive 除以 relevant elements。也就是


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)