零基础入门数据分析!NumPy+Pandas+Matplotlib 实战全攻略(附代码 + 详解)
引言
对于想转行数据分析、零基础学 Python 的朋友来说,NumPy+Pandas+Matplotlib 就是数据分析领域的「三剑客」,也是入行必过的第一关!很多新手踩坑:要么乱学顺序,要么死记硬背函数,要么一上来就啃高阶语法,直接劝退。这篇文章严格按照数值计算→数据处理→可视化→综合实战的科学顺序,4 周搞定三剑客(每天投入 1-2 小时即可),全程无晦涩理论、全是可直接运行的代码 + 逐行详解,学完就能独立完成入门级数据分析项目!
全文框架:前置准备→NumPy(数值基石)→Pandas(核心处理,重点)→Matplotlib(可视化)→综合实战→学习总结,新手跟着走,一步不迷路!
目录
1.3 Jupyter Notebook 启动与使用(最佳实战工具)
模块 3:阶段 2 - Pandas:数据分析核心引擎(全文重点!)
2. DataFrame(二维数据:Excel 表格,核心中的核心)
模块 4:阶段 3 - Matplotlib(3-5 天):数据可视化
模块 1:前置准备:零基础必看!
1.1 数据分析刚需 Python 基础(只学这些就够)
不用啃完整本 Python!仅需掌握 4 个基础知识点,直接开冲三剑客:
- 变量定义(
a=10) - 列表 / 字典基础(
[1,2,3]/{"name":"小明"}) - 条件判断(
if/else) - 基础循环(
for循环)
1.2 三剑客 + Jupyter 一键安装
打开电脑的命令提示符(CMD),直接复制运行这行代码,一键安装所有工具:
# 安装numpy、pandas、matplotlib、jupyter notebook
pip install numpy pandas matplotlib jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple
解释:
-i是清华镜像源,解决安装慢、失败的问题,新手必加!
1.3 Jupyter Notebook 启动与使用(最佳实战工具)
- CMD 中输入命令:
jupyter notebook - 自动弹出浏览器页面,点击
New→Python3新建代码文件 - 代码写在单元格里,按
Shift+Enter运行,全程用这个工具跑代码
1.4 前置小练习(巩固基础)
# 基础练习:定义列表+循环+判断
score = [80, 90, 60, 75]
for i in score:
if i >= 80:
print(f"分数{i}:优秀")
运行结果:
分数80:优秀
分数90:优秀
模块 2:阶段 1 - NumPy:数值计算底层基石
2.1 NumPy 核心定位
通俗说:Python 自带的列表太慢,NumPy 用「数组」替代列表,专门做数值计算,是 Pandas 的底层基础,处理大数据速度提升 100 倍!
2.2 必学核心知识点 + 实战代码
1. 导入库 + 数组创建(入门第一步)
# 1. 导入numpy库,固定简写为np(行业通用规范)
import numpy as np
# 2. 从列表创建数组
arr1 = np.array([1,2,3,4])
# 3. 生成连续数值数组(左闭右开,1到9)
arr2 = np.arange(1,10)
# 4. 生成全0/全1数组(3行2列)
arr3 = np.zeros((3,2))
arr4 = np.ones((2,3))
print(arr1)
print(arr2)
print(arr3)
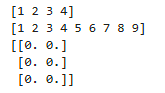
逐行解释:
import numpy as np:导入库,np 是固定简写,必须记np.array():将 Python 列表转为 NumPy 数组np.arange():生成连续数字,和range()用法一致np.zeros()/ones():生成指定形状的全 0 / 全 1 数组,括号内是 (行,列)
2. 数组属性查看(快速了解数据)
arr = np.array([[1,2,3],[4,5,6]])
# 查看数组形状(行,列)
print("形状:", arr.shape)
# 查看数组维度
print("维度:", arr.ndim)
# 查看数据类型
print("类型:", arr.dtype)

核心属性:shape(最常用,看数据行列)、ndim(维度)、dtype(数据类型)
3. 索引切片 + 条件筛选
arr = np.arange(1,10)
# 索引:取第2个元素(索引从0开始)
print(arr[1])
# 切片:取第2到第5个元素
print(arr[1:5])
# 条件筛选:取大于5的数字
print(arr[arr>5])

新手易错:索引从 0 开始,切片左闭右开!
4. 向量化运算(NumPy 核心优势)
arr = np.array([1,2,3])
# 数组整体运算,不用写循环!
print(arr + 10) # 每个元素+10
print(arr * 2) # 每个元素×2
![]()
优势:对比 Python 循环,代码更简洁、计算更快!
5. 常用统计函数
arr = np.array([1,2,3,4,5])
print("求和:", np.sum(arr))
print("均值:", np.mean(arr))
print("最大值:", np.max(arr))
print("标准差:", np.std(arr))
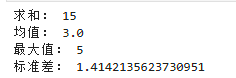
高频函数:sum(求和)、mean(均值)、max(最值)、std(标准差)
6. 随机数生成(模拟数据必备)
# 生成0-1之间的随机数组(3行3列)
arr = np.random.rand(3,3)
print(arr)
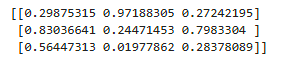
2.3 NumPy 小实战
# 实战:生成10个学生随机成绩,计算平均分
import numpy as np
score = np.random.randint(0,100,10) # 生成0-100的10个随机整数
print("学生成绩:", score)
print("平均分:", np.mean(score))
![]()
2.4 NumPy 新手避坑指南
⚠️ 避坑 1:数组和列表不能直接混合运算,必须用
np.array()转数组⚠️ 避坑 2:索引从 0 开始,切片不包含右边界⚠️ 避坑 3:二维数组索引写法是arr[行,列],不是列表的arr[行][列]
模块 3:阶段 2 - Pandas:数据分析核心引擎(全文重点!)
3.1 Pandas 核心定位
Excel 的代码版!数据分析绝对主角,专门处理表格数据(CSV/Excel),数据清洗、分组统计、筛选查询全靠它,占实战工作 80% 的工作量!
3.2 核心数据结构(必学)
1. Series(一维数据:带索引的列表)
import pandas as pd
# 创建Series:索引+数值
s = pd.Series([80,90,70], index=["小明","小红","小刚"])
print(s)
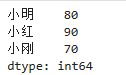
解释:一维表格,左边是索引,右边是数值。
2. DataFrame(二维数据:Excel 表格,核心中的核心)
# 创建DataFrame(标准表格)
data = {
"姓名": ["小明","小红","小刚"],
"语文": [80,90,70],
"数学": [95,85,90]
}
df = pd.DataFrame(data)
print(df)
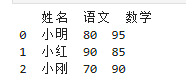
解释:行 = 样本,列 = 字段,和 Excel 表格完全一致,Pandas 所有操作都围绕 DataFrame!
3.3 Pandas 必学实战技能(逐行详解)
1. 数据读写(读取 / 导出 Excel/CSV)
import pandas as pd
# 读取CSV文件(Excel用pd.read_excel())
# df = pd.read_csv("数据.csv")
# 导出文件
# df.to_csv("导出数据.csv", index=False) # index=False:不导出索引列
# 演示用:创建模拟数据
df = pd.DataFrame({
"商品": ["手机","电脑","平板"],
"销量": [100,80,120],
"价格": [3000,5000,2000]
})
核心函数:pd.read_csv()(读文件)、df.to_csv()(写文件)
2. 数据探查(快速看懂数据)
# 查看前5行数据(最常用)
print(df.head())
# 查看数据基本信息(列名、数据类型、缺失值)
print(df.info())
# 查看数值列统计信息(均值、最值、数量)
print(df.describe())
# 查看数据行列数
print("行列数:", df.shape)
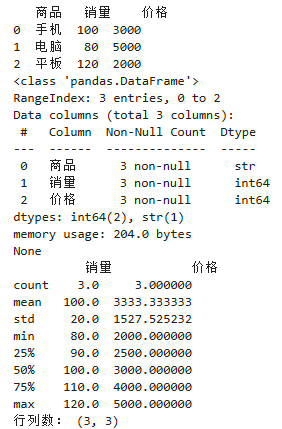
实战作用:拿到数据第一步,先探查数据结构、缺失值、异常值!
3. 数据清洗(高频核心!)
# 模拟带缺失值、重复值的数据
df = pd.DataFrame({
"姓名": ["小明","小红","小明","小刚"],
"成绩": [80,None,80,90]
})
# 1. 处理缺失值:删除/填充
df = df.dropna() # 删除缺失值
# df = df.fillna(0) # 缺失值填充为0
# 2. 删除重复值
df = df.drop_duplicates()
# 3. 数据类型转换
df["成绩"] = df["成绩"].astype(int)
print(df)

核心操作:dropna()(删缺失值)、fillna()(填缺失值)、drop_duplicates()(删重复值)
4. 数据筛选与排序
# 条件筛选:销量大于100的商品
df = pd.DataFrame({"商品":["手机","电脑","平板"],"销量":[100,80,120]})
res = df[df["销量"] > 100]
# 排序:按销量降序排序(ascending=False=降序)
res = df.sort_values(by="销量", ascending=False)
print(res)

5. 分组聚合(数据分析灵魂!)
# 模拟数据:按班级分组统计平均分
df = pd.DataFrame({
"班级": ["一班","一班","二班","二班"],
"成绩": [80,90,70,85]
})
# 分组+求均值
res = df.groupby("班级")["成绩"].mean()
print(res)
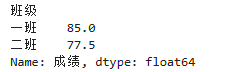
核心公式:df.groupby(分组列)[统计列].聚合函数()聚合函数:mean(均值)、sum(求和)、count(计数)、max(最值)
6. 数据合并(简单拼接)
# 两个表格上下拼接
df1 = pd.DataFrame({"姓名":["小明","小红"]})
df2 = pd.DataFrame({"姓名":["小刚","小丽"]})
df = pd.concat([df1,df2], ignore_index=True)
print(df)

3.4 Pandas 专项实战(完整流程)
# 实战:学生成绩分析(读取→清洗→统计)
import pandas as pd
# 1. 创建数据
df = pd.DataFrame({
"姓名": ["小明","小红","小刚","小明"],
"语文": [80,90,None,80],
"数学": [95,85,90,95]
})
# 2. 数据清洗
df = df.drop_duplicates() # 去重
df = df.fillna(df["语文"].mean()) # 缺失值填充为语文平均分
# 3. 统计分析:计算总分
df["总分"] = df["语文"] + df["数学"]
# 4. 结果输出
print("清洗后数据:")
print(df)
print("\n总分排名:")
print(df.sort_values("总分", ascending=False))
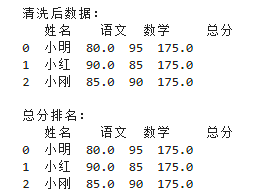
3.5 Pandas 新手避坑指南
⚠️ 避坑 1:列名必须加引号,
df["成绩"]不能写成df[成绩]⚠️ 避坑 2:groupby后必须指定统计列,否则会报错⚠️ 避坑 3:导出文件必须加index=False,否则会多一列无用索引⚠️ 避坑 4:缺失值会导致统计报错,优先清洗缺失值再分析
模块 4:阶段 3 - Matplotlib(3-5 天):数据可视化
4.1 Matplotlib 核心作用
把枯燥的数字变成直观图表,让分析结果一目了然,入门只学 5 种基础图表就够用!
4.2 固定绘图模板(新手直接套用)
# 导入库,固定简写
import matplotlib.pyplot as plt
# 解决中文乱码(必加!)
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
4.3 5 种入门必绘图表
1. 折线图(展示趋势)
x = [1,2,3,4]
y = [10,20,15,25]
plt.plot(x,y, color="red", linewidth=2)
plt.title("月度销量趋势")
plt.xlabel("月份")
plt.ylabel("销量")
plt.show()
2. 柱状图(分类对比)
x = ["一班","二班","三班"]
y = [85,90,88]
plt.bar(x,y, color="blue")
plt.title("班级平均分对比")
plt.show()
3. 直方图(数据分布)
data = [80,85,90,95,80,85,90]
plt.hist(data, bins=5)
plt.title("成绩分布")
plt.show()
4. 散点图(变量关系)
x = [1,2,3,4,5]
y = [10,20,30,40,50]
plt.scatter(x,y)
plt.title("学习时长与成绩关系")
plt.show()
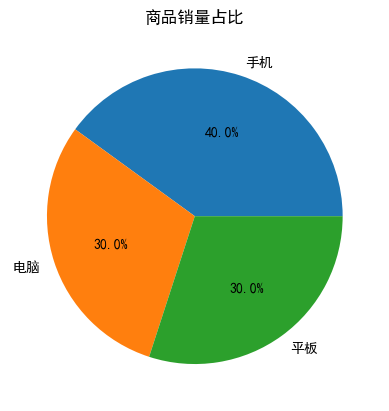
5. 饼图(占比分析)
labels = ["手机","电脑","平板"]
sizes = [40,30,30]
plt.pie(sizes, labels=labels, autopct="%1.1f%%")
plt.title("商品销量占比")
plt.show()
4.4 图表美化(基础操作)
plt.title():加标题plt.xlabel/ylabel():加坐标轴名称plt.legend():加图例plt.color:修改颜色
4.5 Matplotlib 新手避坑指南
⚠️ 避坑 1:不写中文配置代码,图表中文会乱码⚠️ 避坑 2:绘图最后必须加
plt.show(),否则不显示图表⚠️ 避坑 3:数据维度必须对应,否则报错
模块 5:阶段 4 - 综合实战项目:电商销售数据分析
三剑客联动!完整流程:生成数据→清洗分析→可视化,新手跟着敲就能跑通!
# ===================== 1. 导入三剑客 =====================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 解决中文乱码
plt.rcParams["font.sans-serif"] = ["SimHei"]
# ===================== 2. NumPy生成模拟数据 =====================
# 生成30条销售数据:商品、销量、销售额
goods = ["手机","电脑","平板","耳机"]
sale_num = np.random.randint(50,200,30) # 销量50-200
sale_amount = sale_num * np.random.choice([3000,5000,2000,100],30) # 销售额
# ===================== 3. Pandas数据处理 =====================
# 创建DataFrame
df = pd.DataFrame({
"商品": np.random.choice(goods,30),
"销量": sale_num,
"销售额": sale_amount
})
# 数据清洗:去重+缺失值处理
df = df.drop_duplicates()
# 统计:按商品分组统计总销量、总销售额
result = df.groupby("商品").agg({
"销量": "sum",
"销售额": "sum"
}).reset_index()
print("销售统计结果:")
print(result)
# ===================== 4. Matplotlib可视化 =====================
# 柱状图:商品销量对比
plt.figure(figsize=(8,5))
plt.bar(result["商品"], result["销量"], color=["red","blue","green","orange"])
plt.title("电商商品销量对比")
plt.xlabel("商品类型")
plt.ylabel("总销量")
plt.show()
# 饼图:销售额占比
plt.figure(figsize=(6,6))
plt.pie(result["销售额"], labels=result["商品"], autopct="%1.1f%%")
plt.title("商品销售额占比")
plt.show()
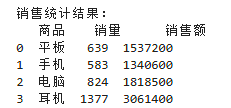
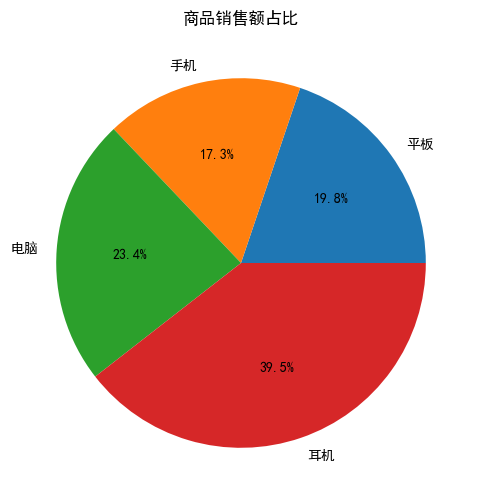
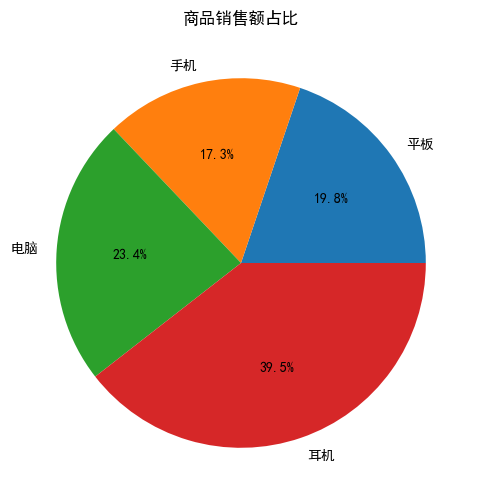
实战结论:
- 平板 / 手机销量最高,是主力商品
- 电脑销售额占比最大,利润贡献最高
- 耳机销量偏低,可优化营销方案
模块 6:必备学习资源 + 避坑总结
6.1 免费优质学习资源
- 官方文档:NumPy/Pandas/Matplotlib 官网(中文翻译版)
- 练习数据集:Kaggle 入门数据集、阿里云天池
- 工具:Jupyter Notebook(全程实战)
6.2 全文核心学习总结
- 学习顺序:NumPy→Pandas→Matplotlib,不可逆
- 权重分配:Pandas 占 60% 精力,重点练数据清洗、分组聚合
- 学习节奏:4 周,每天 1-2 小时,边敲代码边学
6.3 新手通用避坑指南
⚠️ 不要死记函数:用到再查,多练自然记住⚠️ 不要跳过数据清洗:80% 的报错都来自脏数据⚠️ 不要只看不动手:代码必须亲手敲一遍,才能学会⚠️ 不要贪多:入门只学刚需内容,高阶语法后期再学
结语 + 进阶方向
恭喜你!学完这篇文章,你已经掌握了数据分析三剑客的入门核心技能,能独立完成数据读取、清洗、统计、可视化全流程!
入门标准:能独立完成本文的电商 / 成绩分析项目进阶路线:
- 可视化进阶:Seaborn(更美观的图表)
- 进阶分析:Scikit-learn(机器学习入门)
- 实战提升:Kaggle 入门竞赛、企业真实数据集
数据分析没有捷径,多动手、多实战就是最快的路!加油,新手们!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)