Linux 数据库开发 学习笔记
数据库介绍
什么是数据库?
数据库是结构化数据集合,支持高效存储、管理和检索,可以持久存储数据,提供安全、可靠、高效的数据访问机制
为什么需要数据库?
•数据持久化:程序重启后数据不丢失
•数据共享:多用户/应用可并发访问
•数据一致性:通过事务机制(ACID)保证数据完整性
•高效查询:通过索引、优化器加速数据检索
数据库的发展

数据库分类
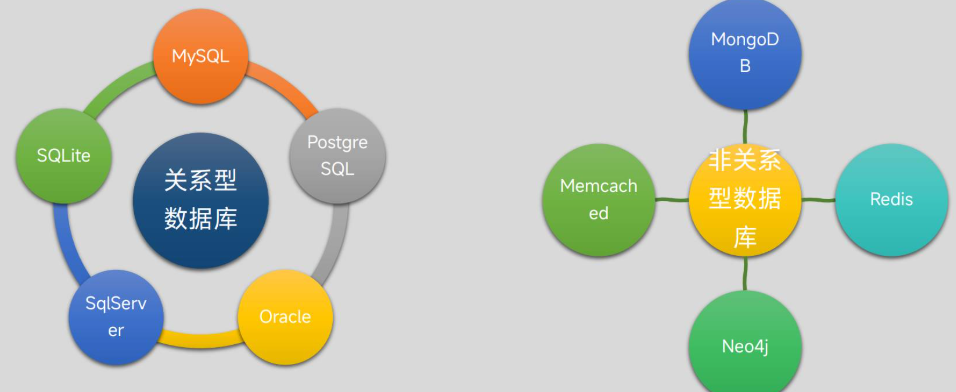
主流关系型数据库对比
| 数据库 | 优势 | 缺点 | |
|---|---|---|---|
| 关系型 | MySQL | • 开源免费,社区活跃 • 高并发读写优化(OLTP场景) • 易部署,轻量级 |
• 复杂查询性能较弱(如多表JOIN) • 功能扩展性有限(相比PostgreSQL) |
| PostgreSQL | • 功能全面(支持JSON、GIS、全文检索等) • 高度可扩展(自定义数据类型、函数) • ACID兼容性强 |
• 默认配置下高并发性能略逊于MySQL • 内存消耗较高 |
|
| Oracle | • 企业级性能(高可用、分布式优化) • 强大的事务处理与锁机制 • 完善的商业支持与工具链 |
• 高昂成本(商业授权) • 学习曲线陡峭,管理复杂 |
|
| SQL Server | • 与Windows生态深度集成(.NET、Azure) • 图形化管理工具(SSMS)易用 • 内置BI工具(SSAS、SSRS) |
• 仅支持Windows/Linux(有限跨平台) • 社区版功能受限 |
|
| SQLite | • 零配置,嵌入式数据库(单文件) • 轻量级(库文件仅数MB) • 无服务端,适合本地存储 |
• 不支持高并发(写锁全局) • 无用户权限管理 • 数据量不宜过大,SQL执行效率相对较低 |
|
| 非关系型 | MongoDB(文档型) | • 灵活模式(JSON文档结构) • 水平扩展(分片集群) • 丰富的查询语言(类SQL语法) • 支持多文档事务(4.0+) |
• 内存消耗较高 • 复杂关联查询性能弱于关系型数据库 |
| Redis(键值型) | • 内存存储,超高性能(10万+ QPS) • 支持多种数据结构(字符串、哈希、列表等) • 持久化(RDB/AOF)与高可用(哨兵/集群) |
• 数据规模受内存限制 • 无复杂查询能力(仅键查询) • 高并发写入可能丢数据(异步持久化) |
|
| Neo4j(图数据库) | • 高效处理复杂关系(原生图存储) • 强大的图查询语言(Cypher) • ACID事务支持 |
• 扩展性受限(社区版单机) • 存储非图数据效率低 |
数据库安装
软件在线安装sudo apt-get install sqlite3(软件) libsqlite3-dev(函数库)
数据库及数据表的创建
数据类型
| 存储类 | 描述 |
|---|---|
| NULL | 值是一个NULL值。 |
| INTEGER | 值是一个带符号的整数,根据值的大小存储在1、2、3、4、6或8字节中,例如:age INTEGER。 |
| REAL | 值是一个浮点值,存储为8字节的IEEE浮点数字,例如:gpa REAL。 |
| TEXT | 值是一个文本字符串,使用数据库编码(UTF-8、UTF-16BE或UTF-16LE)存储,例如:student_name TEXT。 |
| BLOB | 用于存储二进制数据,如图像、音频片段等。比如,如果要存储用户上传的图片的二进制数据,可以定义一个image_data BLOB列。 |
数据库及数据表的创建
使用CREATE TABLE语句创建数据表,语法如下:
CREATE TABLE [IF NOT EXISTS] table_name (
column1 data_type constraint,
column2 data_type constraint,
...
);•IF NOT EXISTS:可选参数,用于避免在表已存在时创建表而导致的错误
•table_name:要创建的表的名称•column1,column2:表中的列名
•data_type:列的数据类型,如INTEGER(整数)、TEXT(文本)、REAL(浮点数)、BLOB(二进制对象)等
•constraint:约束条件,如PRIMARYKEY(主键)、NOTNULL(非空)等。
主键设置
CREATE TABLE students (
student_id INTEGER PRIMARY KEY,
student_name TEXT NOT NULL,
age INTEGER
);CREATE TABLE course_registration (
student_id INTEGER,
course_id INTEGER,
PRIMARY KEY (student_id, course_id)
);数据操作语句
基本查询语句
SELECT
column1,
column2,
...
FROM
table_name
[WHERE condition]
[ORDER BY column [ASC|DESC]];

增\删
INSERT INTO
1. 插入所有列的数据
INSERT INTO table_name VALUES (value1, value2, ...);示例:
INSERT INTO students VALUES (1, 'Alice', 20);2. 插入指定列的数据
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);示例:
INSERT INTO students (student_id, student_name) VALUES (2, 'Bob');DELETE FROM
语法:
DELETE FROM table_name [WHERE condition];示例:
DELETE FROM students WHERE student_id = 2;改(UPDATE)
语法:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
[WHERE condition];示例:
将 students 表中 student_id 为 1 的学生的年龄更新为 21 岁。
UPDATE students SET age = 21 WHERE student_id = 1;聚合/通配符
函数聚合
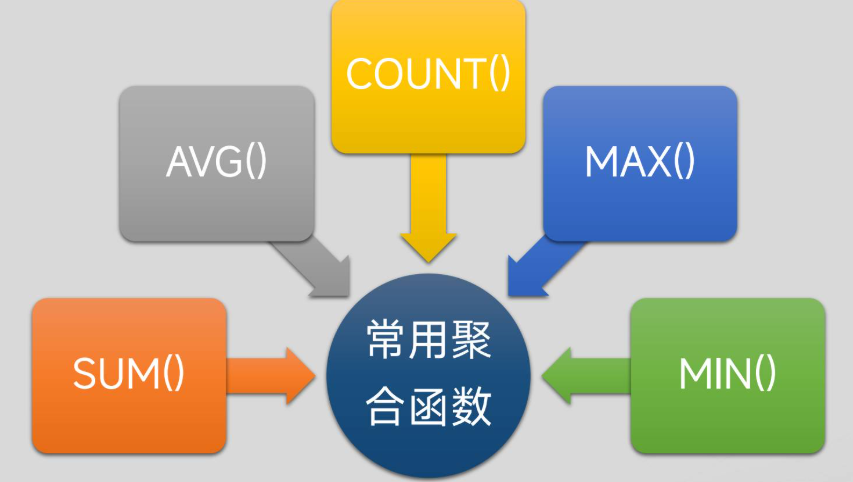
GROUPBY语句
用于按照某一列或多列对数据进行分组,并对每个组应用聚合函数
例如,假设students表中还有一个class列表示学生所在班级,要统计每个班级的学生人数:
SELECT
class,
COUNT(student_id)
FROM students
GROUP BY class;HAVING语句
用于对分组后的结果进行筛选,它的作用类似于WHERE子句,但WHERE子句用于筛选行,而HAVING子句用于筛选分组
例如,要找出学生人数大于10人的班级:
SELECT
class,
COUNT(student_id)
FROM students
GROUP BY class
HAVING COUNT(student_id) > 10;通配符
%
任意长度字符(通配符 %)
SELECT * FROM students WHERE student_name LIKE 'A%';_
下划线(_):代表单个任意字符。
SELECT * FROM students WHERE student_name LIKE '_o_';别名
列别名
语法: column_name AS alias_name
示例: 查询 students 表中学生的姓名和年龄,并给年龄列取个别名 student_age:
SELECT student_name, age AS student_age
FROM students;表别名
语法为:table_name AS alias_name
例如,在 students 表和 grades 表进行连接查询时:
SELECT s.student_name, g.score
FROM students AS s
JOIN grades AS g ON s.student_id = g.student_id;事务处理
事务
一组原子性操作的逻辑单元,确保数据库从一种一致状态转换到另一种一致状态
原子性
•事务内的操作要么全部完成,要么全部不执行(无中间状态)
一致性
•事务执行前后,数据库必须满足所有约束(如主键、外键、CHECK约束)
持久性
•事务提交后,修改永久保存到磁盘
隔离性
•并发事务之间互不干扰(默认隔离级别为SERIALIZABLE)
事务控制命令
BEGINTRANSACTION
•开始事务处理(可以简写为BEGIN)
COMMIT
•保存更改,或者可以使用END TRANSACTION命令
ROLLBACK
•回滚所做的更改
BEGIN TRANSACTION; -- ① 显式开启事务,进入“原子操作模式”
UPDATE accounts SET balance = balance - 100 WHERE user = 'Alice'; -- ② 操作1
UPDATE accounts SET balance = balance + 100 WHERE user = 'Bob'; -- ③ 操作2
COMMIT; -- ④ 提交事务,确认所有修改永久生效
-- 若任一操作失败,需手动执行 ROLLBACK; 回滚显式事务与隐式事务
隐式事务:
每条独立的SQL语句自动包裹在一个事务中,执行后立即提交(无需手动BEGIN和COMMIT)
SQLite默认行为:所有单条SQL操作(如INSERT、UPDATE、DELETE)均以隐式事务执行。
特点:操作简单,但无法保证多步骤操作的原子性
-- 隐式事务:每条语句自动提交
INSERT INTO users (name) VALUES ('Alice'); -- 自动提交
INSERT INTO users (name) VALUES ('Bob'); -- 自动提交| 特性 | 隐式事务 | 显式事务 |
|---|---|---|
| 语法 | 无需 BEGIN 和 COMMIT,直接执行单条 SQL 语句 |
需手动包裹在 BEGIN 和 COMMIT/ROLLBACK 之间 |
| 提交时机 | 语句执行后立即提交 | 手动调用 COMMIT 后批量提交 |
| 原子性保障 | 仅单条语句的原子性 | 支持多步骤操作的原子性(全成功或全回滚) |
| 适用场景 | 简单查询、单条数据修改 | 转账、订单支付等需多步骤关联操作的业务逻辑 |
| 风险 | 多步骤操作可能部分成功(数据不一致) | 失败时完全回滚,数据一致性高 |
嵌套事务
BEGIN TRANSACTION;
INSERT INTO logs (event) VALUES ('Start import'); -- 操作1
SAVEPOINT batch1; -- ① 创建保存点(类似子事务标记)
INSERT INTO data VALUES (1, 'A'); -- 操作2
INSERT INTO data VALUES (2, 'B'); -- 操作3
-- 假设发现错误需回滚到 batch1
ROLLBACK TO batch1; -- ② 回滚到保存点,撤销操作2和3
RELEASE batch1; -- ③ 释放保存点(非必须)
COMMIT; -- 最终提交:仅保留操作1经典案例:AB银行账户转账
步骤 1:开启显式事务
BEGIN TRANSACTION;步骤 2:从 Alice 账户扣款(需检查余额)
UPDATE accounts
SET balance = balance - 100
WHERE user = 'Alice' AND balance >= 100; -- 防止透支步骤 3:验证是否扣款成功
SELECT changes(); -- SQLite 函数,返回受影响行数
-- 若返回 0,说明余额不足或 Alice 账户不存在步骤 4:向 Bob 账户存款
UPDATE accounts
SET balance = balance + 100
WHERE user = 'Bob';步骤 5:根据条件提交或回滚
-- 假设应用层代码检查到 changes() > 0
COMMIT;
-- 若 changes() = 0,执行 ROLLBACK;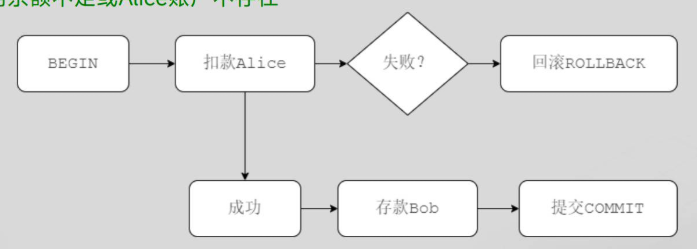
Linux中的数据库操作
数据库连接管理(open)
函数原型:
int sqlite3_open(const char *filename, sqlite3 **ppDb);
参数:
filename:数据库文件路径(若为:memory:则创建内存数据库)
ppDb:数据库句柄指针
返回值:SQLITE_OK成功,其他为错误码
作用:建立与数据库的连接:若文件不存在,自动创建空数据库;若为内存数据库,直接在内存中初始化
数据库连接管理(close)
函数原型:
int sqlite3_close(sqlite3 *db);
参数:
db:通过sqlite3_open获取的数据库句柄。必须为有效的非空指针,否则函数行为未定义
返回值:SQLITE_OK(0)表示成功,SQLITE_ERROR(1)表示失败
作用:关闭数据库连接,释放内部缓存和锁机制。若有未完成的事务,会自动回滚
SQL语句执行(exec)
函数原型:
int sqlite3_exec(sqlite3 *db,const char *sql,int (*callback)(void*,int,char**,char**), void *userdata,char **errmsg);
参数:
db:数据库句柄
sql:SQL语句字符串
callback:回调函数(查询时触发)
userdata:传递给回调的用户数据
errmsg:错误信息指针
返回值:SQLITE_OK(0)表示成功,SQLITE_ERROR(1)表示失败
作用:执行SQL语句
查询接口(int callback)
函数原型:
int callback(void *userdata, int argc, char **argv, char **colNames);
参数:
argc:每行结果的列数
argv:指向当前行数据的字符串数组,每个元素对应一列的值。若列为NULL,则argv[i]为NULL
colNames:指向列名的字符串数组,与argv中的列一一对应(如colNames[0]为第一列的列名)
返回值:返回0继续,非0终止执行
作用:自定义处理查询结果的逻辑(如打印、存储数据)
非回调查询(get_table)
函数原型:
int sqlite3_get_table(sqlite3*db,constchar *sql,char ***resultp,int*nrow,int*ncolumn,char **errmsg);
参数:
db:数据库句柄
sql:SQL语句字符串
resultp:指向二维数组的指针(输出参数)。查询结果存储为resultp[0](列名数组)、resultp[1..nrow](行数据),所有字符串需调用sqlite3_free_table释放
nrow:指向整数的指针(输出参数),存储查询结果的行数(不包含列名行)
ncolumn:指向整数的指针(输出参数),存储查询结果的列数(包含列名)
errmsg:存储错误
返回值:SQLITE_OK(0)表示成功,错误码表示失败
作用:非回调查询:将结果一次性存储到内存中,适用于结果集较小的场景(需手动释放内存)
预处理语句(prepare)
函数原型:
int sqlite3_prepare( sqlite3 *db,const char *zSql,intnByte,sqlite3_stmt **ppStmt,,const char **pzTail);
参数:
db:数据库句柄
zSql:SQL语句字符串
nByte:zSql的最大长度(字节数)。若为-1,则自动计算到\0为止
ppStmt:指向sqlite3_stmt类型指针的指针(输出参数),接收预处理语句句柄
pzTail:指向zSql中未被解析部分的指针(输出参数)。若zSql包含多条语句,*pzTail指向第一条语句之后的内容(常用于分批次执行)
返回值:SQLITE_OK(0)表示成功,错误码表示失败
作用:预编译SQL语句
绑定参数(bind)
函数原型:
int sqlite3_bind_int(sqlite3_stmt *stmt, int idx, int value);
int sqlite3_bind_text(sqlite3_stmt *stmt, int idx, const char *value, int len, void(*free)(void*));
参数:
stmt:预处理语句句柄
idx:占位符位置(从1开始)
value:绑定到占位符的值
len:文本/Blob长度(-1表示自动计算)
free:释放value的回调函数
返回值:SQLITE_OK(0)表示成功,错误码表示失败
作用:为预处理语句中的文本类型占位符赋值,支持自定义内存管理
执行预处理语句(step)
函数原型:
int sqlite3_step(sqlite3_stmt *stmt);
参数:
stmt:预处理语句句柄
返回值:SQLITE_ROW(100):成功获取下一行结果(用于查询),SQLITE_DONE(101):语句执行完成(无更多结果,或非查询语句),其他值:错误码
作用:执行预处理语句
执行预处理语句(finalize)
函数原型:
int sqlite3_finalize(sqlite3_stmt *stmt);
参数:
stmt:预处理语句句柄(需确保已通过sqlite3_step执行完毕)
返回值:SQLITE_OK(0)表示成功,错误码表示失败
作用:释放预处理语句占用的内存和句柄,必须在不再使用stmt时调用
预处理语句(Prepared Statement)
sqlite3_prepare_v2()– 编译 SQL 语句为预处理对象
sqlite3_step()– 执行预处理语句(单步)
sqlite3_reset()– 重置语句,准备重新执行
sqlite3_finalize()– 销毁预处理对象,释放资源
sqlite3_bind_*()– 绑定参数(如sqlite3_bind_int、sqlite3_bind_text等)
sqlite3_column_*()– 获取结果集列值(如sqlite3_column_int、sqlite3_column_text等)
sqlite3_clear_bindings()– 清除所有绑定的参数
sqlite3_stmt_readonly()– 检查语句是否只读
sqlite3_stmt_busy()– 检查语句是否正在执行
mysql_stmt_init()– 初始化预处理句柄
mysql_stmt_prepare()– 准备 SQL 语句
mysql_stmt_param_count()– 获取参数个数
mysql_stmt_bind_param()– 绑定输入参数
mysql_stmt_execute()– 执行预处理语句
mysql_stmt_bind_result()– 绑定结果集列
mysql_stmt_store_result()– 存储结果集
mysql_stmt_fetch()– 逐行获取结果
mysql_stmt_free_result()– 释放结果集
mysql_stmt_close()– 关闭预处理句柄
通用 SQL 层面(如 PDO、JDBC):
prepare()– 准备
bindParam()/bindValue()– 绑定参数
execute()– 执行
fetch()/getResult()– 获取结果
什么是MySQL数据库
定义:MySQL是一个开源的关系型数据库管理系统(RDBMS)
客户端应用程序(PHP、Python,java)
MySQL服务器层-连接器-查询缓存-分析器-优化器-执行器
存储引擎层InnoDB(默认) MyISAM Memory
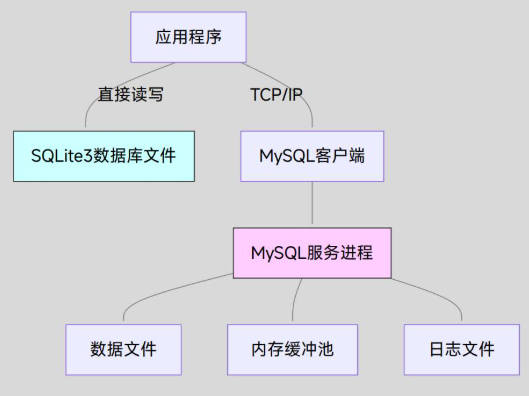
MySQL vs SQLite3
| 特性 | MySQL | SQLite3 |
|---|---|---|
| 架构 | 客户端-服务器 | 嵌入式 |
| 并发 | 高并发支持 | 单写多读 |
| 存储 | 独立服务进程 | 单文件 |
| 数据类型 | 丰富(ENUM, SET 等) | 基本类型 |
| 网络访问 | 原生支持 | 需应用层实现 |
| 适用场景 | 中大型应用 | 移动 / 嵌入式 / IoT |
关键流程对比:
SQLite3:
1、应用直接操作数据库文件
2、文件锁控制并发
3、无网络通信开销
MySQL:
1、客户端与服务进程通信
2、服务进程管理内存缓冲
3、复杂的日志系统(redo/undo)
4、支持远程访问
为什么要使用MySQL
| 优势 | 说明 | 应用场景 |
|---|---|---|
| 开源免费 | 社区版零成本 | 创业公司 / 个人项目 |
| 高性能 | 优化查询引擎 | 高并发 Web 应用 |
| 可靠性 | ACID 事务支持 | 金融 / 电商系统 |
| 易用性 | 丰富文档和工具 | 快速开发部署 |
| 扩展性 | 读写分离 / 分库分表 | 大型分布式系统 |
SQLite3 所有数据类型
| 存储类 | 说明 | 示例 |
|---|---|---|
| NULL | 空值 | NULL |
| INTEGER | 有符号整数,根据大小自动使用 1/2/3/4/6/8 字节存储 | 42, -300 |
| REAL | 浮点数,8 字节 IEEE 754 双精度 | 3.14, 2.5e5 |
| TEXT | 文本字符串,使用 UTF-8/UTF-16 编码 | 'hello', '张三' |
| BLOB | 二进制大对象,完全按输入原样存储(不做编码转换) | x'FFD8FFE0' 或从文件读入的字节 |
MySQL核心概念与操作
连接数据库
mysql-u root -p创建数据库
CREATE DATABASE school;
USE school;创建表
CREATE TABLE students (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT,
gpa DECIMAL(3,2)
);增删改查
增
INSERT INTO students (name, age, gpa) VALUES ('张三', 20, 3.8);查
SELECT * FROM students WHERE gpa > 3.5;改
UPDATE students SET age = 21 WHERE name = '张三';删
DELETE FROM students WHERE id = 1;类型处理:
SQLite3(动态类型)
INSERT INTO numbers (int_col) VALUES ('123abc'); -- 成功!存储为文本MySQL(严格类型)
INSERT INTO numbers (int_col) VALUES ('123abc'); -- 错误!Truncated incorrect value空值处理:
SQLite3(允许主键为空)
CREATE TABLE t(id INTEGER PRIMARY KEY);
INSERT INTO t(id) VALUES (NULL); -- 成功!自动生成ROWIDMySQL(主键不可为空)
CREATE TABLE t(id INT PRIMARY KEY);
INSERT INTO t(id) VALUES (NULL); -- 错误!Column 'id' cannot be nullMySQL vs SQLite3数据类型对比
| 类型 | MySQL | SQLite3 |
|---|---|---|
| 整数 | TINYINT/SMALLINT/INT/BIGINT | INTEGER |
| 字符串 | VARCHAR/CHAR | TEXT |
| 日期时间 | DATETIME/TIMESTAMP | TEXT/REAL/INTEGER |
| 二进制 | BLOB/LONGBLOB | BLOB |
sqlite3_exec()
函数的原型为:
int sqlite3_exec(sqlite3* db, const char* sql, sqlite3_callback callback, void* data, char** errmsg);int sqlite3_exec(sqlite3* db, const char* sql, sqlite3_callback callback, void* data, char** errmsg);
参数 errmsg 是一个指向 char* 的指针,用于输出错误信息。当执行 SQL 语句出错时,SQLite 会将动态分配的错误信息字符串的地址写入 *errmsg,调用者可通过 *errmsg 获取错误描述,并在使用后调用 sqlite3_free(*errmsg) 释放内存
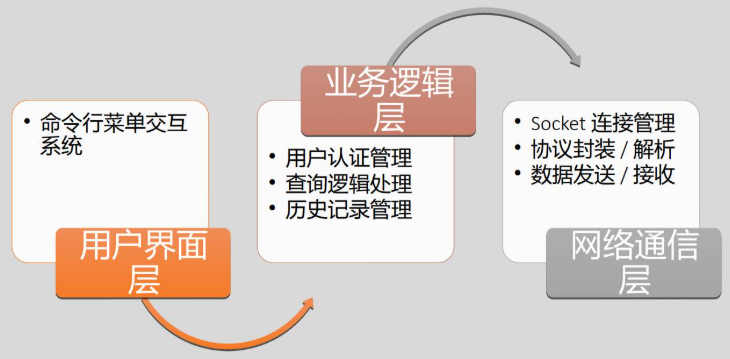
项目概述
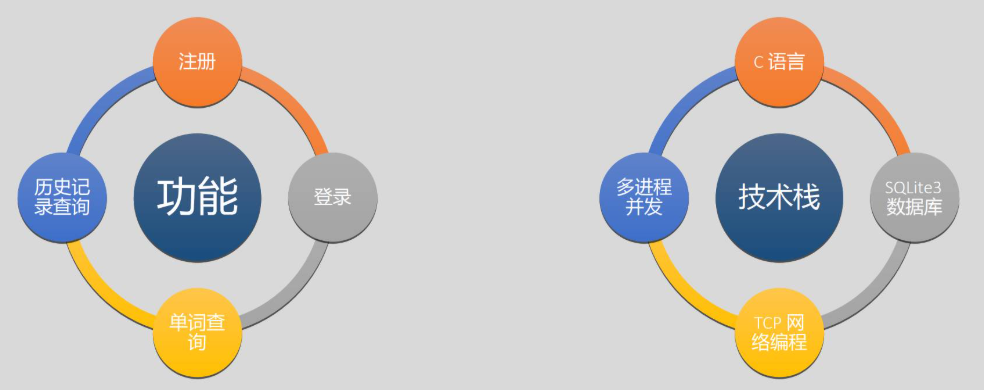
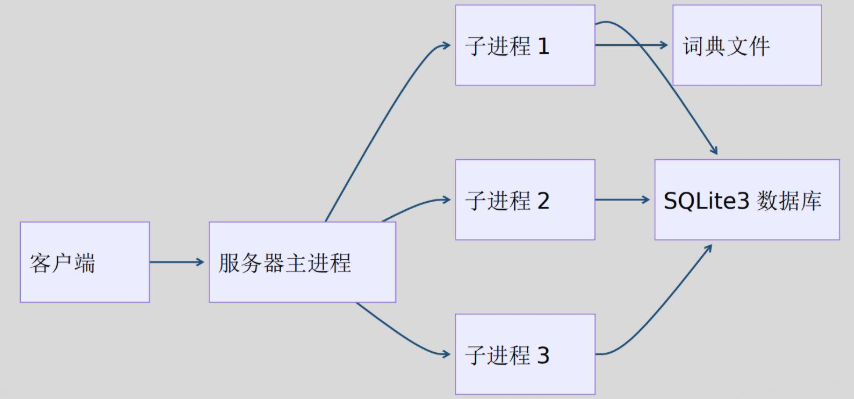
系统架构设计
数据表设计
用户表
| 字段名 | 类型 | 说明 |
|---|---|---|
| name | TEXT | 用户名(主键) |
| pass | TEXT | 密码 |
历史记录表
| 字段名 | 类型 | 说明 |
|---|---|---|
| name | TEXT | 用户名(主键) |
| date | TEXT | 查询时间 |
| word | TEXT | 查询的单词 |
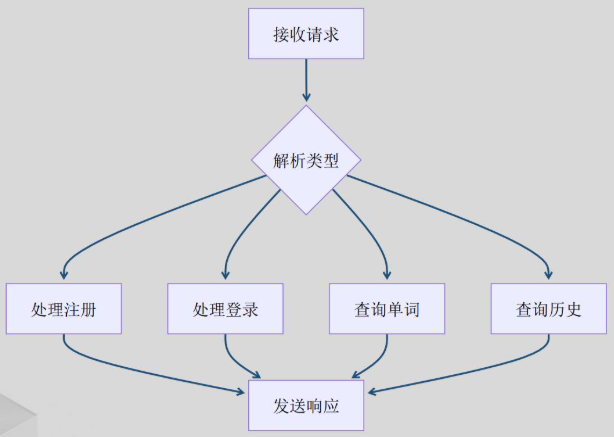
核心流程
请求处理流程:
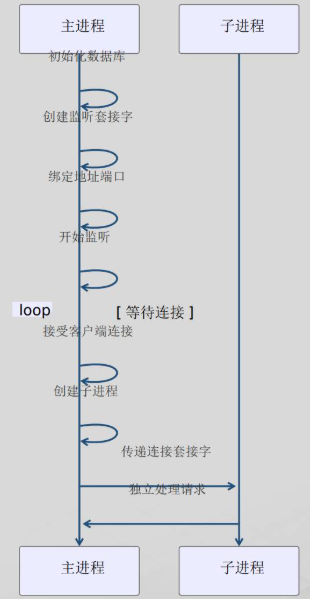
服务器启动流程:
文件处理

协议设计
消息结构体:
typedef struct {
int type; // 操作类型:R/L/Q/H
char name[N]; // 用户名
char data[256]; // 密码/单词/结果
} MSG;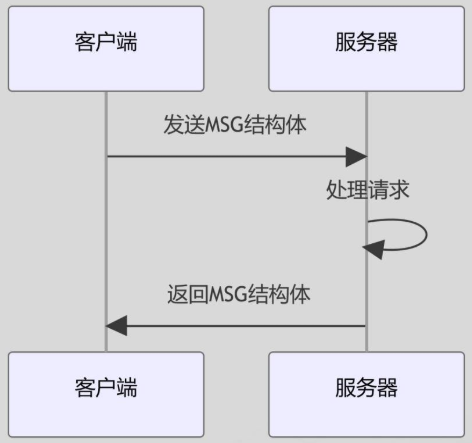
回调机制
历史记录查询回调机制:
int history_callback(void *arg, int f_num, char **f_value, char **f_name) {
int connectfd = *(int *)arg; // 获取连接套接字
MSG msg;
// 格式化历史记录:时间 + 单词
sprintf(msg.data, "%s : %s", f_value[1], f_value[2]);
send(connectfd, &msg, sizeof(msg), 0); // 发送记录
return 0; // 继续处理下一条
}
客户端设计
客户端核心功能:
1、用户认证(注册/登录)
2、单词查询
3、历史记录查询
4、连接管理
客户端-服务端交互

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)