13种机器学习模型+多分类+PCA+贝叶斯优化超参数+SHAP高级可视化
感谢关注,一起来学习干货。
本期摘要
探索性数据分析 (EDA):
- 数据质量评估:
综合分析缺失值、数据类型和唯一值。
- 分布探索:
使用直方图、核密度估计(KDE)和箱线图分析目标变量与特征变量的分布、偏度及异常值。
- 关系挖掘:
通过相关性热力图、小提琴图和ANOVA F检验等方法,探索特征之间以及特征与目标变量之间的关系。

- 数据预处理与特征工程:
- 稳健的数据清洗:
采用中位数填充缺失值,并基于IQR(四分位距)方法对异常值进行智能处理(比例低则移除,比例高则进行Winsorizing缩尾处理)。
- 数据标准化:
使用
StandardScaler消除特征量纲差异,提升模型性能和收敛速度。 - 降维分析:
通过主成分分析 (PCA) 评估数据降维的潜力和必要性。
- 模型评估与选择:
- 多模型横评:
系统性地训练和评估了12种分类模型,涵盖线性模型、树模型、集成模型、SVM、神经网络等。
- 统计显著性检验:
运用配对t检验和Wilcoxon符号秩检验,科学地判断模型性能差异是否真实存在,而非随机波动。
- 超参数优化:
使用Optuna框架进行高效的贝叶斯优化,自动搜索LightGBM模型的最佳参数组合。
- 深度模型可解释性 (SHAP):
- 全局解释:
通过摘要图(Summary Plot)和条形图(Bar Plot),识别对模型所有预测起决定性作用的关键特征,并按类别进行细分。
- 局部解释:
利用瀑布图(Waterfall Plot)和决策图(Decision Plot),精准剖析模型对单个样本或样本群的预测决策路径。
- 关系与交互探索:
借助依赖图(Dependence Plot)和交互图(Interaction Plot),揭示特征与预测之间的非线性关系,以及特征之间的协同或制约效应。
- 高级定制化可视化:
创建了信息密度极高的四象限分析图和专业级组合仪表盘,将全局重要性、局部依赖性、数据分布等多维信息整合于一张图中。
阶段 1: 环境初始化与设置
这个阶段负责为整个机器学习项目搭建基础环境。
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFold
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, f_classif, mutual_info_classif
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, roc_auc_score, roc_curve
from sklearn.metrics import precision_score, recall_score, f1_score
# 机器学习模型
from sklearn.linear_model import LogisticRegression, Ridge, SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, AdaBoostClassifier, \
ExtraTreesClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
#mlines
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体和图表样式
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 显示中文
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.max_rows', None) # 显示所有行
# 设置随机种子
np.random.seed(42)
print("=" * 80)
print("机器学习完整Pipeline: EDA → 预处理 → 模型对比 → 最优选择")
print("=" * 80)
阶段 2: 数据加载与准备
此阶段负责将原始数据读入程序,并明确定义哪些列是用于预测的特征(feature_cols),哪些是我们要预测的目标(main_target)。
作用解释: 这是数据分析的第一步。通过pd.read_csv将数据加载成一个DataFrame,这是后续所有操作的基础。明确地分离特征和目标变量,可以使代码结构更清晰,避免在后续步骤中混淆。
新手指南:如何替换为自己的数据集
假设你有一个自己的数据集,名为 my_customer_data.csv,你想用它来替换示例数据。请遵循以下三个简单步骤:
步骤 1: 准备你的数据文件
- 格式确认:
确保你的数据文件是 CSV 格式。这是最通用、最容易处理的表格数据格式。
- 文件位置:
为了简单起见,请将你的CSV文件(例如
my_customer_data.csv)放在和你的Python代码文件相同的文件夹下。这样你就不需要处理复杂的文件路径问题。
步骤 2: 修改代码 - 加载你的文件
找到加载数据的代码行,将示例文件名替换为你的文件名。
步骤 3: 修改代码 - 定义你的特征和目标
这是最重要的一步。你需要告诉代码你的数据集中哪些是特征,哪个是目标。
- 定义你的特征 (
feature_cols)将
feature_cols列表中的内容完全替换为你想要用作输入的列名。
- 定义你的目标 (
main_target)将
main_target变量的值替换为你要预测的列名。
# 1. 数据加载和准备
print("\n1. 数据加载和准备")
print("-" * 50)
# 读取数据
data = pd.read_csv('公众号Python机器学习ml-2025-9-13.csv')
print(f"数据形状: {data.shape}")
print(data.columns)
# 定义特征和目标变量
feature_cols = ['age', 'marry', 'years', 'income', 'education', 'consume',
'work', 'gender', 'family']
feature_cols = [col for col in feature_cols if col in data.columns]
#grade目标变量
main_target = 'grade'
print(f"特征变量: {feature_cols}")
print(f"目标变量: {main_target}")
阶段 3: EDA - 数据概览
这是探索性数据分析(EDA)的第一部分,旨在快速了解数据集的宏观情况。它会打印出数据的基本信息,包括形状(行数和列数)、数据类型、缺失值情况以及每个特征的唯一值数量。最后,它还会显示数值型特征的描述性统计信息(如均值、标准差、分位数等)。
作用解释: 这一步就像对数据进行一次“体检”。通过概览,我们可以快速发现问题,例如:
- 缺失值:
哪些列有缺失数据?缺失比例有多高?这决定了后续的缺失值处理策略。
- 数据类型:
特征是数值型还是类别型?是
-
否存在需要转换的数据类型?
- 唯一值:
唯一值数量可以帮助我们判断一个特征是连续的还是离散的。
- 描述性统计:
可以让我们对数值特征的分布范围和中心趋势有一个初步的印象。
# ==================== EDA探索性数据分析部分 ====================
print("\n" + "=" * 80)
print("EDA 探索性数据分析")
print("=" * 80)
# 2. 数据概览
print("\n2. 数据基本信息")
print("-" * 50)
print("数据集基本信息:")
print(f"数据形状: {data.shape}")
print(f"特征数量: {len(feature_cols)}")
print(f"样本数量: {len(data)}")
# 数据类型和缺失值信息
print("\n数据类型和缺失值:")
info_df = pd.DataFrame({
'数据类型': data[feature_cols + [main_target]].dtypes,
'缺失值数量': data[feature_cols + [main_target]].isnull().sum(),
'缺失值比例(%)': (data[feature_cols + [main_target]].isnull().sum() / len(data) * 100).round(2),
'唯一值数量': data[feature_cols + [main_target]].nunique()
})
print(info_df)
# 基本统计信息
print("\n特征变量描述性统计:")
desc_stats = data[feature_cols].describe()
print(desc_stats.round(4))
阶段 4: EDA - 目标变量分析
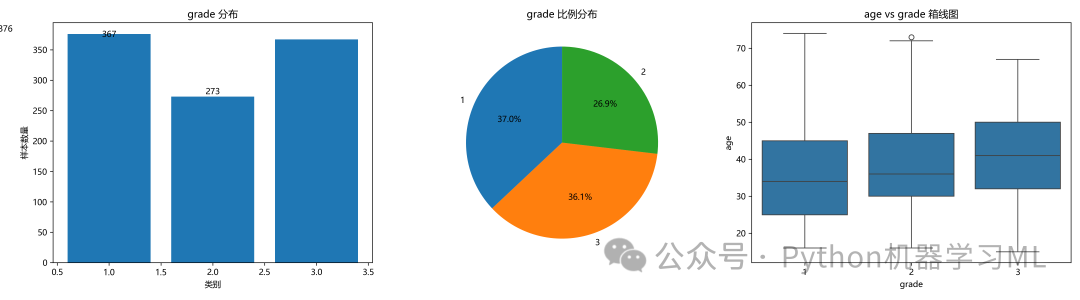
这个阶段专门分析我们要预测的目标变量 grade。它会计算并打印出目标变量中每个类别的数量和比例,并通过柱状图、饼图和箱线图进行可视化。
作用解释: 对目标变量的分析至关重要,因为它直接关系到模型的建立和评估。
- 类别分布:
我们可以了解这是一个平衡还是不平衡的数据集。如果某个类别的样本数量远少于其他类别,那么在建模时可能需要采用特殊的处理方法(如分层抽样、过采样、欠采样或调整类别权重)。
- 可视化:
图表能直观地展示类别不平衡的程度,并初步探索目标变量与某个数值特征(这里是第一个特征)之间的关系。
python
# 3. 目标变量分析
print("\n3. 目标变量分析")
print("-" * 50)
# 目标变量分布
target_counts = data[main_target].value_counts()
target_props = data[main_target].value_counts(normalize=True)
print("目标变量分布:")
target_summary = pd.DataFrame({
'数量': target_counts,
'比例(%)': (target_props * 100).round(2)
})
print(target_summary)
# 目标变量可视化
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
# 柱状图
axes[0].bar(target_counts.index, target_counts.values)
axes[0].set_title(f'{main_target} 分布')
axes[0].set_xlabel('类别')
axes[0].set_ylabel('样本数量')
for i, v inenumerate(target_counts.values):
axes[0].text(i, v + 0.5, str(v), ha='center', va='bottom')
# 饼图
axes[1].pie(target_counts.values, labels=target_counts.index, autopct='%1.1f%%', startangle=90)
axes[1].set_title(f'{main_target} 比例分布')
# 箱线图
sns.boxplot(x=data[main_target], y=data[feature_cols[0]], ax=axes[2])
axes[2].set_title(f'{feature_cols[0]} vs {main_target} 箱线图')
axes[2].set_xlabel(main_target)
axes[2].set_ylabel(feature_cols[0])
plt.tight_layout()
plt.savefig('target_variable_analysis.png', dpi=300)
plt.show()
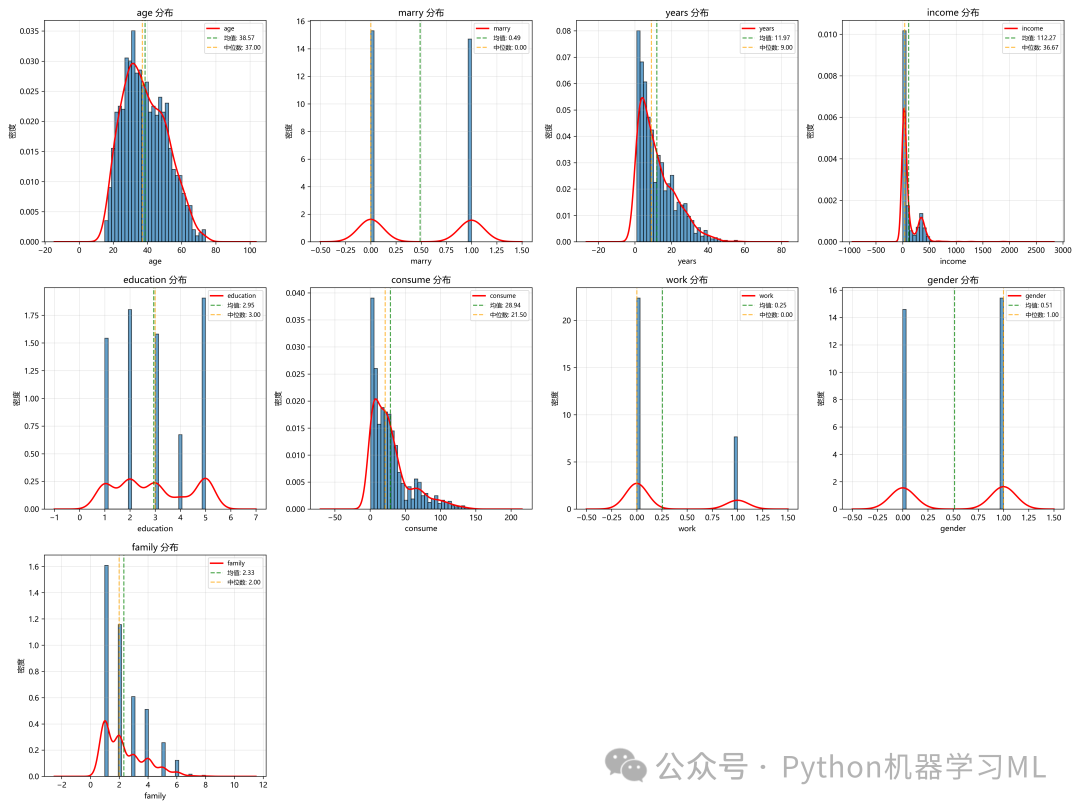
阶段 5: EDA - 特征变量分布分析
此阶段通过绘制每个特征的直方图(Histogram)和核密度估计图(KDE)来深入了解它们的分布情况。
作用解释: 通过观察每个特征的分布图,我们可以获得很多有价值的信息:
- 分布形状:
特征是符合正态分布、均匀分布,还是偏态分布(左偏或右偏)?这可以为后续是否需要进行数据转换(如对数变换)提供依据。
- 数据集中趋势:
图中标注的均值和中位数可以帮助我们判断分布的对称性。如果均值和中位数相差较大,说明数据存在偏斜。
- 多峰性:
分布是否存在多个峰值?这可能暗示着数据中存在多个潜在的子群体。
python
# 4. 特征变量分布分析
print("\n4. 特征变量分布分析")
print("-" * 50)
# 计算需要的子图数量
n_features = len(feature_cols)
n_cols = 4
n_rows = (n_features + n_cols - 1) // n_cols
# 特征分布直方图
print("绘制特征分布直方图...")
fig, axes = plt.subplots(n_rows, n_cols, figsize=(20, 5 * n_rows))
axes = axes.ravel() if n_rows > 1else [axes] if n_cols == 1else axes
for i, col inenumerate(feature_cols):
if i < len(axes):
# 直方图和KDE
axes[i].hist(data[col].dropna(), bins=30, density=True, alpha=0.7, edgecolor='black')
# 添加KDE曲线
try:
data[col].dropna().plot.density(ax=axes[i], color='red', linewidth=2)
except:
pass
axes[i].set_title(f'{col} 分布')
axes[i].set_xlabel(col)
axes[i].set_ylabel('密度')
axes[i].grid(True, alpha=0.3)
# 添加统计信息
mean_val = data[col].mean()
median_val = data[col].median()
axes[i].axvline(mean_val, color='green', linestyle='--', alpha=0.7, label=f'均值: {mean_val:.2f}')
axes[i].axvline(median_val, color='orange', linestyle='--', alpha=0.7, label=f'中位数: {median_val:.2f}')
axes[i].legend(fontsize=8)
# 隐藏多余的子图
for j inrange(i + 1, len(axes)):
axes[j].set_visible(False)
plt.tight_layout()
plt.savefig('feature_distribution_analysis.png', dpi=300)
plt.show()
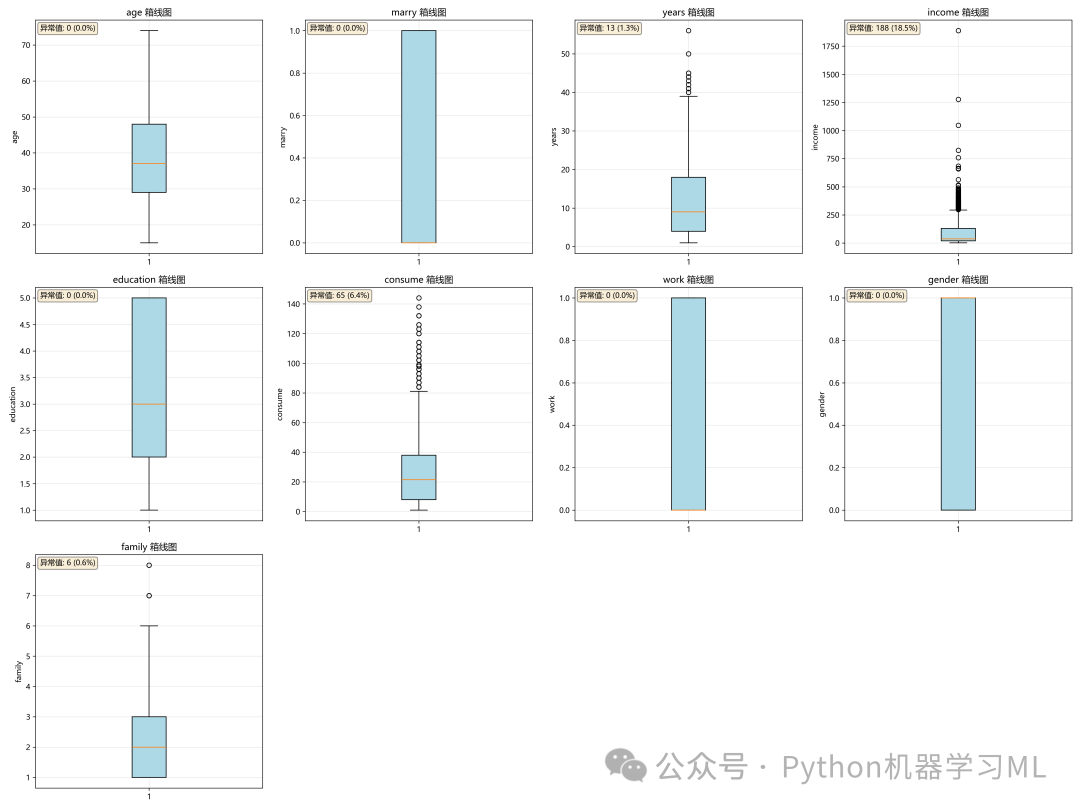
阶段 6: EDA - 箱线图与异常值分析
这个阶段使用箱线图(Box Plot)来可视化每个数值特征的分布,并系统地检测和量化异常值。
作用解释: 箱线图是识别异常值的有力工具。
- 可视化:
它可以清晰地展示数据的中位数、四分位数(Q1, Q3)以及由“胡须”(whiskers)定义的正常数据范围。任何落在“胡须”之外的点通常被认为是异常值。
- 量化异常值:
代码使用标准的IQR(四分位距)方法来精确计算异常值的边界,并统计每个特征中异常值的数量和比例。这为后续决定如何处理异常值(是移除、替换还是保留)提供了数据支持。
python
# 5. 箱线图分析
print("\n5. 箱线图分析(异常值检测)")
print("-" * 50)
print("绘制箱线图分析异常值...")
fig, axes = plt.subplots(n_rows, n_cols, figsize=(20, 5 * n_rows))
axes = axes.ravel() if n_rows > 1else [axes] if n_cols == 1else axes
outlier_summary = {}
for i, col inenumerate(feature_cols):
if i < len(axes):
# 箱线图
box_plot = axes[i].boxplot(data[col].dropna(), patch_artist=True)
box_plot['boxes'][0].set_facecolor('lightblue')
axes[i].set_title(f'{col} 箱线图')
axes[i].set_ylabel(col)
axes[i].grid(True, alpha=0.3)
# 计算异常值
Q1 = data[col].quantile(0.25)
Q3 = data[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = data[(data[col] < lower_bound) | (data[col] > upper_bound)][col]
outlier_count = len(outliers)
outlier_percent = (outlier_count / len(data)) * 100
outlier_summary[col] = {
'count': outlier_count,
'percentage': outlier_percent,
'lower_bound': lower_bound,
'upper_bound': upper_bound
}
# 添加异常值信息
axes[i].text(0.02, 0.98, f'异常值: {outlier_count} ({outlier_percent:.1f}%)',
transform=axes[i].transAxes, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
# 隐藏多余的子图
for j inrange(i + 1, len(axes)):
axes[j].set_visible(False)
plt.tight_layout()
plt.savefig('boxplot_outlier_analysis.png', dpi=300)
plt.show()
# 异常值统计
print("\n异常值统计总结:")
outlier_df = pd.DataFrame(outlier_summary).T
outlier_df.columns = ['异常值数量', '异常值比例(%)', '下界', '上界']
outlier_df['异常值比例(%)'] = outlier_df['异常值比例(%)'].round(2)
print(outlier_df)
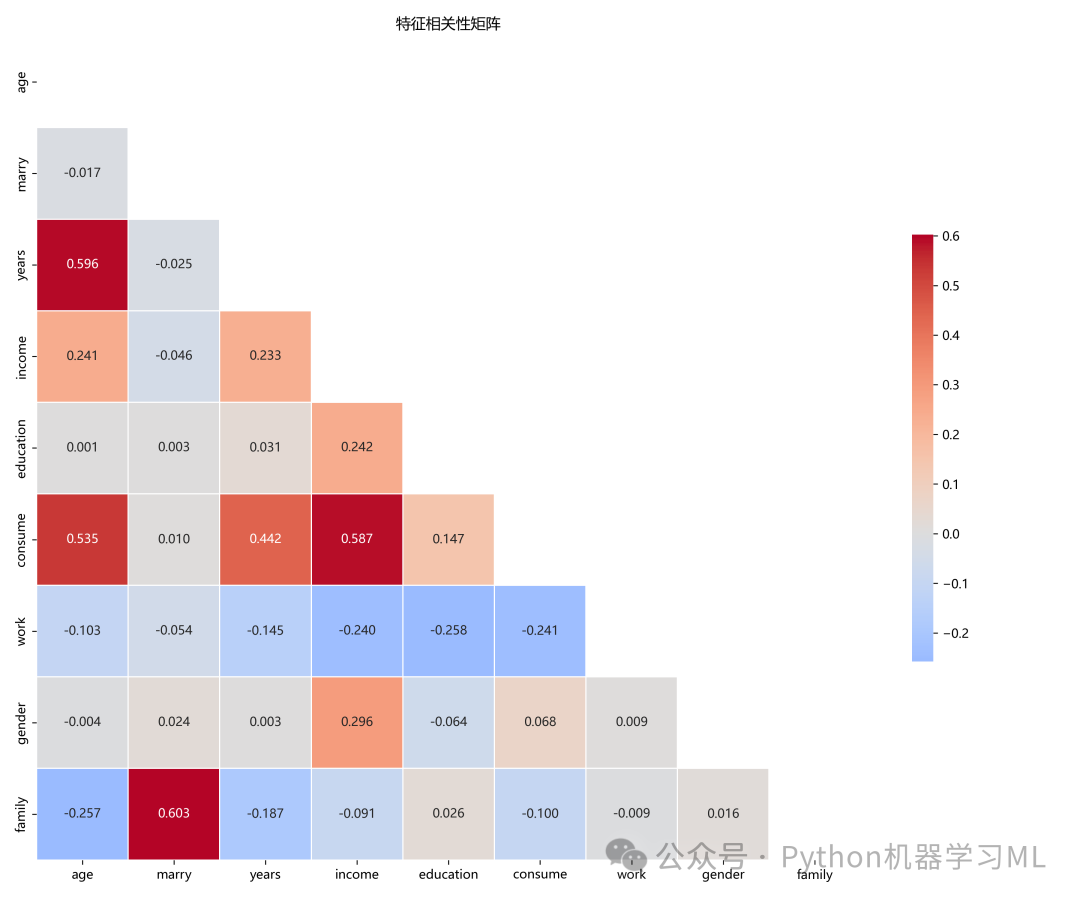
阶段 7: EDA - 特征相关性分析
此阶段计算并可视化特征之间的线性相关性,并对高度相关的特征对进行处理。
作用解释:
- 相关性热力图:
热力图可以直观地展示所有特征两两之间的相关系数。颜色越暖(如红色)表示正相关性越强,颜色越冷(如蓝色)表示负相关性越强。
- 识别多重共线性:
强相关的特征(例如相关系数绝对值 > 0.8)会引入多重共线性问题,这会影响某些模型(如线性模型)的稳定性和解释性。
- 特征选择:
代码会自动识别出这些高相关性的特征对,并提出移除其中一个的建议,作为一种简单的特征选择策略,以提高模型的稳健性。
python
# 6. 特征相关性分析
print("\n6. 特征相关性分析")
print("-" * 50)
print("计算特征间相关性...")
correlation_matrix = data[feature_cols].corr()
# 相关性热力图
plt.figure(figsize=(12, 10))
mask = np.triu(np.ones_like(correlation_matrix, dtype=bool))
sns.heatmap(correlation_matrix, mask=mask, annot=True, cmap='coolwarm', center=0,
square=True, linewidths=0.5, cbar_kws={"shrink": 0.5}, fmt='.3f')
plt.title('特征相关性矩阵')
plt.tight_layout()
plt.savefig('feature_correlation_matrix.png', dpi=300)
plt.show()
# 高相关性特征对,
print("\n高相关性特征对 (|r| > 0.8):")
high_corr_pairs = []
for i inrange(len(correlation_matrix.columns)):
for j inrange(i + 1, len(correlation_matrix.columns)):
corr_val = correlation_matrix.iloc[i, j]
ifabs(corr_val) > 0.8:
high_corr_pairs.append({
'feature1': correlation_matrix.columns[i],
'feature2': correlation_matrix.columns[j],
'correlation': corr_val
})
if high_corr_pairs:
high_corr_df = pd.DataFrame(high_corr_pairs)
high_corr_df = high_corr_df.sort_values('correlation', key=abs, ascending=False)
print(high_corr_df)
else:
print("没有发现高相关性特征对")
#若有高相关特征,则对高相关特征进行处理
if high_corr_pairs:
to_remove = set()
for pair in high_corr_pairs:
# 简单策略:移除相关性较高对中的第二个特征
to_remove.add(pair['feature2'])
print(f"\n建议移除以下高相关性特征以减少多重共线性: {to_remove}")
feature_cols = [col for col in feature_cols if col notin to_remove]
print(f"更新后的特征列表: {feature_cols}")
else:
print("无需移除任何特征")
阶段 8: EDA - 特征与目标变量关系分析
这是EDA的最后一部分,旨在探索每个特征与目标变量 grade 之间的关系。
作用解释: 这一步是为了寻找对预测目标有价值的特征。
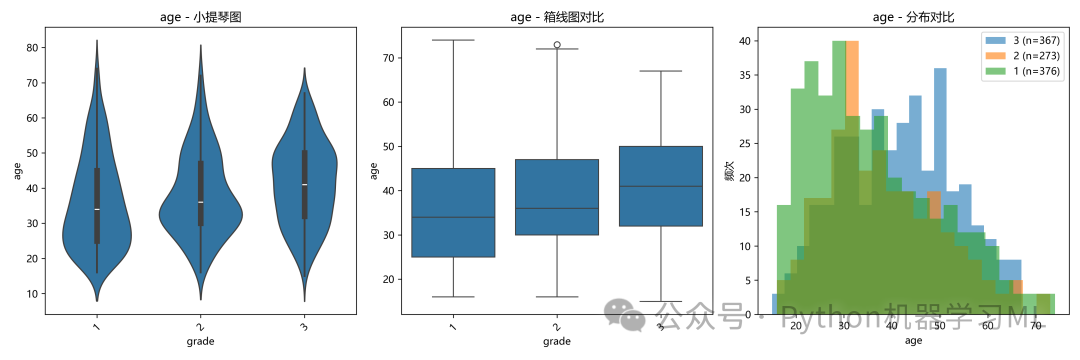
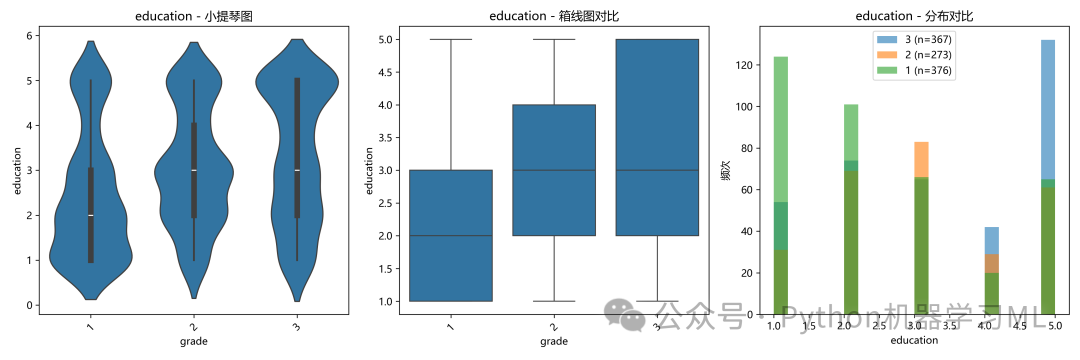
- 分类对比图:
代码为每个特征生成了三种对比图(小提琴图、箱线图、叠加直方图)。通过比较不同
grade类别下,某个特征的分布情况,我们可以直观地判断这个特征是否有区分不同类别的能力。如果不同类别下的分布差异很大,说明这个特征可能非常重要。 - 统计检验:
代码接着使用统计方法(如果是数值型目标则用相关系数,如果是分类型目标则用ANOVA F检验)来量化这种关系。F检验的p值如果很小(<0.05),则在统计学上支持“该特征在不同目标类别下的均值存在显著差异”的结论,进一步确认了该特征的预测价值。
python
# 7. 特征与目标变量关系分析
print("\n7. 特征与目标变量关系分析")
print("-" * 50)
# 不同类别下的特征分布对比
unique_targets = data[main_target].unique()
n_targets = len(unique_targets)
print(f"绘制不同{main_target}类别下的特征分布对比...")
# 为每个特征创建分类对比图
for idx, col inenumerate(feature_cols[:6]): # 只显示前6个特征避免图太多
plt.figure(figsize=(15, 5))
# 小提琴图
plt.subplot(1, 3, 1)
sns.violinplot(data=data, x=main_target, y=col)
plt.title(f'{col} - 小提琴图')
plt.xticks(rotation=45)
# 箱线图
plt.subplot(1, 3, 2)
sns.boxplot(data=data, x=main_target, y=col)
plt.title(f'{col} - 箱线图对比')
plt.xticks(rotation=45)
# 直方图叠加
plt.subplot(1, 3, 3)
for target in unique_targets:
subset = data[data[main_target] == target][col].dropna()
plt.hist(subset, alpha=0.6, label=f'{target} (n={len(subset)})', bins=20)
plt.xlabel(col)
plt.ylabel('频次')
plt.title(f'{col} - 分布对比')
plt.legend()
plt.tight_layout()
plt.savefig(f'feature_{col}_by_{main_target}.png', dpi=300)
plt.show()
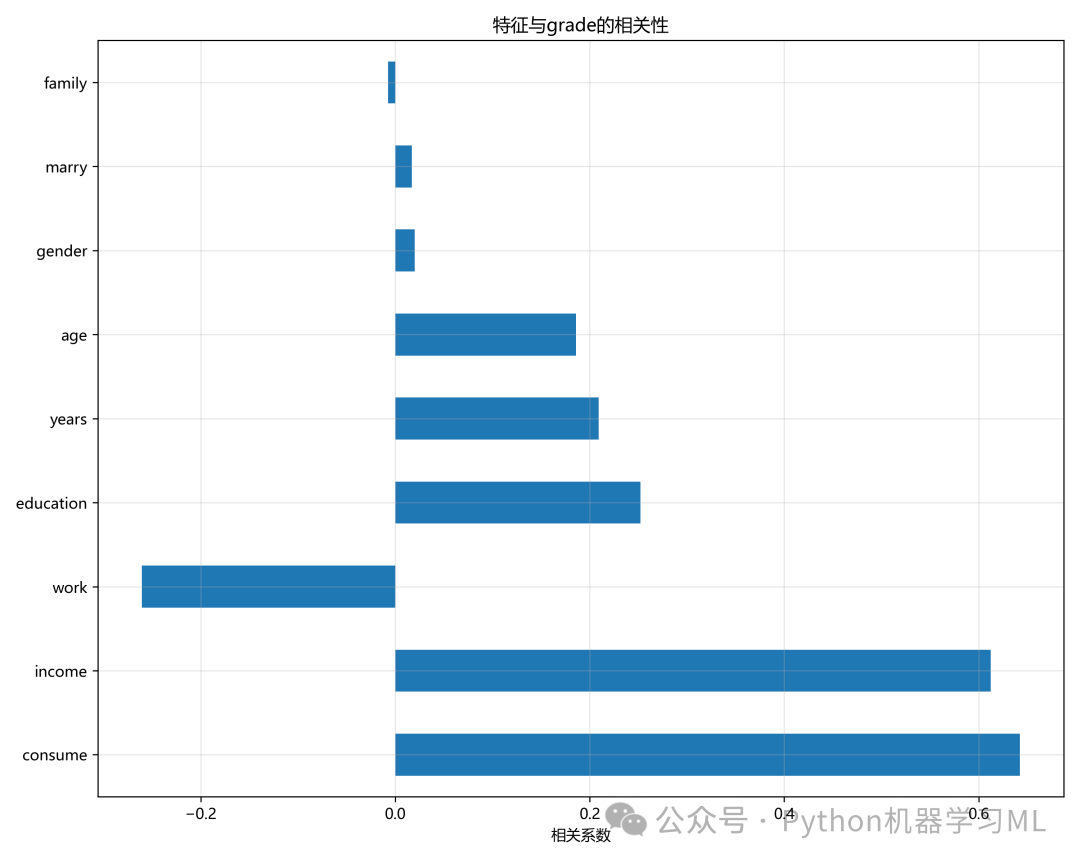
# 8. 特征与目标变量相关性
print("\n8. 特征与目标变量相关性")
print("-" * 50)
# 如果目标变量是数值型,计算相关性
if data[main_target].dtype in ['int64', 'float64']:
target_correlation = data[feature_cols + [main_target]].corr()[main_target].drop(main_target).sort_values(key=abs,
ascending=False)
print("特征与目标变量相关性:")
print(target_correlation)
# 可视化特征与目标变量相关性
plt.figure(figsize=(10, 8))
target_correlation.plot(kind='barh')
plt.title(f'特征与{main_target}的相关性')
plt.xlabel('相关系数')
plt.grid(True, alpha=0.3)
plt.tight_layout()
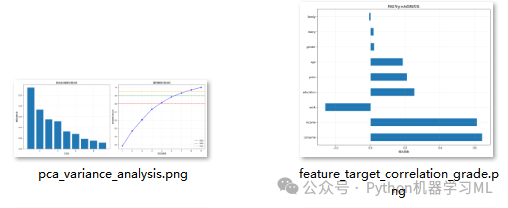
plt.savefig(f'feature_target_correlation_{main_target}.png', dpi=300)
plt.show()
else:
# 如果是分类变量,使用方差分析
from scipy import stats
print("特征与目标变量关联性分析 (F-统计量):")
f_stats = []
p_values = []
for col in feature_cols:
groups = [data[data[main_target] == target][col].dropna() for target in unique_targets]
f_stat, p_val = stats.f_oneway(*groups)
f_stats.append(f_stat)
p_values.append(p_val)
anova_results = pd.DataFrame({
'Feature': feature_cols,
'F_statistic': f_stats,
'p_value': p_values,
'significant': ['是'if p < 0.05else'否'for p in p_values]
}).sort_values('F_statistic', ascending=False)
print(anova_results)
阶段 9: 数据预处理
在完成EDA之后,这个阶段开始对数据进行正式的、系统的清洗和转换,为建模做准备。这包括处理缺失值、处理异常值、以及数据标准化。
作用解释: 这是将原始数据转化为机器学习模型可以“消化”的干净数据的关键步骤。
- 缺失值处理:
机器学习模型通常不能处理含有缺失值(NaN)的数据。这里使用中位数(
median)来填充所有缺失的数值,这是一种比均值更稳健的填充方法,因为它不易受异常值影响。 - 异常值处理:
根据之前EDA的发现,代码在这里实现了一套处理逻辑:如果异常值样本比例较高(>5%),则采用“缩尾”(Winsorizing)方法,将极端值替换为设定的边界值,以保留样本信息;如果比例较低,则直接移除这些异常样本。
- 数据标准化:
使用
StandardScaler将所有特征缩放到均值为0、标准差为1的范围。这对于许多模型(如SVM、逻辑回归、神经网络)至关重要,因为它可以防止度量单位不同的特征对模型产生不成比例的影响,并有助于算法更快地收敛。
python
# ==================== 预处理和建模部分 ====================
# 2. 数据预处理
print("\n" + "=" * 80)
print("数据预处理")
print("=" * 80)
# 提取特征和目标
X = data[feature_cols].copy()
y = data[main_target].copy()
# 处理缺失值
print("处理缺失值...")
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='median')
X_filled = pd.DataFrame(imputer.fit_transform(X), columns=X.columns)
print(f"处理前缺失值: {X.isnull().sum().sum()}")
print(f"处理后缺失值: {X_filled.isnull().sum().sum()}")
# 3. 异常值处理
print("\n3. 异常值检测和处理")
print("-" * 50)
defdetect_outliers_iqr(df, column):
"""使用IQR方法检测异常值"""
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = (df[column] < lower_bound) | (df[column] > upper_bound)
return outliers, lower_bound, upper_bound
# 检测异常值
outlier_info = {}
total_outliers = pd.Series([False] * len(X_filled))
for col in feature_cols:
outliers, lower, upper = detect_outliers_iqr(X_filled, col)
outlier_count = outliers.sum()
outlier_percent = (outlier_count / len(X_filled)) * 100
outlier_info[col] = {
'count': outlier_count,
'percentage': outlier_percent,
'lower_bound': lower,
'upper_bound': upper
}
total_outliers = total_outliers | outliers
print("异常值统计:")
for col, info in outlier_info.items():
print(f"{col}: {info['count']} ({info['percentage']:.2f}%)")
print(f"\n总异常值样本数: {total_outliers.sum()} ({(total_outliers.sum() / len(X_filled)) * 100:.2f}%)")
# 异常值处理策略
outlier_threshold = 0.05# 5%阈值
if (total_outliers.sum() / len(X_filled)) > outlier_threshold:
print("\n异常值比例较高,使用Winsorizing方法处理...")
# Winsorizing: 将异常值替换为分位数值
X_clean = X_filled.copy()
for col in feature_cols:
outliers, lower, upper = detect_outliers_iqr(X_filled, col)
X_clean.loc[X_clean[col] < lower, col] = lower
X_clean.loc[X_clean[col] > upper, col] = upper
else:
print("\n异常值比例较低,直接移除异常值...")
# 移除异常值
X_clean = X_filled[~total_outliers].copy()
y_clean = y[~total_outliers].copy()
print(f"处理后数据形状: {X_clean.shape}")
# 4. 数据标准化
print("\n4. 数据标准化")
print("-" * 50)
scaler = StandardScaler()
X_scaled = pd.DataFrame(scaler.fit_transform(X_clean), columns=X_clean.columns)
print("标准化前后对比:")
comparison_df = pd.DataFrame({
'原始均值': X_clean.mean(),
'原始标准差': X_clean.std(),
'标准化后均值': X_scaled.mean(),
'标准化后标准差': X_scaled.std()
})
print(comparison_df.round(4))
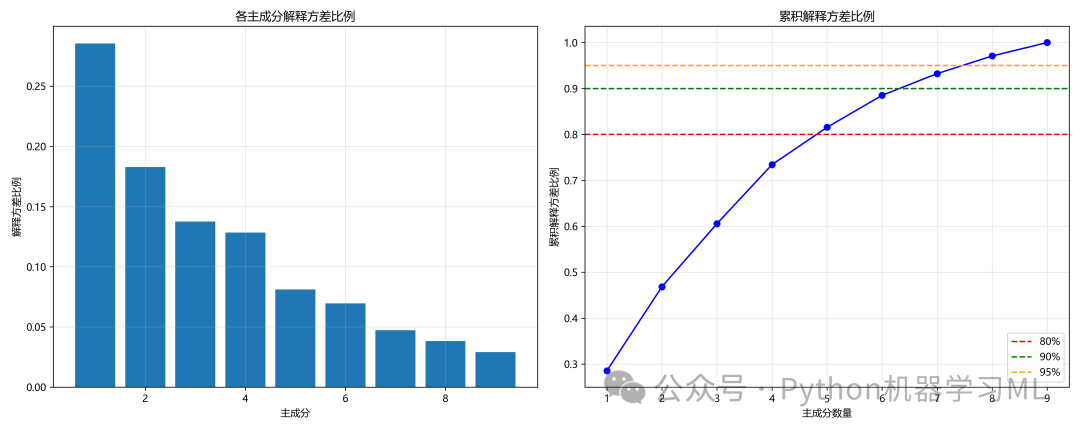
阶段 10: PCA降维分析与决策
这个阶段使用主成分分析(PCA)来探索数据降维的可能性。
作用解释: PCA是一种无监督的降维技术,它能将原始的多个相关特征转换成少数几个线性无关的新特征(主成分),同时尽可能多地保留原始数据的信息(方差)。
- 分析:
代码首先计算并可视化了所有主成分能解释的方差比例。累积方差图是决策的关键,它告诉我们用多少个主成分可以保留原始数据80%、90%或95%的信息。
- 决策:
基于分析结果,代码设定了一个决策规则:如果特征数量本身较多(>10),并且用少于70%数量的主成分就能解释90%的方差,那么就执行PCA降维;否则,保留原始特征。这是一种平衡模型简化和信息损失的实用策略。
python
# 5. PCA降维分析
print("\n5. PCA降维分析")
print("-" * 50)
# 执行PCA分析
pca_full = PCA()
pca_result = pca_full.fit_transform(X_scaled)
# 计算累积解释方差
explained_variance = pca_full.explained_variance_ratio_
cumulative_variance = np.cumsum(explained_variance)
# 可视化PCA结果
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 个体解释方差
ax1.bar(range(1, len(explained_variance) + 1), explained_variance)
ax1.set_xlabel('主成分')
ax1.set_ylabel('解释方差比例')
ax1.set_title('各主成分解释方差比例')
ax1.grid(True, alpha=0.3)
# 累积解释方差
ax2.plot(range(1, len(cumulative_variance) + 1), cumulative_variance, 'bo-')
ax2.axhline(y=0.8, color='r', linestyle='--', label='80%')
ax2.axhline(y=0.9, color='g', linestyle='--', label='90%')
ax2.axhline(y=0.95, color='orange', linestyle='--', label='95%')
ax2.set_xlabel('主成分数量')
ax2.set_ylabel('累积解释方差比例')
ax2.set_title('累积解释方差比例')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('pca_variance_analysis.png', dpi=300)
plt.show()
# PCA降维决策
n_features = len(feature_cols)
n_components_80 = np.where(cumulative_variance >= 0.8)[0][0] + 1
n_components_90 = np.where(cumulative_variance >= 0.9)[0][0] + 1
n_components_95 = np.where(cumulative_variance >= 0.95)[0][0] + 1
print(f"原始特征数: {n_features}")
print(f"解释80%方差需要: {n_components_80} 个主成分")
print(f"解释90%方差需要: {n_components_90} 个主成分")
print(f"解释95%方差需要: {n_components_95} 个主成分")
# 降维决策
use_pca = False
if n_features > 10and n_components_90 < n_features * 0.7:
use_pca = True
optimal_components = n_components_90
print(f"\n✓ 建议使用PCA降维,保留{optimal_components}个主成分")
pca = PCA(n_components=optimal_components)
X_final = pd.DataFrame(pca.fit_transform(X_scaled),
columns=[f'PC{i + 1}'for i inrange(optimal_components)])
else:
print(f"\n✓ 不建议使用PCA降维,保持原始特征")
X_final = X_scaled
print(f"最终特征维度: {X_final.shape}")
阶段 11: 数据集划分
在所有预处理步骤完成后,此阶段将最终处理好的数据集划分为训练集(Training Set)和测试集(Test Set)。
作用解释: 这是机器学习中至关重要的一步。
- 训练集:
用于训练模型,让模型从这些数据中学习模式。
- 测试集:
模型在训练过程中从未见过的数据,用于在模型训练完成后,客观、公正地评估模型的泛化能力(即在全新数据上的表现)。
- 分层抽样 (
stratify=y_final):这是一个关键参数。它能确保在划分数据集时,训练集和测试集中目标变量的类别比例与原始数据集中保持一致。这对于分类问题,尤其是不平衡数据集,是必不可少的,可以避免因随机划分导致某个类别在训练集或测试集中缺失或比例失衡。
python
# 6. 数据集划分
print("\n6. 数据集划分")
print("-" * 50)
# 确保 X_final 和 y_final 定义一致
if'X_clean'inlocals() and'y_clean'inlocals():
X_final = X_clean
y_final = y_clean
else:
X_final = X
y_final = y
# 使用分层抽样确保类别分布一致
# 然后再进行划分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X_final, y_final, test_size=0.2, random_state=42, stratify=y_final)
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")
print(f"训练集标签分布: {pd.Series(y_train).value_counts().to_dict()}")
print(f"测试集标签分布: {pd.Series(y_test).value_counts().to_dict()}")
阶段 12: 模型训练与初步评估
这个阶段是整个Pipeline的核心,它定义了多个不同的机器学习模型,并通过一个循环对它们进行逐一的训练和评估。
作用解释: 这个自动化流程旨在通过“海选”的方式快速比较多种算法的性能,而无需为每种算法单独编写训练和评估代码。
- 模型定义:
代码在一个字典中定义了12种常用的分类模型,涵盖了线性模型、树模型、集成模型、SVM、近邻、朴素贝叶斯和神经网络等多种类型。
- 循环训练评估:
- 训练 (
model.fit):每个模型都在相同的训练集上进行训练。
- 预测 (
model.predict):训练好的模型在测试集上进行预测。
- 评估指标:
计算准确率(accuracy)、精确率(precision)、召回率(recall)和F1分数(f1-score)等多个关键分类指标。
- 交叉验证 (
cross_val_score):在训练集上进行5折交叉验证,得到一个更稳健的模型性能估计(
cv_mean和cv_std),这有助于判断模型是否过拟合。
- 训练 (
- 结果存储:
所有的评估结果都被系统地存储在字典中,为后续的比较和可视化做好了准备。
python
# 7. 机器学习模型定义
print("\n7. 机器学习模型定义")
print("-" * 50)
# 定义13种机器学习模型
models = {
'Logistic Regression': LogisticRegression(max_iter=1000),
'SGD Classifier': SGDClassifier(max_iter=1000, tol=1e-3),
'Decision Tree': DecisionTreeClassifier(),
'Random Forest': RandomForestClassifier(n_estimators=100),
'AdaBoost': AdaBoostClassifier(n_estimators=100),
'Extra Trees': ExtraTreesClassifier(n_estimators=100),
'Support Vector Machine': SVC(probability=True),
'Gaussian Naive Bayes': GaussianNB(),
'K-Nearest Neighbors': KNeighborsClassifier(),
'Multi-layer Perceptron': MLPClassifier(max_iter=1000),
'XGBoost': XGBClassifier(use_label_encoder=False, eval_metric='logloss'),
'lightGBM': LGBMClassifier()
}
print(f"定义了{len(models)}种机器学习模型")
# 8. 模型训练和评估
print("\n8. 模型训练和评估")
print("-" * 50)
# 存储结果
results = {}
cv_scores = {}
predictions = {}
# 5折交叉验证
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
print("开始训练和评估模型...")
for name, model in models.items():
print(f"训练 {name}...", end=' ')
try:
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1] ifhasattr(model, 'predict_proba') andlen(
np.unique(y_final)) == 2elseNone
# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
# 交叉验证
cv_score = cross_val_score(model, X_train, y_train, cv=cv, scoring='accuracy')
# 存储结果
results[name] = {
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1_score': f1,
'cv_mean': cv_score.mean(),
'cv_std': cv_score.std()
}
cv_scores[name] = cv_score
predictions[name] = {'y_pred': y_pred, 'y_pred_proba': y_pred_proba}
print("✓")
except Exception as e:
print(f"✗ 错误: {str(e)}")
continue
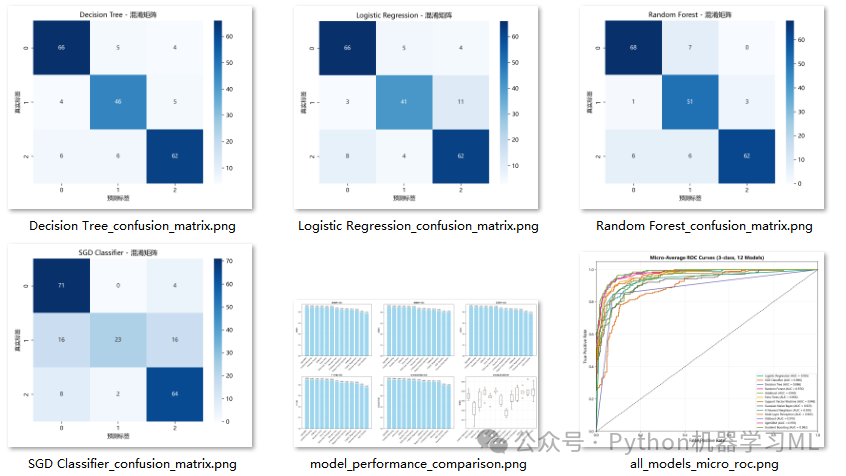
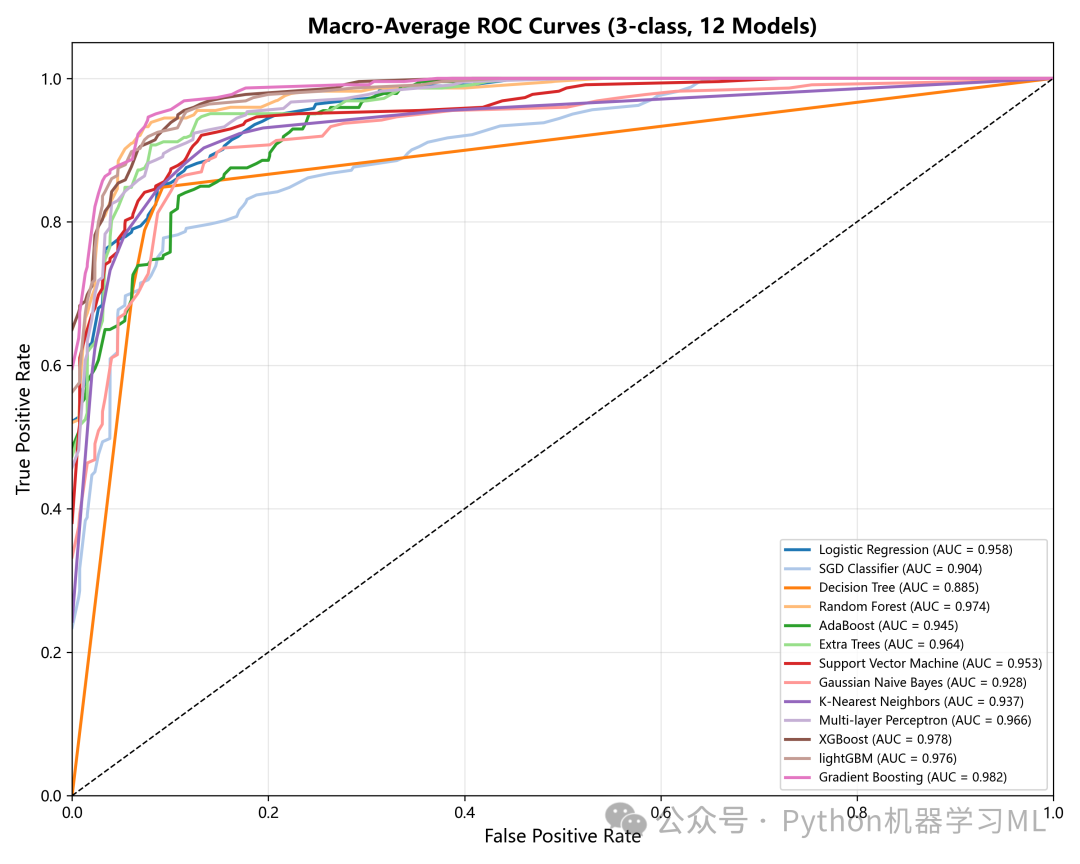
阶段 13: ROC曲线对比分析
这个阶段专门用于为所有能够输出概率或置信度的模型绘制受试者工作特征(ROC)曲线,并计算曲线下面积(AUC)。
作用解释: ROC曲线和AUC是评估分类模型性能,尤其是在不平衡数据集上性能的重要工具。
- ROC曲线:
它展示了在不同分类阈值下,模型的真正类率(True Positive Rate, 召回率)与假正类率(False Positive Rate)之间的权衡关系。曲线越靠近左上角,说明模型性能越好。
- AUC (Area Under Curve):
它是ROC曲线下的面积,取值在0.5到1之间。AUC可以看作是模型将一个随机的正样本排在随机的负样本前面的概率。AUC值越大,模型区分正负样本的能力越强。
- 宏平均(Macro-average)与微平均(Micro-average):
对于多分类问题,代码计算并绘制了两种平均ROC曲线:
- 宏平均:
对每个类别的ROC曲线独立计算,然后取平均。它平等对待每个类别,无论类别大小。
- 微平均:
将所有类别的预测结果汇总在一起计算。它更受大类别的影响。 通过将所有模型的ROC曲线绘制在一张图上,我们可以非常直观地比较它们在不同阈值下的整体分类性能。
- 宏平均:
python
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn.preprocessing import label_binarize
from sklearn.metrics import roc_curve, auc, RocCurveDisplay
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.metrics import (accuracy_score, precision_score, recall_score,
f1_score)
# ------------- 2. 训练所有模型,保存分数 -------------------
print("\n=== 模型训练并缓存预测概率 ===")
y_test_bin = label_binarize(y_final, classes=sorted(y_final.unique()))
n_classes = y_test_bin.shape[1]
# 重新切分(保持与前面一致)
X_train, X_test, y_train, y_test = train_test_split(
X_final, y_final, test_size=0.2, random_state=42, stratify=y_final)
y_test_bin = label_binarize(y_test, classes=sorted(y_final.unique()))
model_scores = {} # 存AUC
model_fpr_tpr = {} # 存曲线 (fpr, tpr)
skip_models = [] # 无法画ROC的模型
for name, model in models.items():
try:
model.fit(X_train, y_train)
# 取得“连续输出”以绘制 ROC
ifhasattr(model, "predict_proba"):
y_score = model.predict_proba(X_test) # shape = (n_samples, n_classes)
elifhasattr(model, "decision_function"):
y_score = model.decision_function(X_test)
# 若 decision_function 只给 (n_samples,),需转成 (n_samples, n_classes)
if y_score.ndim == 1:
# 二分类才会遇到,但为了代码健壮性:
y_score = np.column_stack([-y_score, y_score])
else:
print(f"⚠️ {name} 既无 predict_proba 也无 decision_function,跳过 ROC。")
skip_models.append(name)
continue
# 计算 micro-average & macro-average AUC
fpr = dict()
tpr = dict()
roc_auc = dict()
for i inrange(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test_bin[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# micro
fpr["micro"], tpr["micro"], _ = roc_curve(
y_test_bin.ravel(), y_score.ravel()
)
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
# macro
all_fpr = np.unique(np.concatenate([fpr[i] for i inrange(n_classes)]))
mean_tpr = np.zeros_like(all_fpr)
for i inrange(n_classes):
mean_tpr += np.interp(all_fpr, fpr[i], tpr[i])
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
model_scores[name] = roc_auc
model_fpr_tpr[name] = (fpr, tpr)
print(f"✓ {name} - macro AUC: {roc_auc['macro']:.3f}")
except Exception as e:
print(f"✗ {name} 训练或预测出错: {e}")
skip_models.append(name)
continue
# ------------- 3. 绘制一张大图:macro-average ROC -----------------
print("\n=== 绘制 ROC 曲线 ===")
plt.figure(figsize=(10, 8))
colors = cycle(plt.cm.tab20.colors) # 至少 20 种颜色
for (name, color) inzip(model_scores.keys(), colors):
fpr, tpr = model_fpr_tpr[name]
auc_val = model_scores[name]["macro"]
plt.plot(
fpr["macro"],
tpr["macro"],
color=color,
lw=2,
label=f"{name} (AUC = {auc_val:.3f})"
)
# 对角线
plt.plot([0, 1], [0, 1], "k--", lw=1)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate", fontsize=12)
plt.ylabel("True Positive Rate", fontsize=12)
plt.title("Macro-Average ROC Curves (3-class, 12 Models)", fontsize=14, fontweight="bold")
plt.legend(loc="lower right", fontsize=8)
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig("all_models_macro_roc.png", dpi=300)
plt.show()
# ------------- 4. (可选)再画 micro-average -----------------
plt.figure(figsize=(10, 8))
colors = cycle(plt.cm.Dark2.colors)
for (name, color) inzip(model_scores.keys(), colors):
fpr, tpr = model_fpr_tpr[name]
auc_val = model_scores[name]["micro"]
plt.plot(
fpr["micro"],
tpr["micro"],
color=color,
lw=2,
label=f"{name} (AUC = {auc_val:.3f})"
)
plt.plot([0, 1], [0, 1], "k--", lw=1)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate", fontsize=12)
plt.ylabel("True Positive Rate", fontsize=12)
plt.title("Micro-Average ROC Curves (3-class, 12 Models)", fontsize=14, fontweight="bold")
plt.legend(loc="lower right", fontsize=8)
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig("all_models_micro_roc.png", dpi=300)
plt.show()
# ------------- 5. 简单汇总表 -----------------
print("\n=== 主要 AUC 汇总 (macro / micro) ===")
for name, scores in model_scores.items():
print(f"{name:25s} Macro AUC: {scores['macro']:.3f} | Micro AUC: {scores['micro']:.3f}")
if skip_models:
print("\n⚠️ 以下模型因缺少连续输出而未绘制 ROC:", ", ".join(skip_models))
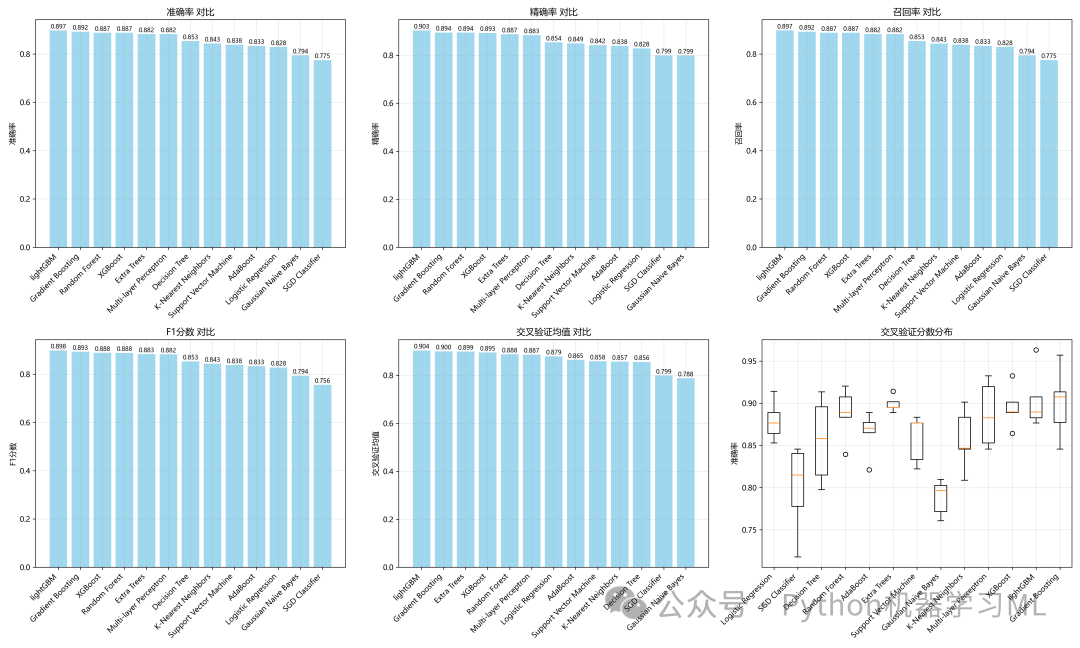
阶段 14: 模型性能可视化对比
这个阶段将阶段12中计算出的所有模型的性能指标,通过表格和图表的形式进行直观的对比。
作用解释: 数值结果虽然精确,但不够直观。可视化的目的是让模型之间的性能优劣一目了然。
- 性能对比表:
首先将所有结果汇总成一个DataFrame,清晰地展示每个模型的各项指标。
- 条形图对比:
为每个核心指标(准确率、精确率、召回率、F1分数、交叉验证均值)分别绘制条形图。通过条形的高度,可以快速识别出在特定指标上表现最好的模型。
- 交叉验证箱线图:
这个图展示了每个模型在5次交叉验证中得分的分布情况。箱体越窄,说明模型性能越稳定;中位线越高,说明平均性能越好。这个图对于评估模型的稳定性非常有帮助。
python
# 9. 结果可视化对比
print("\n9. 模型性能可视化对比")
print("-" * 50)
# 创建结果DataFrame
results_df = pd.DataFrame(results).T
print("\n模型性能对比表:")
print(results_df.round(4))
# 性能对比可视化
fig, axes = plt.subplots(2, 3, figsize=(20, 12))
axes = axes.ravel()
metrics = ['accuracy', 'precision', 'recall', 'f1_score', 'cv_mean']
metric_names = ['准确率', '精确率', '召回率', 'F1分数', '交叉验证均值']
for i, (metric, name) inenumerate(zip(metrics, metric_names)):
if i < len(axes):
data_to_plot = results_df[metric].sort_values(ascending=False)
bars = axes[i].bar(range(len(data_to_plot)), data_to_plot.values, color='skyblue', alpha=0.8)
axes[i].set_title(f'{name} 对比')
axes[i].set_xticks(range(len(data_to_plot)))
axes[i].set_xticklabels(data_to_plot.index, rotation=45, ha='right')
axes[i].set_ylabel(name)
axes[i].grid(True, alpha=0.3)
# 添加数值标签
for j, bar inenumerate(bars):
height = bar.get_height()
axes[i].text(bar.get_x() + bar.get_width() / 2., height + 0.001,
f'{height:.3f}', ha='center', va='bottom', fontsize=8)
# 交叉验证分数箱线图
iflen(cv_scores) > 0:
axes[5].boxplot([cv_scores[name] for name in results.keys()],
labels=[name for name in results.keys()])
axes[5].set_title('交叉验证分数分布')
axes[5].set_xticklabels(results.keys(), rotation=45, ha='right')
axes[5].set_ylabel('准确率')
axes[5].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('model_performance_comparison.png', dpi=300)
plt.show()
阶段 15: 综合排名与最优模型选择
在比较了所有模型的各项性能指标后,这个阶段通过一个加权评分系统来计算一个“综合得分”,并据此选出最优模型。
作用解释: 不同的评估指标各有侧重(如精确率关注“查准”,召回率关注“查全”),单一指标可能无法全面反映模型的好坏。
- 综合得分:
代码为不同的指标分配了权重,然后对每个模型的指标进行归一化处理(消除量纲影响),最后计算加权总分。这提供了一个更全面、更平衡的视角来评判模型的整体性能。
- 最终排名:
基于综合得分对所有模型进行排序,并打印出详细的排名列表。
- 最优模型选择:
排名第一的模型被选为“最优模型”,其名称和核心性能指标被突出显示。这个最优模型将用于后续的详细分析和最终的预测。
python
# 10. 综合排名和最优模型选择
print("\n10. 综合排名和最优模型选择")
print("-" * 50)
# 计算综合得分
weights = {
'accuracy': 0.3,
'precision': 0.2,
'recall': 0.2,
'f1_score': 0.2,
'cv_mean': 0.1
}
results_df['综合得分'] = 0
for metric, weight in weights.items():
# 标准化到0-1范围
normalized = (results_df[metric] - results_df[metric].min()) / (results_df[metric].max() - results_df[metric].min())
results_df['综合得分'] += normalized * weight
# 排序
final_ranking = results_df.sort_values('综合得分', ascending=False)
print("最终模型排名:")
print("=" * 70)
ranking_display = final_ranking[['accuracy', 'precision', 'recall', 'f1_score', 'cv_mean', '综合得分']].round(4)
for i, (name, row) inenumerate(ranking_display.iterrows(), 1):
print(f"{i:2d}. {name:15s} | 综合得分: {row['综合得分']:.4f} | "
f"准确率: {row['accuracy']:.4f} | F1: {row['f1_score']:.4f} | "
f"CV: {row['cv_mean']:.4f}±{final_ranking.loc[name, 'cv_std']:.4f}")
# 选择最优模型
best_model_name = final_ranking.index[0]
best_model = models[best_model_name]
best_predictions = predictions[best_model_name]
print(f"\n🏆 最优模型: {best_model_name}")
print(f" 综合得分: {final_ranking.iloc[0]['综合得分']:.4f}")
print(f" 准确率: {final_ranking.iloc[0]['accuracy']:.4f}")
print(f" F1分数: {final_ranking.iloc[0]['f1_score']:.4f}")
阶段 16: 模型详细分析与最终输出
这是整个Pipeline的收尾阶段。它对所有模型(特别是最优模型)在测试集上的表现进行更深入的分析,并生成最终的预测结果。
作用解释:
- 混淆矩阵:
代码为每一种模型都生成并可视化了其在测试集上的混淆矩阵。混淆矩阵是分析分类模型错误类型的核心工具,它清晰地显示了模型将哪个类别错分成了哪个类别,帮助我们理解模型的“盲点”。
- 测试集预测结果:
最后,代码使用选出的最优模型对测试集进行最终预测,并将真实标签、预测标签以及每个类别的预测概率保存到一个DataFrame中。这个表格是模型最终交付的成果之一,可以用于业务评估或部署上线。
- 总结打印:
打印清晰的完成信息,标志着整个自动化流程的结束。
python
# 11. 模型详细分析
print("\n11. 模型详细分析")
print("-" * 50)
#12种模型中的混淆矩阵
for name in results.keys():
y_pred = predictions[name]['y_pred']
y_pred_proba = predictions[name]['y_pred_proba']
print(f"\n🔍 {name} 模型详细分析")
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(6, 5))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title(f'{name} - 混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.tight_layout()
plt.savefig(f'{name}_confusion_matrix.png', dpi=300)
plt.show()
print("\n" + "=" * 80)
print("🎉 完整的机器学习Pipeline已完成!")
print("🔍 包含EDA分析 → 数据预处理 → 模型对比 → 结果分析")
print("📊 生成了详细的可视化图表和分析报告")
print("=" * 80)
#测试集预测结果,计算各个类别概率
y_test_pred = best_model.predict(X_test)
y_test_pred_proba = best_model.predict_proba(X_test) ifhasattr(best_model, 'predict_proba') elseNone
test_results_df = pd.DataFrame({
'真实标签': y_test,
'预测标签': y_test_pred
})
if y_test_pred_proba isnotNone:
for i inrange(y_test_pred_proba.shape[1]):
test_results_df[f'类别_{i}_概率'] = y_test_pred_proba[:, i]
print("\n测试集预测结果示例:")
print(test_results_df.head())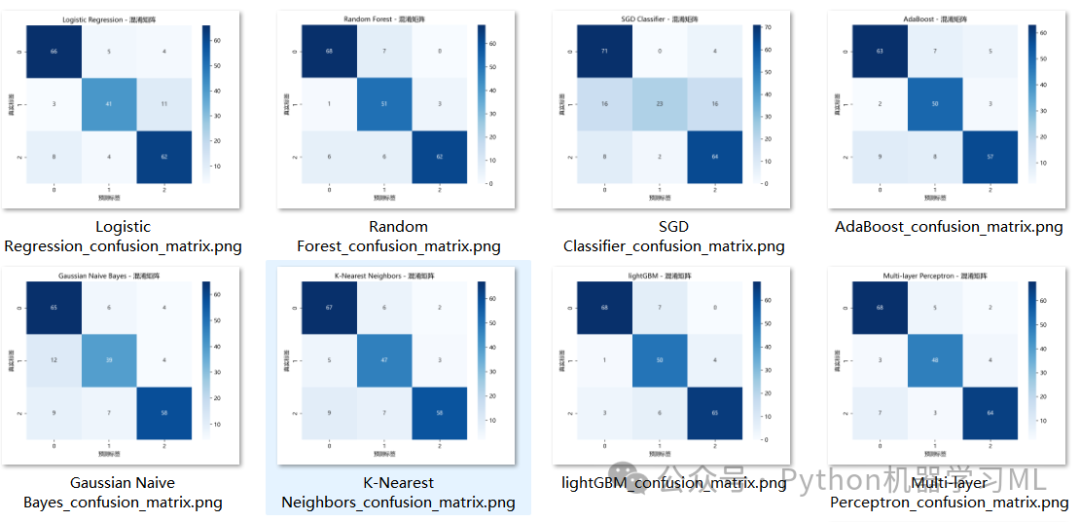
阶段 17: 模型训练与SHAP值初始化
这个阶段对之前的模型训练部分进行了重要升级。它不再使用LightGBM的默认参数,而是引入了强大的超参数优化框架Optuna,通过贝叶斯优化来系统地寻找LightGBM模型的最佳参数组合,以最大化其性能。
作用解释: 模型的性能高度依赖于其超参数(Hyperparameters,即模型的“设置”)。手动调整这些参数费时费力且效率低下。此阶段通过自动化流程来解决这个问题:
- 定义目标函数 (
objective):这个函数是优化的核心。它定义了“好”模型的标准:对于
Optuna提供的每一组参数组合(trial),该函数都会创建一个LightGBM模型,并在训练集上进行5折交叉验证,最终返回平均准确率。Optuna的目标就是让这个返回值最大化。 - 创建并运行优化 (
study.optimize):Optuna会创建一个“研究”(study),并智能地尝试50组不同的参数组合(n_trials=50)。它会根据前几次尝试的结果,来决定下一次应该尝试哪些更有潜力的参数,这个过程比随机搜索更高效。 - 使用最佳参数训练最终模型:
在找到能获得最高交叉验证分数的最佳参数组合后,代码会使用这套“黄金参数”在全部训练数据上训练一个最终的、性能最优的LightGBM模型。
- 性能评估:
最后,用优化后的模型在训练集和测试集上评估准确率,以验证优化效果。
这个经过精心优化的模型,将作为后续所有SHAP可解释性分析的基础,确保我们的分析是基于一个性能最强的模型进行的。
python
# SHAP可视化 - 使用LightGBM模型
# 训练模型
import shap
import lightgbm as lgb
import optuna
from sklearn.model_selection import cross_val_score
import numpy as np
# 定义目标函数
defobjective(trial):
params = {
'n_estimators': trial.suggest_int('n_estimators', 50, 300),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.3),
'num_leaves': trial.suggest_int('num_leaves', 10, 100),
'max_depth': trial.suggest_int('max_depth', 3, 15),
'subsample': trial.suggest_float('subsample', 0.6, 1.0),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.6, 1.0),
'reg_alpha': trial.suggest_float('reg_alpha', 0.0, 10.0),
'reg_lambda': trial.suggest_float('reg_lambda', 0.0, 10.0),
'min_child_samples': trial.suggest_int('min_child_samples', 10, 100),
'random_state': 42,
'n_jobs': -1,
'verbose': -1
}
model = lgb.LGBMClassifier(**params)
scores = cross_val_score(model, X_train, y_train, cv=5, scoring='accuracy')
return np.mean(scores)
print("开始贝叶斯优化...")
# 创建study并优化
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)
print(f"最佳交叉验证分数: {study.best_value:.4f}")
print("最佳参数:")
for param, value in study.best_params.items():
print(f" {param}: {value}")
# 使用最佳参数训练最终模型
model = lgb.LGBMClassifier(**study.best_params, random_state=42, n_jobs=-1, verbose=-1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print(f"\n使用优化后参数的结果:")
print(f"训练集准确率: {train_score:.4f}")
print(f"测试集准确率: {test_score:.4f}")
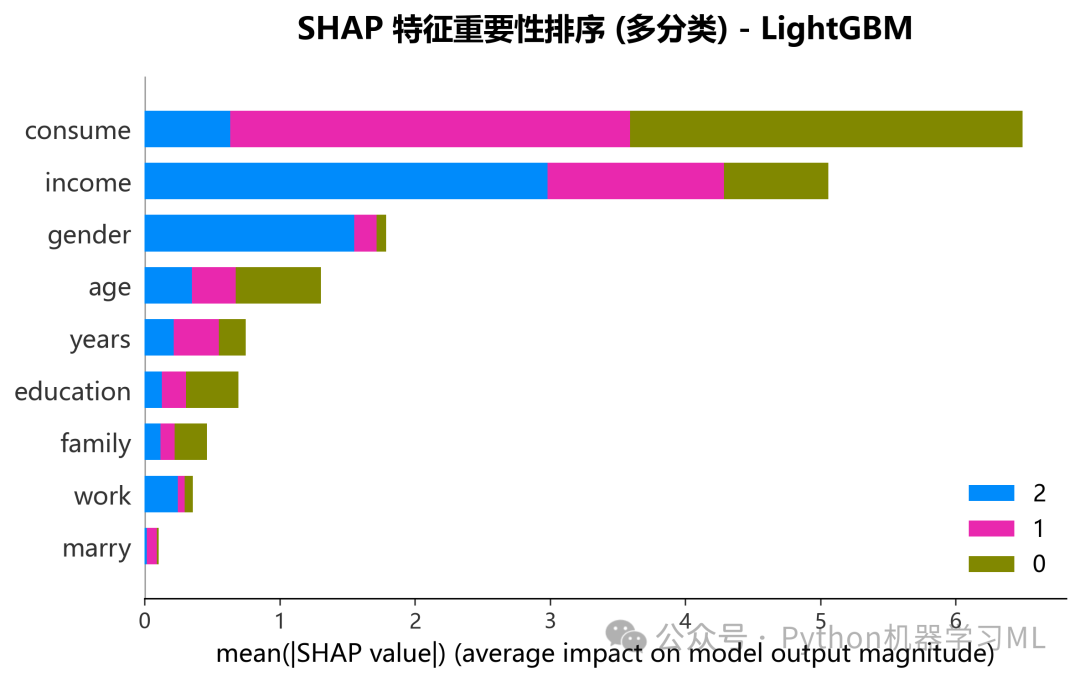
阶段 18: 全局特征重要性分析 (多分类条形图)
这个阶段生成第一张SHAP可视化图:多分类条形图(Bar Plot)。
作用解释: 这张图从全局视角展示了每个特征对所有类别的平均影响大小。图中,每个特征对应一组条形,每个条形代表该特征对一个特定类别的平均绝对SHAP值。通过这张图,我们可以快速回答:
-
哪些特征在总体上是最重要的?
-
某个重要特征主要是对哪个(或哪些)类别有最大的影响?
它提供了一个宏观的、跨类别的特征重要性概览。
python
# 现在可以正确绘制Bar Plot
plt.figure(figsize=(12, 8))
shap.summary_plot(shap_values_list, X_test,
plot_type="bar",
feature_names=feature_cols,
class_names=class_names if'class_names'inlocals() else [f'Class_{i}'for i inrange(3)],
show=False)
plt.title('SHAP 特征重要性排序 (多分类) - LightGBM', fontsize=16, fontweight='bold', pad=20)
plt.tight_layout()
plt.savefig('shap_bar_plot_lightgbm.png', dpi=300, bbox_inches='tight')
plt.show()
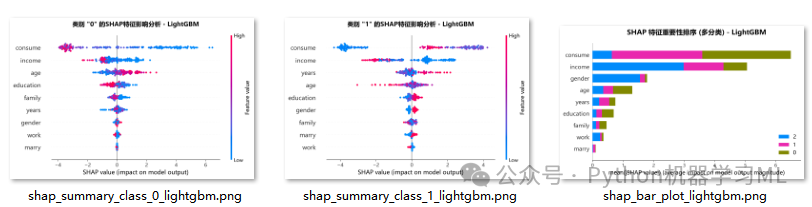
阶段 19: 各类别独立的特征影响分析 (Summary Plot)
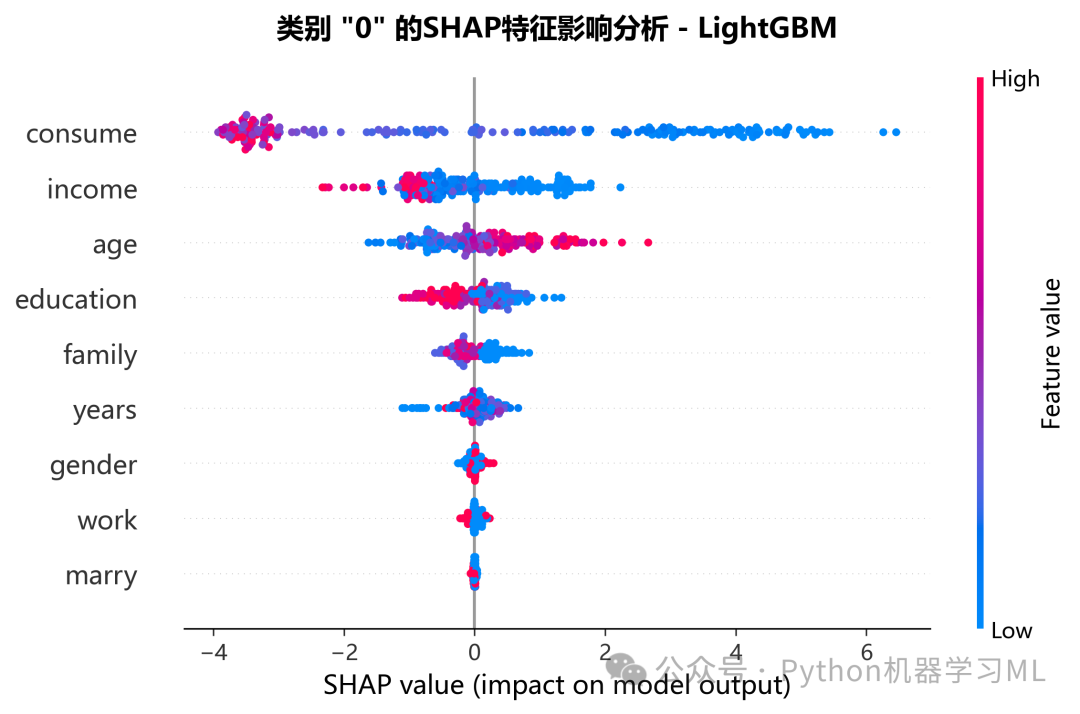
此阶段为每个类别单独生成一张SHAP摘要图(Summary Plot / Dot Plot)。
作用解释: 与上一张图不同,摘要图提供了更丰富的信息。它不再是简单的平均值,而是展示了每个样本的SHAP值。
- 点的含义:
图中每个点代表一个样本。
- x轴位置:
点在x轴的位置表示该特征对该样本的SHAP值(正表示推高该类别的概率,负表示拉低)。
- 颜色:
点的颜色表示该特征在样本中的原始值大小(通常红色表示高值,蓝色表示低值)。
通过为每个类别单独绘制此图,我们可以深入理解:
- 对于特定类别,特征值的高低如何影响预测?
(例如,“age”值越高,是增加还是减少了被预测为“类别1”的概率?)
- 特征影响的分布情况
,而不仅仅是平均影响。
python
# 为每个类别单独绘制Summary Plot
class_names_display = class_names if'class_names'inlocals() else [f'Class_{i}'for i inrange(3)]
for i inrange(3):
plt.figure(figsize=(10, 8))
shap.summary_plot(shap_values_list[i], X_test,
feature_names=feature_cols,
show=False,
max_display=10)
plt.title(f'类别 "{class_names_display[i]}" 的SHAP特征影响分析 - LightGBM',
fontsize=14, fontweight='bold', pad=20)
plt.tight_layout()
plt.savefig(f'shap_summary_class_{i}_lightgbm.png', dpi=300, bbox_inches='tight')
plt.show()
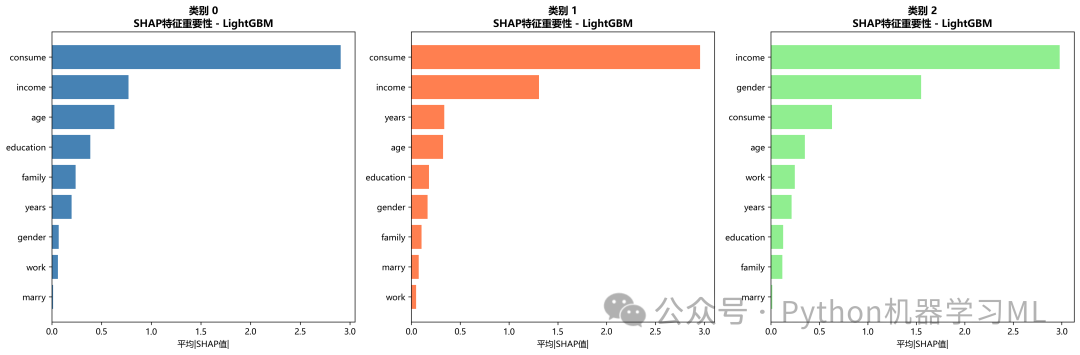
阶段 20: 各类别独立的特征重要性排序 (Bar Plot)
这个阶段再次为每个类别绘制特征重要性,但这次使用的是更简洁的水平条形图。
作用解释: 这是一种更聚焦、更清晰地展示单个类别内特征重要性排序的方式。它只关心“影响大小”(平均绝对SHAP值),而不像Summary Plot那样展示影响方向和分布。通过并排比较这几张图,我们可以非常清楚地看到,对于不同的目标类别,模型所依赖的特征集合和它们的相对重要性是否发生了变化。
python
# SHAP Feature Importance by Class - 每个类别的特征重要性
print("\nSHAP Feature Importance by Class - 每个类别的特征重要性")
# 计算每个类别的平均绝对SHAP值
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
colors = ['steelblue', 'coral', 'lightgreen']
for i inrange(3):
# 计算该类别的特征重要性
class_importance = np.mean(np.abs(shap_values_list[i]), axis=0)
importance_df = pd.DataFrame({
'feature': feature_cols,
'importance': class_importance
}).sort_values('importance', ascending=True)
axes[i].barh(importance_df['feature'], importance_df['importance'],
color=colors[i])
axes[i].set_title(f'类别 {class_names_display[i]}\nSHAP特征重要性 - LightGBM',
fontsize=12, fontweight='bold')
axes[i].set_xlabel('平均|SHAP值|')
plt.tight_layout()
plt.savefig('shap_importance_by_class_lightgbm.png', dpi=300, bbox_inches='tight')
plt.show()
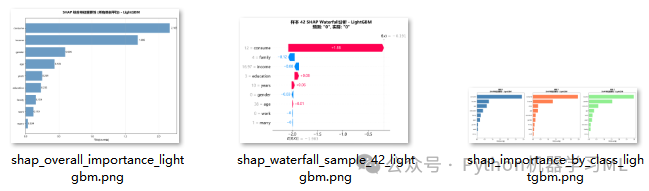
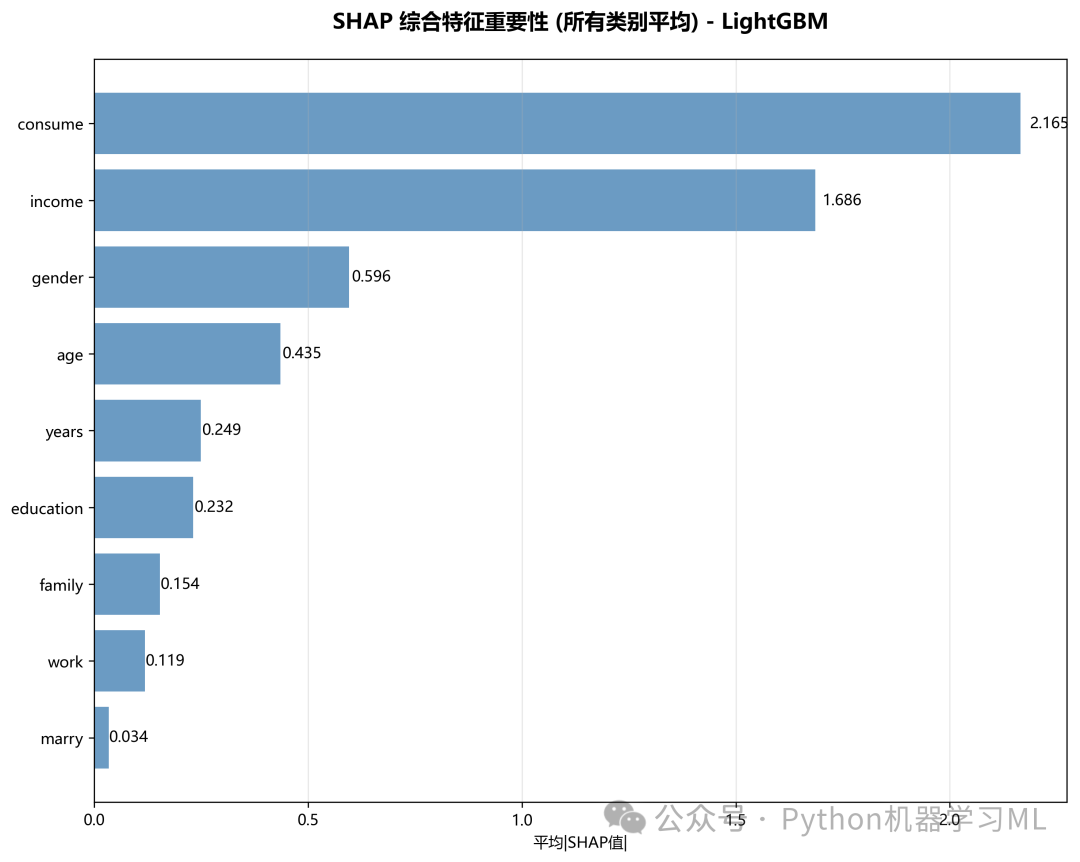
阶段 21: 综合特征重要性排序
此阶段将所有类别的重要性进行平均,生成一张最终的、综合的特征重要性排序图。
作用解释: 这张图回答了一个最常见的问题:“总的来说,哪个特征对模型预测最重要?”。它通过对每个特征在所有类别中的平均绝对SHAP值再取平均,得到了一个不受特定类别偏好的、最能代表全局重要性的排序。这通常是向非技术人员解释模型时最有用的图表之一。
# SHAP Overall Feature Importance - 综合特征重要性
print("\nSHAP Overall Feature Importance - 综合特征重要性")
# 计算所有类别的平均特征重要性
overall_importance = np.mean([np.mean(np.abs(shap_values_list[i]), axis=0)
for i inrange(3)], axis=0)
importance_df = pd.DataFrame({
'feature': feature_cols,
'importance': overall_importance
}).sort_values('importance', ascending=True)
plt.figure(figsize=(10, 8))
bars = plt.barh(importance_df['feature'], importance_df['importance'],
color='steelblue', alpha=0.8)
plt.title('SHAP 综合特征重要性 (所有类别平均) - LightGBM', fontsize=14, fontweight='bold', pad=20)
plt.xlabel('平均|SHAP值|')
plt.grid(axis='x', alpha=0.3)
# 添加数值标签
for i, bar inenumerate(bars):
width = bar.get_width()
plt.text(width + width * 0.01, bar.get_y() + bar.get_height() / 2,
f'{width:.3f}', ha='left', va='center', fontsize=10)
plt.tight_layout()
plt.savefig('shap_overall_importance_lightgbm.png', dpi=300, bbox_inches='tight')
plt.show()
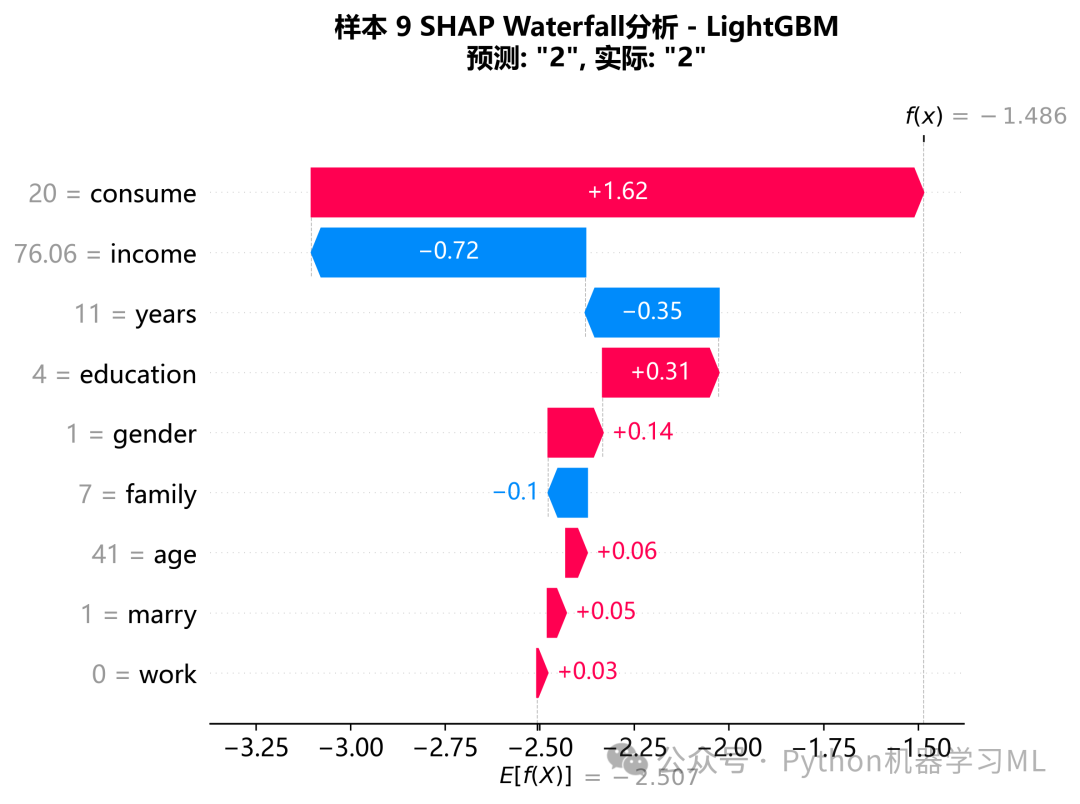
阶段 22: 逐样本预测分析 (Waterfall Plot)
在宏观分析之后,此阶段深入到微观层面,随机挑选几个样本,并使用瀑布图来详细解释它们的预测过程。
作用解释: 瀑布图是解释单个预测最精确的工具。它展示了从模型的基准值(所有样本的平均预测概率)开始,每个特征是如何一步步将预测值“推高”(红色)或“拉低”(蓝色),最终得到该样本的最终预测得分。通过分析几个典型样本(例如,正确预测的和错误预测的),我们可以获得对模型在具体案例中如何决策的深刻理解。
# SHAP Waterfall Plot - 逐样本分析
# 随机选择几个不同预测结果的样本进行分析
print("\nSHAP Waterfall Plot - 逐样本分析")
import random
random.seed(42)
# 随机选择几个不同预测结果的样本
sample_indices = []
for class_i inrange(3):
class_samples = np.where(y_pred == class_i)[0]
iflen(class_samples) > 0:
sample_indices.extend(random.sample(class_samples.tolist(), min(2, len(class_samples))))
print(f"选择的样本索引: {sample_indices}")
for sample_idx in sample_indices[:6]: # 最多分析6个样本
if sample_idx < len(X_test):
pred_class = y_pred[sample_idx]
actual_class = y_test.iloc[sample_idx] # 使用 .iloc 按位置访问
plt.figure(figsize=(12, 8))
# 创建waterfall plot
shap.waterfall_plot(
shap.Explanation(
values=shap_values_list[pred_class][sample_idx],
base_values=explainer.expected_value[pred_class],
data=X_test.iloc[sample_idx].values,
feature_names=feature_cols
),
show=False
)
class_names_display = class_names if'class_names'inlocals() else [f'Class_{i}'for i inrange(3)]
plt.title(
f'样本 {sample_idx + 1} SHAP Waterfall分析 - LightGBM\n预测: "{class_names_display[pred_class]}", 实际: "{class_names_display[actual_class]}"',
fontsize=14, fontweight='bold', pad=20)
plt.tight_layout()
plt.savefig(f'shap_waterfall_sample_{sample_idx + 1}_lightgbm.png', dpi=300, bbox_inches='tight')
plt.show()
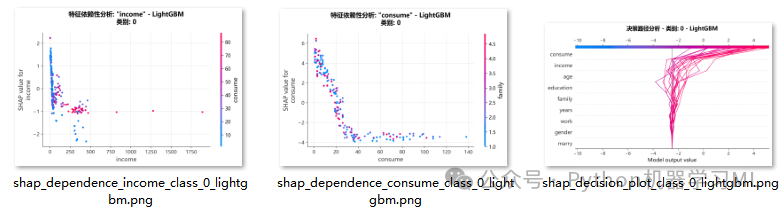
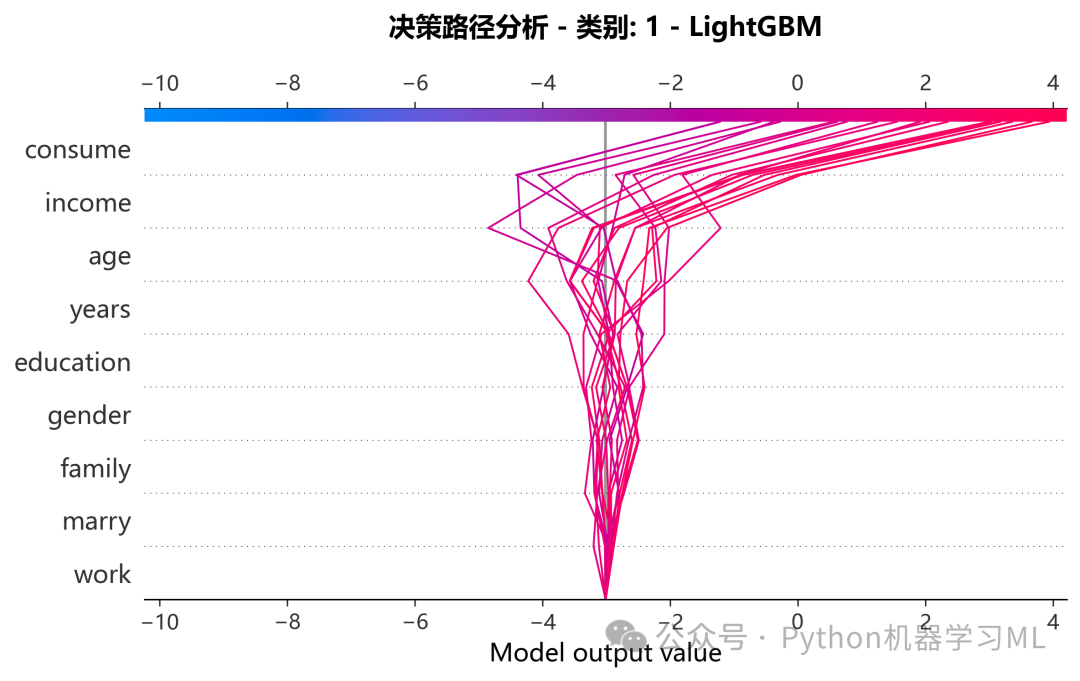
阶段 23: 预测决策路径分析 (Decision Plot)
此阶段使用决策图来可视化多个样本的预测路径。
作用解释: 决策图可以看作是瀑布图的“多样本”版本。图中的每一条线都代表一个样本。它从底部的基准值开始,随着特征自下而上地加入,线条会根据每个特征的SHAP值向左(负贡献)或向右(正贡献)弯曲,最终汇集到顶部的最终预测值。通过为每个类别绘制一张决策图,我们可以观察到:
- 对于同一个类别,模型的决策路径是否相似?
(线条是否聚集在一起并以相似的方式弯曲?)
- 哪些特征是导致样本间预测差异的主要因素?
(线条在哪个特征处开始发散?)
# SHAP Decision Plot - 决策图 - 显示决策过程
# 选择每个类别的一些代表性样本
print("\nSHAP Decision Plot - 决策图 - 显示决策过程")
samples_per_class = 20
decision_samples = []
for class_i inrange(3):
class_samples = np.where(y_pred == class_i)[0]
iflen(class_samples) > 0:
selected = np.random.choice(class_samples,
min(samples_per_class, len(class_samples)),
replace=False)
decision_samples.extend(selected)
decision_samples = sorted(decision_samples)[:60] # 最多60个样本
for class_i inrange(3):
# 选择该类别的样本
class_samples_for_decision = [idx for idx in decision_samples if y_pred[idx] == class_i][:20]
iflen(class_samples_for_decision) > 0:
plt.figure(figsize=(12, 8))
shap.decision_plot(
explainer.expected_value[class_i],
shap_values_list[class_i][class_samples_for_decision],
X_test.iloc[class_samples_for_decision],
feature_names=feature_cols,
show=False
)
class_names_display = class_names if'class_names'inlocals() else [f'Class_{i}'for i inrange(3)]
plt.title(f'决策路径分析 - 类别: {class_names_display[class_i]} - LightGBM',
fontsize=14, fontweight='bold', pad=20)
plt.tight_layout()
plt.savefig(f'shap_decision_plot_class_{class_i}_lightgbm.png', dpi=300, bbox_inches='tight')
plt.show()
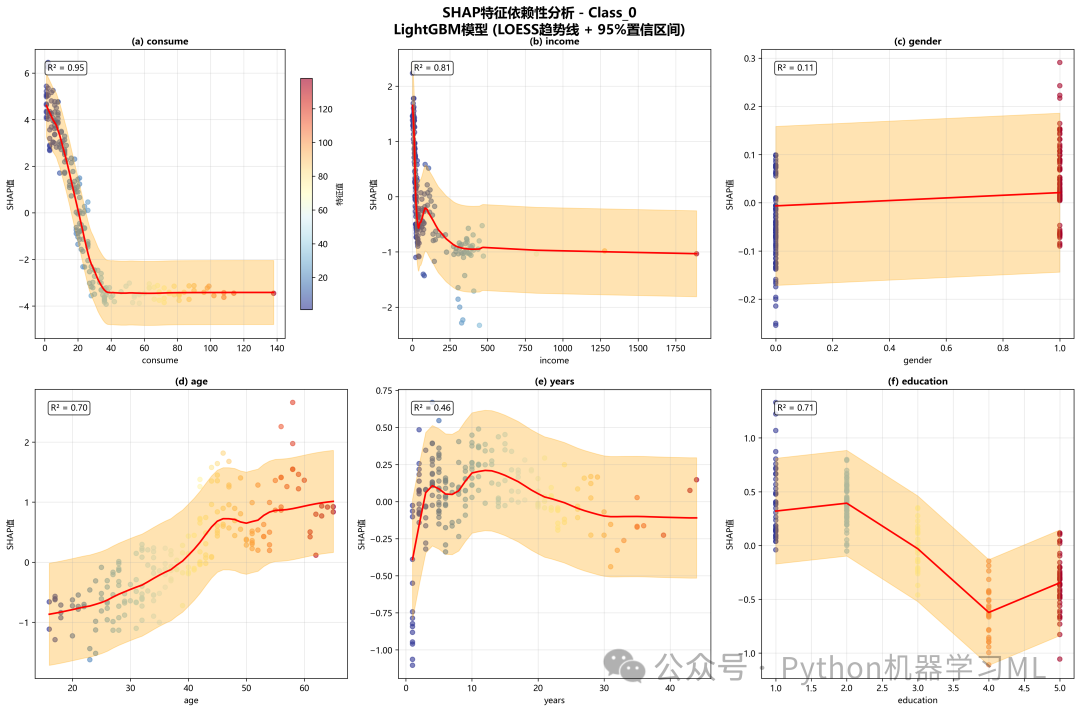
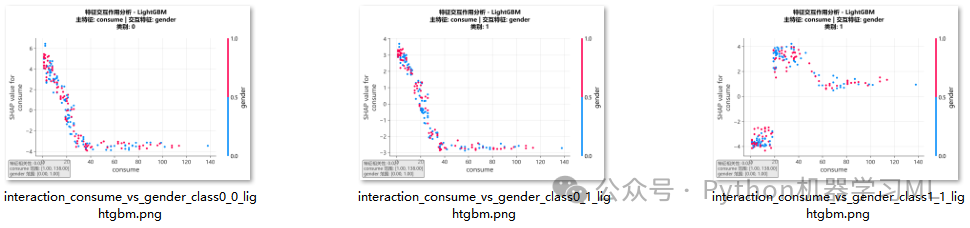
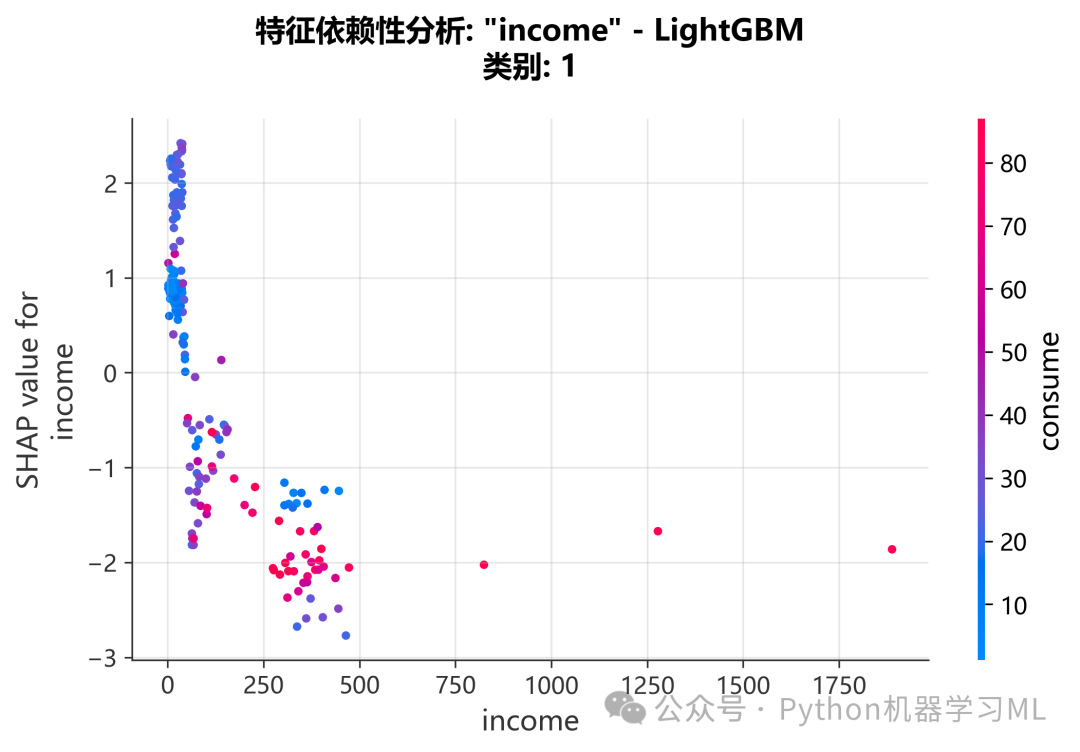
阶段 24: 特征依赖与交互分析
这是SHAP分析中最深入的部分,旨在揭示特征之间的复杂关系。它包括依赖图(Dependence Plot)和交互图(Interaction Plot)。
作用解释:
- 依赖图 (
shap.dependence_plot):- 基础依赖图:
x轴是某个特征的值,y轴是该特征的SHAP值。它展示了特征值的变化如何影响其对模型预测的贡献,帮助我们发现非线性关系和阈值效应。
- 交互图:
这是依赖图的增强版。散点的颜色不再是固定的,而是由另一个“交互特征”的值决定。通过观察颜色分布,我们可以判断主特征的影响是否会受到交互特征的影响。例如,当年齡(主特征)相同时,收入(交互特征)的高低是否会改变年齡对预测的贡献?
- 基础依赖图:
- 高级依赖图 (带LOESS拟合)(此部分代码文章内未给出):
代码还实现了一个更高级的版本,它在散点图的基础上增加了:
- LOESS趋势线:
平滑地拟合出SHAP值随特征值变化的平均趋势。
- 置信区间:
显示趋势线的统计可靠性。
- R²值:
量化趋势线对数据变化的解释程度。
- LOESS趋势线:
- 批量分析:
代码系统地为最重要的几个特征及其交互对生成了这些图,从而全面地探索模型学到的复杂模式。
# Force Plot - 展示模型如何得出预测结果
print("=== SHAP Force Plot 分析 ===")
if'feature_cols'inlocals() andlen(feature_cols) == 8:
print("使用 feature_cols 对齐数据...")
X_test_aligned = X_test[feature_cols].copy()
print(f"对齐后 X_test 形状: {X_test_aligned.shape}")
else:
print("跳过对齐,使用原始 X_test")
X_test_aligned = X_test.copy()
# dependence_plot
print("=== SHAP Dependence Plot - 特征依赖性分析 ===")
# 计算特征重要性
overall_importance = np.mean([np.mean(np.abs(shap_values_list[i]), axis=0)
for i inrange(3)], axis=0)
importance_ranking = np.argsort(overall_importance)[::-1] # 降序排列
top_features_idx = importance_ranking[:5] # 选择前5个最重要的特征
print(f"分析的主要特征: {[feature_cols[i] for i in top_features_idx]}")
# 确保使用正确的测试数据
X_test_for_plot = X_test_reset if'X_test_reset'inlocals() else X_test.reset_index(drop=True)
# 为每个主要类别和主要特征绘制依赖图
for class_i inrange(3):
class_names_display = class_names if'class_names'inlocals() else [f'Class_{i}'for i inrange(3)]
for feature_idx in top_features_idx[:3]: # 每个类别分析前3个特征
feature_name = feature_cols[feature_idx]
try:
plt.figure(figsize=(10, 6))
shap.dependence_plot(
feature_idx,
shap_values_list[class_i],
X_test_for_plot,
feature_names=feature_cols,
show=False
)
plt.title(f'特征依赖性分析: "{feature_name}" - LightGBM\n类别: {class_names_display[class_i]}',
fontsize=14, fontweight='bold', pad=20)
# 添加网格和样式改进
plt.grid(True, alpha=0.3)
# 清理文件名
clean_feature_name = clean_filename(feature_name)
clean_class_name = clean_filename(str(class_names_display[class_i]))
filename = f'shap_dependence_{clean_feature_name}_class_{clean_class_name}_lightgbm.png'
plt.tight_layout()
plt.savefig(filename, dpi=300, bbox_inches='tight')
plt.show()
print(f"完成: {feature_name} - 类别 {class_names_display[class_i]}")
except Exception as e:
print(f"绘制失败: {feature_name} - 类别 {class_i}, 错误: {e}")
plt.close()
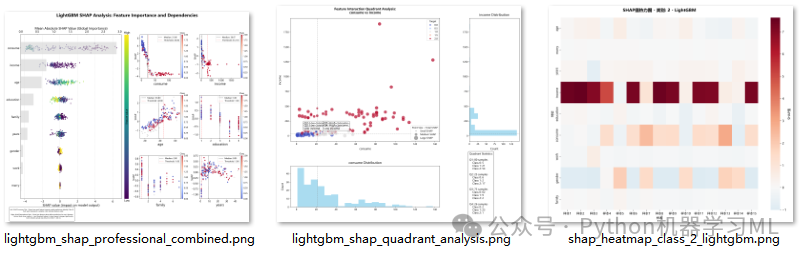
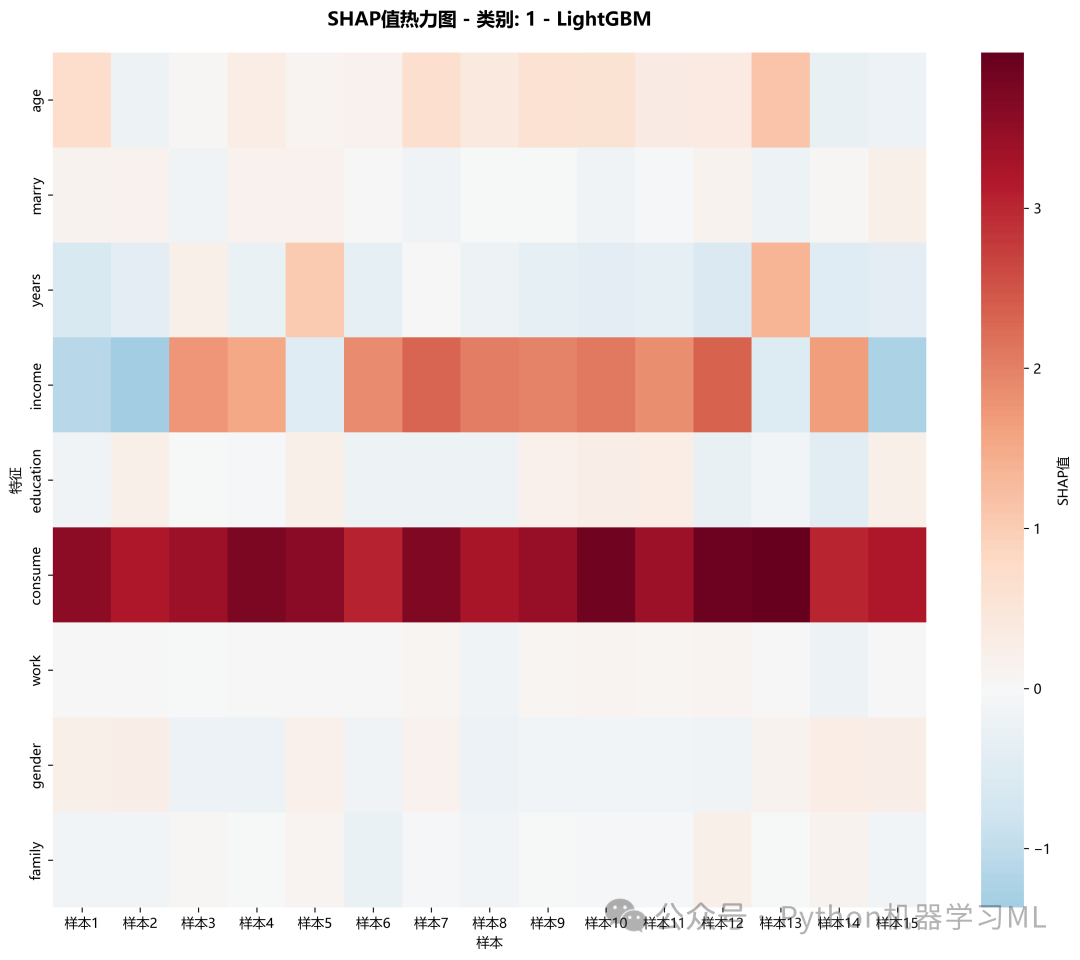
阶段 25: 样本-特征模式分析 (Heatmap)
此阶段为每个类别生成SHAP热力图,用于识别样本和特征之间的模式。
作用解释: 热力图的x轴是样本,y轴是特征,单元格颜色代表SHAP值。与之前的热力图不同,这里是为每个类别单独生成一张,并且样本是按照类别进行分组的。这可以帮助我们发现:
- 类内一致性:
对于某个特定类别的样本,模型是否依赖于相似的特征组合来做出判断?(即,某一列或几列的颜色模式是否在多行中重复出现?)
- 特征的区分能力:
某个特征是否对所有属于该类别的样本都有一致的正向或负向影响?
# SHAP Heatmap - 显示样本和特征的SHAP值模式
# 选择每个类别的一些样本
heatmap_samples = []
samples_per_class_heatmap = 15
for class_i inrange(3):
class_samples = np.where(y_pred == class_i)[0]
iflen(class_samples) > 0:
selected = np.random.choice(class_samples,
min(samples_per_class_heatmap, len(class_samples)),
replace=False)
heatmap_samples.extend([(idx, class_i) for idx in selected])
# 按类别排序
heatmap_samples.sort(key=lambda x: x[1])
sample_indices_heatmap = [x[0] for x in heatmap_samples]
for class_i inrange(3):
class_sample_indices = [idx for idx, cls in heatmap_samples if cls == class_i]
iflen(class_sample_indices) > 0:
plt.figure(figsize=(12, 10))
# 创建热力图数据
shap_data = shap_values_list[class_i][class_sample_indices]
# 使用seaborn创建热力图
sns.heatmap(shap_data.T,
xticklabels=[f'样本{i + 1}'for i inrange(len(class_sample_indices))],
yticklabels=feature_cols,
cmap='RdBu_r',
center=0,
cbar_kws={'label': 'SHAP值'})
class_names_display = class_names if'class_names'inlocals() else [f'Class_{i}'for i inrange(3)]
plt.title(f'SHAP值热力图 - 类别: {class_names_display[class_i]} - LightGBM',
fontsize=14, fontweight='bold', pad=20)
plt.xlabel('样本')
plt.ylabel('特征')
plt.tight_layout()
plt.savefig(f'shap_heatmap_class_{class_i}_lightgbm.png', dpi=300, bbox_inches='tight')
plt.show()
else:
print(f"✗ 类别 {class_i} 没有样本,跳过热力图绘制")
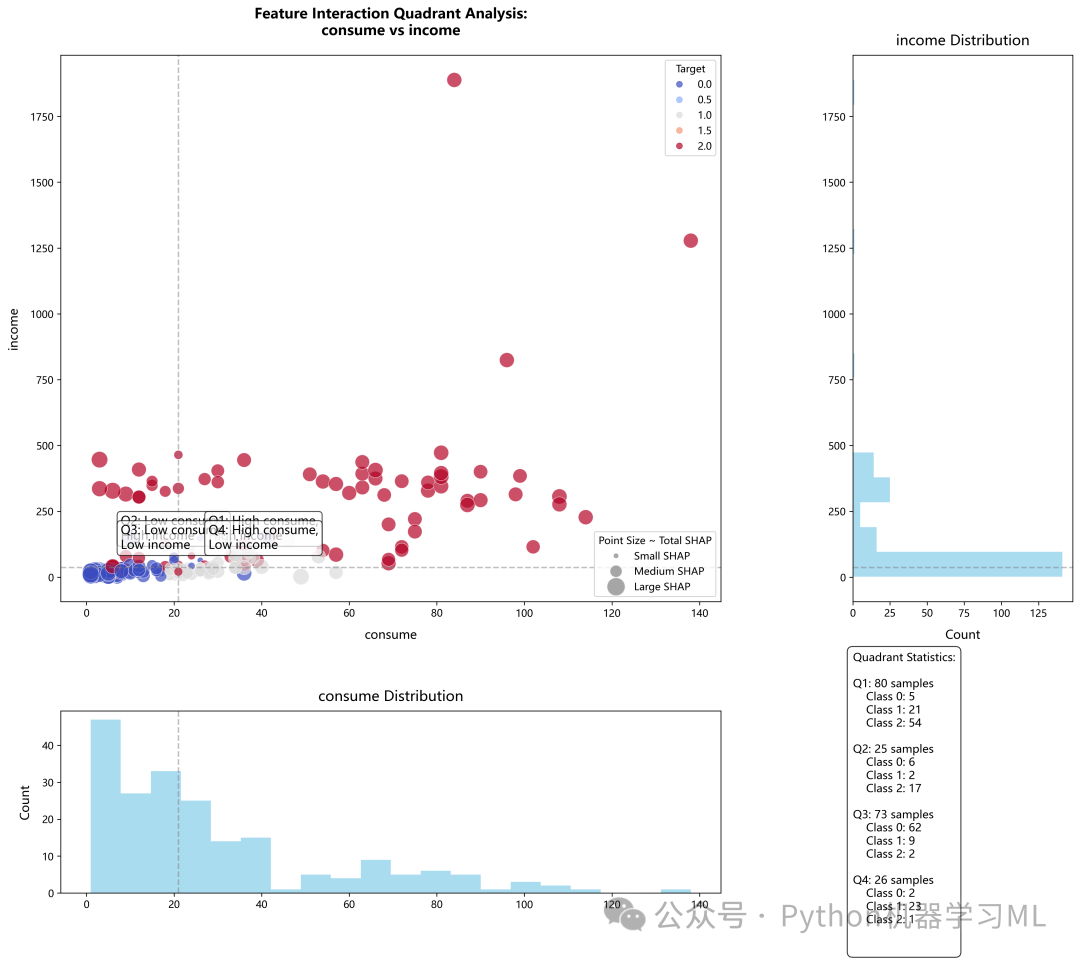
阶段 26: 改进的SHAP四象限分析(此部分代码文章内未给出)
这是一个自定义的高级可视化阶段,它将最重要的两个特征的关系、它们对模型的影响以及数据分布整合在一张信息密度极高的图中。
作用解释: 这张图通过四象限法来分析两个最重要特征的交互作用:
- 主散点图:
x轴和y轴分别是两个最重要特征的原始值。点的大小代表这两个特征对预测的总贡献(SHAP绝对值之和),点的颜色代表样本的真实类别。
- 象限划分:
图被两条中位线划分为四个象限(例如,Q1: 特征1高 & 特征2高)。
- 边缘直方图:
主图的底部和右侧分别显示了两个特征的分布直方图。
- 统计信息:
右下角的小框内量化了每个象限中的样本数量和类别分布。
通过这张图,我们可以直观地看出不同特征值组合的区域(象限)主要对应哪个目标类别,以及在哪个区域内模型预测的“信心”(点的大小)最强。
阶段 27: 专业级SHAP组合可视化(此部分代码文章内未给出)
这是整个分析的压轴部分,旨在生成一张“出版级别”的、高度集成的组合图,将全局特征重要性分析和局部特征依赖性分析完美地结合在一起。
作用解释: 这张图被设计成一个信息仪表盘,旨在用一张图全面展示SHAP分析的核心发现:
- 左侧 (全局分析):
- SHAP摘要图:
与阶段19类似,但通过自定义绘图,将背景的平均重要性条形图(灰色)和前景的SHAP值散点图叠加在一起,实现了信息的高度整合。
- SHAP摘要图:
- 右侧 (局部分析):
- SHAP依赖图矩阵:
选取最重要的6个特征,以2x3的网格形式展示它们的依赖图。
- 阈值自动标注:
每张依赖图上都自动计算并标注了中位数和“拐点”(趋势变化最显著的点),为解读特征效应提供了关键参考点。
- SHAP依赖图矩阵:
- 统一的美学设计:
整个图表使用了统一的颜色、字体和布局参数,使其看起来非常专业和协调。
- 解释性文本:
图表底部还添加了对左右两部分内容的解释,方便读者理解。
这张图是整个SHAP分析的精华,浓缩了最重要的全局和局部洞察,非常适合用于最终的报告或展示。
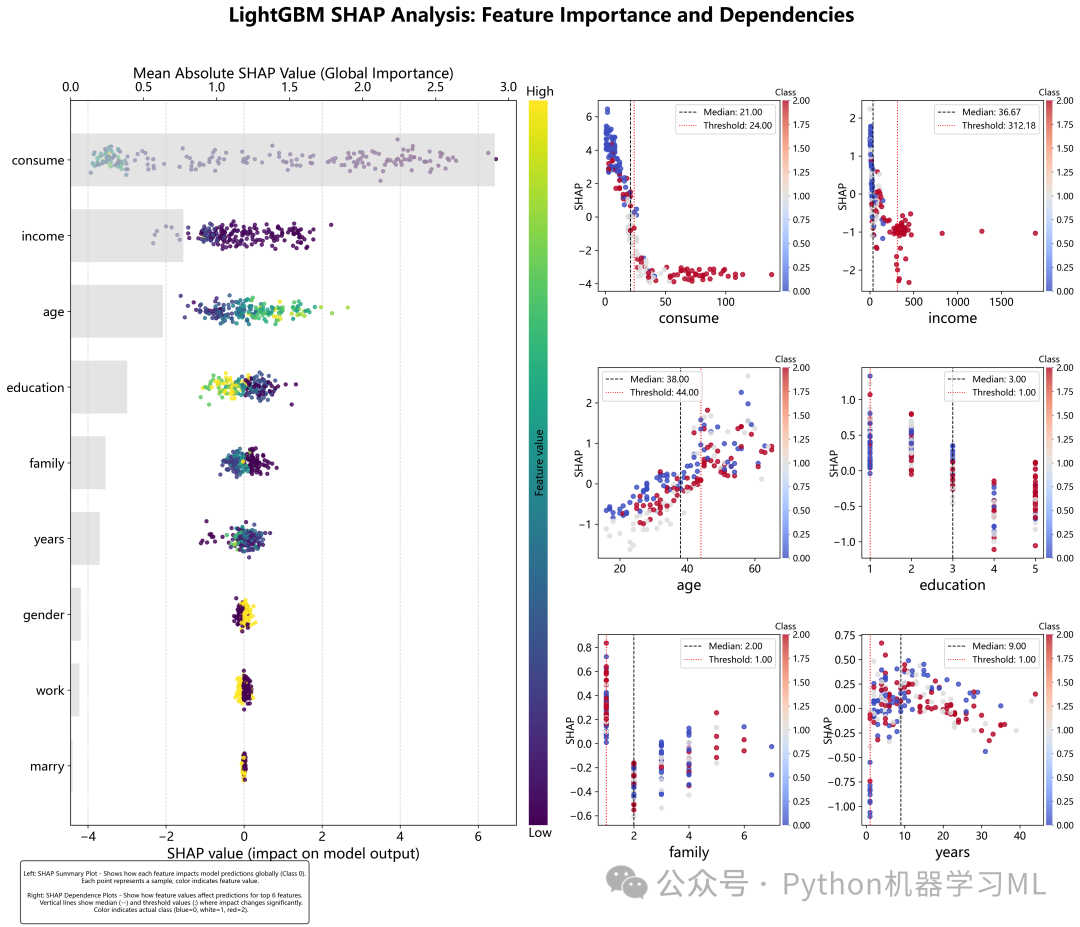
该文章案例

数据请加微信免费获取。
注:本代码全程Python语言实现,拿到代码后,先用示例数据复现跑通,确认环境没问题后,再上自己的数据。
【数据,请加微信免费获取】
如果你对类似于这样的文章感兴趣。
欢迎关注、点赞、转发~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)