《白话机器学习的数学》阅读笔记
第一章 开始二人之旅
1.3 机器学习的算法
1.回归:简单易懂地说,回归就是在处理连续数据(如时间序列数据)时使用的技术。
举例:选出几个过去某个时间点的股价数据,从这样的数据中学习它的趋势,求出“明天的股价会变为 多少”“今后的趋势会怎样”的方法就是回归,它就是一种机器学习算法。
*然而,股价的变动不只受过去股价的影响,所以光靠这个信息并不能很好地预测出来。当我们要预测什么事情的时候,经常会把对预测有影响的数据收集起来进行组合。)
2.分类:顾名思义。分为二分类和多分类。
3.聚类:与分类的区别在于数据带不带标签。也有人把标签称为正确答案数据。聚类任务的数据是不带标签的。
举例:假设在有100名学生的学校进行摸底考试,然后根据考试成绩把100名学生分为几组,根据分组结果,我们能得出某组偏重理科、某组偏重文科这样有意义的结论。
4.使用有标签的数据进行的学习称为有监督学习,与之相反,使用没有标签的数据进行的学习称为无监督学习。回归和分类是有监督学习,而聚类是无监督学习。
第二章 学习回归
2.2 定义模型
学习语境:假设存在这样一个前提:投入的广告费越多,广告的点击量就越高,进而带来访问数的增加。(即大致为一次函数)
*在统计学领域,人们常常使用 来表示未知数和推测值。采用
加数字下标的形式,是为了防止当未知数增加时,表达式中大量出现 a、b、c、d…这样的符号。这样不但不易理解,还可能会出现符号本身不够用的情况。
我们需要使用机器学习来求出正确的 和
的值。
2.3 最小二乘法
为了方便理解,将上面的一次函数改写:
我们的目标是:求出让 最小的
和
的值。用表达式展现出来就是:假设有
个训练数据,那么它们的误差之和可以用这样的表达式表示。
这个表达式称为目标函数, 的
是误差的英语单词 Error 的首字母。
* 和
中的
不是
次幂的意思,而是指第
个训练数据。
计算误差的平方是为了防止正误差和复误差正负相抵的情况。使用平方而不是绝对值以及乘以1/2都是为了之后对目标函数进行微分更加方便。
2.3.1 最速下降法
1.微分是计算变化的快慢程度时使用的方法。
2.只要向与导数的符号相反的方向移动 ,
就会自然而然地沿着最小值(我们的目标)的方向前进了。用表达式表示即为:
其中的意思是通过
来定义
。
3. 是称为学习率的正的常数,根据学习率的大小,到达最小值的更新次数也会发生变化。换种说法就是收敛速度会不同。有时候甚至会出现完全无法收敛,一直发散的情况。如果
较大,
会在两个值上跳来跳去,甚至有可能远离最小值,这就是发散状态。而当
较小时,移动量也变小,更新次数就会增加,但是值确实是会朝着收敛的方向而去。
4.解释完为什么以及如何求微分后,我们回到目标函数 的微分。特别需要注意的是
中的
拥有
和
两个参数,即目标函数是拥有
和
的双变量函数,所以不能用普通的微分,而要用偏微分。如此一来,更新表达式就是这样的:
而为了计算这个偏微分,我们发现需要用到复合函数的微分的知识,因为 中有
,而
中有
。
2.4 多项式回归
为了更好地拟合数据,我们把 定义为更高次的函数
虽然次数越大拟合得越好,但难免也会出现过拟合的问题。还需要特别注意的是,这里虽然是多次函数,但是变量仍然是一个。
2.5 多重回归
1.为了让问题尽可能地简单,这次我们只考虑广告版面的大小,设广告费为 、广告栏的宽为
、广告栏的高为
,那么
可以表示如下:
接下来,换汤不换药,分别求目标函数对的偏微分,然后更新参数即可。
2.推广到有 个变量的情况,为了简化表达式我们可以可以把参数
和变量
看作向量。保证向量
和
维度和下标都相同,将向量
转置后与向量
相乘
即
3.设 、
则第
个元素
偏微分的表达式为:
则,这样就汇总成了一个表达式。
4.所谓的最速下降法就是对所有的训练数据都重复进行计算,但是训练数据越多,循环次数也就越多,那么计算起来非常花时间。因此计算量大、计算时间长是最速下降法的一个缺点。
2.6 随机梯度下降法
1.最速下降法除了计算花时间以外,还有一个缺点就是容易陷入局部最优解。如图:
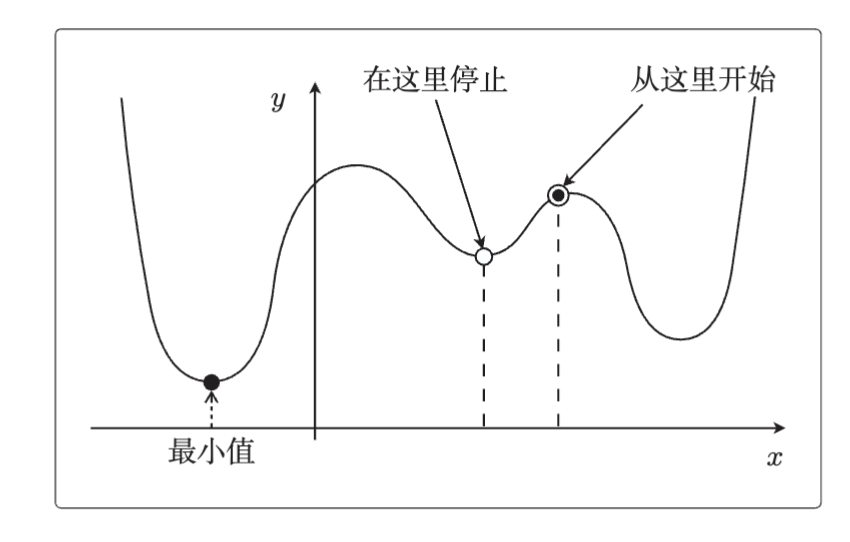 因此,我们引入“随机梯度下降法”。最速下降法使用了所有训练数据的误差,而在随机梯度下降
因此,我们引入“随机梯度下降法”。最速下降法使用了所有训练数据的误差,而在随机梯度下降
法中会随机选择一个训练数据,并使用它来更新参数。
2.最速下降法更新 1 次参数的时间,随机梯度下降法可以更新 次。此外,随机梯度下降法由于训练数据是随机选择的,更新参数时使用的又是选择数据时的梯度,所以不容易陷入目标函数的局部最优解。
3.小批量梯度下降法:随机选择 个训练数据来更新参数的做法。设随机选择
个训练数据的索引的集合为
,那么我们这样来更新参数
这像是介于最速下降法和随机梯度下降法之间的方法。
4.不管是随机梯度下降法还是小批量梯度下降法,我们都必须考虑学习率 。把
设置为合适的值是很重要的。这是一个很难的问题。可以通过反复尝试来找到合适的值,不过,除此之外还有几个办法(此书没有继续细讲)。
第三章 学习分类
3.2 内积
1.分类任务的需要求的目标参数变成了向量。我们需要找到使得 的权重向量
。实向量空间的内积是各相应元素乘积的和,所以刚才的表达式也可以写成
2.通过训练找到权重向量,然后才能得到与这个向量垂直的直线,最后根据这条直线就可以对数据进行分类了。
3.3 感知机
1.如何求出权重向量:将权重向量用作参数,创建更新表达式来更新参数。
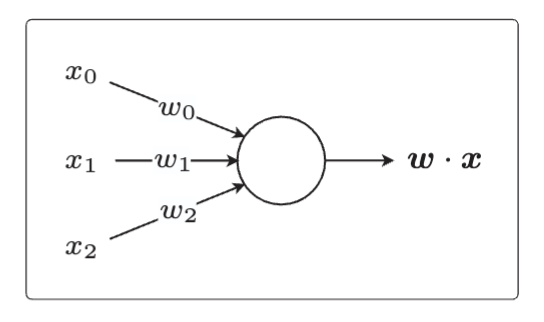
2.感知机模型:感知机是接受多个输入后将每个值与各自的权重相乘,最后输出总和的模型。人们常用这样的图来表示它。感知机是非常简单的模型,基本不会应用在实际的问题中。但它是神经网络和深度学习的基础模型,所以记住它没坏处。
3.3.2 权重向量的更新表达式
其中,是通过判别函数对向量
进行分类的结果,
是实际的标签。也就是说,更新表达式只有在判别函数分类失败的时候才会更新参数值。像这样重复更新所有的参数,就是感知机的学习方法。
3.4 线性可分
感知机最大的缺点就是它只能解决线性可分的问题。线性可分指的就是能够使用直线分类的情况,不能用直线分类的就不是线性可分。
3.5 逻辑回归
3.5.1 sigmoid函数
exp 的全称是 exponential,即指数函数。 与
含义相同,只是写法不同。e 是自然常数,具体的值为 2.7182...。也就是说
可以换成
这样的写法。
1.设 为横轴,
为纵轴,那么它的图形为
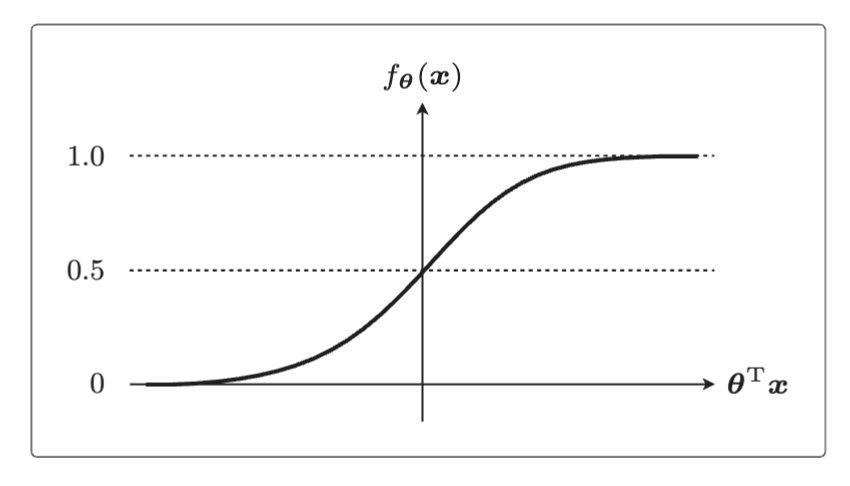
2.sigmoid函数的两个特征:
(1) = 0 时
= 0.5;
(2) 0 < < 1【所以sigmoid函数可以作为概率来使用】。
3.sigmoid函数的导数:
这个表达式在神经网络的反向传播中常用,因为它计算高效,只需知道 Sigmoid 函数的值即可计算导数。
3.5.2 决策边界
1.我们把未知数据 是横向图像的概率作为
。其表达式:
该式子为条件概率,是在给出 数据时
,即图像为横向的概率。
2.自然地,我们以0.5为阈值,即
结合sigmoid函数我们可以将这个式子改写成:
改写后,我们将 这条直线作为边界线,就可以把这条线两侧的数据分类为横向和纵向了。这样用于数据分类的直线称为决策边界。为了求得这条决策边界,我们需要求得正确的参数
,因此需要定义目标函数进行微分,然后求参数的更新表达式。这种算法就称为逻辑回归。
3.6 似然函数
底层逻辑: 的时候,我们希望概率
是最大的;
的时候,我们希望概率
是最大的.
假定所有的训练数据都是互不影响、独立发生的,这种情况下整体的概率就可以用下面的联合概率来表示。
我们的目标现在转化求出使 最大的参数
。这里的目标函数
也被称为似然,函数的名字
取自似然的英文单词 Likelihood 的首字母。
3.7 对数似然函数
1.不过直接对似然函数进行微分有点困难,在此之前要把函数变形。因为(1)概率都是 1 以下的数,所以像联合概率这种概率乘法的值会越来越小。如果值太小,编程时会出现精度问题。(2)与加法相比,乘法的计算量要大得多。
2.取似然函数的对数
3.微分对数似然函数(逻辑回归)
和回归的时候是一样的,我们把似然函数也换成这样的复合函数,然后对各个参数 求微分。
其中,
所以:
4.接下来要做的就是从这个表达式导出参数更新表达式。不过现在是以最大化为目标,所以必须按照与最小化时相反的方向移动参数。也就是说,最小化时要按照与微分结果的符号相反的方向移动,而最大化时要与微分结果的符号同向移动。
为了与回归时的符号保持一致,也可以将表达式调整为下面这样。
3.8 线形不可分
1.将逻辑回归应用于线性不可分问题的方法:增加次数。
2.在逻辑回归的参数更新中也可以使用随机梯度下降法。
第四章 评估
4.1 模型评估
模型的评估也就是定量地表示机器学习模型的精度。
4.2 交叉验证
4.2.1 回归问题的验证
1.如何评估模型呢?
把获取的全部训练数据分成两份:一份用于测试,一份用于训练。然后用前者来评估模型。
模型评估就是检查训练好的模型对测试数据的拟合情况。
2.定量评估回归模型:在训练好的模型上计算测试数据的误差的平方,再取其平均值就可以了。假设测试数据有 个:
。这个值被称为均方误差或者 MSE,全称 Mean Square Error。这个误差越小,精度就越高,模型也就越好。
4.2.2 分类问题的验证
对于分类有别的指标。由于回归是连续值,所以可以从误差入手,但是在分类中我们必须要考虑分类的类别是否正确。在回归中要考虑的是答案不完全一致时的误差,而分类中要考虑的是答案是否正确。一般来说,二分类的结果可以用这张表来表示。
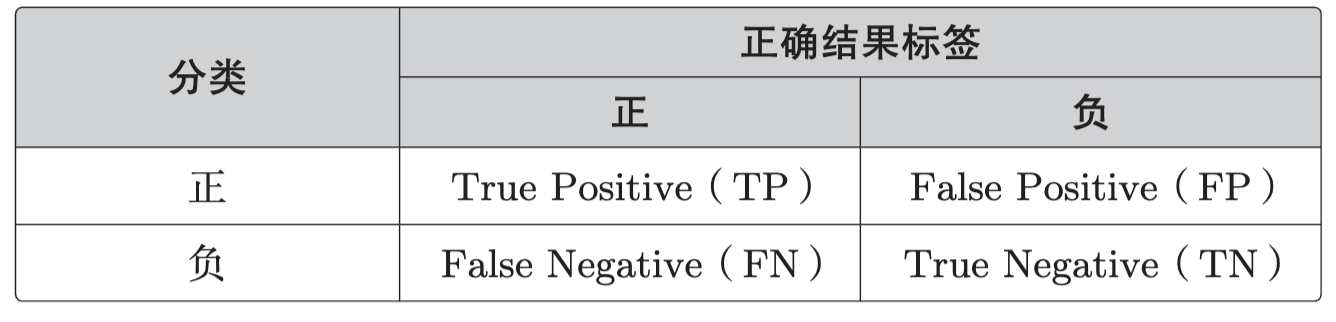 分类结果为正的情况是 Positive、为负的情况是 Negative。分类成功为 True、分类失败为 False。我们可以使用表里的 4 个记号来计算分类的精度。
分类结果为正的情况是 Positive、为负的情况是 Negative。分类成功为 True、分类失败为 False。我们可以使用表里的 4 个记号来计算分类的精度。
它表示的是在整个数据集中,被正确分类的数据 TP 和 TN 所占的比例。
4.2.3 精确率和召回率
一般来说,只要计算出这个 Accuracy 值,基本上就可以掌握分类结果整体的精度了。但是有时候只看这个结果会有问题。
举例:假设有 100 个数据,其中 95 个是 Negative。那么,哪怕出现模型把数据全部分类为 Negative 的极端情况,Accuracy 值也为 0.95,也就是说模型的精度是 95%。但是不管精度多高,一个把所有数据都分类为 Negative 的模型,不能说它是好模型吧。
所以要引入别的指标。
1.精确率Precision
这个指标只关注 TP 和 FP。根据表达式来看,它的含义是在被分类为 Positive 的数据中,实际就是 Positive 的数据所占的比例。
2.召回率Recall
这个指标只关注 TP 和 FN。根据表达式来看,它的含义是在Positive 数据中,实际被分类为 Positive 的数据所占的比例。
3.上面介绍的精确率和召回率都是以 TP 为主进行计算的,也是可以以 TN 为主的,当数据不平衡时,使用数量少的那个会更好。
4.2.4 F值
1.基于这两个指标来考虑精度是比较好的。不过一般来说,精确率和召回率会一个高一个低,需要我
们取舍。举一个例子方便理解:
 看一下两个模型的平均值,会发现模型 B 的更高。但它是把所有数据都分类为 Positive 的模型,精确率极低,仅为 0.02,并不能说它是好模型。所以只看平均值确实无法知道模型的好坏。所以就出现了评定综合性能的指标 F 值。
看一下两个模型的平均值,会发现模型 B 的更高。但它是把所有数据都分类为 Positive 的模型,精确率极低,仅为 0.02,并不能说它是好模型。所以只看平均值确实无法知道模型的好坏。所以就出现了评定综合性能的指标 F 值。
精确率和召回率只要有一个低,就会拉低 F 值。
2.有时称 F 值为 F1 值会更准确。这两个值有的时候含义相同,有的时候却并不相同。除 F1 值之外,还有一个带权重的 F 值指标。
我们可以认为 F 值指的是带权重的 F 值,当权重为 1 时才是刚才介绍的 F1 值。
3.把全部训练数据分为测试数据和训练数据的做法称为交叉验证。交叉验证的方法中,尤为有名的是 K 折交叉验证,掌握这种方法很有好处。
(1)把全部训练数据分为 K 份;
(2)将 K − 1 份数据用作训练数据,剩下的 1 份用作测试数据;
(3)每次更换训练数据和测试数据,重复进行 K 次交叉验证;
(4)最后计算 K 个精度的平均值,把它作为最终的精度。
不切实际地增加 K 值会非常耗费时间,所以我们必须要确定一个合适的 K 值。
4.3 正则化
4.3.1 过拟合
1.模型只能拟合训练数据的状态被称为过拟合,英文是 overfitting。过拟合不止在回归时出现,在分类时也经常发生,我们要时常留意它。
2.如何避免过拟合?
(1)增加全部训练数据的数量
(2)使用简单的模型
(3)正则化
首先,重要的是增加全部训练数据的数量。之前我也讲过,机器学习是从数据中学习的,所以数据最重要。另外,使用更简单的模型也有助于防止过拟合。
4.3.2 正则化的方法
1.向目标函数增加正则化项。比如向回归的目标函数增加如下的正则化项。我们要对这个新的目标函数进行最小化,这种方法就称为正则化。
m 是参数的个数。一般来说不对 应用正则化。所以仔细看会发现 j 的取值是从 1 开始的。这也就是说,假如预测函数的表达式为
, m = 2 就意味着正则化的对象参数为
和
。
这种只有参数的项称为偏置项,一般不对它进行正则化。
是决定正则化项影响程度的正的常数。这个值需要我们自己来定。
4.3.3 正则化的效果
正则化可以防止参数变得过大,有助于参数接近较小的值。参数的值变小,意味着该参数的影响也会相应地变小。这正是通过减小不需要的参数的影响,将复杂模型替换为简单模型来防止过拟合的方式。是可以控制正则化惩罚的强度。
4.3.5 包含正则化项的表达式的微分
1.L2正则化
(1)回归的包含正则化项的表达式的微分
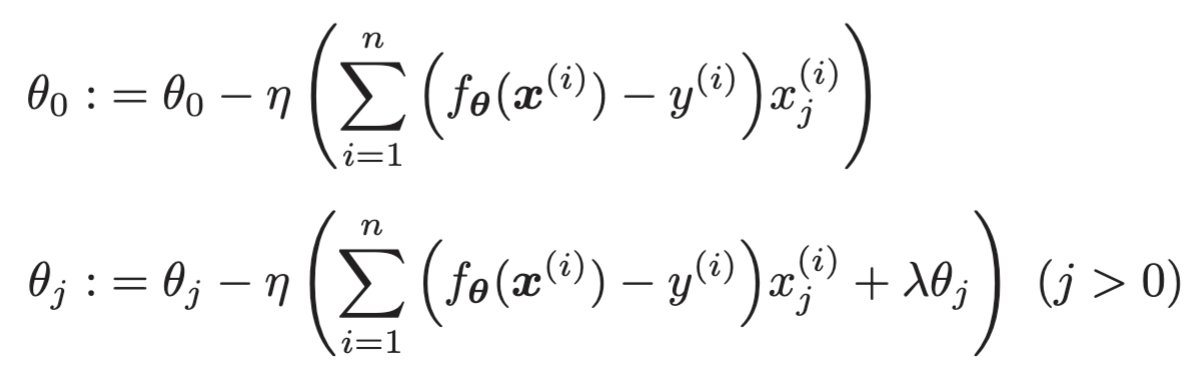
(2)分类的包含正则化项的表达式的微分
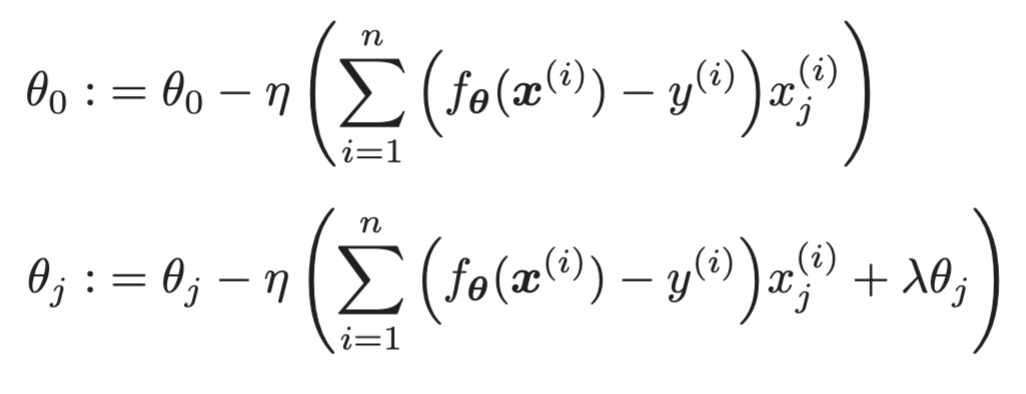 2.L1正则化
2.L1正则化
L1 正则化的特征是被判定为不需要的参数会变为 0,从而减少变量个数。而 L2 正则化不会把参数变为 0。L2 正则化会抑制参数,使变量的影响不会过大,而 L1 会直接去除不要的变量。
4.4 学习曲线
4.4.1 欠拟合
欠拟合是与过拟合相反的状态,它是没有拟合训练数据的状态。
4.4.2 区分过拟合和欠拟合
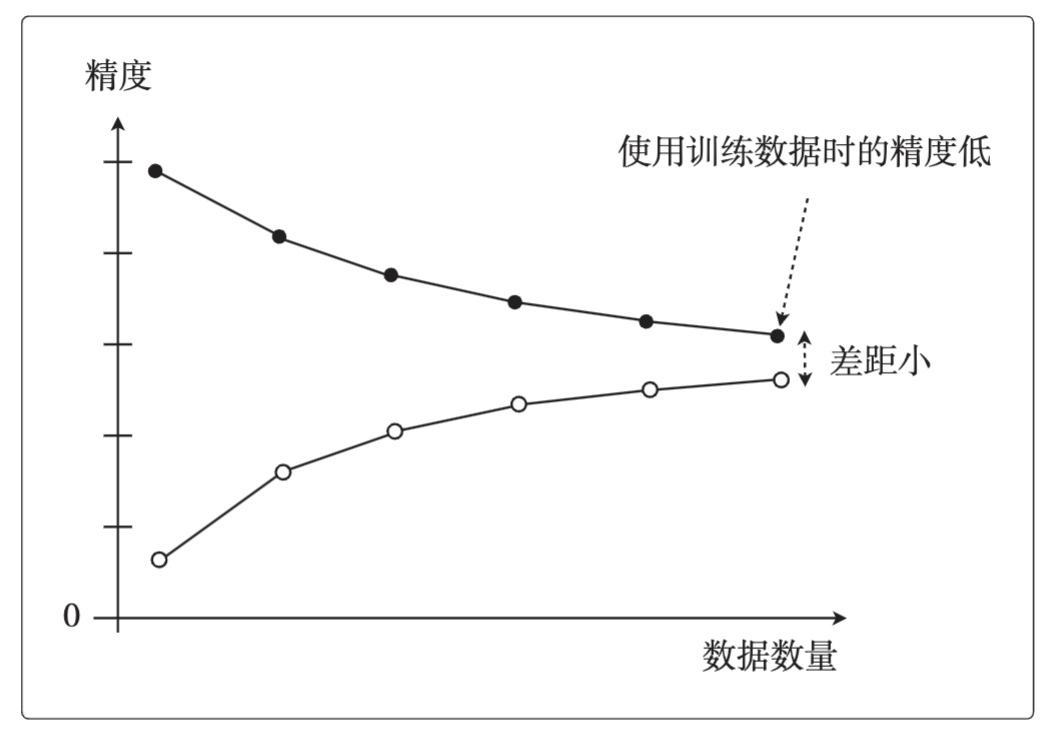
知道模型精度低,却不知道是过拟合还是欠拟合的时候,可以通过学习曲线判断出是过拟合还是欠拟合之后,就可以采取相应的对策以便改进模型了。
(1)欠拟合的学习曲线:即使增加数据的数量,无论是使用训练数据还是测试数据,精度也都会很差的状态。(高偏差)
 2.过拟合的学习曲线:随着数据量的增加,使用训练数据时的精度一直很高,而使用测试数据时的精度一直没有上升到它的水准。(高方差)
2.过拟合的学习曲线:随着数据量的增加,使用训练数据时的精度一直很高,而使用测试数据时的精度一直没有上升到它的水准。(高方差)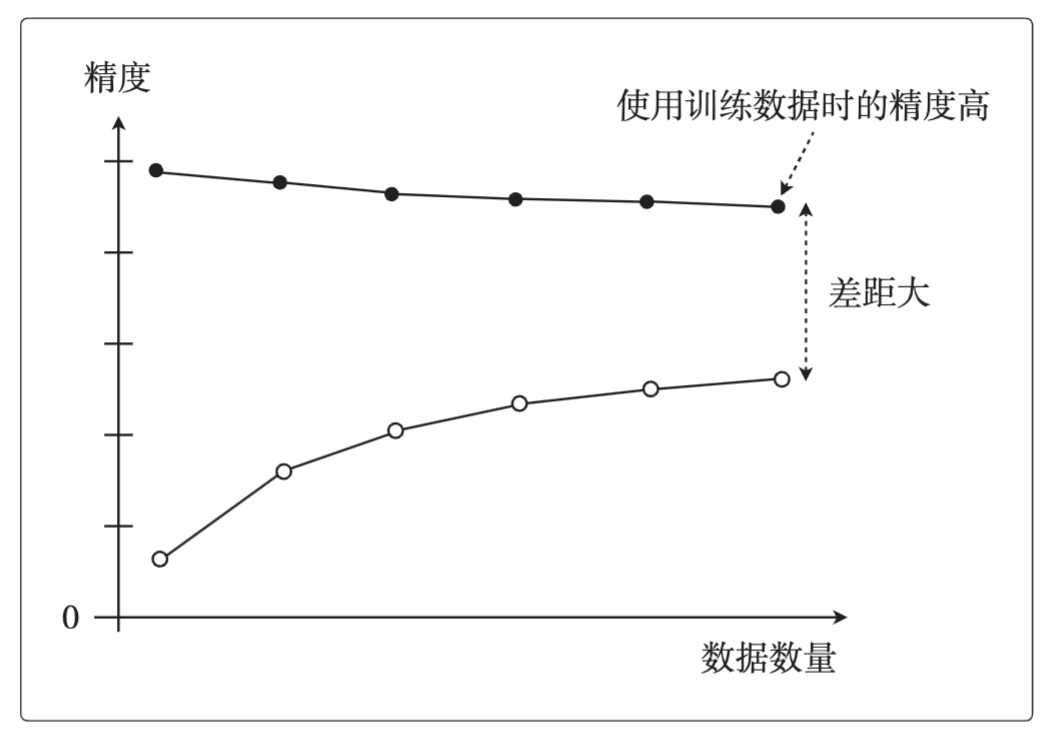
第五章 实现
5.2 回归
5.2.1 确认训练数据
1.我们准备了一些训练数据,储存在click.csv文件中,该文件的部分数据如下图所示。
 我们可以先用 Matplotlib 绘图,结合图来了解训练数据的基本情况。
我们可以先用 Matplotlib 绘图,结合图来了解训练数据的基本情况。
import numpy as np
import matplotlib.pyplot as plt
#读入训练数据
train=np.loadtxt('click.csv',delimiter=',',skiprows=1)
train_x=train[:,0]
train_y=train[:,1]
#绘图
plt.plot(train_x,train_y,'o')
plt.show()5.2.2 作为一次函数实现
首先把 作为一次函数来实现。那么我们要实现下面这样的
和目标函数
。
1.进行 和
的初始化,用随机值作初始值。
#参数初始化
theta0=np.random.rand()
theta1=np.random.rand()
#预测函数
def f(x):
return theta0+theta1*x
#目标函数
def E(x,y):
return 0.5*sum((y-f(x))**2)2.完成标准化( z-score 规范化):把训练数据变成平均值为0、方差为 1 的数据。这个预处理不是必须的,但是做了之后,参数的收敛会更快。 是训练数据的平均值,
是标准差。
#标准化
mu=train_x.mean()
sigma=train_x.std()
def standardize(x):
return (x-mu)/sigma
train_z=standardize(train_x)把变换后的数据也用图展现出来,我们会看到只有横轴的刻度改变了。
3.实现参数更新
的值不能一概而论,要试几次才能确定,可以先设置为
。
要对目标函数进行微分,不断重复参数的更新。我们可以指定次数,也可以比较参数更新前后目标函数的值,如果值基本没什么变化,就可以结束学习了。
注意⚠️:参数的更新必须同时进行。 更新结束后准备更新
时,不能使用更新后的
,而必须要使用更新前的
。
#学习率
ETA = 1e-3
#误差的差值
diff = 1
#更新次数
count = 0
#重复学习
error = E(train_z,train_y)
while diff > 1e-2:
#更新结果保存到临时变量
tmp0 = theta0 - ETA * np.sum((f(train_z) - train_y))
tmp1 = theta1 - ETA * np.sum((f(train_z) - train_y) * train_z)
#更新参数
theta0 = tmp0
theta1 = tmp1
#计算与上一次误差的差值
current_error = E(train_z,train_y)
diff = error - current_error
error = current_error
#输出日志
count += 1
log = ' 第 {} 次 : theta0 = {:.3f}, theta1 = {:.3f}, 差值 = {:.4f}'
print(log.format(count, theta0, theta1, diff))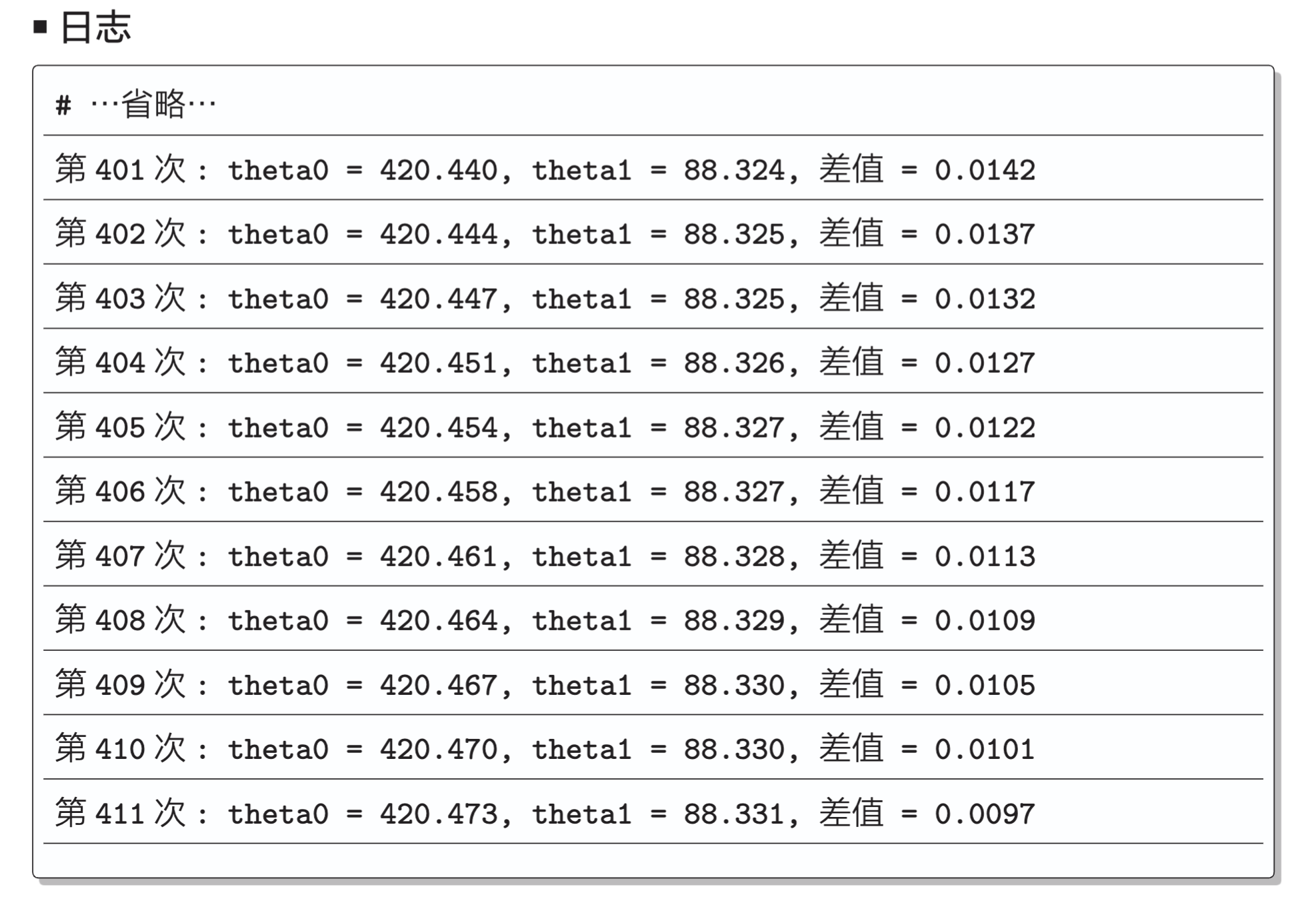 这样就算执行成功了。多次执行之后就会发现,循环次数和误差的减少量在每次执行时都不一样,这一点需要注意。这是因为参数的初始值是随机决定的。
这样就算执行成功了。多次执行之后就会发现,循环次数和误差的减少量在每次执行时都不一样,这一点需要注意。这是因为参数的初始值是随机决定的。
4.绘图以确认结果,查看训练数据和 。
#设置坐标轴范围
x = np.linspace(-3,3,100)
#绘图
plt.plot(train_z,train_y,'o')
plt.plot(x,f(x))
plt.show()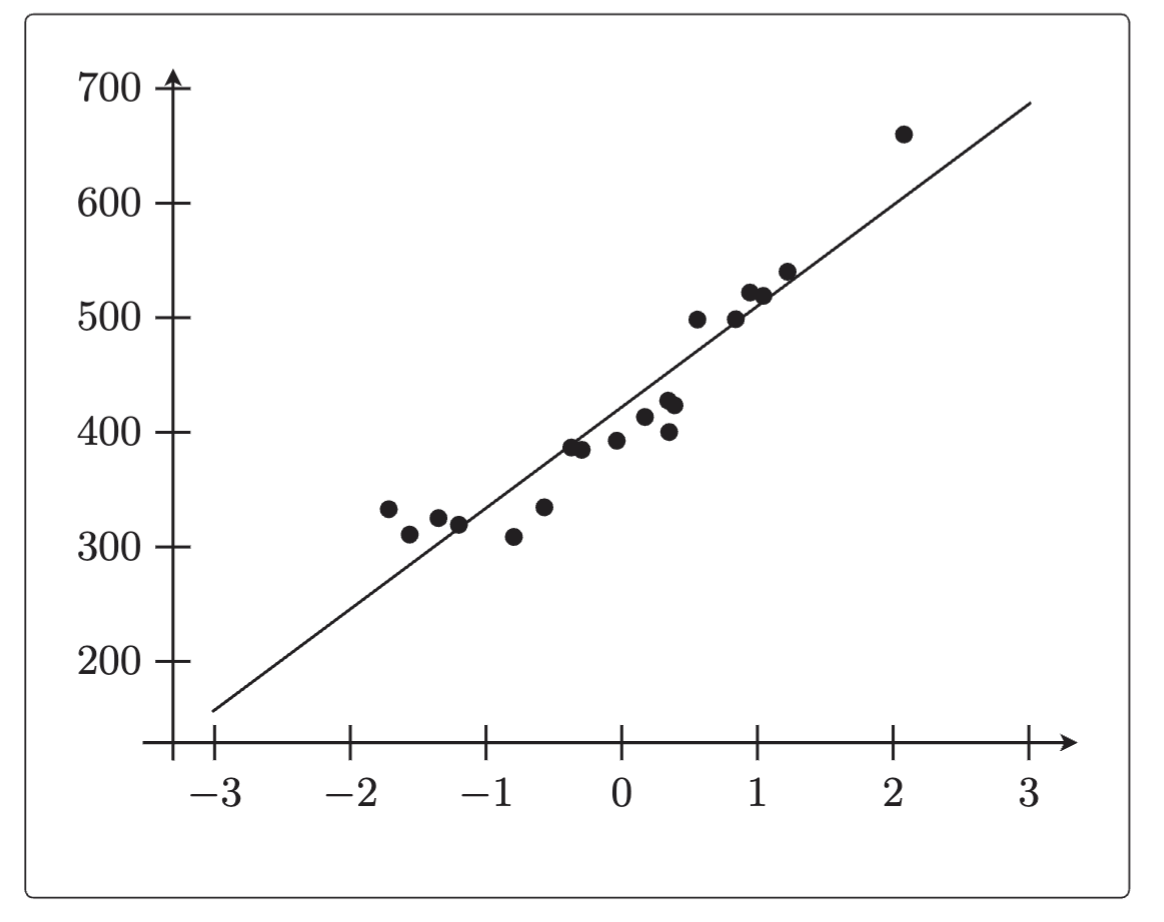 5.2.3 验证
5.2.3 验证
试着随意输入 x 来预测点击量吧。不过要注意,由于已经对训练数据进行了标准化,所以预测数据也要标准化,否则得不出正确答案。
5.2.4 多项式回归的实现
1.多次函数的实现
正如我们在学习多重回归时了解的那样,将参数和训练数据都作为向量来处理,可以使计算变得更简单。
由于训练数据有很多,所以我们把 1 行数据当作 1 个训练数据,以矩阵的形式来处理会更好。
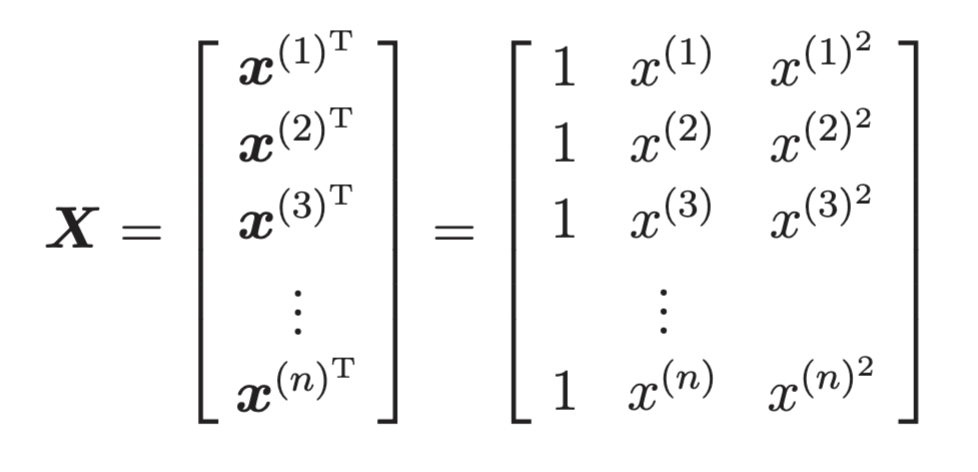 然后,再求这个矩阵与参数向量
然后,再求这个矩阵与参数向量 的积。这样一下子就能计算好了。
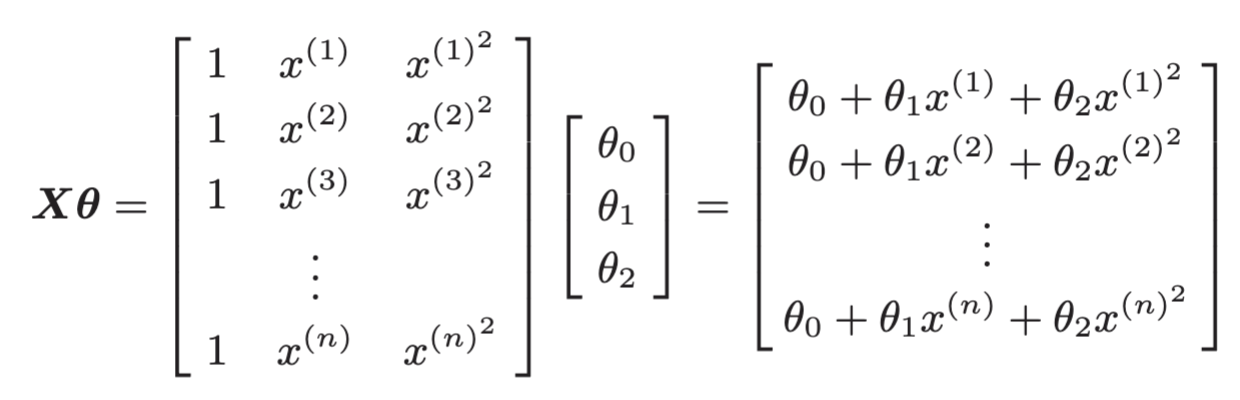 相关python代码如下:
相关python代码如下:
#初始化参数
theta = np.random.rand(3)
#创建训练数据的矩阵
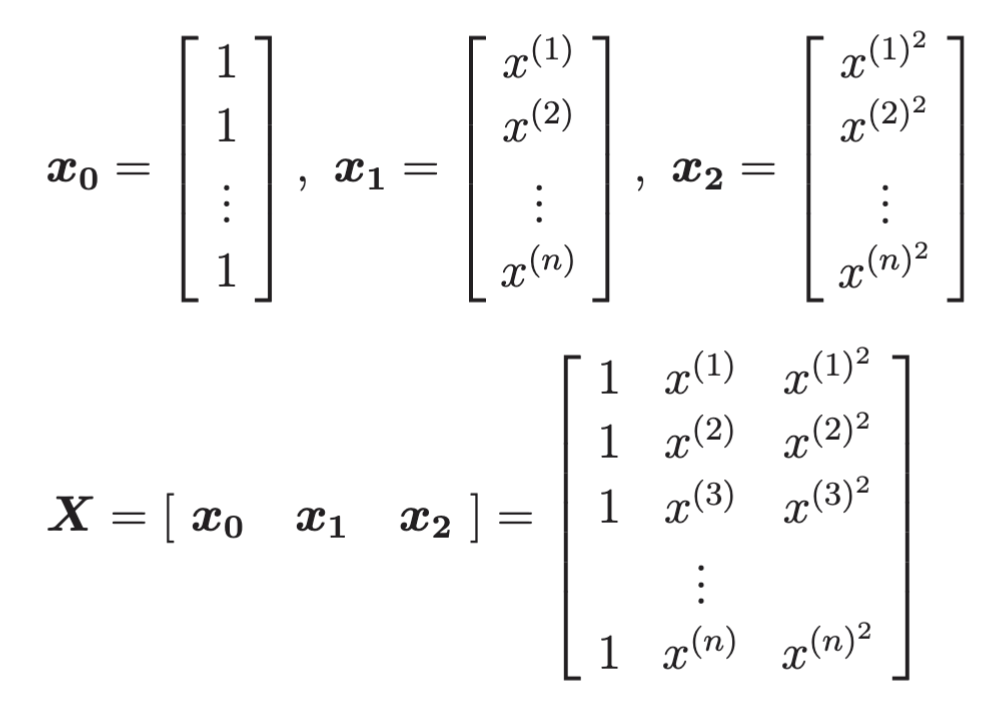
def to_matrix(x):
return np.vstack(np.ones(x.shape[0],x,x**2)).T//一个设计矩阵,列分别为:常数项(1)、一次项(x)、二次项(x^2)。适用于二次多项式回归。
X = to_matrix(train_z)
#预测函数
def f(x):
return np.dot(x,theta)2.参数更新的实现
更新表达式可以像这样写成通用的表达式,我们在学习多重回归时见过它。
这里很容易让人想到用循环来实现,但其实如果好好利用训练数据的矩阵,就能一下子全部计算来。比如在
的时候,把更新表达式的
部分展开,就会变成这样子。
把表达式中 和
的部分分别当作向量来处理。
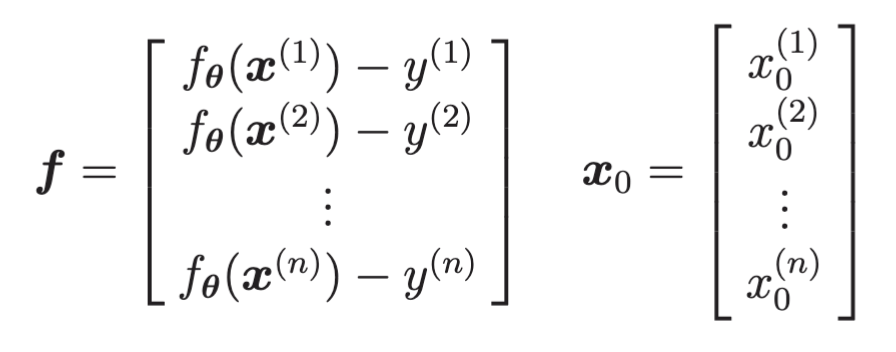 把
把 转置之后与
相乘,就与和的部分一样了。
这里考虑的还只是 的情况,而参数共有 3 个,再用同样的思路考虑
和
的情况就好了。
 因此,参数更新表达式变成了:
因此,参数更新表达式变成了:
3.
对应的python代码如下:
#误差的差值
diff = 1
#重复学习
error = E(X,train_y)
while diff > 1e-2:
#更新参数
theta = theta - ETA * np.dot(f(X)-train_y,X)
#计算与上一次误差的差值
current_error = E(X, train_y)
diff = error - current_error
error = current_error3.在停止重复的条件里可以用上均方误差
#均方误差
def MSE(x,y):
return (1/x.shape[0]) * np.sum((y-f(x))**2)
#用随机值初始化参数
theta = np.random.rand(3)
#均方误差的历史记录
errors = []
#误差的差值
diff = 1
#重复学习
errors.append(MSE(X,train_y))
while diff > 1e-2:
theta = theta - ETA * np.dot(f(X) - train_y, X)
errors.append(MSE(X, train_y))
diff = errors[-2] - errors[-1]
#绘制误差变化图
x = np.arange(len(errors))
plt.plot(x,errors)
plt.show()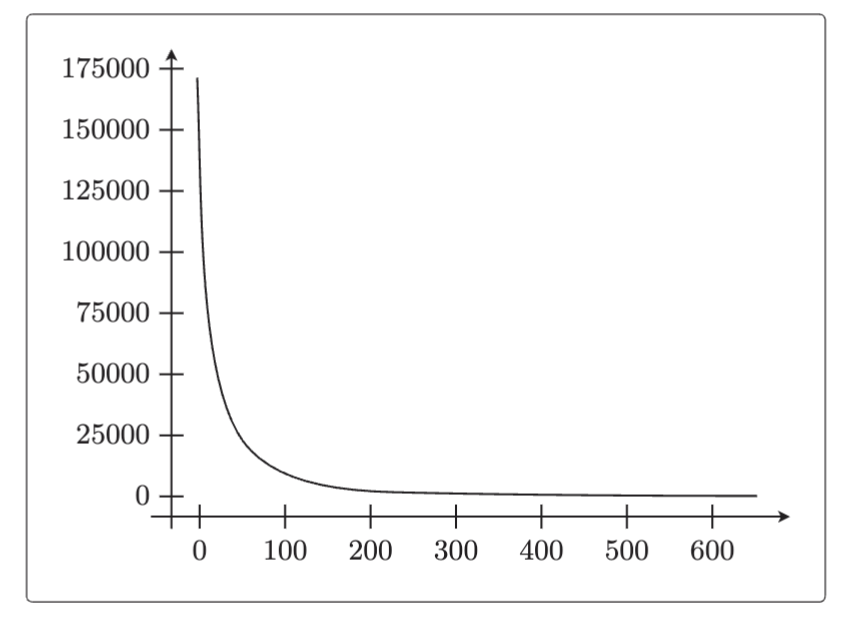 5.2.5 随机梯度下降法的实现
5.2.5 随机梯度下降法的实现
随机梯度下降法的做法是使用以下表达式来更新参数,表达式中的 k 是随机选择的。现在有了训练数据的矩阵 X,把行的顺序随机地予以调整,然后重复应用更新表达式就行了。
#用随机数对参数初始化
theta = np.random.rand(3)
#均方误差的历史记录
errors = []
#误差的差值
diff = 1
#重复学习
errors.append(MSE(X,train_y))
while diff > 1e-2:
#为了调整训练数据的顺序,准备随机的序列
p = np.random.permutation(X.shape[0])
#随机取出训练数据,使用随机梯度下降法更新参数
for x,y in zip(X[p,:],train_y[p]):
theta = theta - ETA * (f(x)-y)*x
#计算与上一次误差的差值
errors.append(MSE(X, train_y))
diff = errors[-2] - errors[-1]对于多重回归的实现,也可以像多项式回归时那样使用矩阵。不过要注意对多重回归的变量进行标准化时,必须对每个参数都进行标准化。如果有变量 、
、
,就要分别使用每个变量的平均值和标准差进行标准化。
5.3 分类——感知机
5.3.1 确认训练数据
我们将用于分类的数据储存在images1.csv中,预览如下:
 绘制图像初步了解这个训练数据:
绘制图像初步了解这个训练数据:
import numpy as np
import matplotlib.pyplot as plt
# 读入训练数据
train = np.loadtxt('images1.csv', delimiter=',', skiprows=1)
train_x = train[:,0:2]
train_y = train[:,2]
# 绘图
plt.plot(train_x[train_y == 1,0],train_x[train_y == 1,1],'o')
// 选择标签为1的样本的第0列特征和第1列特征
plt.plot(train_x[train_y == -1,0],train_x[train_y == -1,1],'x')
plt.axis('scaled')
plt.show()
5.3.2 感知机的实现
1.实现权重初始化+定义判别函数
首先要初始化感知机的权重,然后实现这个在表达式中出现的函数 。
# 权重的初始化
w = np.random.rand(2)
# 判别函数
def f(x):
if np.dot(w,x) >= 0:
return 1
else:
return -12.实现权重的更新表达式
感知机没有类似回归的目标函数,所以感知机停止学习的标准由精度来决定。
不过这里我们姑且先设置为重复 10 次。
# 重复次数
epoch = 10
# 更新次数
count = 0
# 学习权重
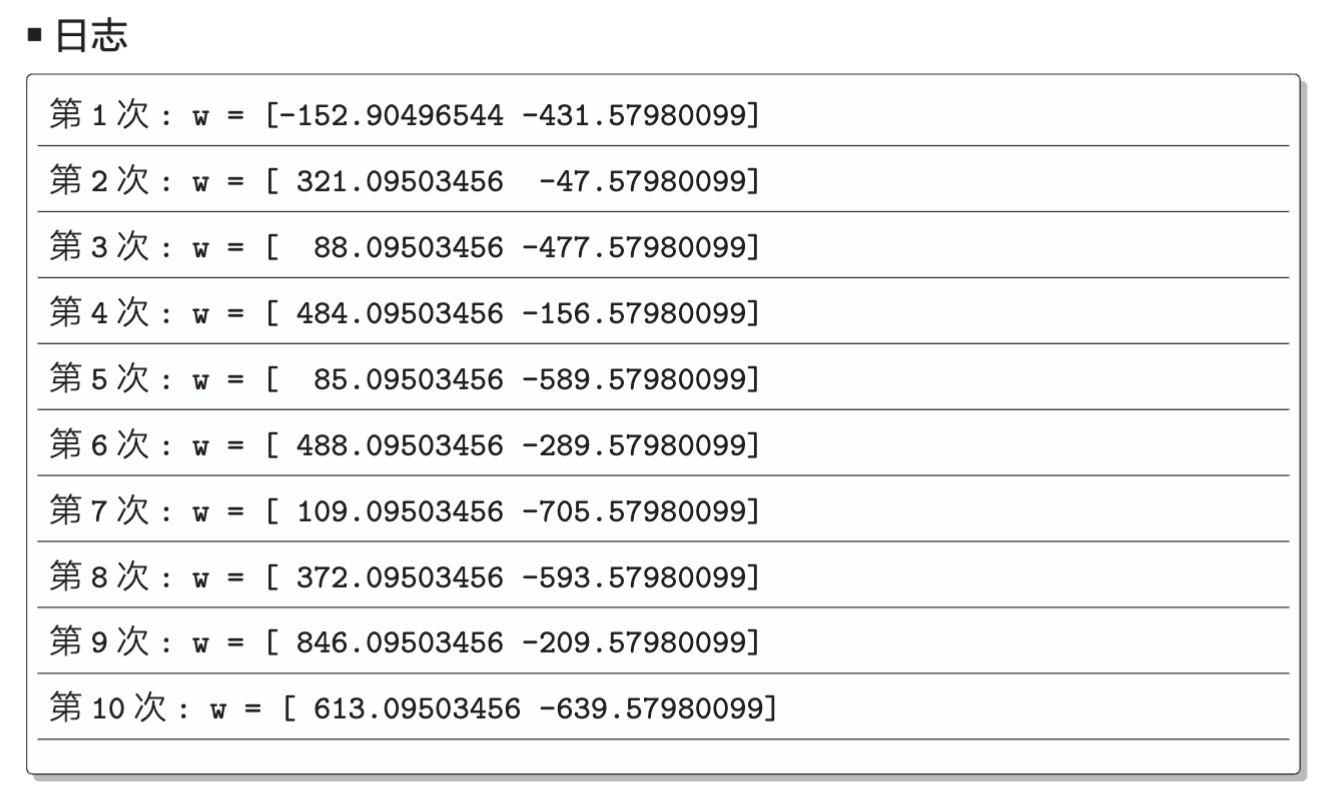
for _ in range(epoch):
for x,y in zip(train_x,train_y):
if f(x) != y:
w = w + y * x
# 输出日志
count += 1
print(' 第 {} 次 : w = {}'.format(count, w))输出的日志是这样的:
3.绘制分界线
现在我们画一条直线试试看,使权重向量成为法线向量的直线方程是内积为 0 的 的集合。所以对它进行移项变形,最终绘出以下表达式的图形即可。
x1 = np.arrange(0,500)
plt.plot(train_x[train_y == 1, 0], train_x[train_y == 1, 1], 'o')
plt.plot(train_x[train_y == -1, 0], train_x[train_y == -1, 1], 'x')
plt.plot(x1, -w[0] / w[1] * x1, linestyle='dashed')
plt.show()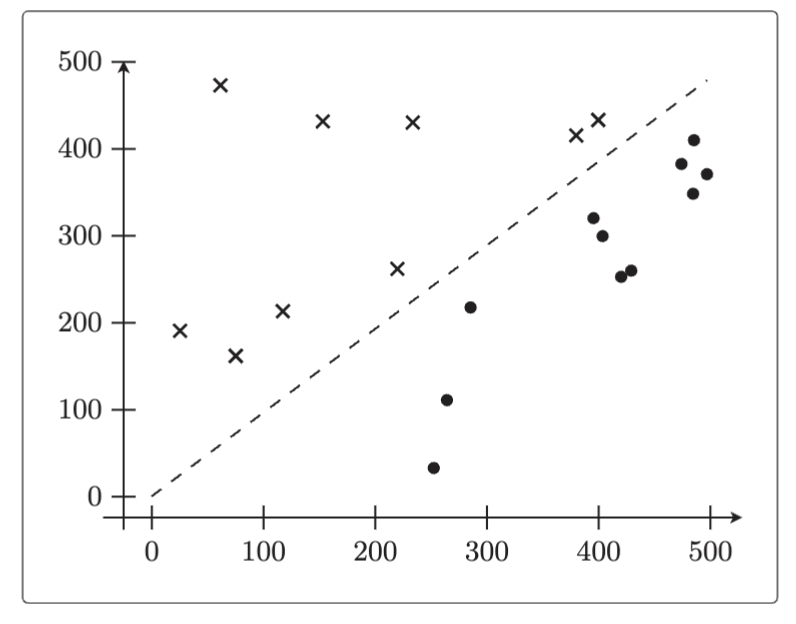 分类效果真不错啊。这次没有对训练数据进行标准化,也可以执行。一般来说进行标准化效果会更好,但不标准化有时也可以执行。这次就是一个例子。
分类效果真不错啊。这次没有对训练数据进行标准化,也可以执行。一般来说进行标准化效果会更好,但不标准化有时也可以执行。这次就是一个例子。
我们刚才试验的都是二维数据,如果增加训练数据和 的维度,那么模型也可以处理三维以上的数据。不过模型依然只能解决线性可分的问题。
5.4 分类——逻辑回归
5.4.1 确认训练数据
我们把数据储存在images2.csv文件中,之前数据中的 和
可以不变,但
需要变一下。因为在逻辑回归中,我们需要把横向分配为 1、纵向分配为 0。
5.4.2 逻辑回归的实现
1.首先初始化参数,然后对训练数据标准化吧。 和
要分别标准化。另外不要忘了加一个
列。
import numpy as np
import matplotlib.pyplot as plt
# 读入训练数据
train = np.loadtxt('images2.csv', delimiter=',', skiprows=1)
train_x = train[:,0:2]
train_y = train[:,2]
# 初始化参数
theta = np.random.rand(3)
# 标准化
mu = train_x.mean(axis=0)
sigma = train_x.std(axis=0)
def standardize(x):
return (x - mu) / sigma
train_z = standardize(train_x)
# 增加 x0
def to_matrix(x):
x0 = np.ones([x.shape[0], 1])
return np.hstack([x0, x])
X = to_matrix(train_z)
# 将标准化后的训练数据画成图
plt.plot(train_z[train_y == 1, 0], train_z[train_y == 1, 1], 'o')
plt.plot(train_z[train_y == 0, 0], train_z[train_y == 0, 1], 'x')
plt.show()2.实现预测函数,即实现sigmoid函数。
# sigmoid函数
def f(x):
return 1/(1+np.exp(-np.dot(x,theta)))3.实现参数更新
学习逻辑回归的时候,我们进行了定义逻辑回归的似然函数,对对数似然函数进行微分等一系列操作,然后最终得到的参数更新表达式如下:
与回归时一样,我们将 当作向量来处理,将它与训练数据的矩阵相乘。同时,我们把重复次数设置得稍微多一点,比如 5000 次左右。在实际问题中需要通过反复尝试来设置这个值,即通过确认学习中的精度来确定重复多少次才足够好。
# 学习率
ETA = 1e-3
# 重复次数
epoch = 5000
# 重复学习
for _ in range(epoch):
theta = theta - ETA * np.dot(f(X)-train_y,X)4.绘制决策边界
在逻辑回归中,这条直线是决策边界。
x0 = np.linspace(-2, 2, 100)
plt.plot(train_z[train_y == 1, 0], train_z[train_y == 1, 1], 'o')
plt.plot(train_z[train_y == 0, 0], train_z[train_y == 0, 1], 'x')
plt.plot(x0, -(theta[0] + theta[1] * x0) / theta[2],
linestyle='dashed')
plt.show()5.4.4 线形不可分分类的实现
将使用的数据存储在data3.csv中。
 这个数据确实不能用一条直线来分类,尝试使用二次函数。在训练数据里加上
这个数据确实不能用一条直线来分类,尝试使用二次函数。在训练数据里加上就能很好地分类了。
也就是说要增加一个 参数,参数总数达到四个了。其他不变,代码如下:
# 参数初始化
theta = np.random.rand(4)
# 标准化
mu = train_x.mean(axis=0)
sigma = train_x.std(axis=0)
def standardize(x):
return (x - mu) / sigma
train_z = standardize(train_x)
# 增加 x0 和 x3
def to_matrix(x):
x0 = np.ones([x.shape[0], 1])
x3 = x[:,0,np.newaxis] ** 2
return np.hstack([x0, x, x3])
X = to_matrix(train_z)
# sigmoid 函数
def f(x):
return 1 / (1 + np.exp(-np.dot(x, theta)))
# 学习率
ETA = 1e-3
# 重复次数
epoch = 5000
# 重复学习
for _ in range(epoch):
theta = theta - ETA * np.dot(f(X) - train_y, X)
# 绘制决策曲线
x1 = np.linspace(-2, 2, 100)
x2 = -(theta[0] + theta[1] * x1 + theta[3] * x1 ** 2) / theta[2]
plt.plot(train_z[train_y == 1, 0], train_z[train_y == 1, 1], 'o')
plt.plot(train_z[train_y == 0, 0], train_z[train_y == 0, 1], 'x')
plt.plot(x1, x2, linestyle='dashed')
plt.show()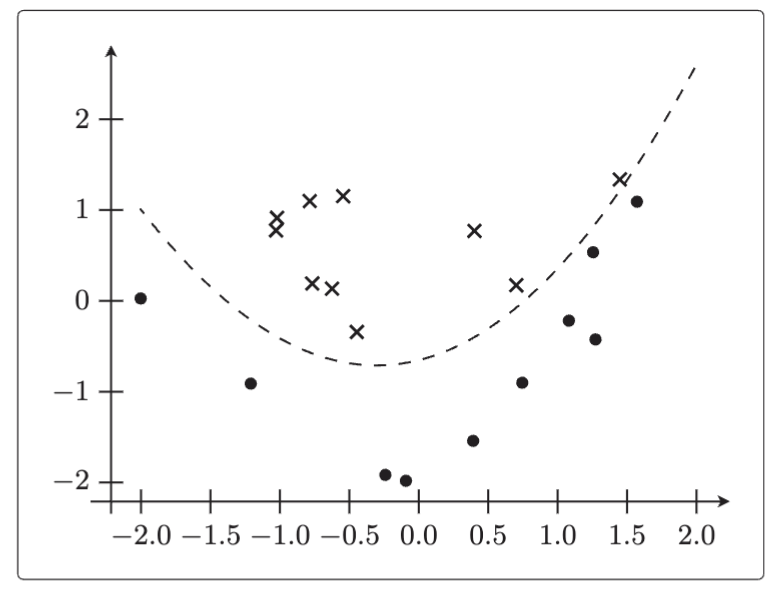 *计算模型的精度并绘图。
*计算模型的精度并绘图。
# 参数初始化
theta = np.random.rand(4)
# 精度的历史记录
accuracies = []
# 重复学习
for _ in range(epoch):
theta = theta - ETA * np.dot(f(X) - train_y, X)
# 计算现在的精度
result = classify(X) == train_y
accuracy = len(result[result == True]) / len(result)
accuracies.append(accuracy)
# 将精度画成图
x = np.arange(len(accuracies))
plt.plot(x, accuracies)
plt.show()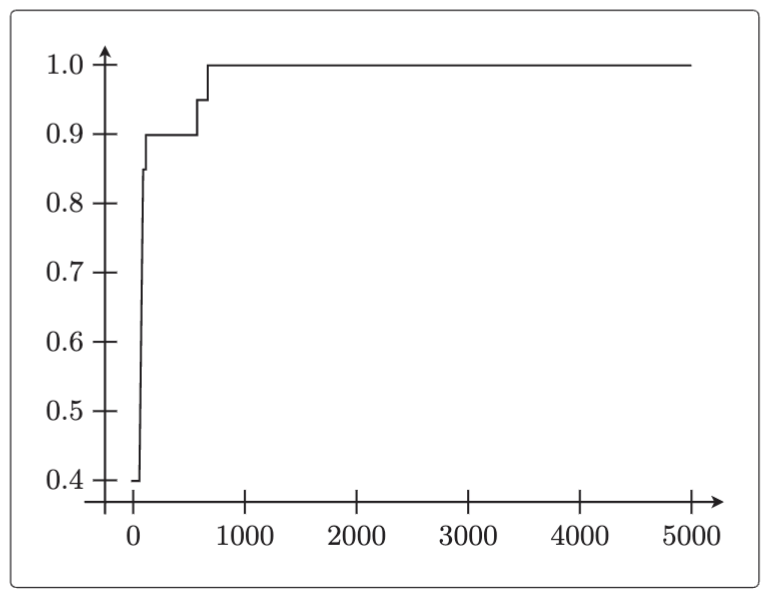 随着次数的增加,精度的确变好了。这条线有棱有角的是因为训练数据只有 20 个。精度值只能为 0.05 的整数倍。而且从图中可以看出,在重复满 5000 次之前,精度已经到 1.0 了。我们每次学习后都计算精度,当精度达到满意的程度后就停止学习。
随着次数的增加,精度的确变好了。这条线有棱有角的是因为训练数据只有 20 个。精度值只能为 0.05 的整数倍。而且从图中可以看出,在重复满 5000 次之前,精度已经到 1.0 了。我们每次学习后都计算精度,当精度达到满意的程度后就停止学习。
5.4.5 随机梯度下降法的实现
要做的也就是把学习部分稍稍修改一下:
# 参数初始化
theta = np.random.rand(4)
# 重复学习
for _ in range(epoch):
# 使用随机梯度下降法更新参数
p = np.random.permutation(X.shape[0])
for x, y in zip(X[p,:], train_y[p]):
theta = theta - ETA * (f(x) - y) * x5.5 正则化
5.5.1 确认训练数据
我们想要通过比较过拟合时图的状态和应用了正则化后图的状态,具体总结出正则化对模型施加了什么样的影响。以函数 为例,我们造一些向这个
加入了一点噪声的训练数据,然后将它们画成图。
import numpy as np
import matplotlib.pyplot as plt
# 真正的函数
def g(x):
return 0.1 * (x ** 3 + x ** 2 + x)
# 随意准备一些向真正的函数加入了一点噪声的训练数据
train_x = np.linspace(-2, 2, 8)
train_y = g(train_x) + np.random.randn(train_x.size) * 0.05
# 绘图确认
x = np.linspace(-2, 2, 100)
plt.plot(train_x, train_y, 'o')
plt.plot(x, g(x), linestyle='dashed')
plt.ylim(-1, 2)
plt.show()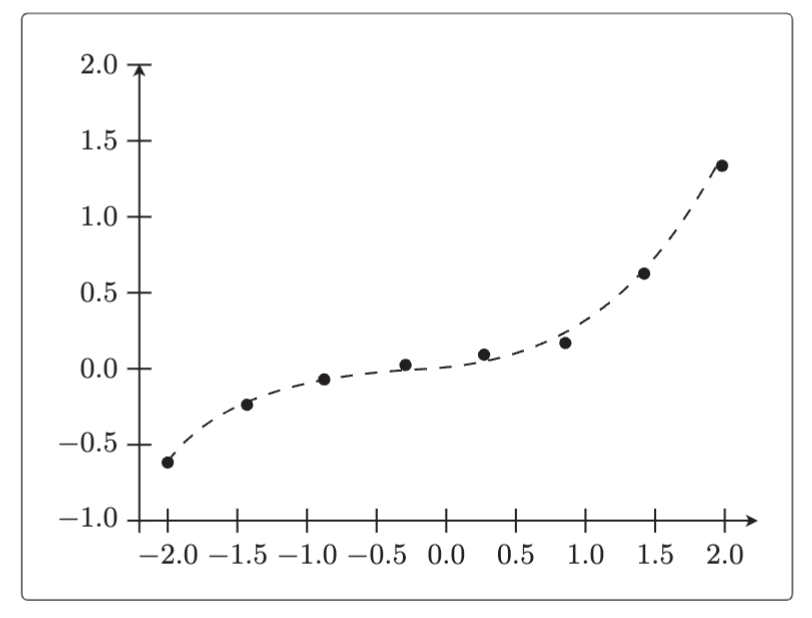 虚线就是正确的
虚线就是正确的 的图形,圆点就是加入了一点噪声的训练数据。我们先准备 8 个数据。
假设我们用 10 次多项式来学习这个训练数据。首先编写从创建训练数据的矩阵到预测函数的定义为止的代码。
# 标准化
mu = train_x.mean()
sigma = train_x.std()
def standardize(x):
return (x - mu) / sigma
train_z = standardize(train_x)
# 创建训练数据的矩阵
def to_matrix(x):
return np.vstack([
np.ones(x.size),
x,
x ** 2,
x ** 3,
x ** 4,
x ** 5,
x ** 6,
x ** 7,
x ** 8,
x ** 9,
x ** 10,
]).T
X = to_matrix(train_z)
# 参数初始化
theta = np.random.randn(X.shape[1])
# 预测函数
def f(x):
return np.dot(x, theta)5.5.2 不应用正则化的实现
接下来实现学习部分吧。首先是不应用正则化的状态。 值和学习的结束条件是根据我之前多次尝试的结果来决定的。
# 目标函数
def E(x, y):
return 0.5 * np.sum((y - f(x)) ** 2)
# 学习率
ETA = 1e-4
# 误差
diff = 1
# 重复学习
error = E(X, train_y)
while diff > 1e-6:
theta = theta - ETA * np.dot(f(X) - train_y, X)
current_error = E(X, train_y)
diff = error - current_error
error = current_error
# 对结果绘图
z = standardize(x)
plt.plot(train_z, train_y, 'o')
plt.plot(z, f(to_matrix(z)))
plt.show()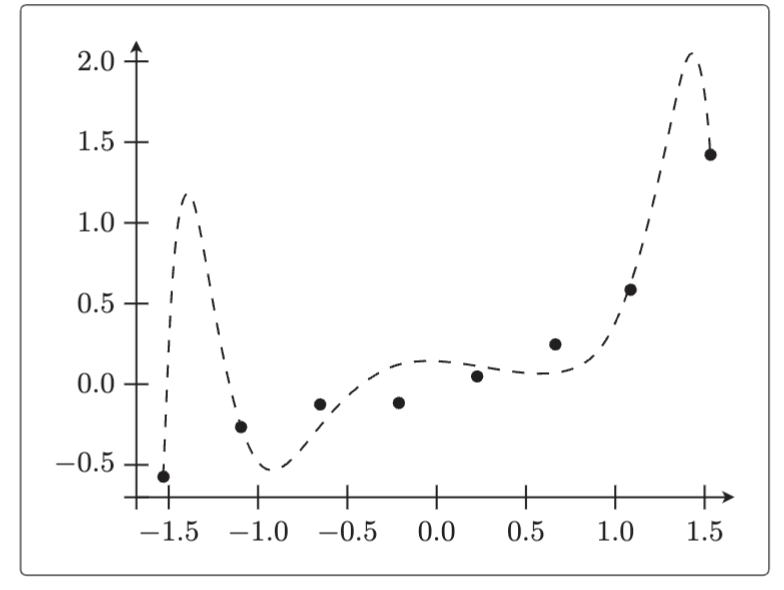 这就是发生了过拟合的状态。由于参数的初始值是随机数,所以每次执行时这个图的形状都不一样。但是,从该图中也能看出它与
这就是发生了过拟合的状态。由于参数的初始值是随机数,所以每次执行时这个图的形状都不一样。但是,从该图中也能看出它与 相差很远。
5.5.3 应用了正则化的实现
接下来应用正则化来学习看看。 的值也是根据之前多次尝试的结果来决定的。
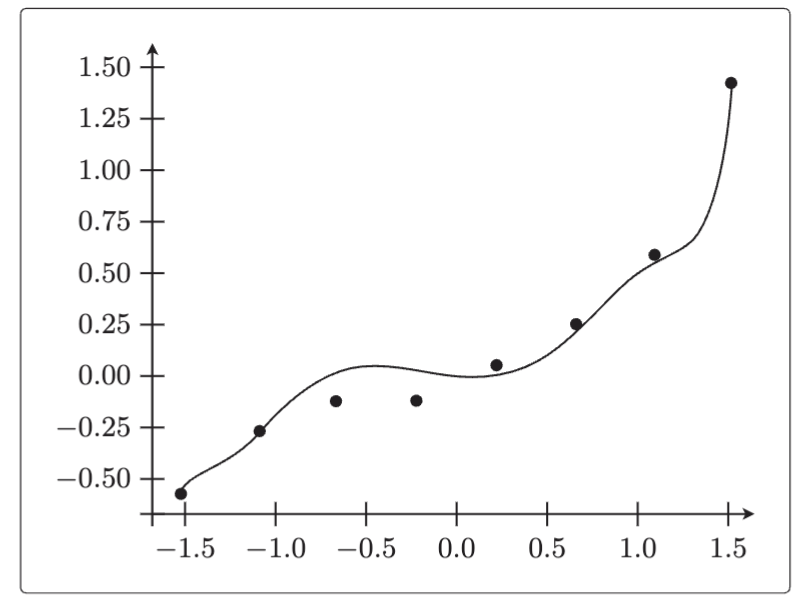
正则化后的模型比刚才的更拟合训练数据。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)