机器学习中的均值漂移聚类算法
摘要:均值漂移聚类算法是一种基于密度的非参数聚类方法,通过迭代将数据点向密度最高区域移动实现聚类。与K均值不同,它无需预设簇数,自动根据数据确定簇数。算法流程包括初始化簇、计算质心、迭代移动和收敛停止。Python实现可使用scikit-learn库,主要步骤包括数据生成、带宽估计、模型训练和结果可视化。该算法在计算机视觉、图像处理等领域有广泛应用,优势在于无需模型假设、能处理复杂形状簇,但高维数据表现不佳且无法控制簇数。
目录
均值漂移聚类算法简介
均值漂移(Mean-Shift)聚类算法是一种非参数聚类算法,其工作原理是通过迭代方式将数据点的均值向数据的密度最高区域移动。数据的密度最高区域由核函数确定,核函数是一种根据数据点到均值的距离为数据点分配权重的函数。均值漂移聚类中常用的核函数是高斯函数。
均值漂移聚类算法是无监督学习中一种功能强大的聚类算法。与 K - 均值聚类不同,它不做任何假设,因此属于非参数算法。
K - 均值算法与均值漂移算法的区别在于,后者无需预先指定簇的数量,簇的数量将由算法根据数据自动确定。
均值漂移算法的工作原理
我们可以通过以下步骤理解均值漂移聚类算法的工作流程:
- 首先,将每个数据点初始化为一个独立的簇。
- 接下来,算法计算各个簇的质心。
- 在此步骤中,更新新质心的位置。
- 然后,迭代上述过程,使质心向密度更高的区域移动。
- 最后,当质心到达无法再移动的位置时,算法停止。
均值漂移聚类算法是一种基于密度的聚类算法,这意味着它根据数据点的密度而非数据点之间的距离来识别簇。换句话说,该算法通过寻找数据点密度最高的区域来确定簇。
均值漂移聚类的 Python 实现
可以使用 Python 的 scikit-learn 库实现均值漂移聚类算法。scikit-learn 库是 Python 中流行的机器学习库,提供了各种数据分析和机器学习工具。使用 scikit-learn 库实现均值漂移聚类算法的步骤如下:
步骤 1:导入必要的库
numpy 库用于 Python 中的科学计算,matplotlib 库用于数据可视化。sklearn.cluster 库包含 MeanShift 类,用于在 Python 中实现均值漂移聚类算法。
estimate_bandwidth 函数用于估计核函数的带宽,这是均值漂移聚类算法中的一个重要参数。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import MeanShift, estimate_bandwidth步骤 2:生成数据
在这一步中,我们生成一个包含 500 个数据点和 2 个特征的随机数据集。使用 numpy.random.randn 函数生成数据。
# 生成数据
X = np.random.randn(500, 2)步骤 3:估计核函数的带宽
在这一步中,使用 estimate_bandwidth 函数估计核函数的带宽。带宽是均值漂移聚类算法中的重要参数,它决定了核函数的宽度。
# 估计带宽
bandwidth = estimate_bandwidth(X, quantile=0.1, n_samples=100)步骤 4:初始化均值漂移聚类算法
在这一步中,使用 MeanShift 类初始化均值漂移聚类算法。将带宽参数传入该类,以设置核函数的宽度。
# 初始化均值漂移算法
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)步骤 5:训练模型
在这一步中,使用 MeanShift 类的 fit 方法在数据集上训练均值漂移聚类算法。
# 训练模型
ms.fit(X)步骤 6:可视化结果
# 可视化结果
labels = ms.labels_
cluster_centers = ms.cluster_centers_
n_clusters_ = len(np.unique(labels))
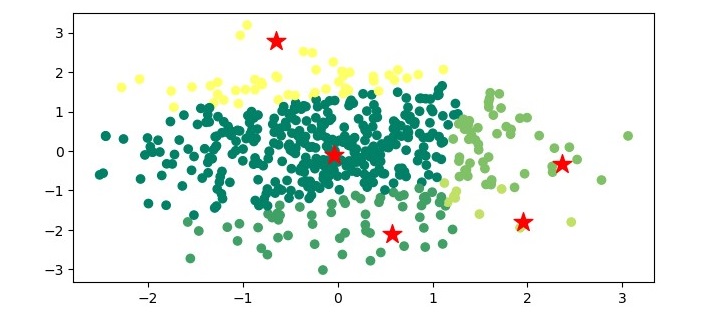
print("估计的簇数量:", n_clusters_)
# 绘制数据点和质心
plt.figure(figsize=(7.5, 3.5))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], marker='*', s=300, c='r')
plt.show()在这一步中,我们对均值漂移聚类算法的结果进行可视化。从训练好的模型中提取簇标签和簇质心,然后打印估计的簇数量。最后,使用 matplotlib 库绘制数据点和质心。
完整示例
以下是均值漂移聚类算法的完整 Python 实现示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import MeanShift, estimate_bandwidth
# 生成数据
X = np.random.randn(500, 2)
# 估计带宽
bandwidth = estimate_bandwidth(X, quantile=0.1, n_samples=100)
# 初始化均值漂移算法
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)
# 训练模型
ms.fit(X)
# 可视化结果
labels = ms.labels_
cluster_centers = ms.cluster_centers_
n_clusters_ = len(np.unique(labels))
print("估计的簇数量:", n_clusters_)
# 绘制数据点和质心
plt.figure(figsize=(7.5, 3.5))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='summer')
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], marker='*', s=200, c='r')
plt.show()输出结果
运行该程序后,将生成以下图像作为输出(注:因数据随机生成,图像具体分布可能略有差异):
示例拓展
以下是一个简单示例,帮助理解均值漂移算法的工作方式。在该示例中,我们首先生成一个包含 4 个不同 blob(团簇)的二维数据集,然后应用均值漂移算法查看结果。
%matplotlib inline
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
from sklearn.datasets import make_blobs
# 定义簇中心
centers = [[3, 3, 3], [4, 5, 5], [3, 10, 10]]
# 生成数据集
X, _ = make_blobs(n_samples=700, centers=centers, cluster_std=0.5)
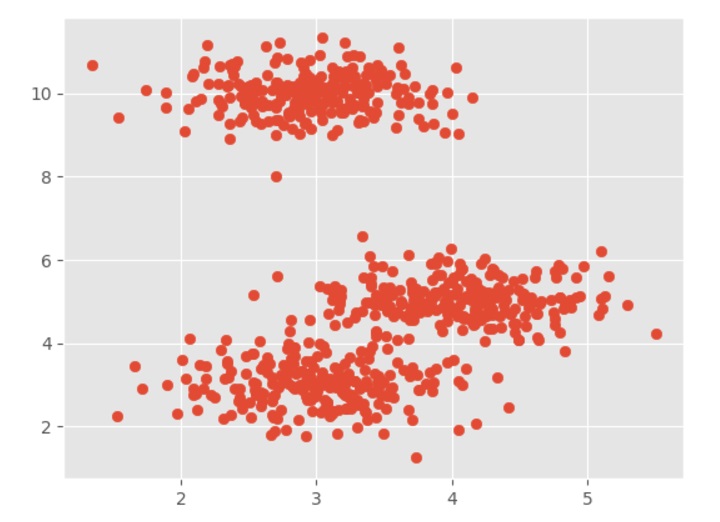
# 绘制原始数据
plt.scatter(X[:, 0], X[:, 1])
plt.show()输出
# 初始化并训练均值漂移模型
ms = MeanShift()
ms.fit(X)
# 获取簇标签和簇中心
labels = ms.labels_
cluster_centers = ms.cluster_centers_
print("簇中心:")
print(cluster_centers)
# 计算估计的簇数量
n_clusters_ = len(np.unique(labels))
print("估计的簇数量:", n_clusters_)
# 绘制聚类结果
colors = 10 * ['r.', 'g.', 'b.', 'c.', 'k.', 'y.', 'm.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize=3)
# 突出显示簇中心
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], marker=".", color='k', s=20, linewidths=5, zorder=10)
plt.show()输出结果
簇中心:
[[ 4.03457771 5.03063843 4.92928409]
[ 3.01124859 2.9957586 2.981767 ]
[ 2.94969928 10.00712673 10.01575558]]
估计的簇数量: 3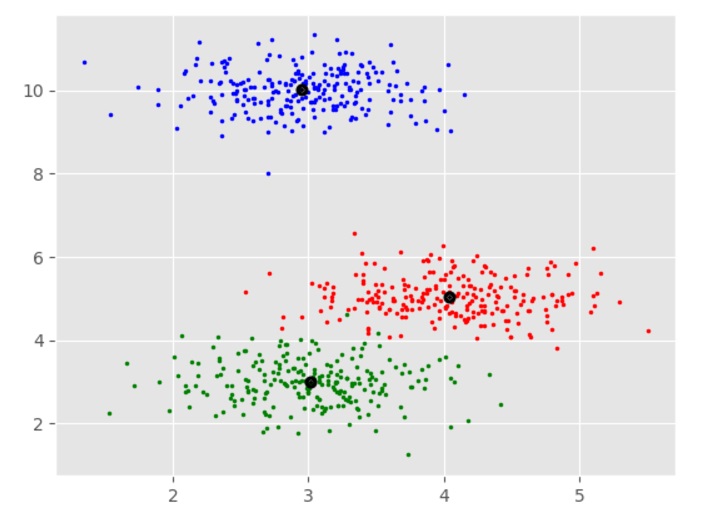
均值漂移聚类的应用场景
均值漂移聚类算法在多个领域具有广泛应用,部分应用场景如下:
- 计算机视觉:均值漂移聚类广泛用于计算机视觉领域,可实现目标跟踪、图像分割和特征提取等功能。
- 图像处理:用于图像分割,即根据像素的相似性将图像划分为多个区域的过程。
- 异常检测:通过识别低密度区域,可用于检测数据中的异常值。
- 客户细分:在市场营销中,可根据客户的行为和偏好相似性划分客户群体,实现客户细分。
- 社交网络分析:基于用户的兴趣和互动行为,对社交网络中的用户进行聚类分析。
优势与劣势
优势
均值漂移聚类算法具有以下优势:
- 无需像 K - 均值或高斯混合模型那样做任何模型假设。
- 能够对非凸形状的复杂簇进行建模。
- 仅需一个带宽参数,簇的数量会自动由该参数确定。
- 不存在 K - 均值算法中出现的局部最小值问题。
- 受异常值影响较小。
劣势
均值漂移聚类算法存在以下劣势:
- 在高维数据场景中表现不佳,且高维数据中簇的数量可能会突然变化。
- 无法直接控制簇的数量,但在部分应用场景中,需要指定固定数量的簇。
- 无法区分有意义的模式和无意义的模式。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 11
11 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)