从零开始的机器学习之路(七)---- Optional Lab 8 Feature scaling and Learning Rat 特征缩放和学习率
文章目录
前引
今天早上把至少这三篇的内容给完成了 是的 : ) 昨晚看完相关视频都到一点钟了
go forward :)
视频资料参考
【机器学习入门】optional lab8-学习率和特征缩放 learning rate and features scaling(推荐)
从零开始的机器学习之路(七)---- Optional Lab 8 Feature scaling and Learning Rat 特征缩放和学习率
1、Feature scaling and Learning Rat Start
其实这一章最主要的就是在讲 特征缩放 主要也就两种方法 均值标准化 还有 Z-Score标准化
对我们数据进行处理 这样让数据均在一个较小区域的区间 比如-1~1 -3~3 这种较小的区间
这样数据训练迭代的效果会好很多 参考这样的图 可以看出等高线 这样去迭代每一次 其实是会更趋近预期的效果的
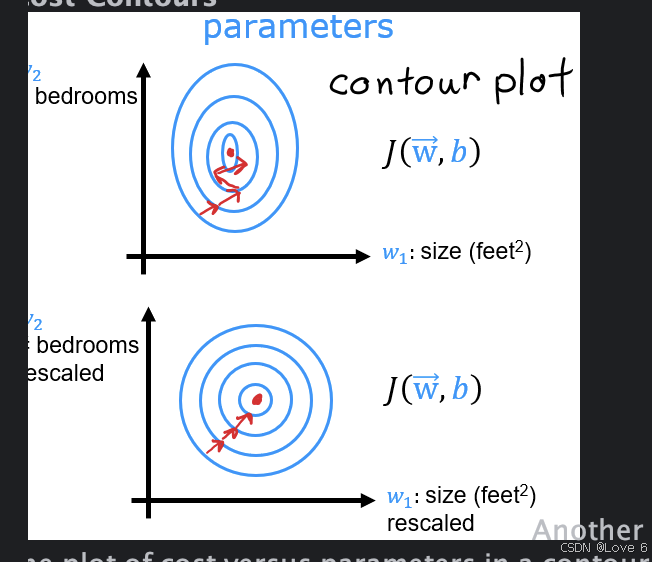
还有一个就是不同学习率的选择 实际迭代的效果的一个差异对比 只不过这个后面简单带过一下就好了
以及在我们实际的场景中 我们应该怎样选取学习率 过大 过小 迭代的一个过程
大概就是这样的
2、Problem Statement
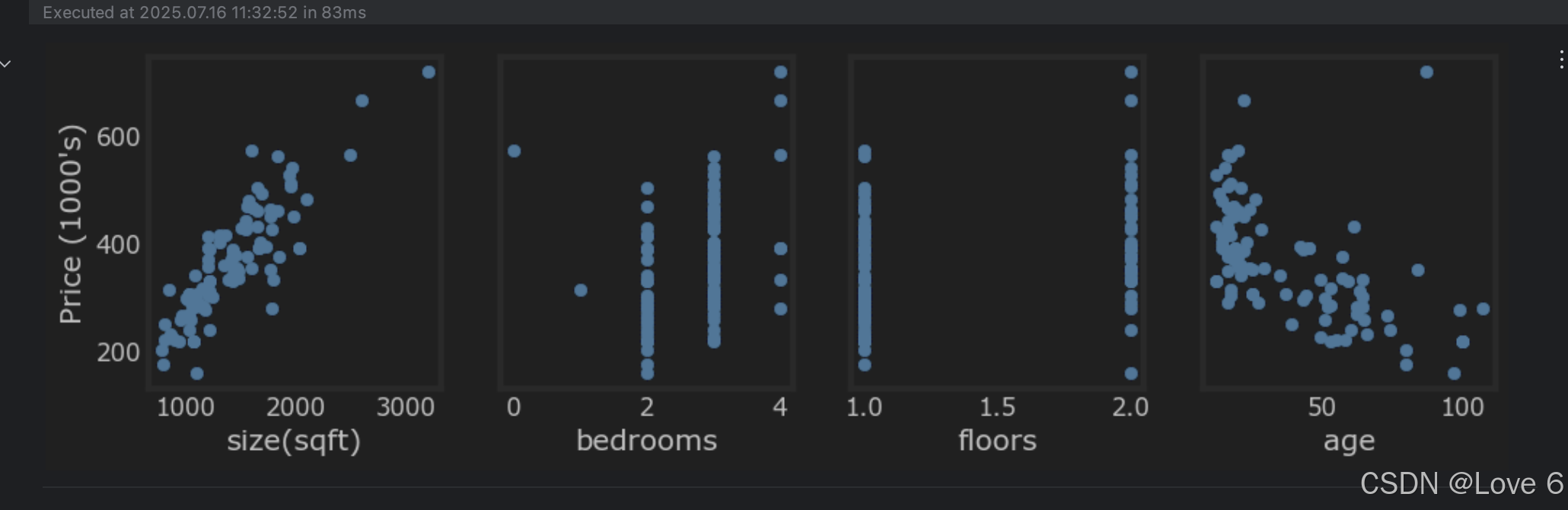
先针对我们目前这个lab的基本情况做个讲一下 我们目前针对数据其实是有四个因素 大小 卧室房间数 楼层数 房屋年龄 参考下图 且针对这四个数据 均有我们的数据
然后其实去计算迭代我们的梯度的也就是之前我们用过的公式 下方红线框框出来的内容
然后也是从这里开始的

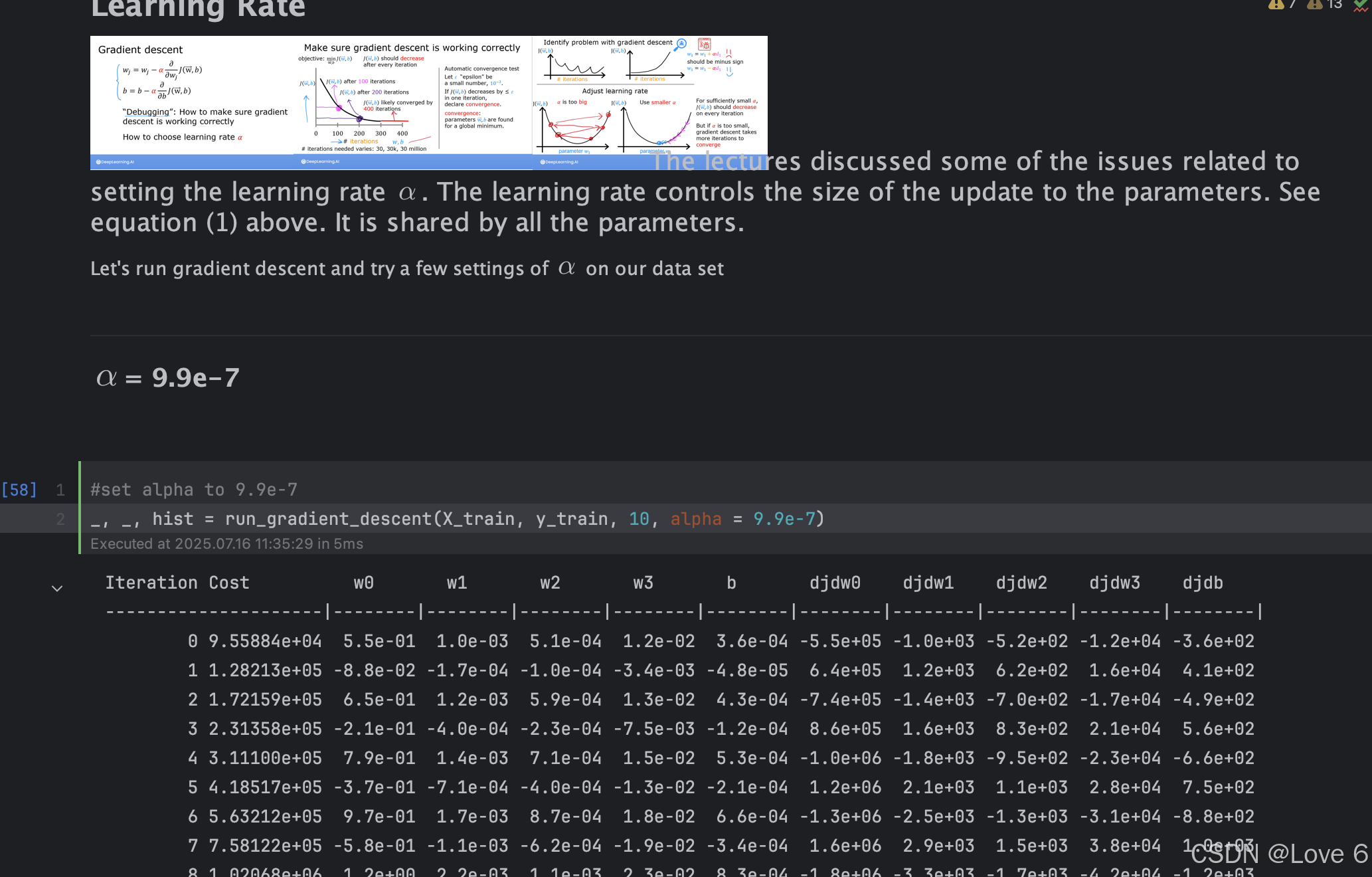
3、不同的学习率 数据迭代参考
下方则是对于不同学习率的迭代器 都是迭代10次
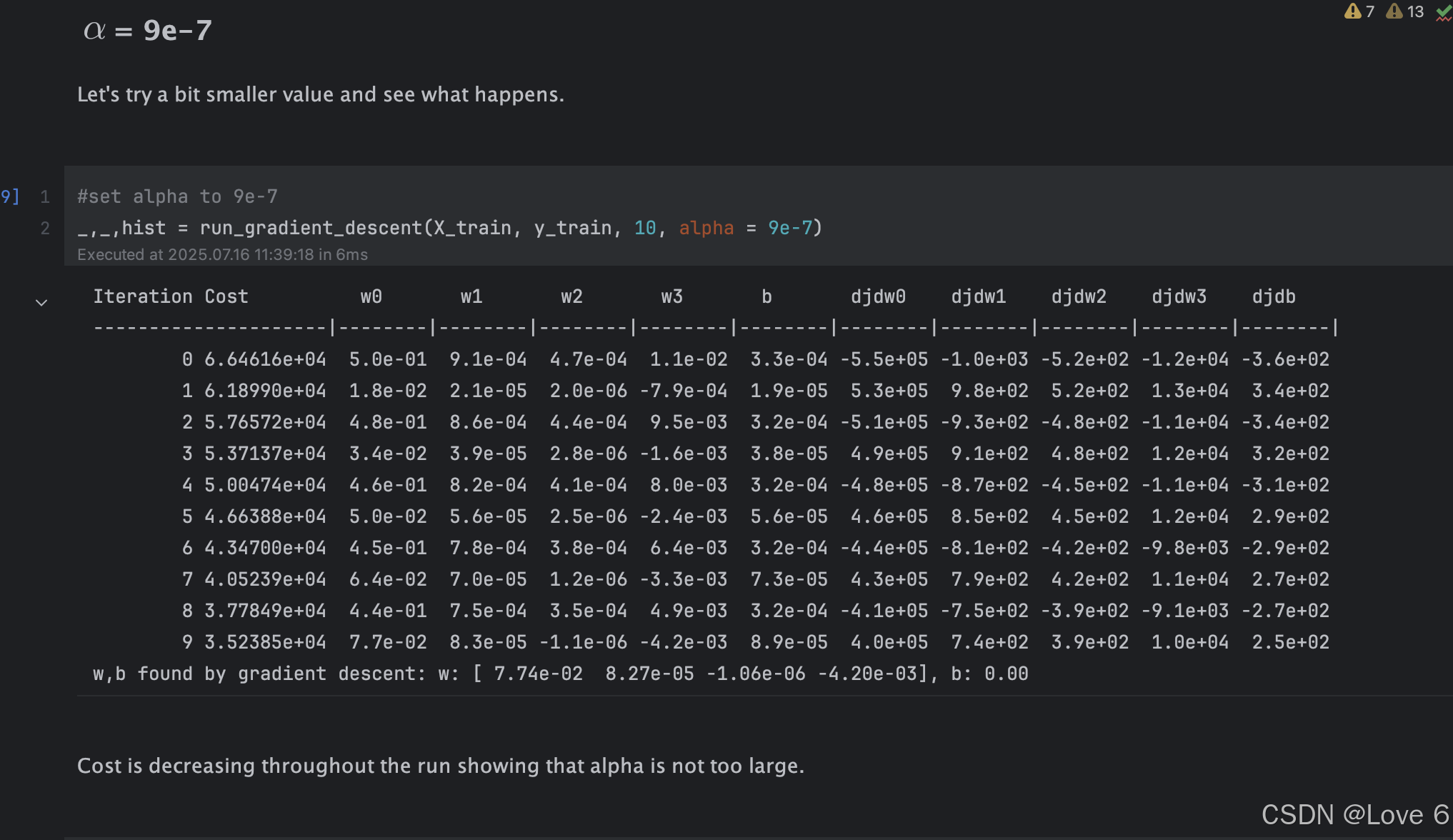
前两幅图是 9.9e-7学习率的图像 然后学习率都是逐渐减小 一直到9e-7 1e-7
9e-7 学习率 这里明显看出来比上面的没有那么激进
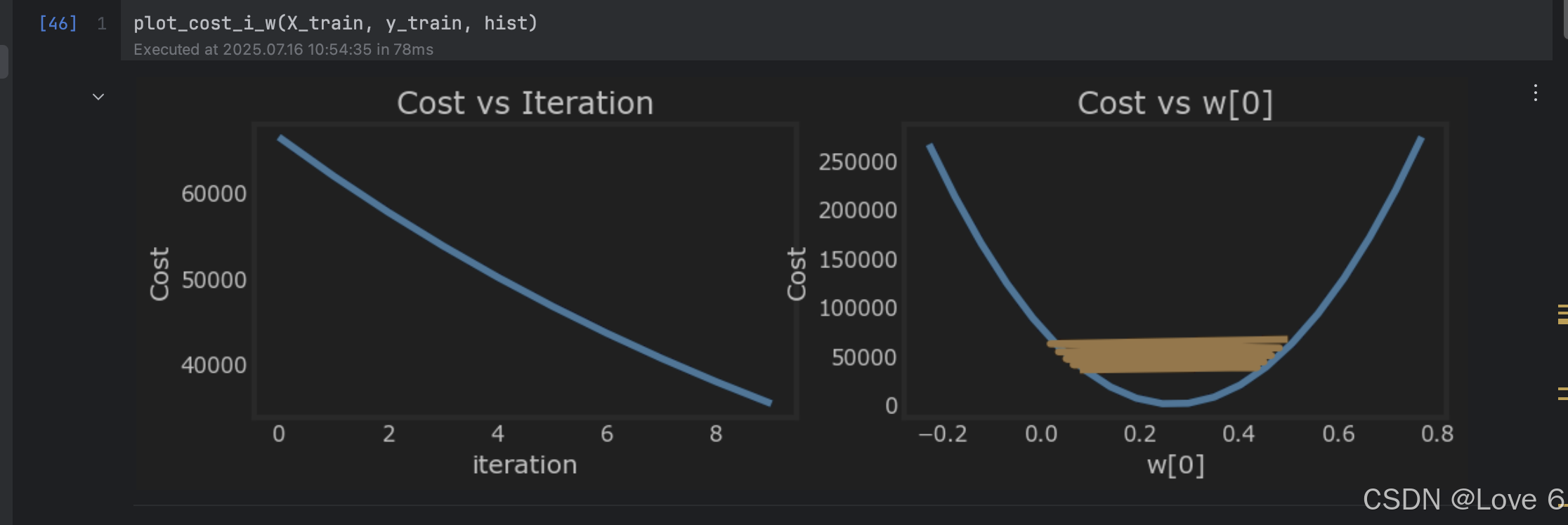
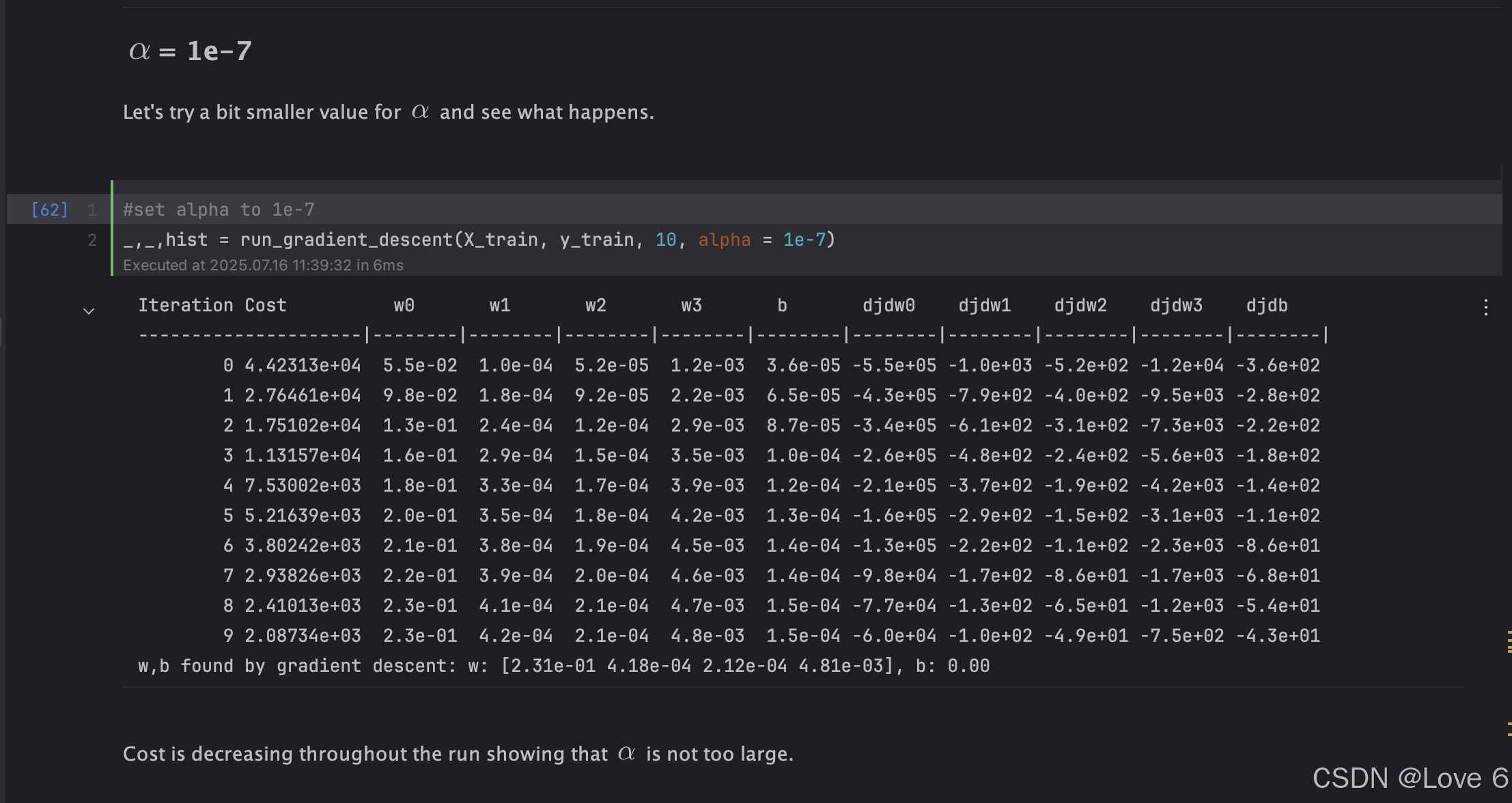
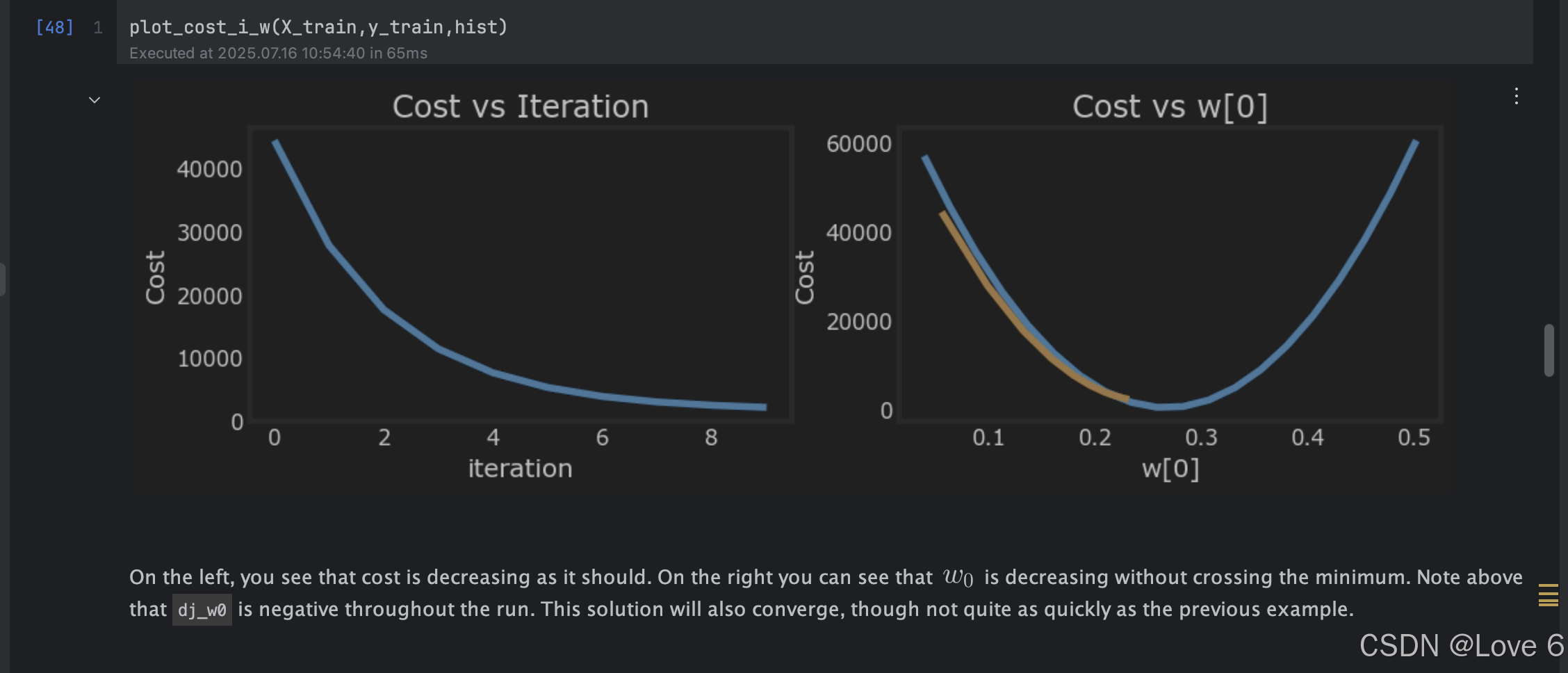
1e-7 能看出来这个学习率其实就比较合适 也没有存在反复来回横跳的情况
4、Feature Scaling 特征缩放
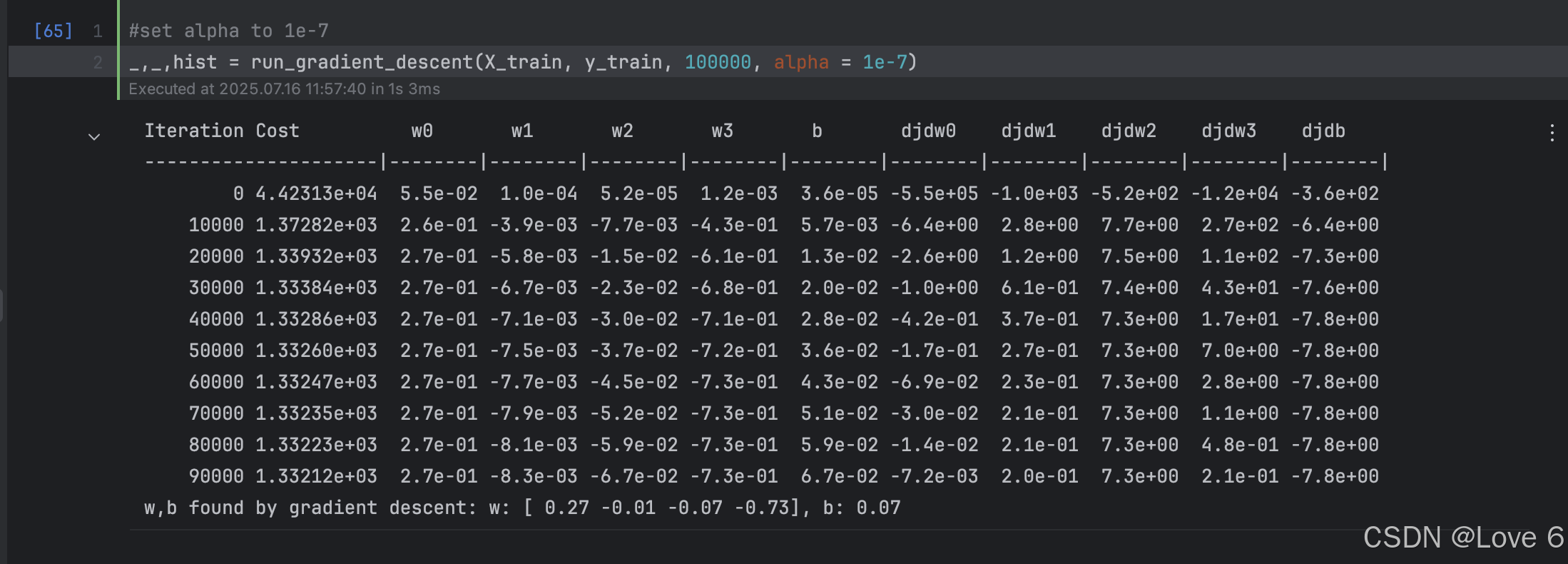
这里其实先可以观察一下 我们针对1e-7学习率 的不同的迭代次数
迭代10次 我们可以认为是shortrun 迭代100000次这种大次数的轮次 可以认为是long run
当我们没有进行 特征缩放的时候 因为其实看size 的取值范围是比较大的
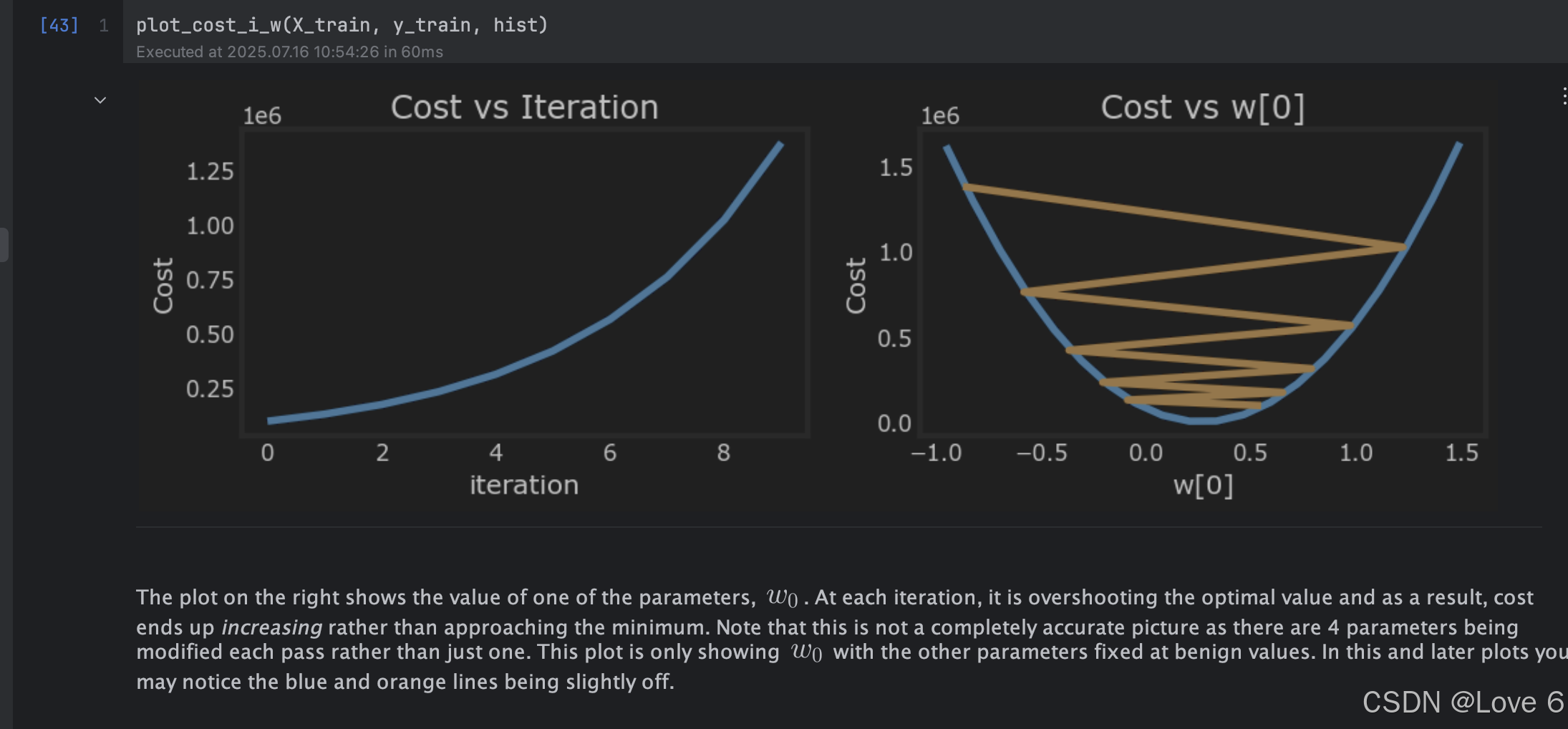
像这种情况下 其实就像下图二 可以看到数据非常不平均 而且这种情况下 我们对w这样迭代起来相对而言 是会更缓慢一些的
而我们这里只需要对数据做标准化 其实能看到 把数据映射到一个固定的区间 这样的情况下 数据是更加集中 密集的 不会像之前那么散
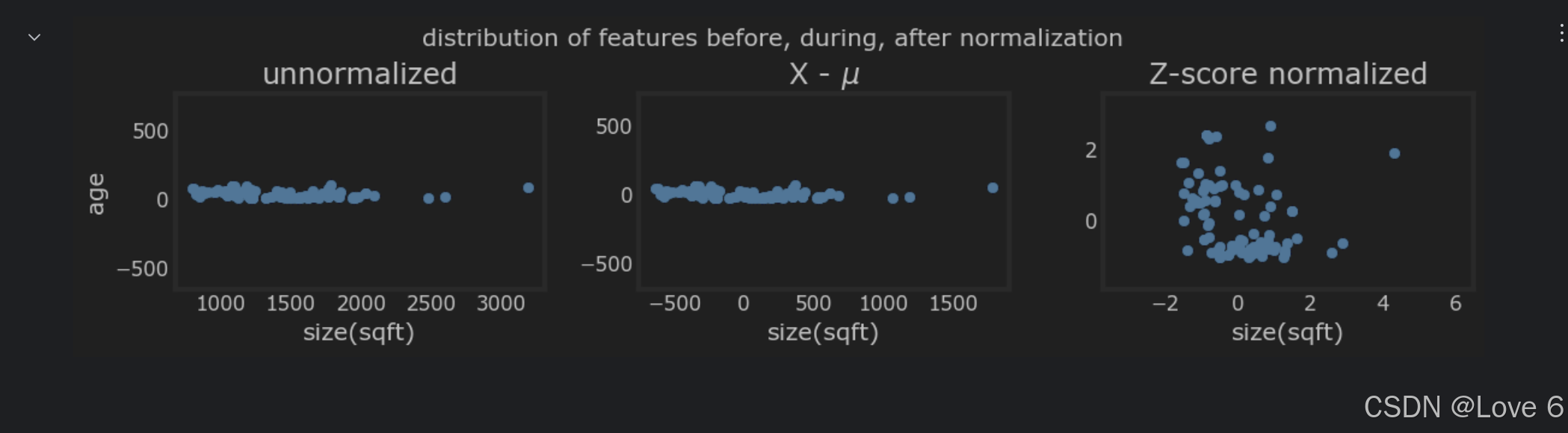
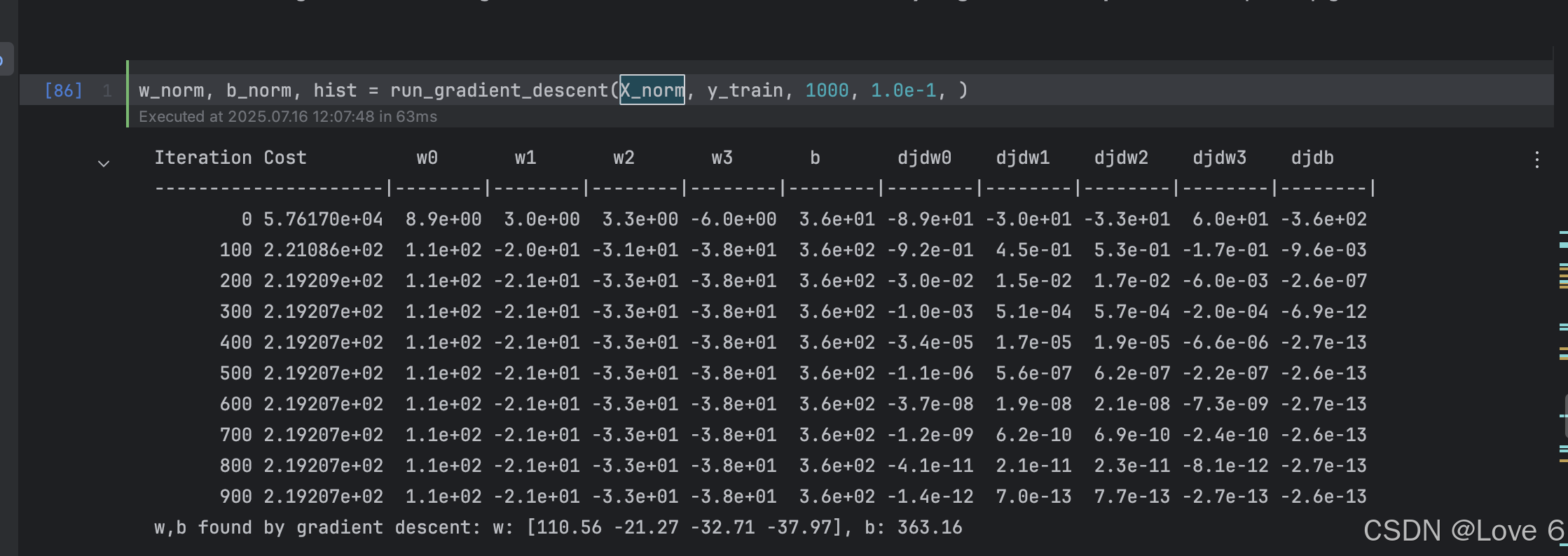
zscore_normalize_features 下面的代码即是 z-scores 标准化
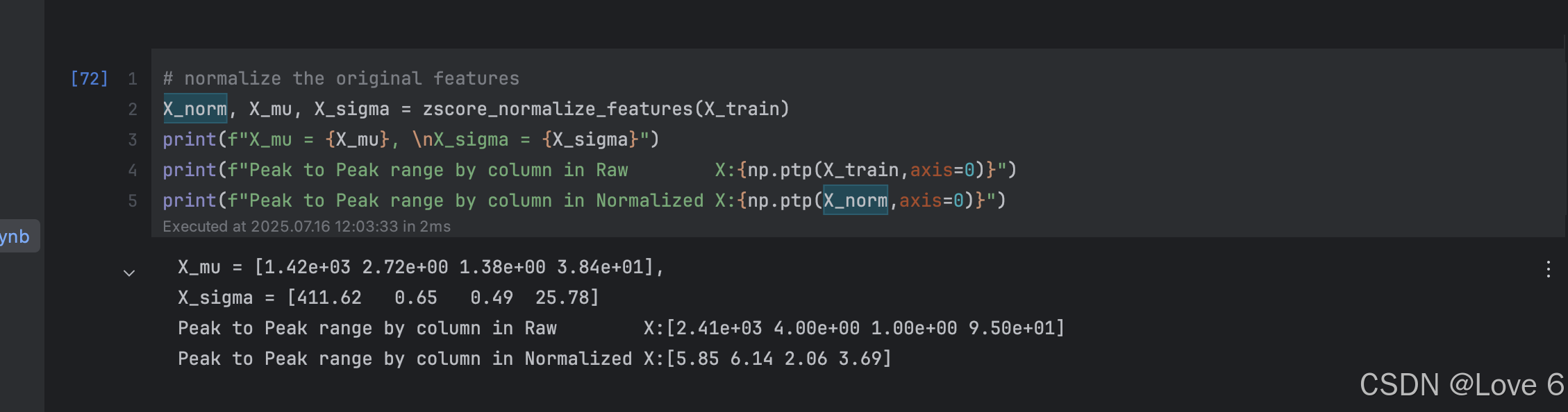
其实也就是一个公式 X - 均值 / 标准差
这里也即是对我们的数据进行处理
def zscore_normalize_features(X):
"""
computes X, zcore normalized by column
Args:
X (ndarray (m,n)) : input data, m examples, n features
Returns:
X_norm (ndarray (m,n)): input normalized by column
mu (ndarray (n,)) : mean of each feature
sigma (ndarray (n,)) : standard deviation of each feature
"""
# find the mean of each column/feature
mu = np.mean(X, axis=0) # mu will have shape (n,)
# find the standard deviation of each column/feature
sigma = np.std(X, axis=0) # sigma will have shape (n,)
# element-wise, subtract mu for that column from each example, divide by std for that column
X_norm = (X - mu) / sigma
return (X_norm, mu, sigma)
#check our work
#from sklearn.preprocessing import scale
#scale(X_orig, axis=0, with_mean=True, with_std=True, copy=True)
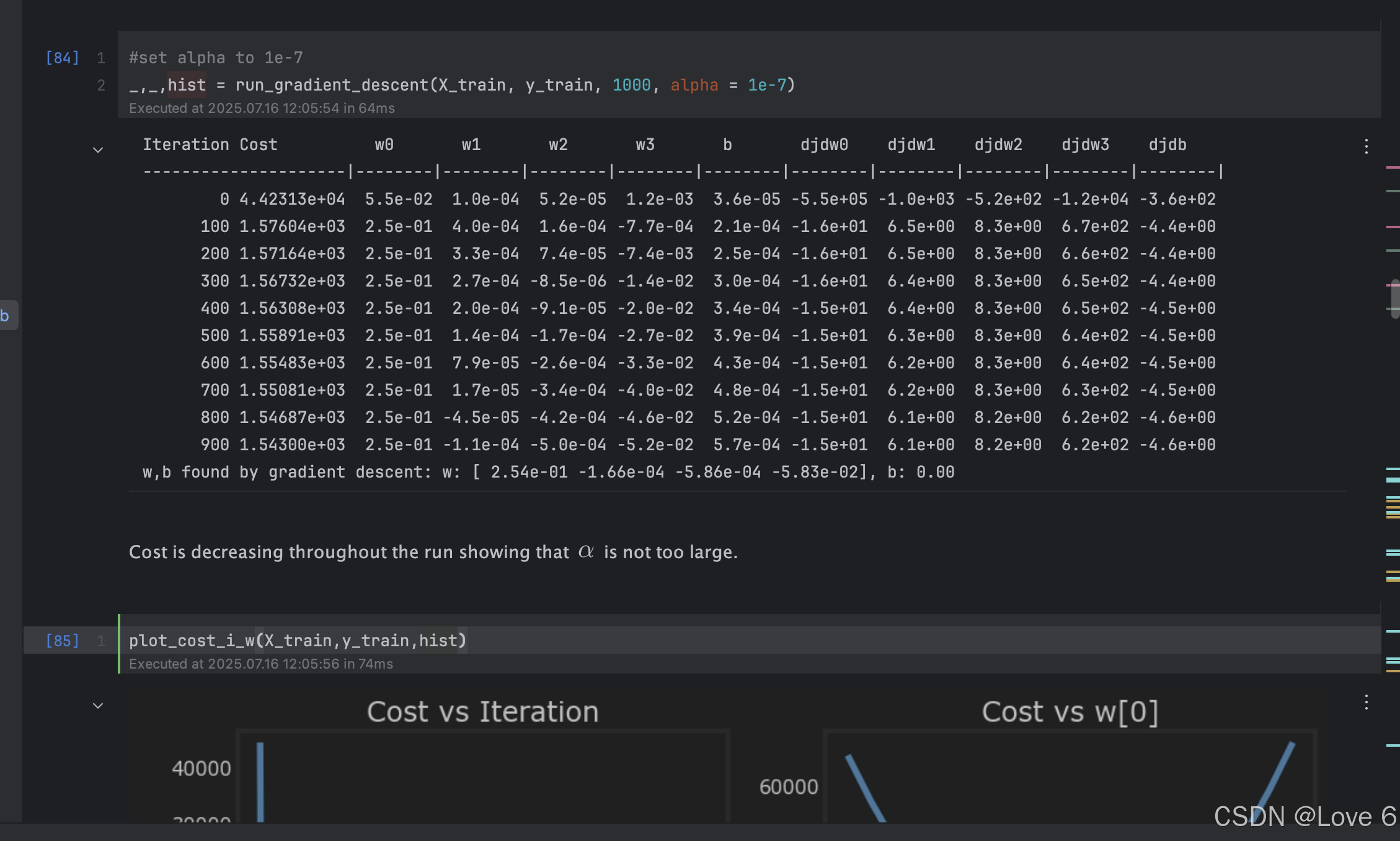
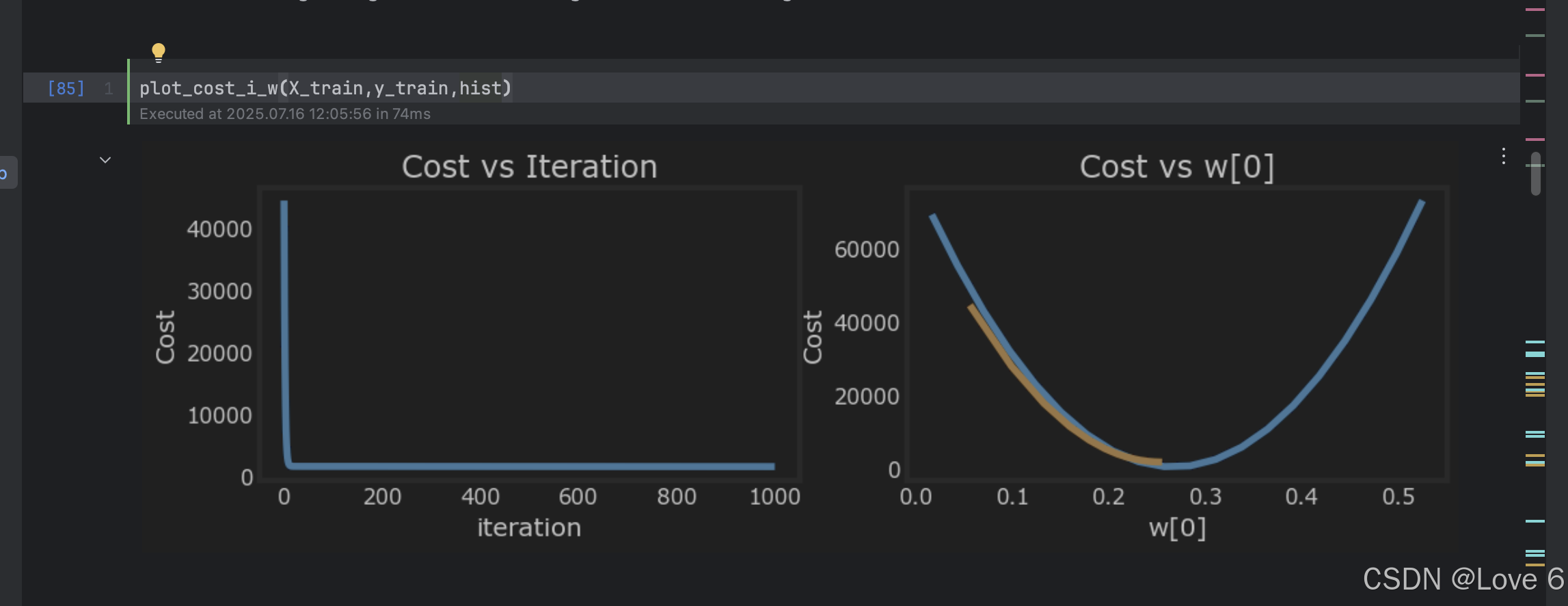
这里的数据是没有进行特征缩放的 可以看到迭代1000次 的开销是1.543e+03
而进行了特征缩放后 能看到其实在第100次的时候 开销就已经比上面削了 而且是趋近最低点了 后面的数据也基本维持不变了
大概实验就讲了这些 :)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)