大数据研发面经八股 - 持续更新
文章目录
1 Hadoop考点
1.1 HDFS分布式文件系统
1.1.1 原理&架构
请详细解释 HDFS 的架构组成及其作用?
- Client客户端、NameNode、Secondary NameNode和多个DataNode组成
- NameNode:管理数据的元数据,制定副本策略,处理读写请求
- DataNode:存储数据,执行实际的读写
- SecondaryNamenode:辅助NameNode,定期合并fsedits和fsimage,提交给NameNode,紧急情况可辅助恢复NameNode
- 实际过程中往往会启用两个或以上的NameNode实现高可用
HDFS 是如何实现数据的分布式存储的?
Block切片/元数据/副本
- 文件是以block数据块切片存储的
- 分别存储在不同的DataNode,默认备份3份
- NameNode管理元数据
HDFS的文件格式有哪些?
- 行式:Sequence File等,适合行读
- 列式:ORC File等,适合列读,写入慢,压缩率高
Block的大小设计?
- 太大:单个文件读取慢,例如为了读少量数据而读一整块
- 太小:小文件问题,占用元数据内存
1.1.2 读写流程
请详细描述在 HDFS 中客户端读取文件的流程?
并行
- 客户端->NameNode请求读取
- NameNode->客户端返回元数据
- 客户端->DataNode分别建立pipeline并行读取数据
- 客户端进行数据块的合并,返回结果
在 HDFS 中,客户端写入文件的流程是怎样的?
串行
- client提交写请求给NameNode
- NameNode检查权限,可以上传
- client对文件切片,请求上传第一个block
- NameNode根据副本数和机架感知,返回DataNode列表
- client依次建立pipeline,传数据,完成后进行校验,返回确认信息后进行下一个block的写入
在 HDFS 的数据读写过程中,如何保证数据的一致性/完整性/容错?
校验和
- 写入时,DataNode在收到数据块后会计算校验和;
- 读取时,客户端重新计算校验和,进行比较;
- 如果数据不一致会从其他地方重新读取。
- 此外,HDFS会定期要求DataNode返回数据块信息,与元数据比较后,对损坏的block的副本进行复制。
节点失效
- NameNode从SecondaryNameNode恢复
- DataNode由NameNode重新分配并拷贝副本
写数据失败了怎么办?
- pipeline会被关闭,ack queue中的packets被添加到queue的前面以保证数据不丢失
- 正常的DataNode上的Block id会升一级,与失败节点区分
- 继续通过pipeline写其他副本
1.1.3 Checkpoint过程
针对NameNode实现高可用的过程
- SecondaryNameNode发起,通知NN
- SNN从NN获取快照fsimage和日志fsedits,加载到内存,进行合并
- 合并后的快照传回NN作为新快照,日志文件重新开始
1.1.4 优缺点
优点
- 便宜地进行拓展
- 多副本 - 可靠
- 适合一次写多次读
- 方便处理大数据
缺点
- 不适合低延时场景
- 小文件不能过多
- 不好写 - 不支持并发写入;也不能随意修改数据
1.2 MapReduce
1.2.1 原理&架构
请详细解释 MapReduce 的工作原理,包括 Map 阶段和 Reduce 阶段的主要操作。
排序是Hadoop的灵魂。尽可能减少小文件
Map:将数据读取为键值对,并且按键值进行分区
Shuffle:每个Map Insistence输出的数据写入各自一个环形缓冲区。进行溢写、排序、规约,以减少Reduce的输入,并且使结果有序
Reduce:进行最终的数据合并与排序
MapReduce 的架构?
类似Yarn
- 客户端:提交任务,接收结果
- JobTracker:管理者,资源调度(资源是slot)。对任务进行切分,分配任务到TaskTracker,同时监控任务情况,任务失败时重新调度
- TaskTracker:执行具体的 Map 任务和 Reduce 任务,定期向 JobTracker 汇报任务的执行状态
规约Combine是什么?
在Map处理完键值对后,MapTask先对临时文件进行一次合并,使一个MapTask只产生一个文件,减少文件数
环形缓冲区为什么这么设计?
为了持续不停地处理数据,防阻塞
- 赤道区分索引和数据
- 占到80%了就对数据进行排序+溢写
- 剩下20%划分一个赤道,继续写
Map分区作用?
- 为了用多个reduce并行处理数据
- 根据实际需求产生多个输出的分区文件
1.2.2 优化
shuffle优化
- 减少shuffle次数
- 减少不必要的排序,一些reduce没必要排序
- 进行数据压缩
- 尽量在内存里处理
- 本节点的数据不走网络,直接去读
数据倾斜优化
-
参数解决
- 聚合时groupby.skewindata
- Join时skewjoin
-
Map阶段的优化
- 数据裁剪。从Map阶段开始,就需要进行数据量的裁剪了。包括通过where进行行裁剪、通过避免select *进行列裁剪、只取需要的分区等。
- **split和merge。**设置mapper.split.size和mapper.merge.size,即mapper的切分和合并,需要寻找合适的mapper数量。太多,则资源紧张时难以调度,太少,可能会单个读取任务时间过长。此外要兼顾读取的均匀
-
Join阶段的优化
-
大表Join小表:MapJoin,将小表加载到内存广播到大表的Map任务,减少了一次shuffle和Reduce。可以通过设置mapjoin.memory来加大内存
-
大表Join中表:Distribute MapJoin,将中表分散到多个节点的内存,大表通过网络方式进行分布式join,减少一次shuffle。但需要大表远大于中表,否则网络通讯的开销还蛮大的,而且现在需要自己算切分大小。shard count = 中表大小/500M ~ 中表大小/200M,取质数
-
大表Join大表:
- 手动方法。将主表里的热点值单拎出来Join,然后再合并
- 自动方法。通过skewJoin,自动的将热点值单独join做优化,优点是相比改代码简单一些,缺点是不自由,限制多。
-
用Join来过滤:Semi Join。只用来过滤数据,这样可以只加载join键,减少不必要的数据传输;
-
多个分区表Join:
-
常见于宽表,各维表往往具有不同主键,需要分别join,再join到主表。
-
分区表往往是对每个国家分区进行排序的,需要先按手动设置根据主键进行排序,然后再Join
-
-
-
GroupBy优化
- 用skewindata自动处理
- Cube表
- 尽量用GroupingSets那一套,Cube、Rollup,避免使用lateral view explode使数据膨胀
- 将不同去重指标分散到多个子查询,例如同时算item_count和sku_count。降低单个查询的复杂度以合理分配reduce
- 根据场景去选择count(1)和count(distinct),大量唯一用distinct,大量热点用count(1)
- 对热点值可以单拎出来聚合,再union all回去,不过要看业务
-
小文件写入动态分区时倾斜,可以用参数先Merge一下
-
数据集成时的倾斜
- 举例说一下OTS同步数据时,10TB+不均匀数据。算分布后手动切分
压缩格式?
- Snappy:shuffle的时候用,不支持split
- LZO:大文件用,支持split
- Gzip/Bzip2
1.3 Yarn
1.3.1 原理&架构
Yarn的主要功能?
- 资源管理+任务调度
- 将资源管理和任务调度分离,提高资源利用率,使不同程序可以在同一集群运行
Yarn的架构?
-
ResourceManager
- 核心。负责启动和监控ApplicationMaster,监控NodeMaster,维护和分配全局资源,分配封装在Container中的资源给到AppMaster
-
ApplicationMaster
- 管理单个程序的资源和调度。监控任务执行,向ResourceManager请求资源,向NodeManager分配资源
-
NodeManager
- 管理单个节点上资源。处理来自ResourceManager和AppMaster的命令,执行计算任务
Yarn的调度策略有哪些?
- 先进先出:先来的先分配。很简陋,大任务吃资源
- 容器调度。分多个容器,分别先进先出
- 公平调度。为每个任务相对公平地分资源,调度和监控比较复杂,开销较大
1.3.2 工作流程
工作机制?
- 用户向Yarn集群提交应用程序
- ResourceManager根据集群资源,在一个NodeManager上启动AppMaster并分配初始资源
- AppMaster向ResourceManager请求Container资源,在NodeManager上启动Task
- AppMaster持续监控并执行任务,可能申请新的资源
- 应用结束后,AppMaster通知ResourceManager,释放资源,资源返回集群资源池
1.3.3 优势
- 解耦了计算和资源调度。使资源调度更简单,资源利用率更高
- 解决了单点故障、单点压力大的问题。早期的JobTracker同时承担资源管理与任务管理,一旦故障会瘫痪整个集群,Yarn通过分布式架构实现了高可用,避免单点故障影响整个集群
- 主备ResourceManager
- 恢复NodeManager和AppMaster
1.4 ZooKeeper
1.4.1 原理&架构
Zookeeper是什么
-
观察者模式的分布式协调框架,将数据的变化通知观察者
-
功能:
- 文件系统存储功能
- 监听功能
-
服务(基于上面功能,提供的一些服务):
- 统一命名空间
- 统一配置管理和集群管理
- 心跳监控
- Master选举
- 分布式锁和事务操作:Znode路径唯一、事务的zxid唯一
Zookeeper的特性?
各种更新都基于事务,全部内存
- 顺序一致性:每个事务请求都会有递增唯一的zxid
- 一致性:事务的处理结果在整个集群上都是一致的
Zookeeper节点角色?
- Leader领导者:中心节点,负责协调集群中其他节点,不直接接受client请求,但接收Follower和Observer转发过来的client请求,进行事务写
- Follower跟随者:从节点,接收客户端请求并返回结果,不具有写权限
- Observer观察者:接收客户端连接,将写操作转给Leader,但不参与投票,只同步Leader节点的状态,是为了集群扩展而生的
Zookeeper数据结构?
- 类似Unix的树状结构,每个节点是一个Znode,Znode路径唯一
- ZNode区分两种类型:
- 短暂,客户端与服务器断开连接后,节点自行删除
- 持久,…,节点不删除
1.4.2 功能实现
Zookeeper怎么实现分布式锁?
排他锁
- 定义锁:通过一个ZNode表示一个锁
- 获取锁:创建表示锁的ZNode,其他想获得锁的节点watch这个锁
- 释放锁:客户端断联自动删除 or 客户端结束后主动删除
共享锁
- 按顺序id建立读锁
- 只有自己的id最小时才能写锁
ZK怎么保证一致性?
ZAB协议:原子广播协议 Zookeeper Atomic Broadcast
- 正常情况下:消息广播,主备模式架构保障一致
- 所有写操作都由Leader完成
- Leader将事务请求广播给所有Follower进行备份,超过半数返回ack应答则提交该事务。
- 重启/故障情况:崩溃恢复,进行选举
1.5 Hive
1.5.1 原理
简要介绍Hive
本质:将HQL翻译成MapReduce程序
- 提供类似SQL的查询语言,将存储在HDFS上的结构化文件映射为数据库表进行查询
- 是Hadoop的数仓工具,也可看成MapReduce的一个客户端
- 方便进行开发和维护
Hive与数仓的区别?
- Hive只是个数仓的工具
- 数仓是企业分析数据的一系列解决方案的集合
Hive的架构?
-
元数据MetaStore:元数据存在关系型数据库,通过metastore去连接mysql
-
解释器、编译器、优化器、执行器
- 解释器:将SQL转化为抽象语法树AST(词法、语法分析)
- 编译器:将AST编译成逻辑执行计划
- 优化器:对逻辑计划进行优化
- 执行器:逻辑计划转化为物理计划去交给计算引擎MR/Spark等执行
-
用户接口:Shell、JDBC、ODBC、Web
Hive的几种表
- 内部表:由Hive完全控制生命周期和存储,删除表会删除源文件
- 外部表:用于与其他系统共享数据,删除表只会删除Hive中的元数据
- 分区表:对数据按特殊规则划分存储的表,通过分区可以减少查询时的扫描数量
- 桶表:将数据按照一定的规则排列,用于提升关联性能
Hive的存储/计算引擎?
-
存储:
- 行式:TextFile、SequenceFile
- 列式:ORCFile、PARQUET
-
计算:
- MR
- Spark
- Tez:支持DAG作业,将原有的Map和Reduce两个操作简化为一个Vertex,绕过MR的很多不必要的中间存储和读取,在一个作业中通过一个大的DAG完成MR多个作业的功能
1.5.2 工作
几个By的区别?
- Order by 全局排序
- Sort by 分区内排序
- Distribute by 分区,一般结合分区排序用
- cluster by 当2、3的目标为同一字段时,可以用该方式代替,但不能再添加DESC了,使数据有序,提升后续查询操作效率
分区和分桶区别?
- 分区:粗粒度,分割成文件夹,数据裁剪
- 分桶:细粒度,文件夹里文件,关联迅速
Hive小文件问题?
- Mapper数量增加,启动开销大
- 占用元数据内存
Hive小文件解决?
- Map输入和Reduce输出阶段通过参数控制合并
- insert overwrite的时候在结尾Distribute by rand() 将数据随机分配给Reduce,使每个Reduce处理数据大致一样
- 使用sequencefile作为表存储格式,不用textfile
- 使用Hadoop的archive归档(写ddl)
几种COUNT
- Count(1): NULL也计数
- Count(*): NULL也计数,一般现在的SQL引擎都会优化一下,不会真的去读全部field,执行速度和count(1)大致相当
- Count(Column): 只统计非NULL column
1.5.3 优缺点
优点:
- SQL开发比较快,避免写MapReduce
- 处理大数据方便
- 支持用户自定义函数
缺点:
- HQL表达能力有限
- 效率较低
Hive与数据库的比较?
- 传统数据库面向事务处理OLTP,关心响应时间、面向事务的严格ACID、数据量较小
- Hive主要面向分析场景OLAP,数据冗余便于分析,处理海量数据
1.6 Spark
1.6.1 原理
Spark工作流程
- 先启动Driver程序,Driver注册一个SparkContext
- 资源管理器根据SparkContext分配并启动Executor
- Driver执行main函数,形成DAG图,根据宽依赖拆分成stage
- 每个stage对应多个task,task分给executor去执行
- 执行期间Executor和Driver会通信,报告执行状态
RDD
- 弹性分布式数据集
- 弹性
- 存储弹性:内存or磁盘
- 容错弹性:数据丢失可自动恢复(checkpoint,保存到HDFS)
- 计算弹性:计算出错可重试(血统机制,需要重新计算父节点)
- 分片弹性:可根据需要重新分片
- 分布式
- 数据集:RDD封装了计算逻辑,并不保存数据
- 不可变:封装的计算逻辑不可变
- 可分区到多个Executor并行计算
- 弹性
Spark特点
- 快。相比MR快很多:因为基于内存,并且高效DAG
- 易用,支持Java、Python、Scala等
宽窄依赖
- 窄依赖:一个父RDD最多被子RDD的一个分区使用
- 宽依赖:发生了shuffle,一个父RDD会被子RDD的多个分区使用,需要等待父RDD处理完成后才能往后处理。stage数量=宽依赖数量+1
任务调度
- Stage级:DAG schedule,切割DAG形成stage
- Task级:Task schedule,监控和管理一个stage中的tasks,交给空闲的executor
1.7 Flink
1.7.1 原理
简要介绍Flink
-
流批一体的数据处理框架
-
提供低延迟、高吞吐、高容错的数据处理
-
能够确保数据精准一次
Flink流批一体架构和Lambda架构对比
- Lambda同时维护两个系统(批处理、实时处理),数据不一致、维护复杂、重复计算
- Flink流处理架构,批处理可以看成流处理的一个子集,用一套框架去解决问题。
Flink架构
- Dispatcher:分发器,将应用移交给Jobmanager
- ResourceManager:资源管理器
- JobManager:控制一个应用程序的主进程,向ResourceManager申请资源,启动、注册、分配给slot
- TaskManager:包含slot插槽,用来执行任务
低延迟怎么理解?
- 数据从到达 -> 被处理的时间延迟很短
- Flink是流处理,不用攒一批数据再处理
- Flink基于内存,进行高效计算和内存分配/回收
- 异步IO,边读数边处理
高吞吐怎么理解?
- 单位时间数据处理量很多
- 低延时的哪些机制
- 分布式的,可并行处理
- 传输时通过序列化/反序列化,压缩数据量
高容错怎么理解?
- 定期保存checkpoint,可以迅速恢复数据
- 能够实现精准一次的数据处理
- 通过Hadoop实现的高可用
1.7.2 核心机制
checkpoint机制
某一时刻全部算子的state的全局分布式快照,一般存在磁盘上,轻量级,频率高,支持增量
- 容错:出错时,可从上一个checkpoint快速恢复数据
- savepoint:进行重启、升级、迁移时人工进行,存储所有状态数据和元数据,慢、贵
- checkpoint过程
- checkpoint协调器(Coordinator)向所有Resource节点触发CK
- source节点向下游广播barrier
- task完成CK后通知Coordinator
- sink节点将数据刷到磁盘
- Coordinator收集齐state后,会认为这一次CK完成了,向持久化存储中再备份一个checkpoint meta文件
- CK超时原因
- 反压了,迟迟等不到barrier,导致Task做不了CK
- 计算量大,Task一直在做计算,没时间CK
- State Size太大,执行超时
请解释Flink精准一次和至少一次的处理语义?
- 至少一次。保证不丢数据,通过checkpoint实现
- 精准一次。至少1次+至多1次
- 自身的事务性写入。基于checkpoint能力,分两阶段提交。只有通过checkpoint校验后才正式持久化
- 外部的幂等性系统。例如Hbase或者Mysql的唯一主键
Window类型
Window是无线数据流处理的核心,将一个无限的stream拆分成有限大小的桶,可以在桶上做计算
- 计数:CountWindow,指定数据条数
- 计时:TimeWindow
- 滚动窗口:固定窗口长度,窗口无重叠
- 滑动窗口:固定窗口长度,滑动参数控制窗口频率,窗口可重叠
- 会话窗口:根据不活动的时间间隔判断,超过一定时间没接收到数据,则下次接受数据时会分配到新session
Flink有哪几种时间?
- 事件时间(Event Time):数据产生的时间
- 摄入时间(Ingestion Time):数据进入Flink系统的时间
- 处理时间(Processing Time):数据实际被处理的时间(到达某一算子的时间)
Flink的水印(WaterMark)是什么?
不能无限期等待数据,WaterMark是关门机制
- 一种衡量事件时间event time进展的机制,代表这这个时间之前的数据都已经到达了
- 用处:
- 处理乱序数据。时间戳小于水印时间的数据,Flink会认为其已经到达,从而放心的对其进行处理
- 触发窗口计算。
反压怎么处理?
- 调上游的并发
- 开mini batch进行微批处理,减少状态更新次数、序列化/反序列化次数
- 倾斜调优
1.8 Kafka
1.8.1 原理&架构
Kafka介绍?
-
订阅式的分布式消息队列
- 不是“生产者消费者”模式,因为一个消息可以被多个消费者消费
-
可以保证消息的可靠传递与顺序
-
消息持久化,不会消失
-
解耦、削峰、异步
Kafka作用?
- 解耦:避免服务之间的强依赖关系,提高灵活性
- 异步:不用等待处理而阻塞主线程,提高整体性能
- 削峰:减少瞬时流量对系统的压力,将压力分散
Kafka架构?
- Broker:一台Kafka服务器就是一个Broker,一个Broker可容纳多个Topic
- Topic:队列的抽象,生产者往里写,消费者往外拿
- Producer:生产者,向Broker发消息
- Consumer:消费者,从Broker取消息,每个消费者负责消费不同分区的数据
- Consumer Group:消费者组,topic可以被多个消费者组消费,彼此不影响
- Partition:为了方便拓展并提高吞吐,一个Topic拆成多个分区
- Replica:副本,每个分区都由若干副本
- Leader:副本的主,会被消费
- Follower:副本的从,用于故障恢复
1.8.2 工作
Kafka怎么保障数据可靠?
- 副本机制。每个分区有多个副本
- 持久化。将消息持久化到磁盘
- ISR机制+ACK机制
- ISR:动态副本同步队列。类似读数据时的“木桶原理”,只有某个分区完成了所有副本的生成后,才允许读这个分区的数,保障安全
- ack:ISR中的follower完成同步后,会返回ack应答给leader,长期没收到就会把follower踢出ISR,加入OSR,当副本追上来之后还能加回ISR。OSR里的follower不能参加选举
Kafka怎么保障数据顺序?
- 每个分区都是有顺序的、不可变的消息队列
- 需要顺序的数据发到同一个分区
- 不同分区的顺序依赖外部系统
为什么一个消费者组里的消费者不能消费同一分区?
- 更多是消费方面的考量,而不是技术上的限制
Kafka如何实现高吞吐?
- 顺序读写
- 零拷贝:跳过用户缓冲区,建立磁盘和内存的直接映射
- 分区分段:分区并行消费,每个分区又分成多个段,每次文件操作的都是一个小文件,比较轻便
- 批量发送:攒一批消息一起发,减少IO
- 数据压缩
如何保证Exactly Once?
- 幂等性:不管向Broker发送多少条,只会持久化一条
- 至少一次:ack=-1,必须经过follower确认,才发送下一条消息
- 事务
1.9 ADB、HBase、Holo
1.9.1 ADB
一般用ADB for Mysql,关系型数据库,一般用在工程系统里做分析
- ADB分布式架构,Mysql通常单机
- ADB是列式存储,Mysql一般行存
- ADB进行了执行计划的优化
1.9.2 Hbase
列式Nosql,适合点查、高并发读写,高度依赖Rowkey设计
- Rowkey设计:唯一的,注意打散、控制长度,一起查询的数据放在一起
1.9.3 Hologres
兼容PostgreSQL,OLAP即席查询引擎,用在报表看数
- 表设计:
- DistributeKey。确定数据分布 - 尽量分布均匀,适用主键/实体id
- ClusteringKey。确定文件内数据排序 - 用于过滤字段,适用filter里的字段
- Bitmap Columns。文件外的索引 - 能够进行等值过滤,适用枚举值较少的过滤字段。
2 Hadoop综合
2.1 各种区别
2.1.1 架构差异
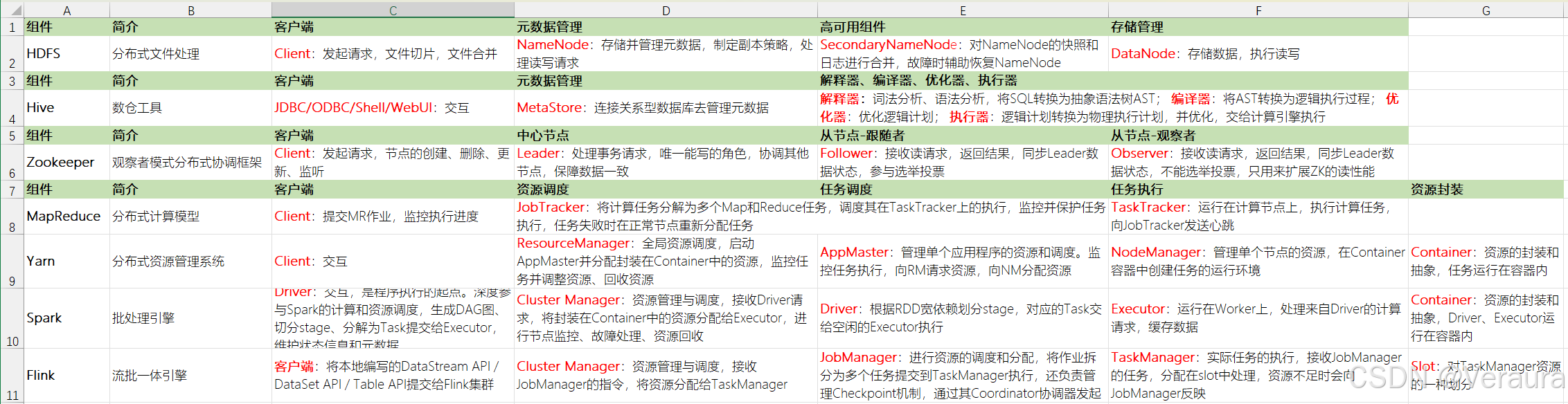
2.1.2 Spark vs Flink
设计理念
Spark用批模拟流,Flink用流模拟批
- Spark:微批处理模拟流计算,数据流按时间切分为多个批次,通过RDD批量处理
- Flink:原生面向流计算,对事件一行行的处理,但支持模拟批处理降低开销
架构
- spark:Driver驱动程序、ClusterMaster管理器、Worker工作节点、Executor执行器
- Driver:解析程序并生成DAG图,运行应用的main函数
- ClusterMaster:控制资源的主节点
- Worker:计算的阶段,启动Executor或Driver
- Executor:执行应用在某个worker上的任务
- flink:Dispatcher分发器、ResourceManager资源管理、JobManager应用控制、TaskManager工作节点、Slot槽位
- Dispatcher:启动应用并移交给JobManager
- JobManager:控制应用的主进程
- ResourceManager:管理TaskManager中的slot,分给JobManager
- TaskManager:管理槽位slot进行计算
- Slot:处理资源的单元
流处理方面
- spark只支持时间窗口
- flink窗口类型很多,count窗口、time窗口(滚动、滑动、会话)
容错机制
- spark:基于RDD的checkpoint,比较简单,将经常用的RDD或者宽依赖加Checkpoint,利用外部系统实现exactly once
- flink:基于Checkpoint的两阶段提交实现exactly once
机器学习
- spark:在内存中缓存中间结果来加速机器学习算法
- flink:支持运行时间内的有环数据流(相比spark的DAG有向无环图),训练更有效
Spark的优点
- 分布式RDD缓存比较强大, 和离线管理比较方便
- Spark的Executor挂掉不会使整个job失败,只是重启一个Executor
- 而flink某个taskmanager挂掉,任务就要重新从Checkpoint开始了
Flink的优点
- 面向事件驱动的真正流式计算,毫秒级计算(相比Spark的秒级)
- 窗口定义十分自由
- 反压机制使分布式队列满了之后被天然阻塞,而spark就需要额外构造一个”速率控制器“
- 有状态数据和Checkpoint容错上做的更好,能够做到exactly once
2.1.3 Hive vs Spark
基本概念
- Hive是数仓工具+查询引擎,而Spark只是取代Hive查询引擎的一种选择
Spark的进步
- 数据类型:几乎可以用Spark SQL处理一切存储介质和各种格式的数据
- 计算速度:把数仓的计算速度推向新高度,是MR的10~100倍(Hive on Spark和SparkSQL的速度差不多,但都比Hive on MapReduce快得多)
- 机器学习:用内存缓存中间结果来加速训练,并且可以让数仓直接使用机器学习的复杂算法
- 容错高:RDD可根据血统重建,通过Checkpoint保存状态
- 通用性:相比MR只有Map、Reduce操作,Spark包括Map、Filter、GroupByKey、ReduceByKey、Union、Join、Sort、Collect等更多操作(Transformation / Action)
Hive的优势
- 性价比高,相比Spark基于内存的模式,可以用处理更大量级的数据
Hive on Spark / Spark on Hive
- Hive on Spark:指Spark作为Hive的计算引擎,Hive仍管理元数据,只是底层会使用spark的作业来运行。
- Spark on Hive:指Spark处理Hive数据源的数据。
- 目前数据湖技术发展,出现了Spark+Hive结合的新形势:Spark Hive catalog,Spark通过Hive的metastore API来建立表 -> 文件的映射
Spark更快的原因
- Spark基于内存,MR基于磁盘
- Spark的DAG减少了数据落地磁盘的次数,并在大多数情况下可以减少shuffle个数
- 粗粒度申请资源,一次申请完、一次释放完,不会中途等资源,但这也导致集群资源利用不充分
2.1.4 Hive vs 传统数据库
- 文件系统
- Hive使用HDFS分布式文件系统
- 关系型数据库多使用服务器本地的文件系统
- 计算模型
- Hive是MapReduce
- 处理问题
- Hive数仓离线场景
- 数据库侧重OLTP实时性能
- 拓展性
- Hive很容易进行拓展
2.1.5 数据湖 vs 数据仓库
- 存储格式
- 数据湖:各种各样,以自然格式存储。
- 数据仓库:结构化、半结构化数据。
- 整理程度:
- 数据湖:比较原始,侧重于把数据存下来。如果不规范化数据管理,可能会变成数据沼泽
- 数据仓库:面向主题进行建模,比较稳定,用于决策
- 灵活程度:
- 数据湖:缺乏结构性,因此更灵活,适合用于训练机器学习和创新型分析
2.2 维度建模
2.2.1 事实表、维度表
事实表的分类
- 事务事实表:基于原子事务建立,如每一笔订单,每一条流量日志
- 详实记录了业务的具体细节
- 注意事实的完整、可加、一致性
- 周期快照事实表:按固定周期记录状态,例如商品每天的价格、库存等
- 用于分析趋势和状态变化
- 累积快照事实表:跟踪业务过程中的关键变化。例如商家的live时间、selling时间
- 展示流程的时间跨度和状态变化,优化业务流程
事实表和维度表的拆分依据
- 用途
- 事实表:主要包含可度量的数值型数据,是业务过程中产生的事实
- 维度表:围绕实体的属性和描述去构建,数据变化较慢
- 粒度
- 事实表:通常细粒度,是原始的业务明细
- 维度表:较粗的粒度,对事实的一种划分和总结
怎么确认哪些维度可进行蜕化?
- 维度特征频繁参与对事实的度量,作为分析的重要内容之一
事实表构建的过程?
- 确认业务过程
- 确认粒度
- 确认维度
- 确认指标
2.2.2 元数据
元数据在整个数仓生命周期中的作用?
- 建设阶段
- 昭示着数据的来源、数据的类型、数据的关系,指导建模过程
- 数据集成阶段
- 数据源之间的映射与转换
- 记录并保障数据的规范质量与完整性
- 数据存储与管理
- 发现存储、计算浪费
- 发现无效节点
- 发现不合规依赖
- 管理数据权限与安全
- 分析与使用
- 帮助用户理解使用数据
- 促进数据探索与发现

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)