基于机器学习的抑郁症分析(高分原创+真实数据集)
·
基于机器学习的抑郁症分析 - 数据预处理篇
项目背景
抑郁症是当今社会一个严重的心理健康问题,尤其在青少年群体中日益突出。本项目旨在通过机器学习方法,分析影响青少年抑郁症的各项因素,为心理健康研究提供数据支持。
数据来源
本项目使用了心理健康测评数据集,包含了多个维度的调查数据:
- 基础人口统计学信息(年级、年龄、性别等)
- 家庭背景(是否留守儿童、是否独生子女等)
- 心理健康指标(抑郁症状、压力水平等)
- 自伤/自杀倾向评估
自杀行为数据的不均衡性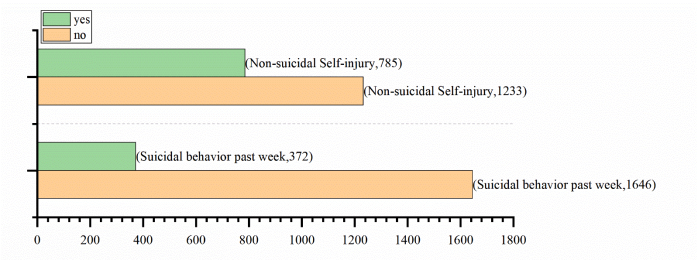
从图中可以看出,自杀行为(Suicidal behavior)表现出明显的不均衡性。具体地:
① 没有发生过自杀行为的组(标记为“no”)中,过去一周发生自杀行为的数量为372。
② 有发生过自杀行为的组(标记为“yes”)中,过去一周发生自杀行为的数量为1646。
可以看到自杀行为在有和没有历史自杀行为的群体中分布极不均衡。对于机器学习模型,如果训练数据在某些类别上的分布远不均匀,模型可能会倾向于忽视那些较少出现的类别,因为这样做在统计上会提高它的整体准确率,但这通常会牺牲模型对小众类别的预测性能。
数据展示
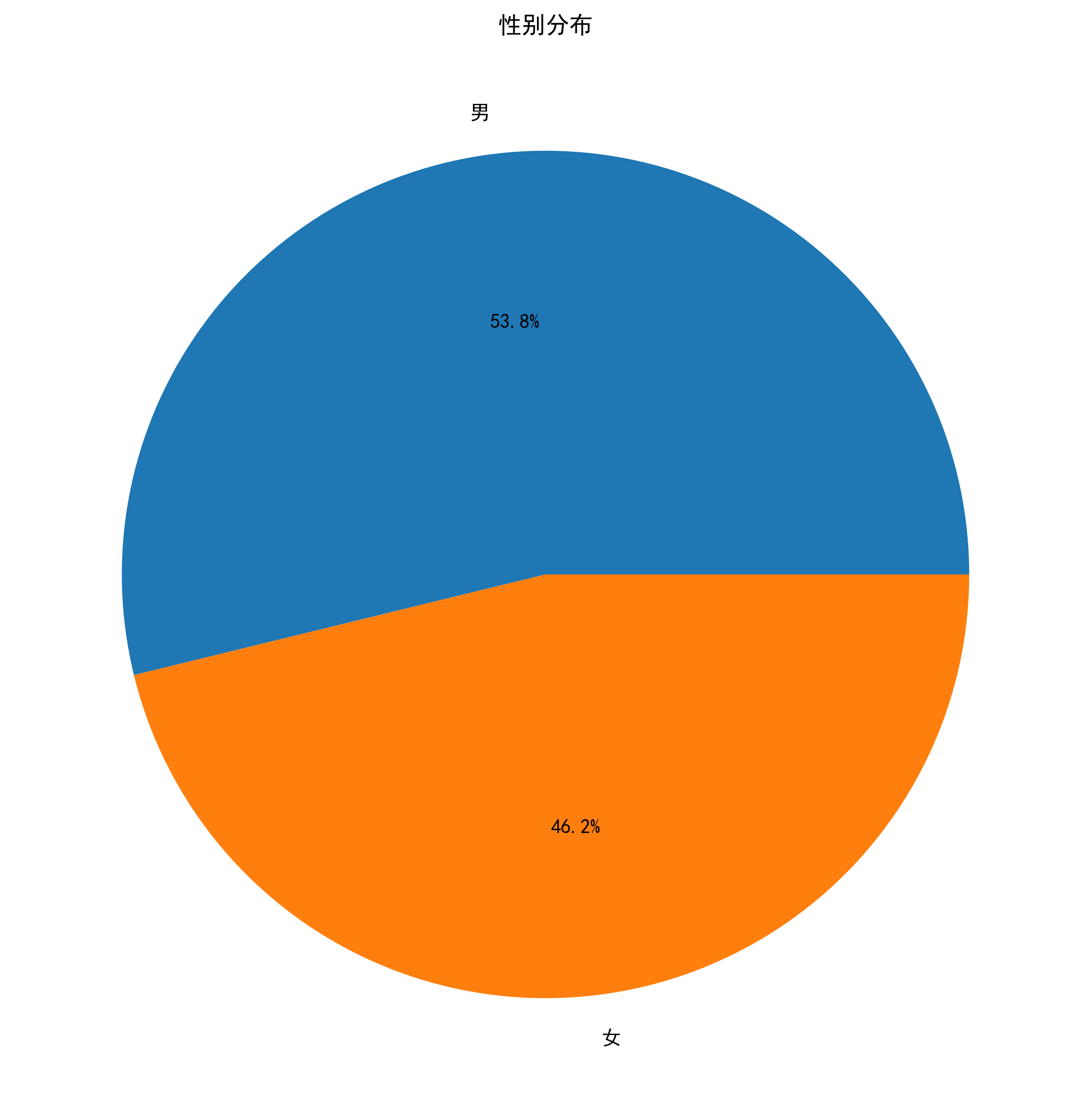
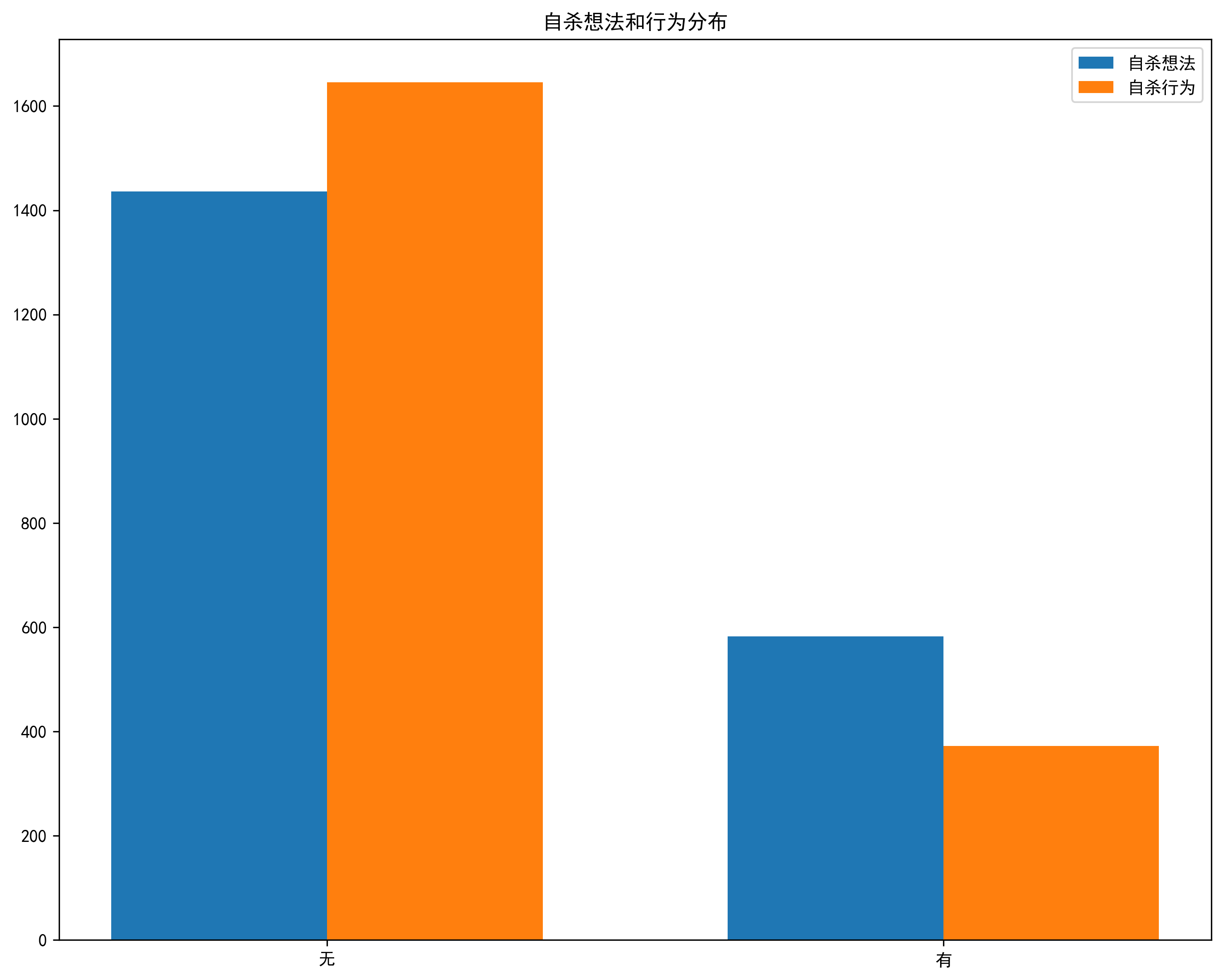
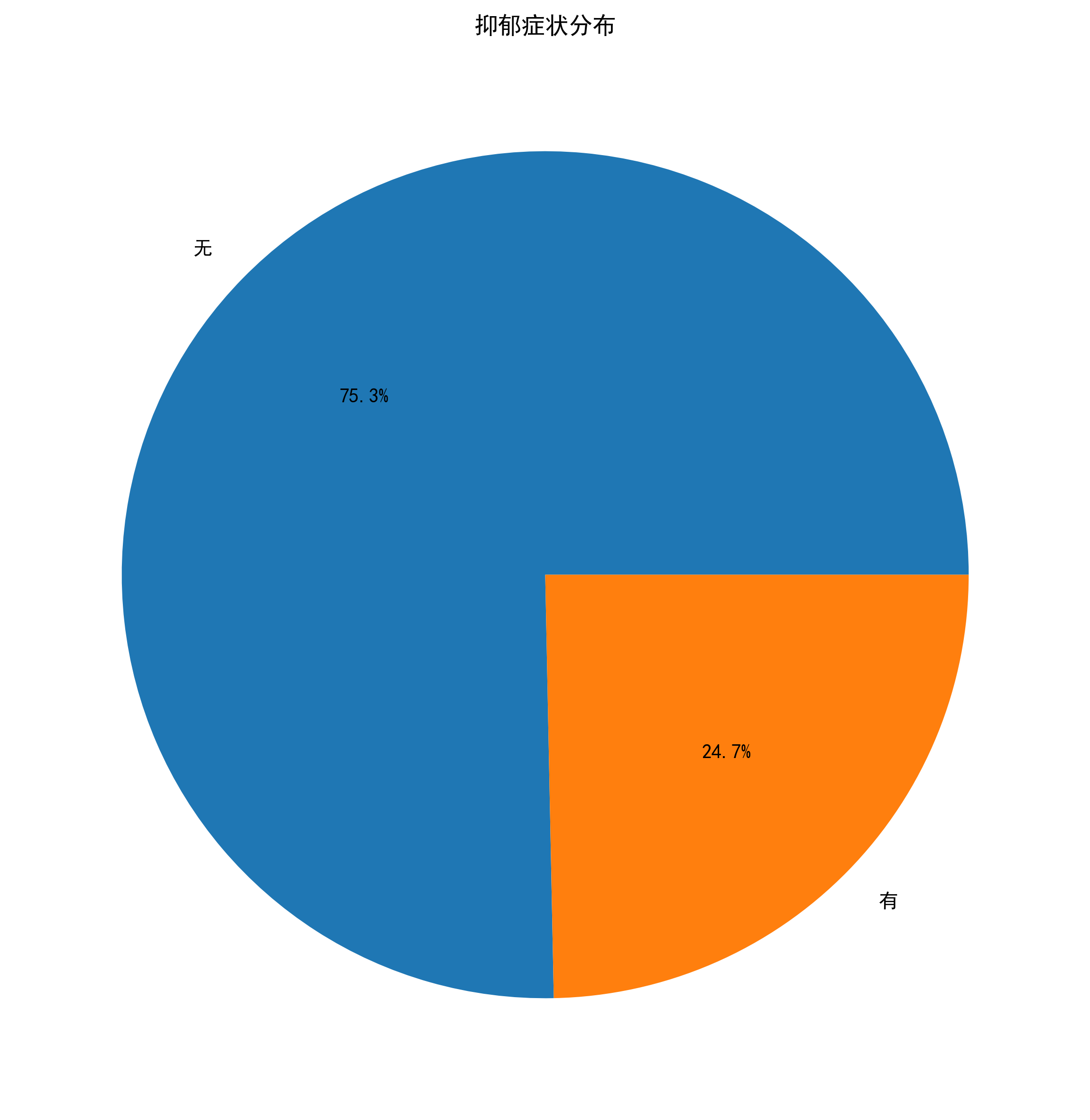
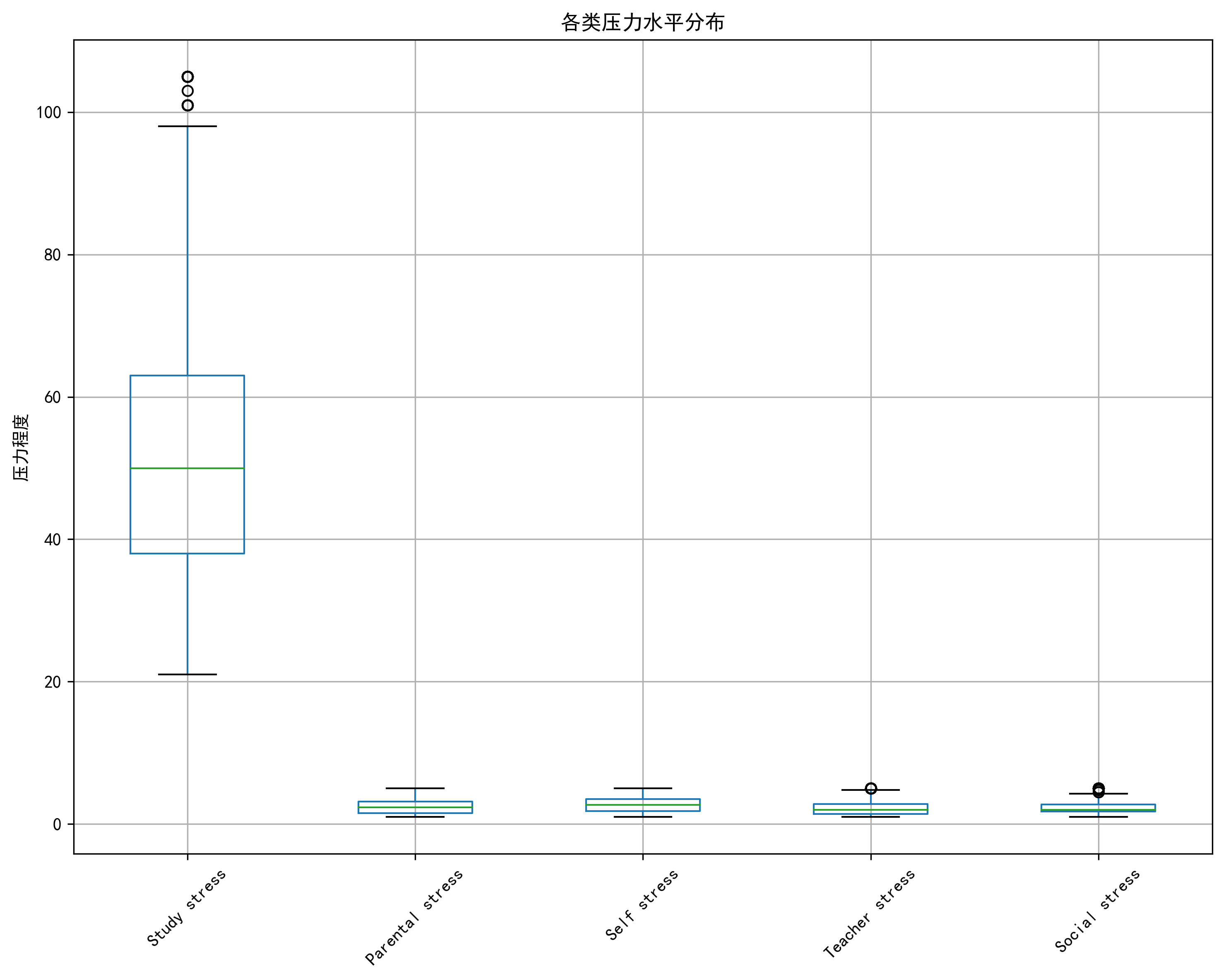
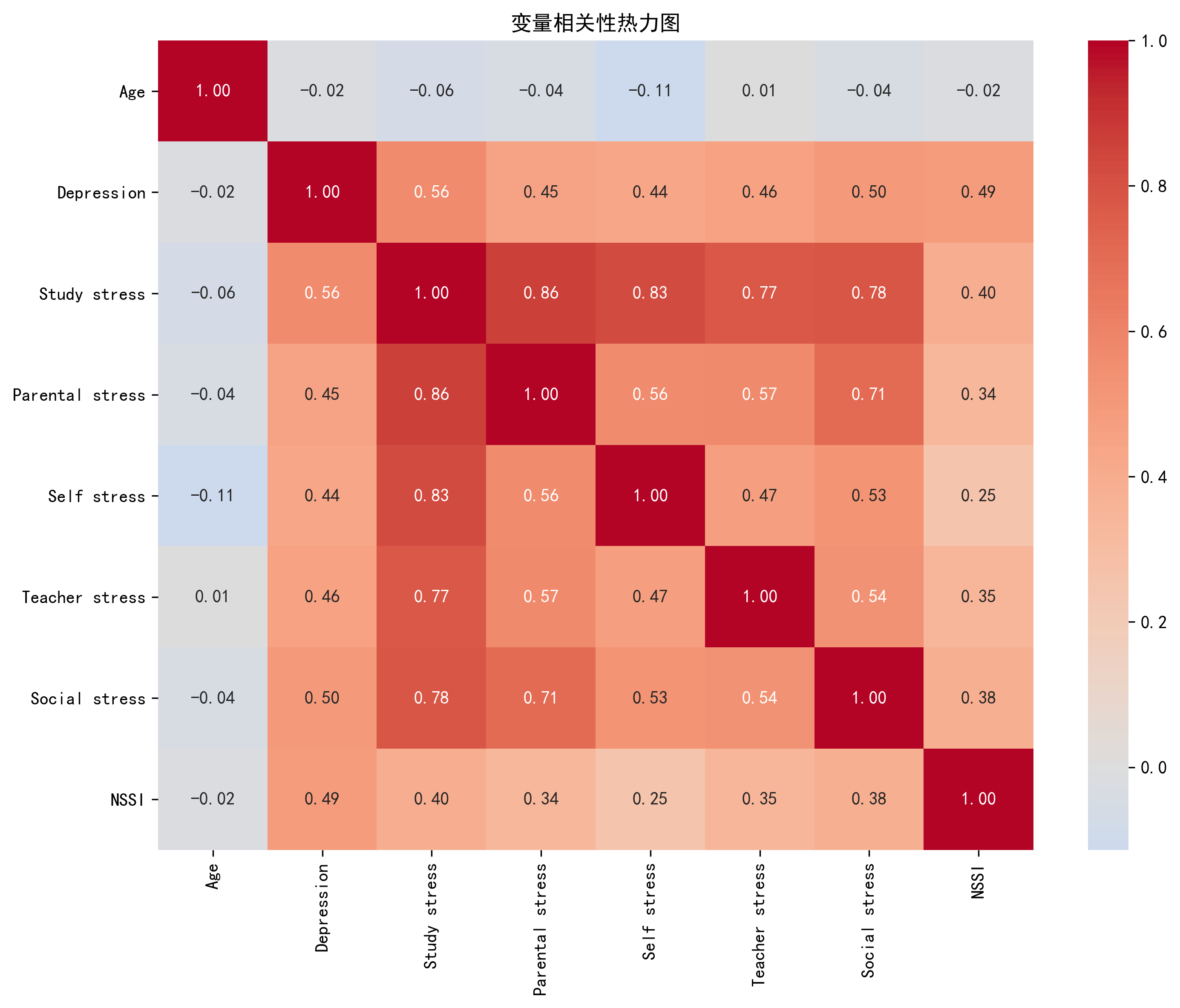
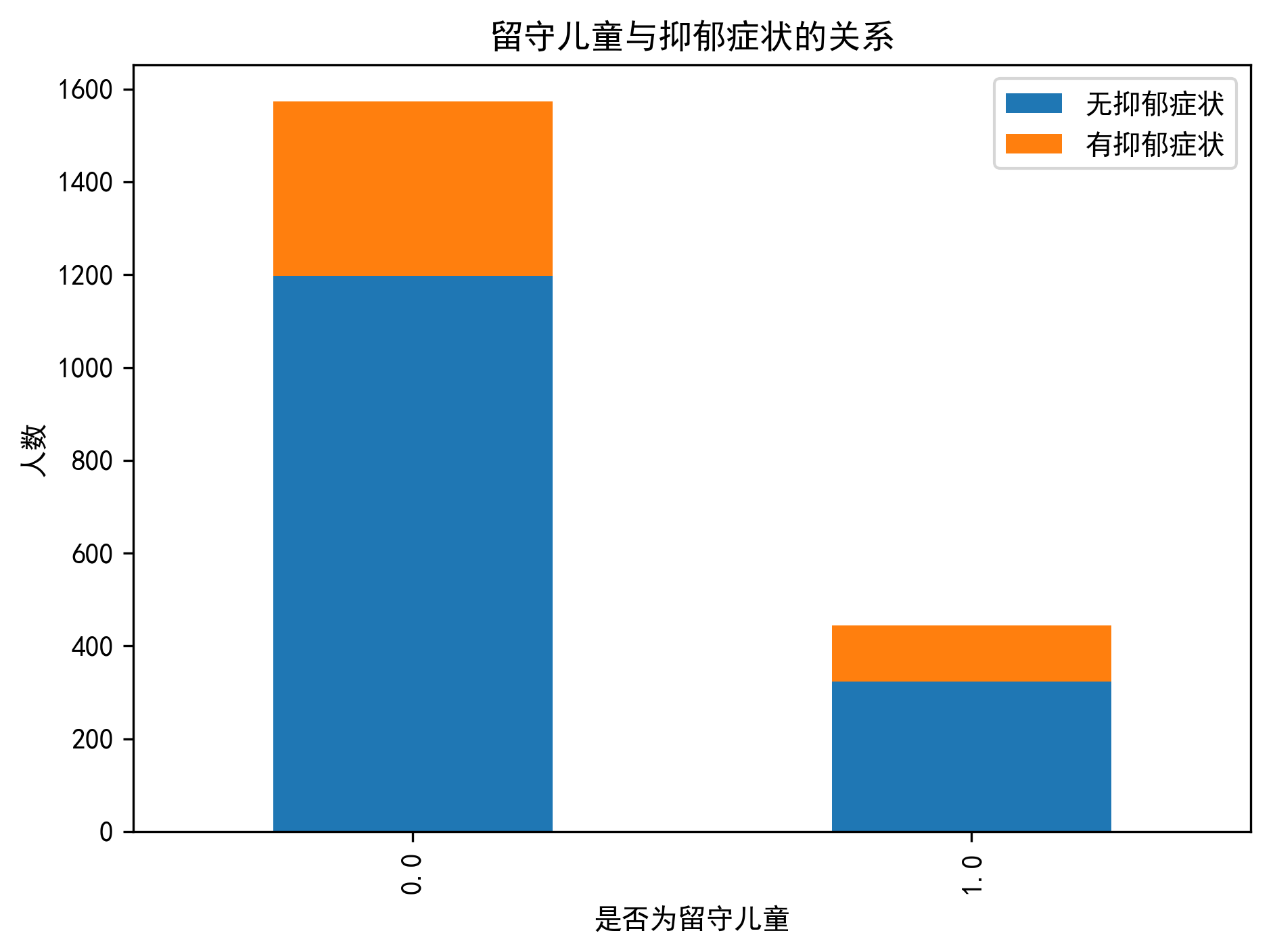
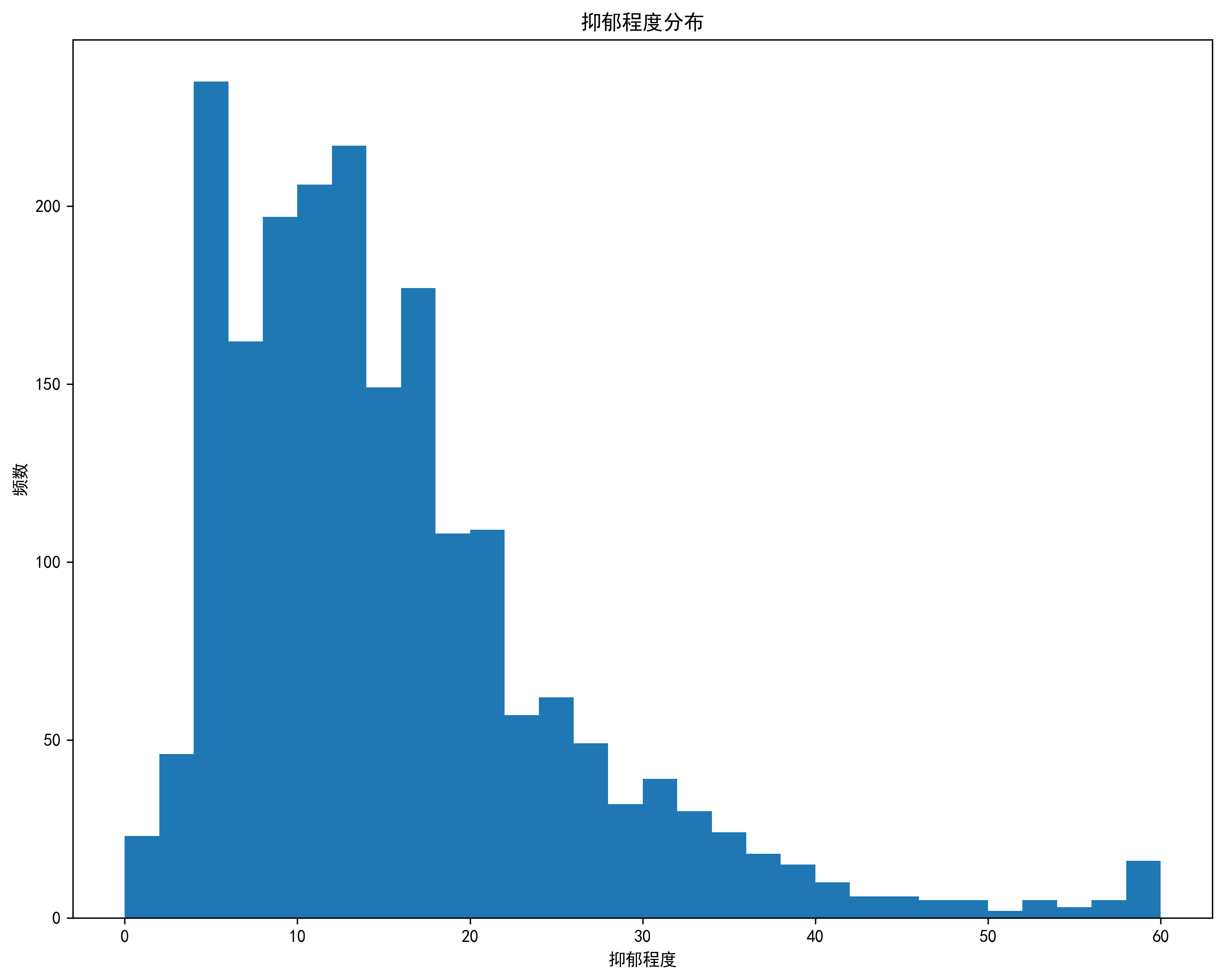
1. 数据读取
使用pandas读取Excel文件中的Sheet2工作表:
df = pd.read_excel('251096941_0_心理健康测评_2018_2018(4).xlsx', sheet_name='Sheet2')
2. 特征选择
从原始数据中选择了17个关键列,包括:
- 基础信息列(年级、年龄、性别等)
- 心理状态相关列
- 压力评估相关列
selected_columns = df.iloc[:, [0, 1, 2, 3, 4, 5, 6, 7, 28, 29, 55, 57, 58, 59, 60, 73, 75]]
3. 数据编码转换
定义了多个映射字典,将文本数据转换为数值型:
- 性别编码:男=1,女=0
- 布尔值编码:是=1,否=0
- 城乡编码:城市=1,农村=0
- 抑郁症状编码:无=0,有=1
- 年级编码:初三=2,初二=1,初一=0
- 自杀想法/行为编码:没有=0,有过=1
4. 数据清洗
- 使用第一行作为列名
- 删除重复的第一行数据
- 重置索引
- 统一数据类型为float
# 人口统计学变量处理
selected_columns['2、年级'] = selected_columns['2、年级'].map(nj_dict)
selected_columns['4、性别'] = selected_columns['4、性别'].map(sex_dict)
selected_columns['5、是否为留守儿童'] = selected_columns['5、是否为留守儿童'].map(bool_dict)
selected_columns['6、居住所在地'] = selected_columns['6、居住所在地'].map(city_dict)
selected_columns['7、是否为独生子女'] = selected_columns['7、是否为独生子女'].map(bool_dict)
# 标签列处理
selected_columns['8、最近一年内,有过自杀想法吗?(自杀想法)'] = selected_columns['8、最近一年内,有过自杀想法吗?(自杀想法)'].replace('考虑过一次', '考虑过1次')
# 转换'8、最近一年内,有过自伤想法吗?'列
selected_columns['8、最近一年内,有过自杀想法吗?(自杀想法)'] = selected_columns['8、最近一年内,有过自杀想法吗?(自杀想法)'].map(zs_to_number_dict)
# 转换'9、最近一年内,有过自伤行为吗?'列
selected_columns['9、最近一年内,有过自杀行为吗?(自杀行为)'] = selected_columns['9、最近一年内,有过自杀行为吗?(自杀行为)'].map(zs_to_number_dict)
selected_columns['是否具有抑郁症状'] = selected_columns['是否具有抑郁症状'].map(yyz_dict)
selected_columns['同时存在NSSI与SA'] = selected_columns['同时存在NSSI与SA'].map(bool_dict)
5. 特征重命名
将中文列名转换为英文,便于后续处理
selected_columns.columns = ['Grade', 'Age', 'Gender', 'Whether a left-behind child', 'Residential address',
'Only child', 'SI', 'SA', 'Depression', 'Depressive symptoms',
'Study stress', 'Parental stress', 'Self stress', 'Teacher stress', 'Social stress', 'NSSI',
'NSSI_SA']

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)