【MapReduce】招聘数据清洗
招聘数据清洗
1.数据集
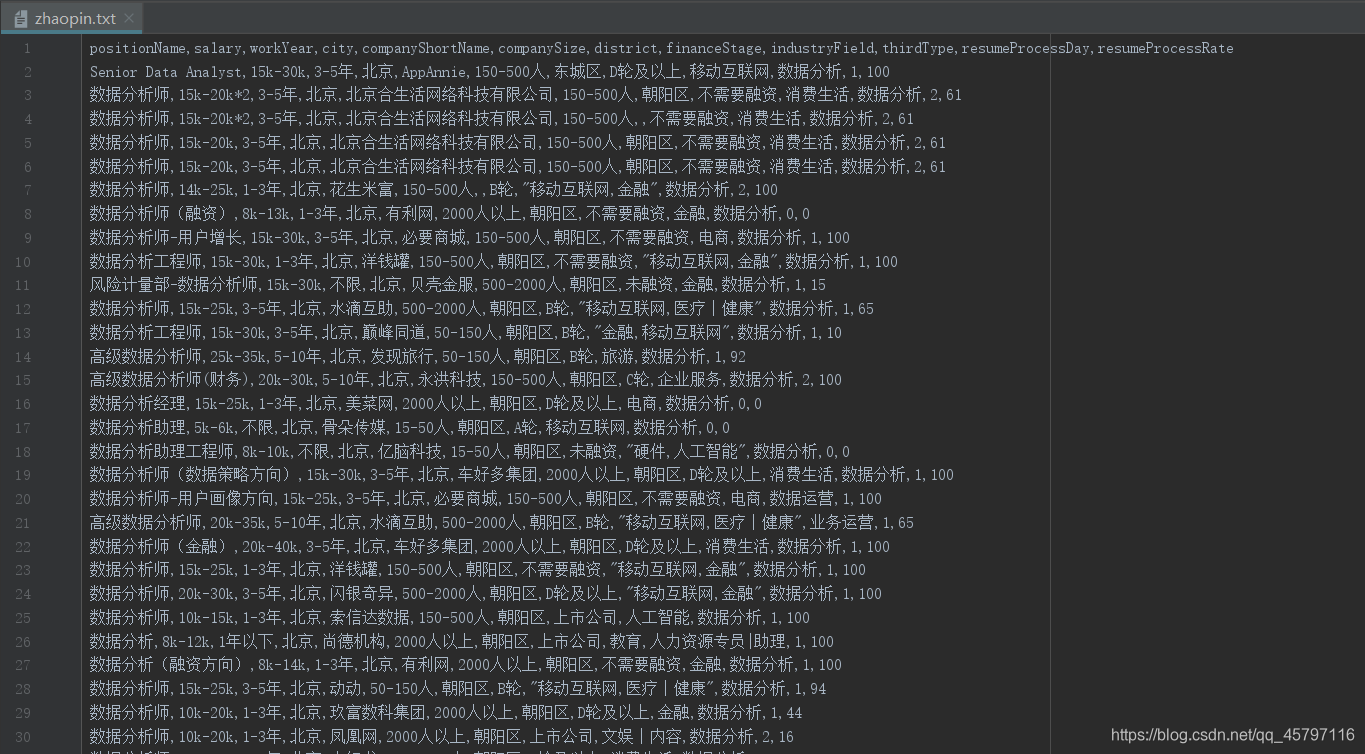
如上图所示,有一份招聘信息数据集,以下是本人人为创造出的清洗条件:
- 包含有两条含有空值的数据
- 两条重复的数据集
返回顶部
2.清洗目标
- 去除数据的首行字段记录
- 对含有空值的记录进行去除
- 对记录进行去重
- 对薪资进行处理,将其结果展示为最高薪资与最低薪资的均值
3.思路
- 去除数据的首行字段记录 ----
字符串比较开头,选择性忽略 - **对含有空值的记录进行去除 ----
isEmpty()** - 对记录进行去重 ----
利用Reduce阶段Key的特性 - 对薪资进行处理,将其结果展示为最高薪资与最低薪资的均值 ----
字符串截取,类型转换计算
4.代码执行
♦ Mapper阶段
package 招聘数据清洗;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class Map extends Mapper<LongWritable, Text, Text, NullWritable> {
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/* 前几行数据
positionName,salary,workYear,city,companyShortName,companySize,district,financeStage,industryField,thirdType,resumeProcessDay,resumeProcessRate
Senior Data Analyst,15k-30k,3-5年,北京,AppAnnie,150-500人,东城区,D轮及以上,移动互联网,数据分析,1,100
数据分析师,15k-20k*2,3-5年,北京,北京合生活网络科技有限公司,150-500人,朝阳区,不需要融资,消费生活,数据分析,2,61
。。。。。。
数据分析师,14k-25k,1-3年,北京,花生米富,150-500人,朝阳区,B轮,"移动互联网,金融",数据分析,2,100
*/
// 1.首先不读取包含有字段名的一列
if (value.toString().startsWith("\uFEFFpositionName"))
return;
// 2.获取一行数据,拆分
// 3.注意在字段值中含有分隔符的不予以拆分
String[] fields = value.toString().split(",(?=(?:[^\"]*\"[^\"]*\")*[^\"]*$)", -1);
// 4.判断是否有空值 --- 去空
if (valid(fields)) {
// 5.处理薪资
// 15k-20k*2
if (fields[1].contains("*")) {
// 拆分获取最大、最小值
String[] salary = fields[1].split("\\*"); // todo 15k-20k -- 2
System.out.println(salary[1]);
String[] salarys = salary[0].split("-"); // todo 15k 20k
int max = Integer.parseInt(salarys[1].trim().substring(0, salarys[1].length() - 1)) * Integer.parseInt(salary[1]);
int min = Integer.parseInt(salarys[0].trim().substring(0, salarys[0].length() - 1));
fields[1] = (max + min) / 2 + "k";
} else { // 15k-20k
// 拆分获取最大、最小值
String[] salary = fields[1].split("-");
int max = Integer.parseInt(salary[1].trim().substring(0, salary[1].length() - 1));
int min = Integer.parseInt(salary[0].trim().substring(0, salary[0].length() - 1));
fields[1] = (max + min) / 2 + "k";
}
// 6.获取完整数据
StringBuffer sb = new StringBuffer();
for (int i = 0; i < fields.length; i++) {
sb.append(fields[i]).append("\t");
}
k.set(sb.toString());
// 6.将完整数据写出
context.write(k, NullWritable.get());
}
}
// 4.判断是否是空值
boolean valid(String[] fields) {
boolean flag = true;
for (String item : fields) {
if (item.trim().isEmpty()) {
flag = false;
break;
}
}
return flag;
}
}
♦ Reducer阶段
package 招聘数据清洗;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class Reduce extends Reducer<Text, NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
// 直接写出
context.write(key,NullWritable.get());
}
}
♦ Driver阶段
package 招聘数据清洗;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Driver {
public static void main(String[] args) {
try {
// 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 配置
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setJarByClass(Driver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 配置文件输入输出路径
Path in = new Path("G:\\Projects\\IdeaProject-C\\MapReduce\\src\\main\\java\\招聘数据清洗\\data\\zhaopin.txt");
Path out = new Path("G:\\Projects\\IdeaProject-C\\MapReduce\\src\\main\\java\\招聘数据清洗\\output");
FileInputFormat.setInputPaths(job,in);
FileOutputFormat.setOutputPath(job,out);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out)){
fs.delete(out,true);
}
// 提交job
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (Exception e){
e.printStackTrace();
}
}
}
♦ 结果输出
结果如下图所示,最终输出记录96条。原始数据100条(1条字段,2条包含空值记录,1条重复记录)。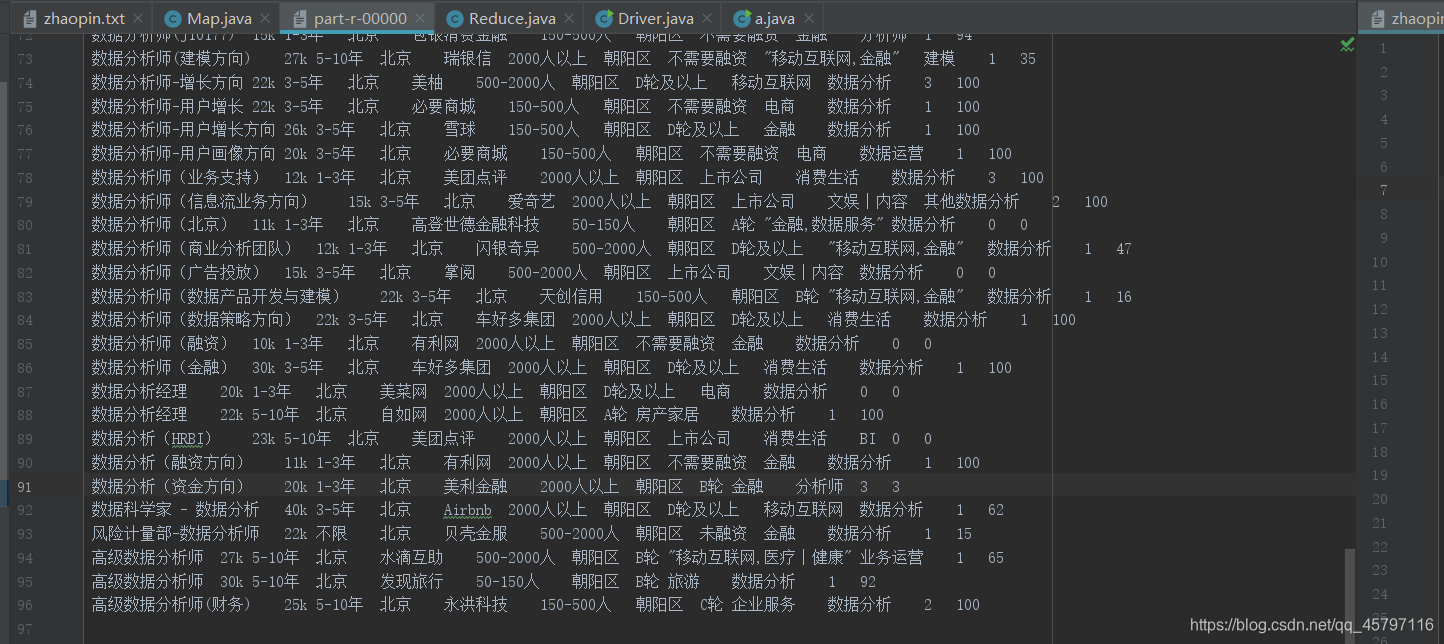
5. 坑
one
//1.首先不读取包含有字段名的一列
if (value.toString().startsWith("\uFEFFpositionName"))
return;
这个地方,存在一个文档编码格式的问题,查了一下叫BOM。BOM(byte-order mark),即字节顺序标记,它是插入到以UTF-8、UTF16或UTF-32编码Unicode文件开头的特殊标记,用来识别Unicode文件的编码类型。对于UTF-8来说,BOM并不是必须的,因为BOM是用来标记多字节编码文件的编码类型和字节顺序(big-endian或little- endian)。而UTF-8中,每个字符的编码有多少位是通过第一个字节来表述的,而且没有big-endian和little-endian的区分。
UTF-8 不需要 BOM,尽管 Unicode 标准允许在 UTF-8 中使用 BOM。所以不含 BOM 的 UTF-8 才是标准形式,在 UTF-8 文件中放置 BOM 主要是微软的习惯(顺便提一下:把带有 BOM 的小端序 UTF-16 称作「Unicode」而又不详细说明,这也是微软的习惯)。
BOM是为 UTF-16 和 UTF-32 准备的,用于标记字节序(byte order)。微软在 UTF-8 中使用 BOM 是因为这样可以把 UTF-8 和 ASCII 等编码明确区分开,否则用Excel打开CSV文件有可能是乱码的。但这样的文件在 Windows 之外的操作系统里会带来问题。「UTF-8」和「带 BOM 的 UTF-8」的区别就是有没有 BOM。即文件开头有没有 U+FEFF。
参见:java utf-8带bom格式内容(带"\uFEFF")转换成utf-8格式
two
/* 前几行数据
positionName,salary,workYear,city,companyShortName,companySize,district,financeStage,industryField,thirdType,resumeProcessDay,resumeProcessRate
Senior Data Analyst,15k-30k,3-5年,北京,AppAnnie,150-500人,东城区,D轮及以上,移动互联网,数据分析,1,100
数据分析师,15k-20k*2,3-5年,北京,北京合生活网络科技有限公司,150-500人,朝阳区,不需要融资,消费生活,数据分析,2,61
。。。。。。
数据分析师,14k-25k,1-3年,北京,花生米富,150-500人,朝阳区,B轮,"移动互联网,金融",数据分析,2,100
*/
//1.首先不读取包含有字段名的一列
if (value.toString().startsWith("\uFEFFpositionName"))
return;
// 2.获取一行数据,拆分
// 3.注意在字段值中含有分隔符的不予以拆分
String[] fields = value.toString().split(",(?=(?:[^\"]*\"[^\"]*\")*[^\"]*$)", -1);
数据分析师,14k-25k,1-3年,北京,花生米富,150-500人,朝阳区,B轮,"移动互联网,金融",数据分析,2,100
这个地方也是个大坑,在切分数据记录的时候,一般就会人为按照 "," 进行,但是留心,本数据集中的industryField字段值使用 " " 括起来的,并且中间的分隔符也是 " ,",这样一来,如果分割的时候直接写 " ,",后面就会出现fields的length大小问题。所以此处需要使用正则表达式进行截取的规范。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)