NVIDIA CUDA 编程指南:GPU 并行计算的“圣经”级入门宝典
NVIDIA CUDA 编程指南:GPU 并行计算的“圣经”级入门宝典
大家好!如果你对 GPU 加速、AI 训练、高性能计算感兴趣,那 NVIDIA CUDA Programming Guide(CUDA 编程指南)绝对是你不能错过的官方文档。它是 NVIDIA 为开发者量身打造的“圣经”,最新版对应 CUDA 13.x 系列(截至 2025 年 12 月),全面取代了旧版的 CUDA C++ Programming Guide。


(上图:经典 CUDA Logo 和 CUDA Python 平台宣传图)
这份指南通俗易懂,从零基础到高级优化,一步步教你如何用 CUDA 在 NVIDIA GPU 上编写高效并行程序。无论你是学生、科研人员还是工程师,都能从中获益巨大。
CUDA 编程模型的核心:线程层次与内核
CUDA 的精髓在于并行执行:一个任务被拆分成成千上万的线程,同时在 GPU 上运行。
- 线程组织:线程 → Block → Grid(网格)。Block 内线程可以共享内存,Grid 可以覆盖整个问题规模。
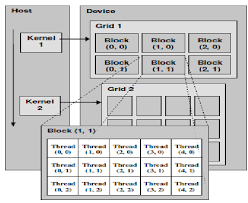
Thread Hierarchy in CUDA | Download Scientific Diagram
(上图:CUDA 线程层次结构示意图,清晰展示 thread、block、grid 的关系)
- 内存层次:全局内存(大但慢)、共享内存(快但小)、寄存器等。合理使用能让性能飞升。
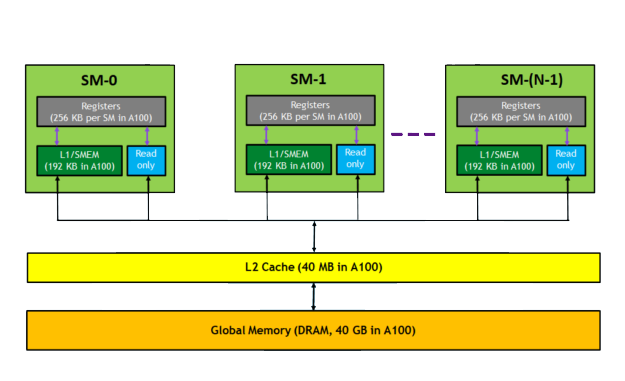
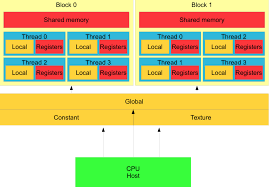
(上图:GPU 内存层次结构,帮你理解为什么优化内存访问这么重要)
入门实战:写一个“Hello World”级 CUDA 内核
指南用 CUDA C++ 教你从简单例子开始。经典的向量加法内核:
C++
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void addVectors(int n, float *a, float *b, float *c) {
int idx = blockIdx.x * blockDim.x + threadIdx.x; // 计算当前线程的全局索引
if (idx < n) {
c[idx] = a[idx] + b[idx];
}
}
int main() {
int N = 1 << 20; // 1M 元素
float *a, *b, *c; // 主机端指针
float *d_a, *d_b, *d_c; // 设备端指针
// 分配主机和设备内存
cudaMallocManaged(&a, N*sizeof(float));
cudaMallocManaged(&b, N*sizeof(float));
cudaMallocManaged(&c, N*sizeof(float));
// 初始化数据
for (int i = 0; i < N; i++) {
a[i] = i;
b[i] = i * 2;
}
// 启动内核:<<<grid, block>>>
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
addVectors<<<blocksPerGrid, threadsPerBlock>>>(N, a, b, c);
cudaDeviceSynchronize(); // 等待 GPU 完成
// 检查结果(简单验证前几个)
printf("c[0] = %f, c[1] = %f\n", c[0], c[1]); // 应该输出 0, 3
cudaFree(a); cudaFree(b); cudaFree(c);
return 0;
}编译运行:nvcc vector_add.cu -o vector_add && ./vector_add
这代码展示了内核定义(__global__)、线程索引计算、内存分配和内核启动。
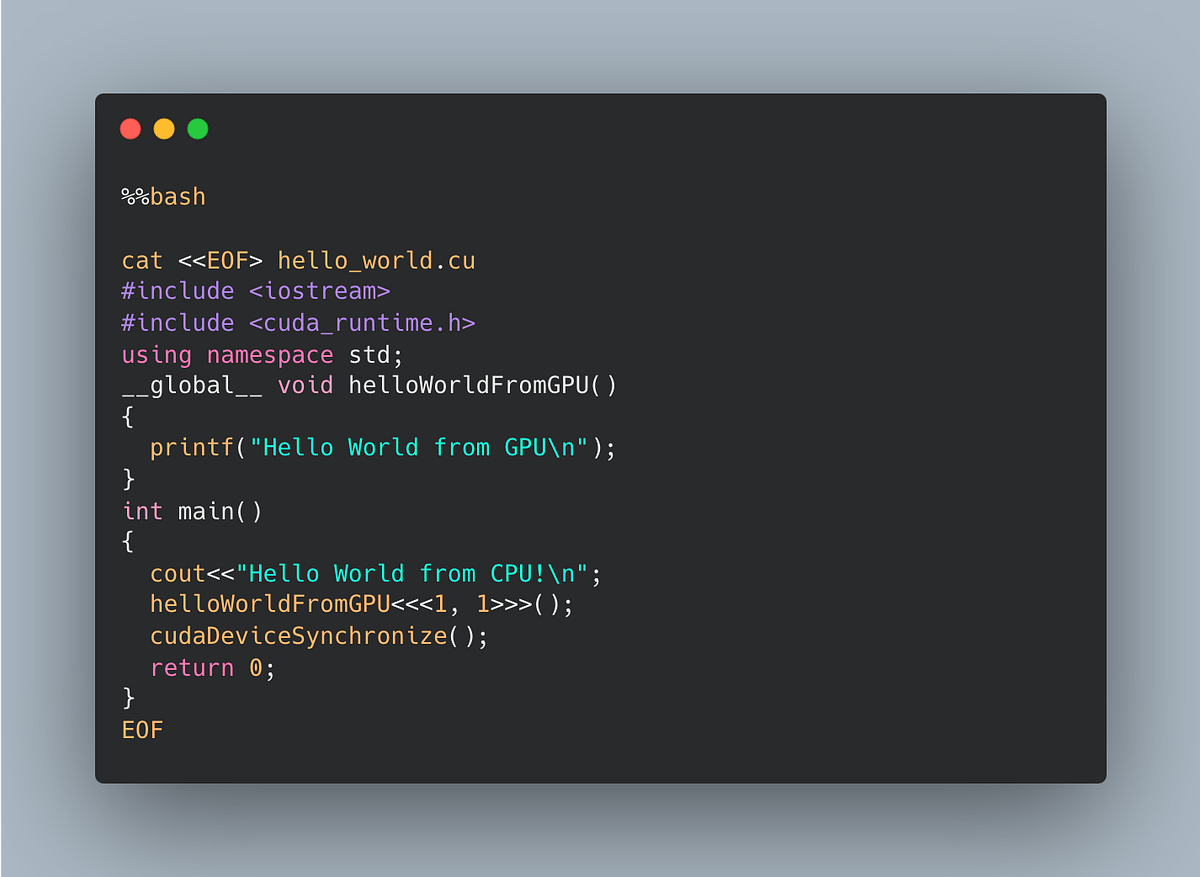
Your very own CUDA kernel!. Where I get you started with CUDA ...
(类似经典 CUDA 内核代码示例截图)
高级特性:让程序更强大
指南深入介绍:
- Unified Memory:自动在 CPU/GPU 间迁移数据,简化编程。
- CUDA Graphs:减少内核启动开销,适合重复任务。
- Dynamic Parallelism:内核里动态启动子内核。
- Tensor Cores 支持:AI 加速必备。
- 与最新 Blackwell 架构结合(如 Tensor Memory Accelerator)。


(上图:NVIDIA Blackwell 架构,CUDA 13.x 的完美搭档)
为什么推荐阅读这份指南?
- 结构清晰:分成入门模型、C++ 编程、高级特性、具体功能和技术附录。
- 实战导向:大量代码示例、性能建议。
- 前向兼容:涵盖最新 CUDA 13.x 特性(如 CUDA Tile 简介)。
官方链接(强烈推荐直接阅读): NVIDIA CUDA Programming Guide
如果你用 PyTorch/JAX 等框架,这份指南也能帮你理解底层优化。入门 CUDA,从这里开始准没错!有问题欢迎评论区讨论 🚀

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 17
17 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)