单阶段目标检测器 -YoloV1
·
YoloV1-单阶段目标检测器
1. 动机
第一篇one stage的文章,将分类任务和回归任务结合在一起做,不需要anchor,输入图片后直接得到图片中物体的bbox以及对应的class。
2.方法概要
- 输入:图片
- 输出:(S×S)∗2(S\times S)*2(S×S)∗2个bbox的(x,y,w,h),以及(S×S)∗2∗20(S\times S)*2*20(S×S)∗2∗20的类别向量(Pascal VOC dataset),还有(S×S)∗2(S\times S)*2(S×S)∗2的表示每个bbox中有没有物体的概率(01二分类)。
- 流程:将原石图片划分为(S×S)(S\times S)(S×S)的grid,然后根据GT 物体的中心落在哪一个grid去划分该GT物体由哪个grid来负责检出。x y w h具体形式应该是和yolo本身的GT产生标准有关系,然后去分grid回归预测,每个grid会给两个bbo x的指标去进行回归预测,因此划分为7x7的grid后,会输出98个bbox。
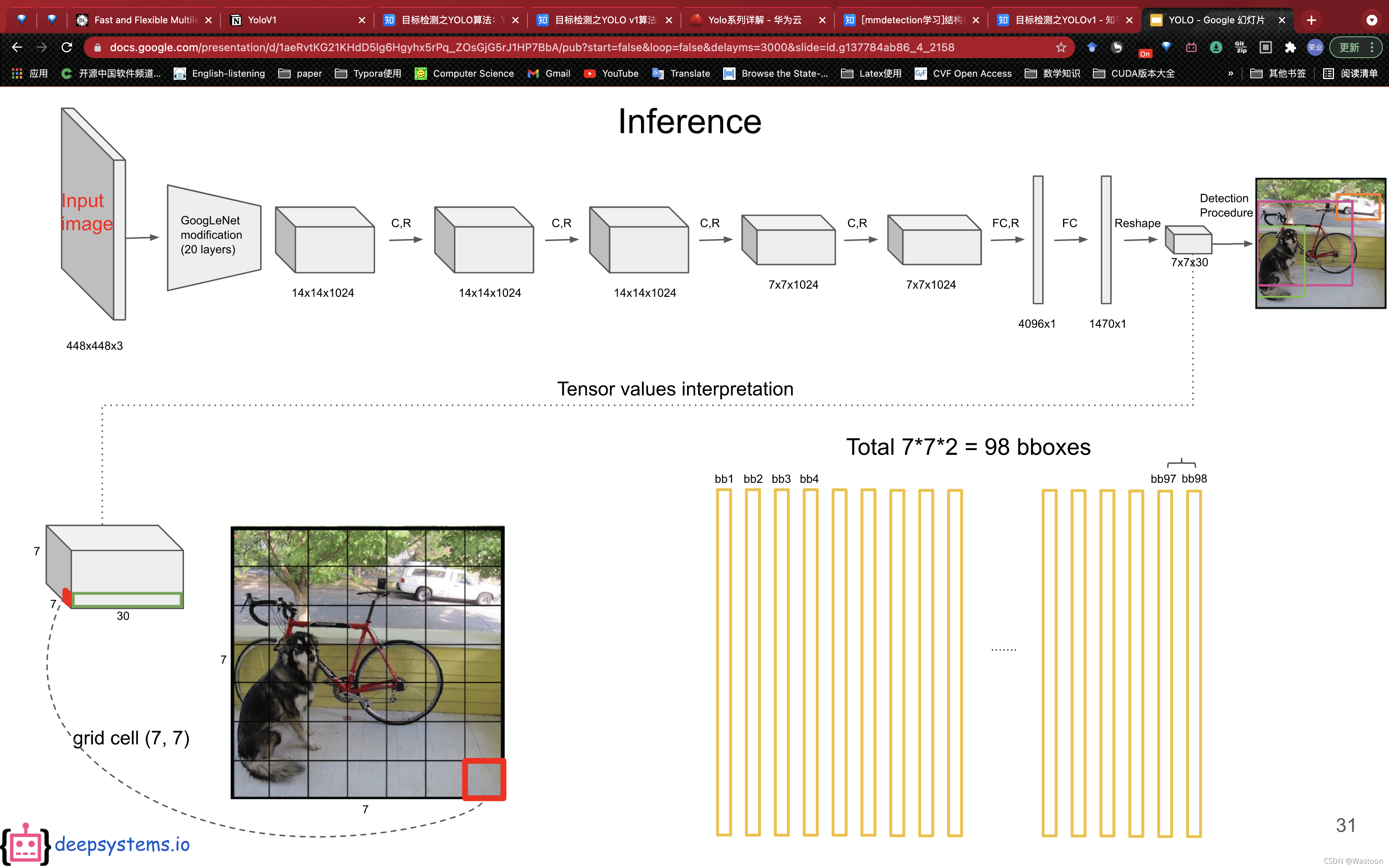
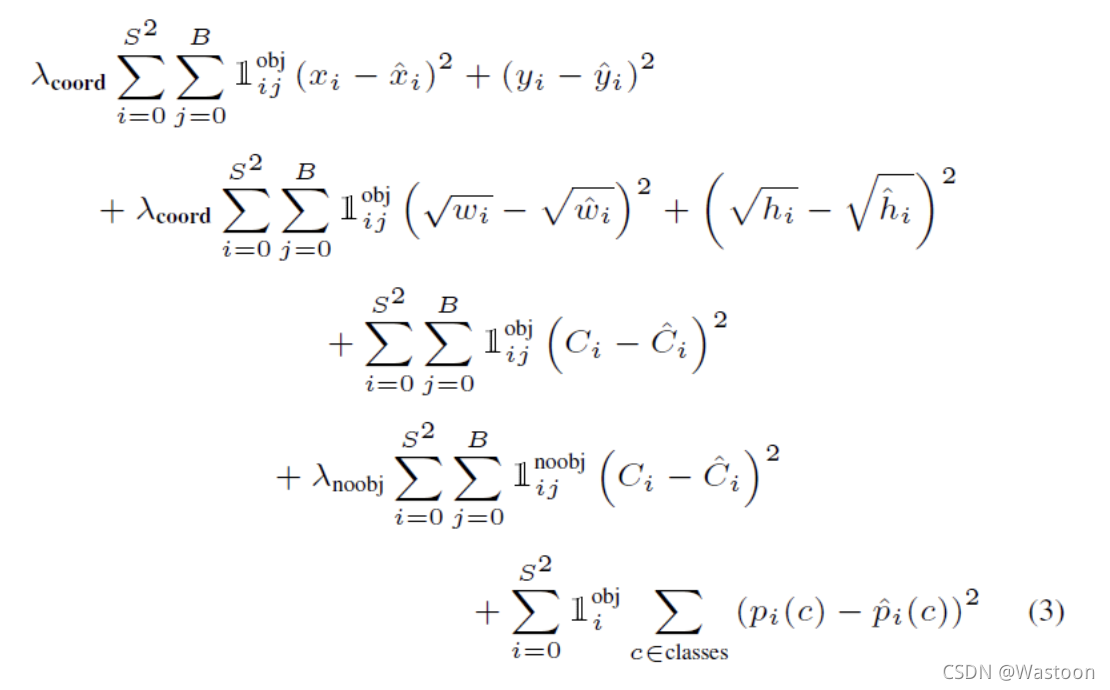
3.细节或注意点
- xy都是0-1之间的数,是与网格大小的比例,表示该bbox中心与对应网格的相对位置
- wh都是0-1之间的数,表示bbox的宽和高与图片宽高的比例
4. 评价
- 快是快,就是每个grid上分配的bbox指标太少,检出量不够
- 划分的grid直接会影响小目标的检出,grid往往会比较大,会更关注到大物体的检出,小物体分配不到有效的anchor,因为极有可能和相邻的大物体在一起时被pass掉。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)