机器学习入门:四大学习方式与十二大经典算法详解
在当今数字化时代,机器学习已经成为人工智能领域中不可或缺的一部分。无论你是数据科学家、软件工程师,还是对人工智能感兴趣的初学者,了解机器学习的基本概念和经典算法都是非常重要的。今天,我们就来深入探讨机器学习的四大学习方式和十二大经典算法,帮助初学者快速入门。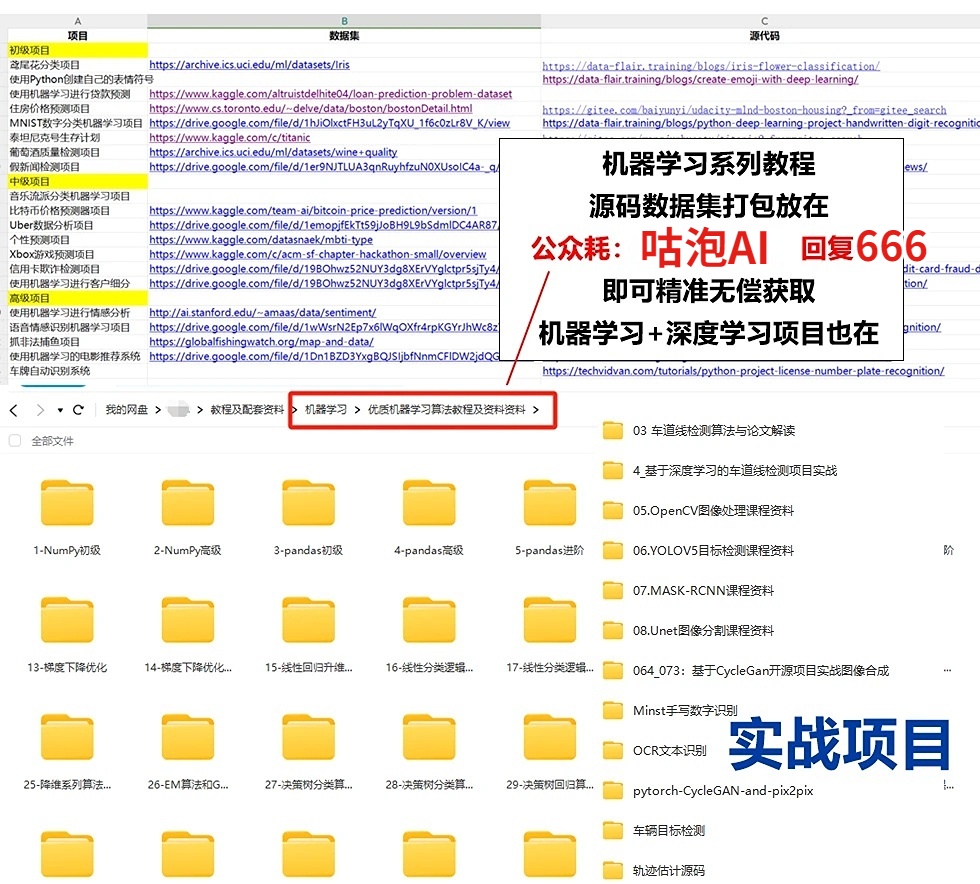
一、机器学习的四大学习方式
(一)监督式学习(Supervised Learning)
监督式学习是机器学习中最常见的学习方式之一。它的核心思想是通过已标记的训练数据来训练模型,从而让模型能够学习到输入特征与输出标签之间的映射关系。在监督式学习中,我们通常会将数据分为训练集和测试集,通过训练集来训练模型,然后用测试集来评估模型的性能。
常见的监督式学习任务包括分类和回归。分类任务的目标是将数据划分为不同的类别,例如垃圾邮件识别(是垃圾邮件或不是垃圾邮件);而回归任务则是预测一个连续的数值,例如房价预测(根据房屋的面积、位置等因素预测其价格)。
(二)非监督式学习(Unsupervised Learning)
与监督式学习不同,非监督式学习的输入数据是没有标签的。它的目标是通过挖掘数据中的内在结构和模式,来对数据进行聚类、降维或异常检测等操作。非监督式学习在处理大规模无标签数据时非常有用,例如在用户画像、基因数据分析等领域。
常见的非监督式学习算法包括K-Means聚类、主成分分析(PCA)和DBSCAN聚类等。这些算法可以帮助我们发现数据中的隐藏信息,从而为后续的数据分析和决策提供支持。
(三)半监督式学习(Semi-Supervised Learning)
半监督式学习是一种介于监督式学习和非监督式学习之间的学习方式。它同时使用了少量的标记数据和大量的无标记数据来进行模型训练。这种方法在实际应用中非常实用,因为标记数据往往获取成本较高,而无标记数据则相对容易获得。
半监督式学习的核心思想是利用少量的标记数据来引导模型学习,同时利用大量的无标记数据来增强模型的泛化能力。例如,在图像分类任务中,我们可能只有少量的已标记图像,但有大量的未标记图像。通过半监督式学习,我们可以充分利用这些数据,提高模型的性能。
(四)强化学习(Reinforcement Learning)
强化学习是一种让智能体(Agent)通过与环境的交互来学习最优策略的学习方式。智能体在环境中采取行动,然后根据环境的反馈(奖励或惩罚)来调整自己的行为,以最大化累积奖励。强化学习在机器人控制、游戏开发和智能决策等领域有着广泛的应用。
强化学习的核心是奖励机制和策略更新。智能体需要根据当前的状态选择一个动作,然后观察环境的反馈,根据反馈来更新自己的策略。例如,在阿尔法狗(AlphaGo)中,智能体通过不断地与对手对弈,学习最优的下棋策略,最终战胜了人类顶尖棋手。
二、十二大经典机器学习算法
(一)回归算法
回归算法是机器学习中最基础的算法之一,它的目标是通过建立一个数学模型来描述输入特征与输出变量之间的关系。常见的回归算法包括:
-
最小二乘法(Ordinary Least Square)
-
最小二乘法是一种经典的回归算法,它的目标是通过最小化预测值与实际值之间的平方误差来找到最优的模型参数。这种方法简单易懂,计算效率高,适用于线性回归问题。
-
例如,在预测房价时,我们可以将房屋的面积、房间数量等作为输入特征,房价作为输出变量,通过最小二乘法来建立一个线性模型,从而预测房价。
-
-
逻辑回归(Logistic Regression)
-
尽管名字中有“回归”二字,但逻辑回归实际上是一种分类算法。它通过Sigmoid函数将线性回归的输出映射到(0,1)区间,从而实现二分类任务。逻辑回归具有良好的可解释性,广泛应用于医学诊断、信用评估等领域。
-
例如,在医学诊断中,我们可以根据患者的症状、检查结果等特征,通过逻辑回归模型来预测患者是否患有某种疾病。
-
-
逐步式回归(Stepwise Regression)
-
逐步式回归是一种用于特征选择的回归方法。它通过逐步添加或删除特征来优化模型的性能。这种方法可以帮助我们找到对模型最有用的特征,从而提高模型的准确性和可解释性。
-
例如,在一个包含大量特征的数据集中,逐步式回归可以帮助我们筛选出最重要的几个特征,从而简化模型。
-
-
多元自适应回归样条(Multivariate Adaptive Regression Splines,MARS)
-
MARS是一种非线性回归方法,它通过将数据划分为不同的区域,并在每个区域内建立线性模型,从而实现对复杂数据的拟合。这种方法可以很好地处理数据中的非线性关系,适用于复杂的数据建模任务。
-
例如,在金融数据分析中,MARS可以用于建模股票价格与多种因素之间的复杂关系。
-
-
本地散点平滑估计(Locally Estimated Scatterplot Smoothing,LOESS)
-
LOESS是一种局部加权回归方法,它通过在数据的局部区域内拟合回归模型,从而实现对数据的平滑处理。这种方法可以很好地处理数据中的噪声和异常值,适用于数据可视化和初步分析。
-
例如,在时间序列分析中,LOESS可以用于平滑时间序列数据,从而更好地观察数据的趋势。
-
(二)决策树算法
决策树算法是一种基于树状结构的模型,它通过递归地划分数据来建立决策规则。决策树模型具有良好的可解释性,广泛应用于分类和回归任务。常见的决策树算法包括:
-
分类及回归树(Classification And Regression Tree,CART)
-
CART是一种经典的决策树算法,它既可以用于分类任务,也可以用于回归任务。CART通过二叉树的形式来划分数据,每次选择最优的特征和分裂点来最大化信息增益或最小化误差。
-
例如,在客户流失预测中,CART可以根据客户的消费行为、年龄、性别等特征,建立决策树模型,从而预测客户是否会流失。
-
-
ID3(Iterative Dichotomiser 3)
-
ID3是最早的决策树算法之一,它通过信息增益来选择最优的特征进行数据划分。ID3算法简单易懂,但在处理连续特征和缺失值时存在一定的局限性。
-
例如,在天气预测中,ID3可以根据气温、湿度、风速等特征,建立决策树模型,从而预测明天是否会下雨。
-
-
C4.5
-
C4.5是ID3的改进版本,它通过信息增益比来选择特征,从而克服了ID3在处理连续特征和缺失值时的不足。C4.5算法在实际应用中非常广泛,适用于各种分类任务。
-
例如,在医学诊断中,C4.5可以根据患者的症状、检查结果等特征,建立决策树模型,从而预测患者是否患有某种疾病。
-
-
Chi-squared Automatic Interaction Detection(CHAID)
-
CHAID是一种基于卡方检验的决策树算法,它通过卡方统计量来选择最优的特征进行数据划分。CHAID算法在处理分类特征时非常有效,适用于市场细分和客户分类等任务。
-
例如,在市场细分中,CHAID可以根据客户的消费行为、年龄、性别等特征,建立决策树模型,从而将客户划分为不同的细分群体。
-
-
Decision Stump
-
Decision Stump是一种非常简单的决策树算法,它只包含一个分裂节点,因此也被称为“单层决策树”。尽管Decision Stump的模型复杂度较低,但它在集成学习中非常有用,例如作为AdaBoost算法的基本分类器。
-
例如,在图像识别中,Decision Stump可以根据图像的某些特征,快速判断图像是否属于某一类别。
-
-
随机森林(Random Forest)
-
随机森林是一种基于决策树的集成学习算法,它通过构建多个决策树,并将它们的预测结果进行集成,从而提高模型的性能。随机森林具有很强的抗过拟合能力,适用于大规模数据集的分类和回归任务。
-
例如,在图像分类任务中,随机森林可以根据图像的像素值等特征,建立多个决策树模型,并将它们的预测结果进行投票,从而实现对图像的分类。
-
-
多元自适应回归样条(Multivariate Adaptive Regression Splines,MARS)
-
MARS不仅可以用于回归任务,还可以用于分类任务。它通过将数据划分为不同的区域,并在每个区域内建立线性模型,从而实现对复杂数据的拟合。在决策树算法中,MARS可以作为一种特殊的决策树模型,用于处理数据中的非线性关系。
-
例如,在金融风险评估中,MARS可以根据客户的信用记录、收入水平等特征,建立决策树模型,从而评估客户的信用风险。
-
-
梯度推进机(Gradient Boosting Machine,GBM)
-
GBM是一种基于梯度提升的集成学习算法,它通过逐步优化模型的损失函数,来构建一系列弱学习器,并将它们组合成一个强学习器。GBM具有很强的模型拟合能力,适用于各种复杂的分类和回归任务。
-
例如,在客户购买预测中,GBM可以根据客户的消费行为、兴趣爱好等特征,建立梯度提升模型,从而预测客户是否会购买某种产品。
-
(三)贝叶斯方法算法
贝叶斯方法是一种基于贝叶斯定理的统计方法,它通过计算后验概率来实现对数据的分类或回归。贝叶斯方法具有很强的理论基础和可解释性,广泛应用于文本分类、图像识别等领域。常见的贝叶斯方法算法包括:
-
朴素贝叶斯算法(Naive Bayes)
-
朴素贝叶斯算法是一种基于贝叶斯定理的简单分类算法,它假设特征之间相互独立,从而简化了概率计算。尽管这个假设在实际中并不总是成立,但朴素贝叶斯算法在许多任务中仍然表现出色,尤其是在文本分类和垃圾邮件识别等领域。
-
例如,在垃圾邮件识别中,朴素贝叶斯算法可以根据邮件中的关键词、发件人等特征,计算邮件是垃圾邮件的概率,从而实现对垃圾邮件的识别。
-
-
平均单依赖估计(Averaged One-Dependence Estimators,AODE)
-
AODE是朴素贝叶斯算法的一种改进版本,它通过考虑特征之间的依赖关系,来提高模型的性能。AODE算法在处理特征之间存在较强依赖关系的数据时,比朴素贝叶斯算法更加有效。
-
例如,在医学诊断中,AODE可以根据患者的症状、检查结果等特征,考虑这些特征之间的依赖关系,从而更准确地预测患者是否患有某种疾病。
-
-
贝叶斯信念网络(Bayesian Belief Network,BBN)
-
BBN是一种基于有向无环图的贝叶斯模型,它通过图结构来表示特征之间的依赖关系,并通过贝叶斯定理来计算后验概率。BBN具有很强的可解释性,适用于复杂系统的建模和推理。
-
例如,在智能交通系统中,BBN可以根据交通流量、天气状况、道路状况等特征,建立交通模型,从而预测交通拥堵的可能性。
-
三、总结
机器学习是一个庞大而复杂的领域,但通过了解其四大学习方式和十二大经典算法,我们可以快速入门并掌握其核心思想。监督式学习、非监督式学习、半监督式学习和强化学习各有其特点和应用场景,而回归算法、决策树算法和贝叶斯方法算法则是机器学习中最基础和最常用的算法。无论你是初学者还是有一定基础的学习者,都应该深入学习这些算法,并通过实际项目来加深理解。
在学习机器学习的过程中,实践是最好的老师。建议大家多动手实践,尝试使用不同的算法来解决实际问题。同时,也可以参考一些开源的机器学习框架,如Scikit-Learn、TensorFlow和PyTorch等,这些框架提供了丰富的算法实现和工具,可以帮助我们更高效地进行机器学习开发。
希望这篇文章能够帮助大家更好地理解机器学习的基础知识,开启机器学习的学习之旅。如果你对机器学习感兴趣,或者在学习过程中遇到任何问题,欢迎随时交流和讨论。让我们一起探索机器学习的奥秘,为人工智能的发展贡献自己的力量!
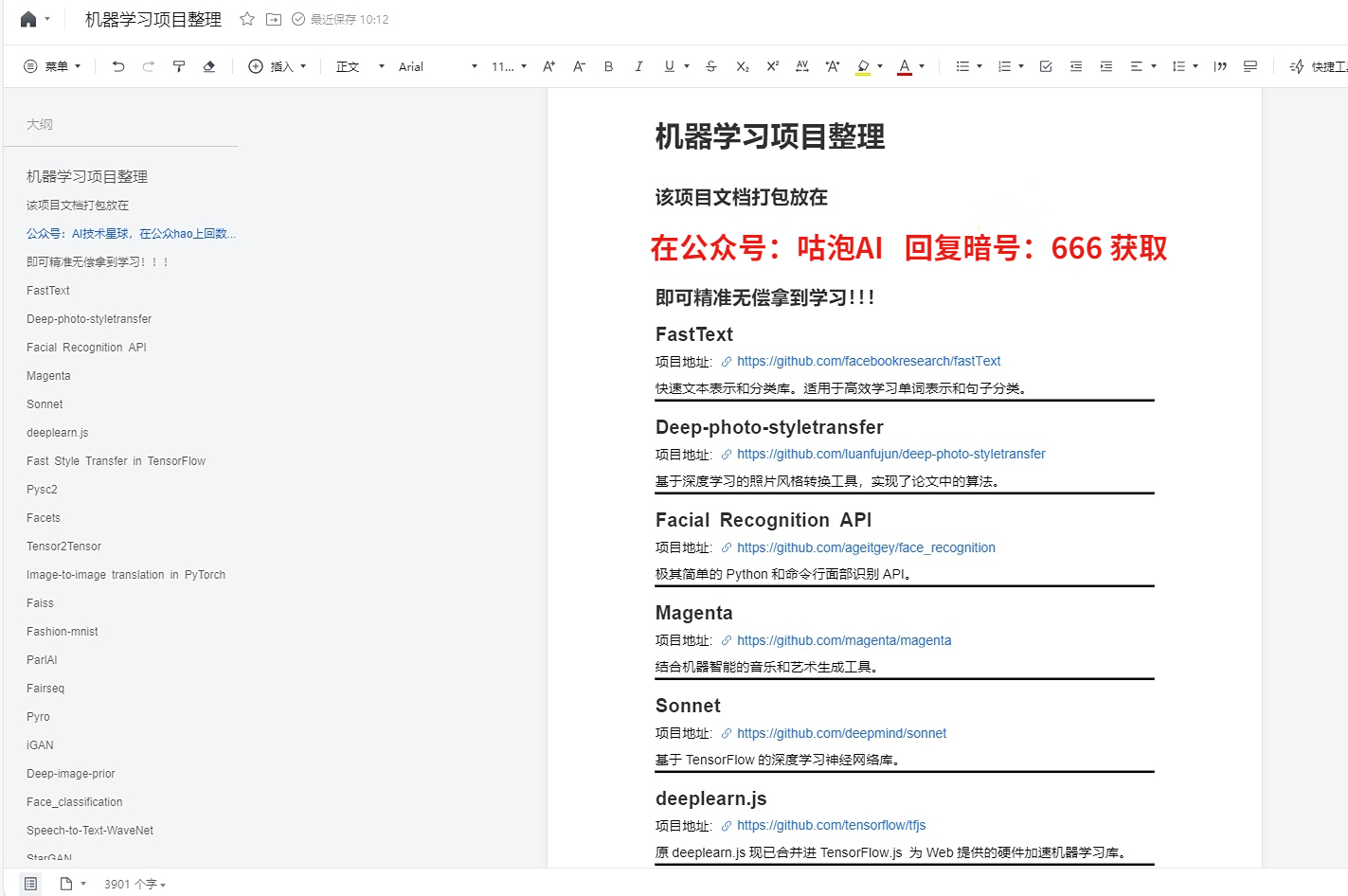
免费分享一些我整理的人工智能学习资料给大家,包括一些AI常用框架实战视频、图像识别、OpenCV、NLQ、机器学习、pytorch、计算机视觉、深度学习与神经网络等视频、课件源码、国内外知名精华资源、AI热门论文、行业报告等。
为了更好的系统学习AI,推荐大家收藏一份
下面是部分截图,关注VX公众号【咕泡AI】发送暗号 666 领取
一、人工智能课程及项目

二、国内外知名精华资源

三、人工智能论文合集

四、人工智能行业报告


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 27
27 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)