数学建模:Python入门
前言
达成成就:算法竞赛cpp,学校上课java,数学建模python,成分复杂。
而且写惯了cpp现在写python感觉浑身难受,不是结尾肌肉记忆打分号就是声明变量int零帧起手。
一、Python语法
1.输入输出
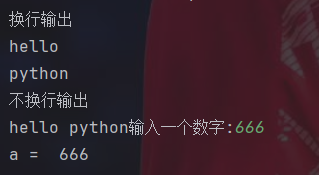
s="hello"
t="python"
print("换行输出")
print(s)
print(t)
print("不换行输出")
print(s,end=" ")
print(t,end="")
a=input("输入一个数字:")
print("a = ",a)Python的语法简单多了,print函数跟java的println类似,都是默认换行。如果不想换行可以在后面加个end=""即可。如果想同时输出多个只需要用逗号分隔即可。
注意从input里读入的数据默认字符串,得需要用强转一下。
2.变量
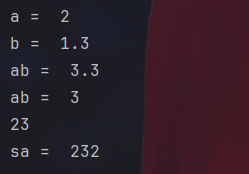
a=2
b=1.3
print("a = ",a)
print("b = ",b)
ab=a+b
print("ab = ",ab)
ab=a+int(b)
print("ab = ",ab)
s="23"
print(s)
sa=s+str(a)
print("sa = ",sa)Python的变量更是简单,连类型都不需要标注,直接声明就行了,甚至后续可以自动转类型。
3.字符串
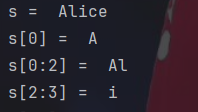
s="Alice"
print("s = ",s)
print("s[0] = ",s[0])
#子串
print("s[0:2] = ",s[0:2])
print("s[2:3] = ",s[2:3])字符串操作跟cpp类似,就是输出子串时方便多了。
这里注意,输出子串时给的区间是左闭右开的。
print("s[-1] = ",s[-1])
print("s[-3:-1] = ",s[-3:-1])
print("s[-4:-2] = ",s[-4:-2])除了正向输出字符串,也可以从结尾开始反向输出,只需要改成负号即可。
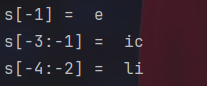
注意这里-1代表结尾字符,因为0是开头字符。
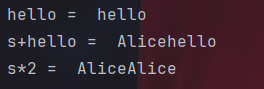
hello="hello"
print("hello = ",hello)
print("s+hello = ",s+hello)
print("s*2 = ",s*2)Python里字符串的拼接也和cpp类似,还可以用乘法一次拼好几个。
4.运算符
#我是注释
"""
我也是注释
我也是!
"""
a=5
b=2
print(a)
print(b)
#注意!!
print("a/b = ",a/b)
print("a//b = ",a//b)
print("a%b = ",a%b)大多数运算符和cpp一样。
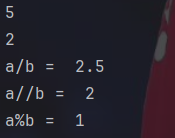
唯一需要特别注意的就是,一个除号在cpp里是除法向下取整,在python里会保留小数部分。如果想要向下取整,需要两个除号。
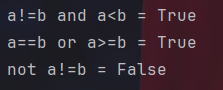
print("a!=b and a<b =",a!=b and a>=b)
print("a==b or a>=b =",a==b or a>=b)
print("not a!=b =",not a!=b)在python里,逻辑运算符直接就是and,or和not。其实and和or也可以用一个“&”和“|”表示,注意此时两侧的条件需要加括号。
5.复合数据结构
#列表
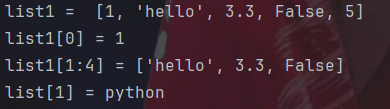
list1=[1,"hello",3.3,False,5]
print("list1 = ",list1)
print("list1[0] =",list1[0])
print("list1[1:4] =",list1[1:4])
list1[1]="python"
print("list[1] =",list1[1])列表就类似数组,只是可以同时存不同类型的数据。
索引方式和字符串一样。
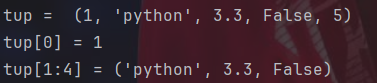
#元组 -> 不能修改
tup=(1,"python",3.3,False,5)
print("tup = ",tup)
print("tup[0] =",tup[0])
print("tup[1:4] =",tup[1:4])元组和列表基本一致,就是在声明之后就不能对其内容进行修改了。
#字典 -> map
dic={"first":1,"second":2,"third":3}
print("dic = ",dic)
print("dic['first'] =",dic["first"])#单引号
dic["second"]=4
print("dic['second'] =",dic["second"])字典类似cpp里的map,即键值对,同样可以存放不同的数据类型。

#集合 -> set
set={1,"second",3,3,1}
print("set = ",set)集合类似cpp里的set,拥有去重的功能。

list2=[6,"python",6.6,True,2]
print("list2 = ",list2)
print("list1+list2 =",list1+list2)
print("list1*2 =",list1*2)此外,列表和字符串一样,支持拼接功能。

a="python"
print("a in list2 = ",a in list2)#是否存在
list3=["python",True]
print("list3 in list2=",list3 in list2)#顺序此外,in关键字可以判断一个元素或列表是否属于另一个列表。
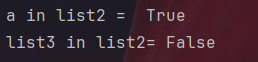
注意,列表和列表的判断需要保证元素顺序也完全一致。
6.条件和循环
a=input("请输入一个整数:")
#输入的类型为字符串
a=int(a)
#注意冒号
if a%2==0:
print("a为偶数")
else:
print("a为奇数")
b=input("请输入一个整数:")
b=int(b)
if b%2==0 and a%2==0:
print("ab均为偶数")
elif b%2!=0 and a%2==0 or b%2==0 and a%2!=0: #注意缩进
print("ab一奇一偶")
else:
print("ab均为奇数")python是用缩进分隔代码块的,所以条件语句和循环语句都不需要括号,只需要空格和冒号即可,还需要注意后续的缩进。

注意在判断一奇一偶时,可以用空一格和空两格来替代括号表示运算的优先级。
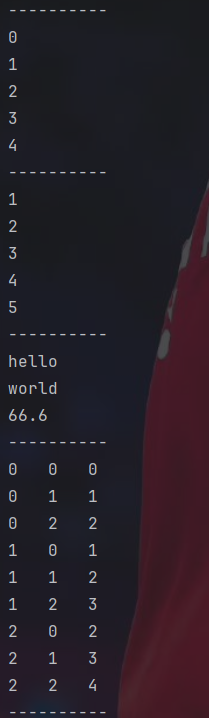
#for循环
for i in range(5):#0~4
print(i)
print("----------")
for i in [1,2,3,4,5]:#1~5
print(i)
print("----------")
for i in ["hello","world",66.6]:
print(i)
print("----------")
for i in range(3):
for j in range(3):
print(i," ",j," ",i+j)for按循环就是要注意range(i)表示从0到i-1循环,此外还可以传一个列表,达到遍历列表的功能。
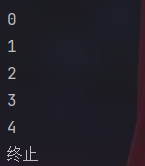
#while循环
n=0
while n<10:
print(n)
n+=1
if n==5:
print("终止")
breakwhile循环就是注意python里好像没有i++这种写法。
7.函数
#函数
def mod(a,b):
return a%b
a=int(input("请输入一个整数:"))
b=int(input("再输入一个整数:"))
print("a % b = ",mod(a,b))
#python里函数没有声明的先后顺序
def minus(a,b):
return add(a,-b)
def add(a,b):
return a+b
print("a - b = ",minus(a,b))
#缺省参数:默认值
def multiply(a,b=1):
return a*b
print("a * b = ",multiply(a))
def prime(a):
i=2
while i*i<=a:
if a%i==0:
return False
i+=1
return True
print("50以内质数:")
for i in range(2,50):
if prime(i):
print(i,"是质数")python的函数同样不需要声明类型,而且也不存在先后顺序。

二、使用Numpy库进行数值计算
使用手册:NumPy Documentation
0.随机数
import numpy as np
#随机数
print(np.random.rand())#0~1之间
print(int(np.random.rand()*10))
print(np.random.randint(0,10))
#随机数组
randArr=np.array(np.random.randint(0,10,16).reshape(4,4))
print(randArr)首先,np.random.rand()函数可以生成一个0~1之间的数,np.random.randint()可以根据传入的范围生成若干个整数。如果想要随机生成一个矩阵的话,可以先用randint生成若干个随机数,然后再用reshape函数重设列表的大小。
1.数组操作
import numpy as np
#numpy的数组
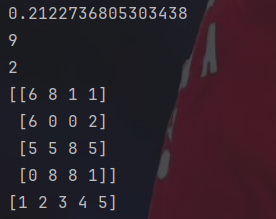
arr=np.array([1,2,3,4,5])
print(arr)
print(type(arr))
#注意多维数组要再加个方括号
arr=np.array([ [1,2,3],[2,3,4],[3,4,5],[4,5,6] ])
print(arr)
print("数组形状:",arr.shape)#矩阵大小多维的数据要记得再多加一个方括号。
2.数组运算
import numpy as np
#数组的索引和切片
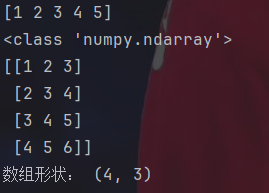
print("arr[0] = ",arr[0])
print("arr[1][2] = ",arr[1][2])
#运算
add=np.array([1,2,3])+np.array([4,5,6])# -> 对应相加
print("加和:")
print(add)
mult=np.array([1,2,3])*np.array([4,5,6])# -> 对应相乘
print("乘积:")
print(mult)数组同样支持索引和切片。运算时就是对应元素相加或相乘,注意必须保证两数组大小一致。
3.线性代数
import numpy as np
#矩阵变换
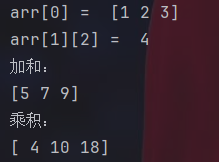
new_arr=arr.reshape(2,6)
print("变换后:")
print(new_arr)
print("After reshaping : ",new_arr.shape)
#转置
arrT=arr.transpose()
print("After transpose : \n",arrT)
#线性代数
vec1=np.array([1,2,3])
vec2=np.array([4,5,6])
print(vec1)
print(vec2)
#点乘
dot=np.dot(vec1,vec2)
print(dot)reshape函数可以对数组大小进行重设,注意必须保证元素总数一致。transpose可以对矩阵进行转置,dot函数可以计算两向量的点乘。
4.统计
import numpy as np
#统计
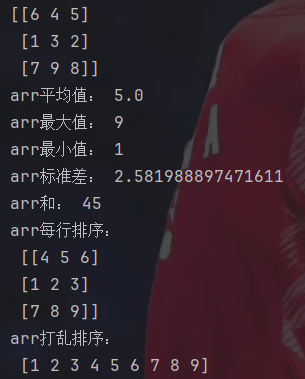
arr=np.array([[6,4,5],[1,3,2],[7,9,8]])
print(arr)
print("arr平均值:",np.mean(arr))
print("arr最大值:",np.max(arr))
print("arr最小值:",np.min(arr))
print("arr标准差:",np.std(arr))
print("arr和:",np.sum(arr))
print("arr每行排序:\n",np.sort(arr))#每行分别排序
print("arr打乱排序:\n",np.sort(arr.reshape(-1)))#reshape(-1)为打乱成一行mean函数可以求出一个矩阵中所有元素的平均值,max和min就是最大最小值,std函数可以求所有元素的标准差,sum就是求和。sort函数如果没有别的参数,就会对各行进行排序。如果想要整体排序,那就需要用reshape(-1)把矩阵重设成一行,然后再进行排序。
5.筛选
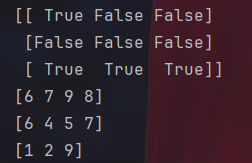
import numpy as np
#筛选
print(arr>5)
print(arr[arr>5])
print(arr[(arr>3) & (arr<8)])
print(arr[(arr<3) | (arr>8)])筛选可以快速找出符合条件的元素,注意“&”和“|”前后需要加括号。
6.保存
import numpy as np
#保存 -> .npy格式文件
np.save("arr.npy",arr)
#导入
file=np.load("arr.npy")
print(file)还可以将数组保存为文件一遍多次使用。
三、使用Pandas库进行表格处理
使用手册:Pandas documentation
1.表格读取
import numpy as np
import pandas as pd
#读取文件
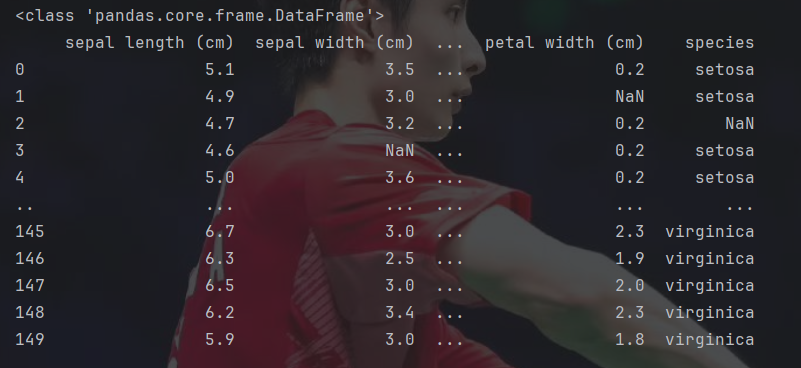
df=pd.read_excel("iris_dataset.xlsx","Sheet1",engine="openpyxl")#引擎参数
print(type(df))
#基础信息
print(df)
print(df.info())
#前五行
print(df.head(5))pandas可以读取excel表格并对其进行操作,其中可以指定读取哪个sheet,这里的引擎参数记住即可。如果直接输出,那就会显示前后若干行信息。
也可以用info()函数查看这个表格的完整信息。
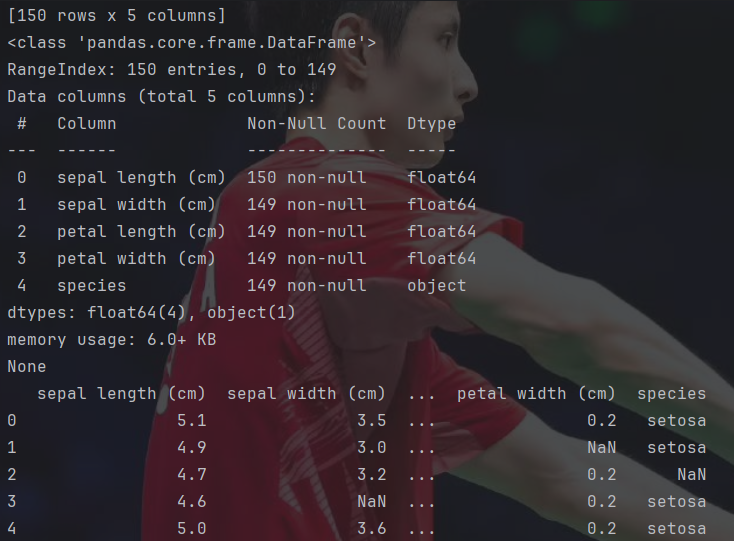
也可以用head()函数输出前面若干行。
2.将数据转化成表格
import numpy as np
import pandas as pd
#将字典转化成表格
dic={"Name":["Spider_Man","Iron_Man","Captain_America"],
"Speed":[9,5,7],
"Strength":[6 for i in range(3)],#6重复3次
"Defense":list(np.random.randint(1,10,3)),}
data=pd.DataFrame(dic)
print(data)因为字典的特性,也可以将字典转化成一个表格的类型。
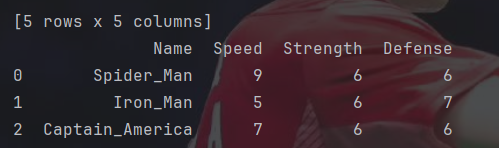
这里在Strength的列表里这样写可以让一个数重复多次。
3.数据处理
import numpy as np
import pandas as pd
#读取文件
df=pd.read_excel("iris_dataset.xlsx","Sheet1",engine="openpyxl")#引擎参数
#缺失值处理
df=df.dropna()
print(df.head(5))#完全没有缺失值的前五行
#数据类型转换 -> 注意!!不能通过指针修改 e.g. loss=df loss["xxx"]=loss["xxx"].astype(xxx)
df["sepal width (cm)"]=df["sepal width (cm)"].astype(int)
print(df.info())因为往往表格中会存在数据缺失,所以可以用dropna()函数先把有缺失的行列去掉,还可以根据需要用astype()函数将表格某些数据的类型进行转换。
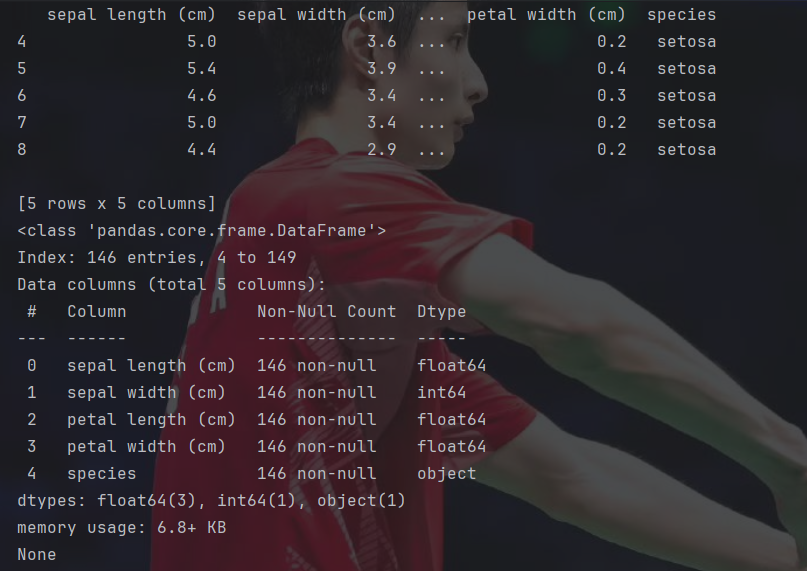
可以看到这里sepal width里的数据被转成了整数类型。
4.数据选择和过滤
import numpy as np
import pandas as pd
#读取文件
df=pd.read_excel("iris_dataset.xlsx","Sheet1",engine="openpyxl")#引擎参数
#缺失值处理
df=df.dropna()
print(df.head(5))#完全没有缺失值的前五行
#数据类型转换 -> 注意!!不能通过指针修改 e.g. loss=df loss["xxx"]=loss["xxx"].astype(xxx)
df["sepal width (cm)"]=df["sepal width (cm)"].astype(int)
print(df.info())
#数据选择和过滤
df_sl_5=df[df["sepal length (cm)"]>5]
print(df_sl_5.head(5))
print(df_sl_5.info())之后就可以对数据进行选择和过滤了,用到的就是numpy里的筛选操作。
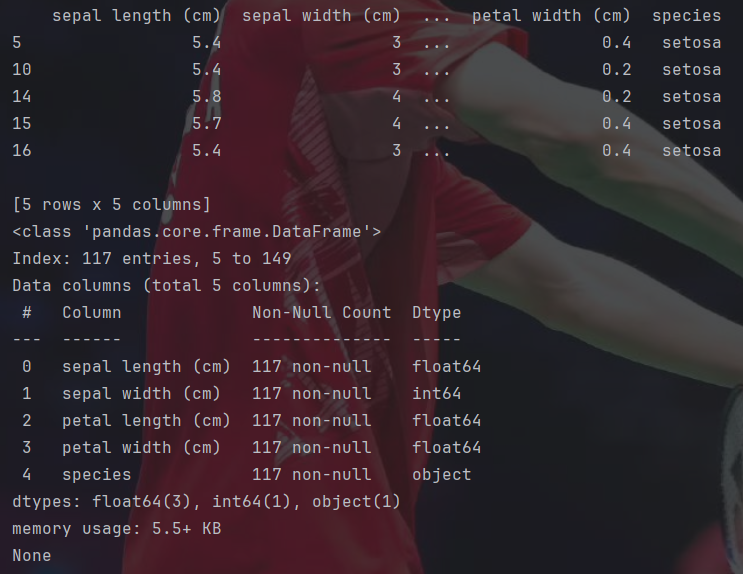
这样就过滤掉了不满足条件的数据。
import numpy as np
import pandas as pd
#读取文件
df=pd.read_excel("iris_dataset.xlsx","Sheet1",engine="openpyxl")#引擎参数
#缺失值处理
df=df.dropna()
print(df.head(5))#完全没有缺失值的前五行
#数据类型转换 -> 注意!!不能通过指针修改 e.g. loss=df loss["xxx"]=loss["xxx"].astype(xxx)
df["sepal width (cm)"]=df["sepal width (cm)"].astype(int)
print(df.info())
#数据选择和过滤
sl_std=df["sepal length (cm)"].std()
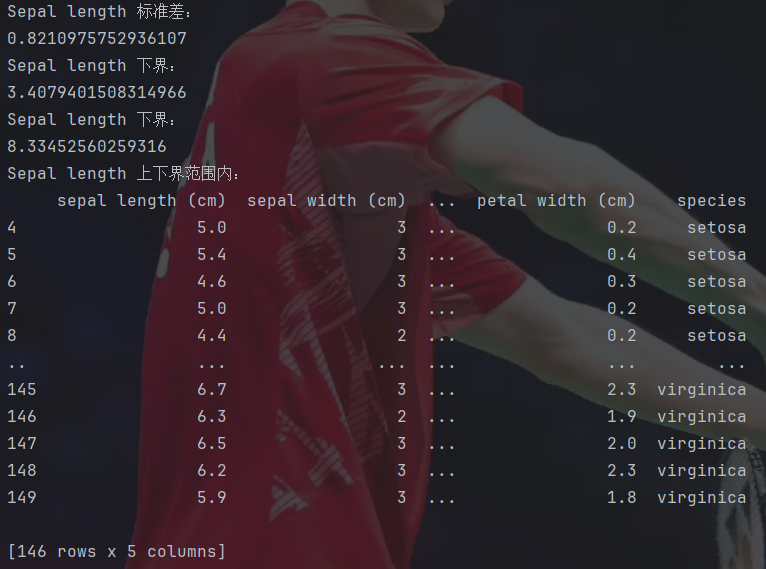
print("Sepal length 标准差:")
print(sl_std)
sl_lower_bound=df["sepal length (cm)"].mean()-3*sl_std
sl_upper_bound=df["sepal length (cm)"].mean()+3*sl_std
print("Sepal length 下界:")
print(sl_lower_bound)
print("Sepal length 下界:")
print(sl_upper_bound)
print("Sepal length 上下界范围内:")
sl_in_range=df[(df["sepal length (cm)"]>=sl_lower_bound) & (df["sepal length (cm)"]<=sl_upper_bound) ]
print(sl_in_range)此外,还可以通过numpy里的函数进行求平均值等操作。这里是求出了sepal length满足的区间,然后把处在这个区间里的数据筛选出来。
四、使用Matplotlib库进行可视化
使用手册:Matplotlib
1.图像绘制
import matplotlib.pyplot as plt
import numpy as np
#创建列表
x=np.linspace(0,2*np.pi,60)
print(x)
#函数
y=np.sin(x)
#绘制图像
plt.plot(x,y)
plt.show()首先,可以用np.linspace创建若干个范围内的间距相等的数值。然后,可以用np里的封装好的函数,将刚刚生成的点作为自变量传入,然后返回对应的因变量的值。接着用plot函数就可以绘制x和y的函数图像,show函数可以在窗口上显示这个图像。
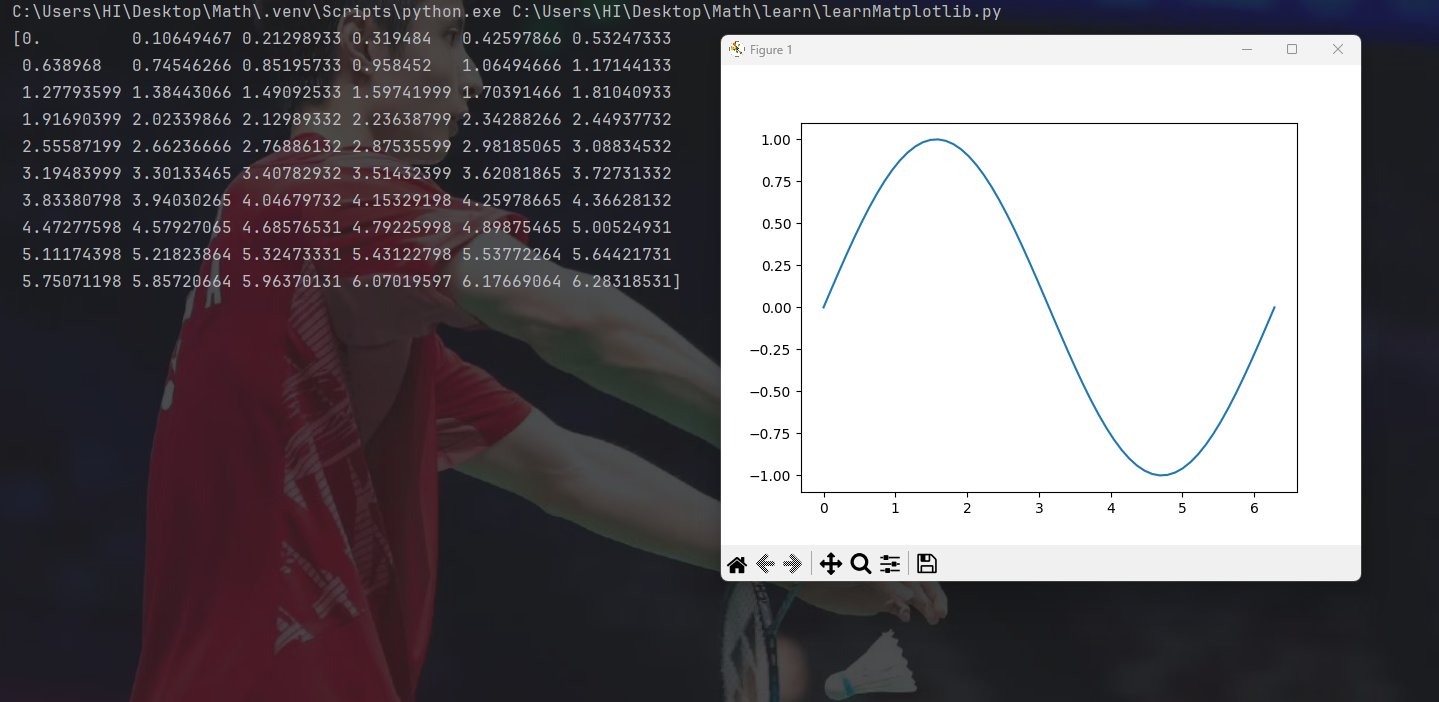
因为生成了六十个自变量,所以整个图像是比较平滑的。
2.信息加入
import matplotlib.pyplot as plt
import numpy as np
#加入信息
x=np.linspace(0,2*np.pi,6)
y=np.sin(x)
plt.plot(x,y)
plt.title("y=sin(x)")
plt.xlabel("x")
plt.ylabel("y")
plt.show()此外,还可以在表格里加入相应信息。
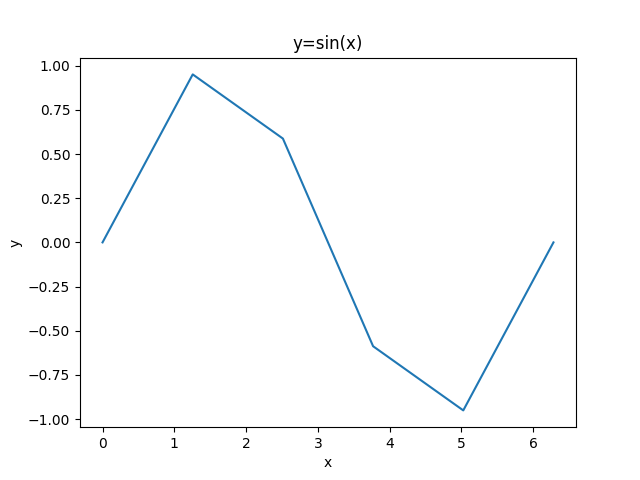
因为这里只生成了六个数据,所以整个图像就是折线。
3.散点图绘制
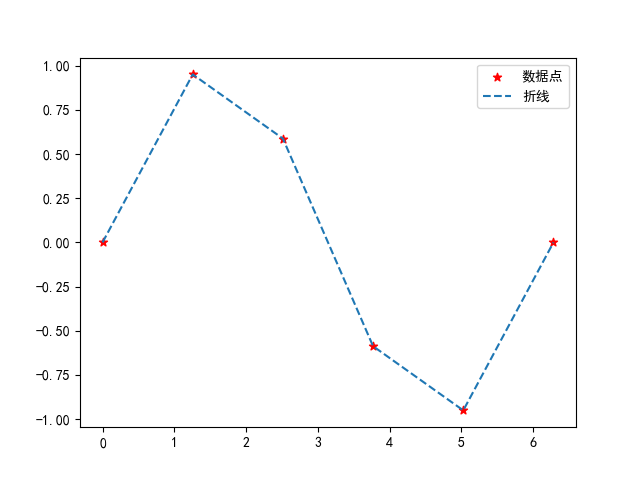
import matplotlib.pyplot as plt
import numpy as np
#只画点
#使用中文字体
from matplotlib.pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
plt.scatter(x,y,marker='*',c="r",label="数据点")#符号 颜色 标签
plt.plot(x,y,linestyle="--",label="折线")#线形 标签
plt.legend()#显示标签
plt.show()散点图的生成可以用scatter函数,其中还可以指定点用什么符号标识,点的颜色和标签。同样也可以在plot函数里设置线的类型,注意这里如果要显示中文字体需要多加三句代码,然后还需要用一个legend函数将标签加载出来。
4.拟合操作
import matplotlib.pyplot as plt
import numpy as np
#拟合操作
x_func=np.linspace(0,2*np.pi,100)
y_func=np.sin(x_func)
x_point=np.linspace(0,2*np.pi,6)
y_point=np.sin(x_point)
plt.scatter(x_point,y_point,marker='*',c="r",label="数据点")
plt.plot(x_func,y_func,linestyle="--",label="拟合图像")
plt.legend()
plt.show()在得到了函数模型后,可以生成和散点的拟合图像。此时可以分离散点和函数变量,然后分别生成对应的散点图和函数图。
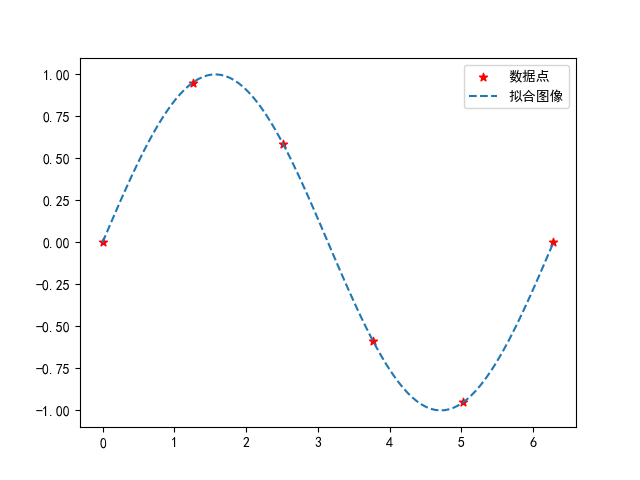
5.多图绘制
import matplotlib.pyplot as plt
import numpy as np
#多图绘制
fig,axes=plt.subplots(1,2)
axes[0].plot(x_func,y_func,linestyle="-",label="函数")
axes[0].set_xlabel("x")
axes[0].set_ylabel("y")
axes[0].legend()#第一个图
axes[1].scatter(x_point,y_point,label="散点")
axes[1].set_xlabel("x")
axes[1].legend()#第二个图
plt.show()如果要绘制多张图像,可以用subplots函数,该函数会读入以图像为单位的行数和列数,然后传回两个参数,一个是整体的变量fig,另一个是存每个小图的列表。此时就可以分别对两图进行编辑,注意图例需要分别用legend函数加载,而且加入信息的函数和plt不同。
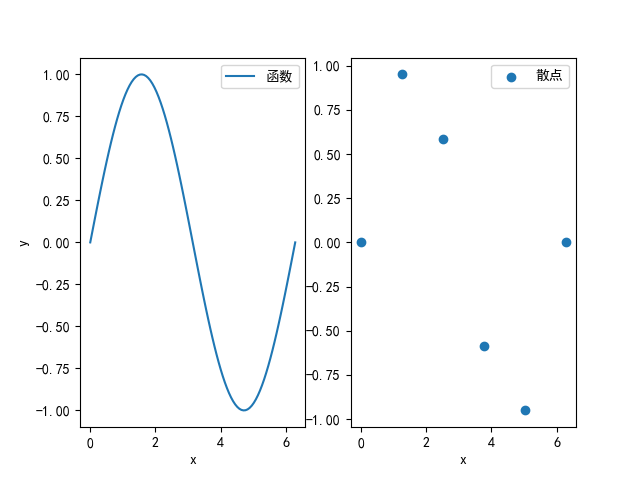
这样就可以分别展示函数图像和散点图像。
6.直方图
import matplotlib.pyplot as plt
import numpy as np
#直方图
x=[1,2,3]
y=[2,4,6]
plt.bar(x,y)
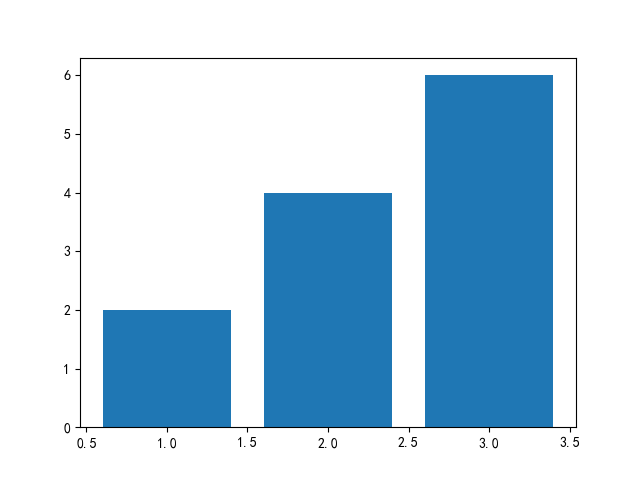
plt.show()
直方图可以用bar()函数绘制,方法和函数图类似。
总结
这三个库真的很强大,其使用上限远远超过这篇博客里写的内容,更多强大的功能就需要自己去网站自学或者用到时去查找。
END

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)