YOLO26 前瞻!2025 边缘目标检测新王者:无 NMS、去 DFL,CPU 速度飙升 43% 的四大核心突破
YOLO26 前瞻!2025 边缘目标检测新王者:无 NMS、去 DFL,CPU 速度飙升 43% 的四大核心突破
YOLO26 基础概况
Ultralytics YOLO26 是 YOLO 系列实时对象检测器的最新演进,从头开始专为边缘和低功耗设备而设计。它引入了简化的设计,消除了不必要的复杂性,同时集成了有针对性的创新,以实现更快、更轻、更易于访问的部署。
YOLO26 的架构遵循三个核心原则:
- 简洁性: YOLO26 是一个原生端到端模型,直接生成预测,而无需非极大值抑制 (NMS)。通过消除此后处理步骤,推理变得更快、更轻,并且更易于在实际系统中部署。清华大学的 Ao Wang 在 YOLOv10 中首次开创了这种突破性方法,并在 YOLO26 中得到了进一步发展。
- 部署效率: 端到端设计消除了管道的整个阶段,从而大大简化了集成,减少了延迟,并使部署在各种环境中更加稳健。
- 训练创新: YOLO26 引入了 MuSGD 优化器,它是 SGD 和 Muon 的混合体 ——受 Moonshot AI 的 Kimi K2 在 LLM 训练方面的突破启发。该优化器带来了增强的稳定性和更快的收敛速度,从而将语言模型的优化进展转移到计算机视觉中。
这些创新共同提供了一个模型系列,该模型系列在小对象上实现了更高的精度,提供了无缝部署,并且在 CPU 上的运行速度提高了 43% — 使 YOLO26 成为迄今为止资源受限环境中最实用和可部署的 YOLO 模型之一。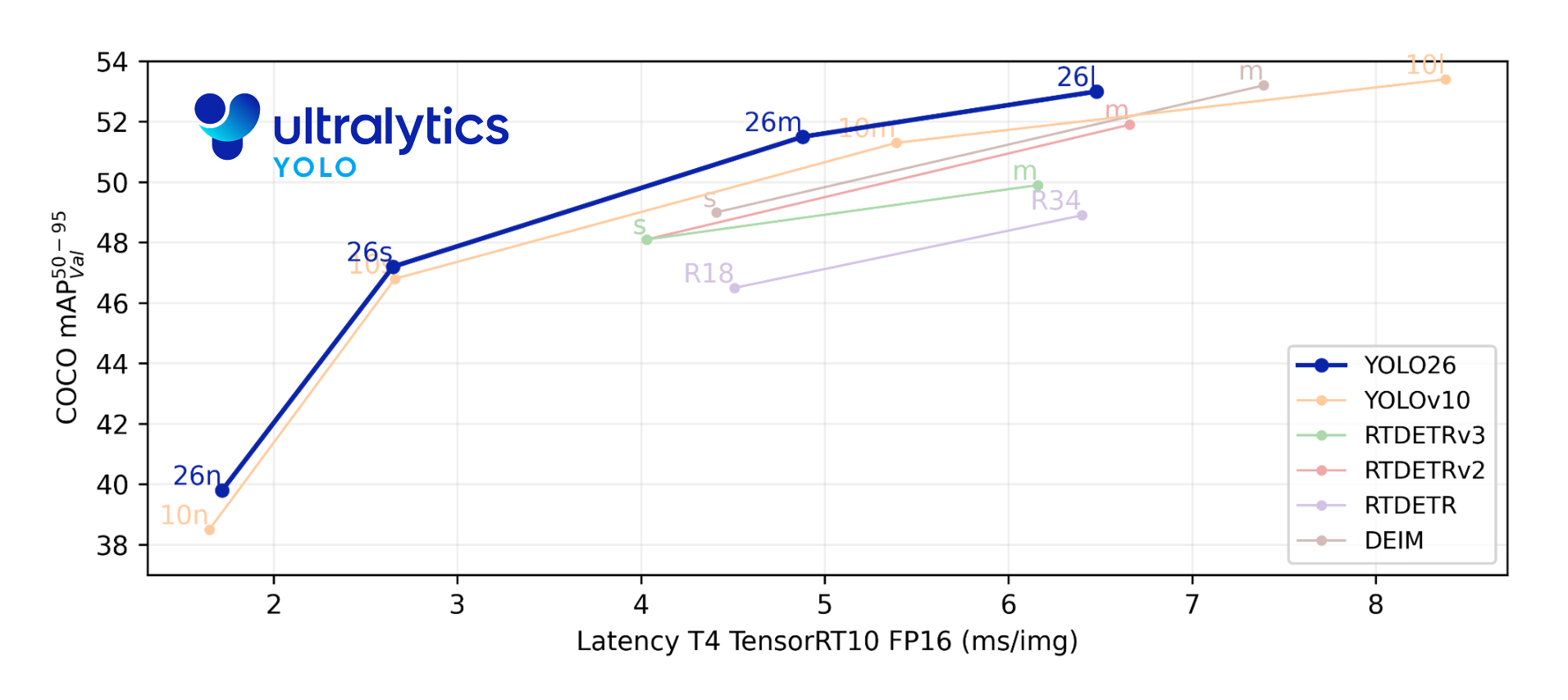
一、YOLO发展背景
早期 YOLO 版本(2016-2022):
- YOLOv1(2016):由 Joseph Redmon 提出,首次将目标检测定义为 “单阶段回归问题”,实现实时推理,但小目标检测能力弱。
- YOLOv2(2017):引入批量归一化、锚框(Anchor Boxes)、多尺度训练,提升不同尺寸目标检测鲁棒性。
- YOLOv3(2018):采用 Darknet-53 深层架构,结合多尺度特征图,成为后续数年学术与工业界 “默认标准”。
- YOLOv4(2020):集成 CSPNet、Mish 激活函数、马赛克数据增强、CIoU 损失,进一步提升精度。
- YOLOv5(2020):Ultralytics 推出(非官方版本),基于 PyTorch 实现,支持模块化设计,简化分割、边缘部署。
- YOLOv6/7(2022):融入 Transformer 启发模块、参数高效优化,接近 SOTA 精度的同时保留实时性。
近期 YOLO 版本(2023-2025,YOLO26 前身):
- YOLOv8(2023):解耦检测头、无锚框预测,支持 TensorRT/CoreML 导出,提供 nano/small 等多尺度变体,广泛应用于工业界。
- YOLOv9(2023):引入 GELAN(通用高效层聚合网络)与渐进式蒸馏,平衡效率与表征能力。
- YOLOv10(2024):通过混合任务对齐分配,优化精度与推理延迟的平衡。
- YOLOv11(2024):提升 GPU 效率,同时保留小目标检测性能,巩固 Ultralytics “生产级模型” 定位。
- YOLOv12/13(2025):采用注意力中心化设计、超图增强视觉感知,但仍依赖 NMS 和 DFL,导致边缘设备部署 latency 高、兼容性差,成为 YOLO26 的改进靶点。
二、YOLO26核心架构改进
1. 移除 DFL(Distribution Focal Loss,分布焦点损失)
背景:DFL 用于提升边界框回归精度(预测坐标概率分布),但存在计算开销大、导出困难问题,需针对 ONNX/TensorRT 等格式自定义处理。
改进效果:
- 简化边界框回归为 “直接回归任务”,无需概率分布计算;
- 与 ProgLoss、STAL 结合,精度持平或超越 DFL-based 模型(如
YOLOv12/13); - 提升跨平台兼容性,消除导出瓶颈,适配边缘硬件。
2. 端到端无 NMS(Non-Maximum Suppression)推理
背景:传统 YOLO(v8-v13)依赖 NMS 过滤重复预测框,需手动调优 IoU 阈值,增加后处理 latency 与部署脆弱性。
改进效果:
- 重新设计预测头,直接输出 “无冗余边界框”,无需后处理;
- CPU 推理速度最高提升43%(nano 模型),latency 低于 YOLOv11/12;
- 无需 NMS 代码,提升可重复性与部署便携性,为 YOLO 家族首次采用该范式。
3. 引入 ProgLoss 与 STAL(小目标优化双策略)
-
ProgLoss(渐进式损失平衡):
核心功能:训练中动态调整不同损失分量权重
解决问题:避免对优势类别过拟合,防止后期训练不稳定 -
STAL(小目标感知标签分配):
核心功能:优先为小目标分配标签(小目标像素少、易遮挡,传统分配易被忽略)
解决问题:提升 COCO、UAV 图像等数据集中小 / 遮挡目标精度 -
对比优势:相较于 YOLOv8/11 的 “依赖数据增强”、YOLOv12/13 的 “注意力模块增复杂度”,ProgLoss+STAL 以轻量化方式实现精度提升,适配边缘设备。
4. 采用 MuSGD 优化器(训练效率提升)
设计逻辑:融合SGD(随机梯度下降) 的鲁棒性 / 泛化能力与Muon 优化器的自适应性,灵感来源于大语言模型训练(如 Moonshot AI 的 Kimi K2).
改进效果:
- 减少训练轮次:达到同等精度所需 epoch 更少,降低计算成本;
- 提升收敛稳定性:避免 YOLOv8-v13 中 SGD/AdamW 的 “需大量超参调优”“收敛波动” 问题;
- 简化开发流程:减少训练重启次数,性能预测更可控。
三、支持的任务和模式
YOLO26 被设计为一个多任务模型系列,将 YOLO 的多功能性扩展到各种计算机视觉挑战中: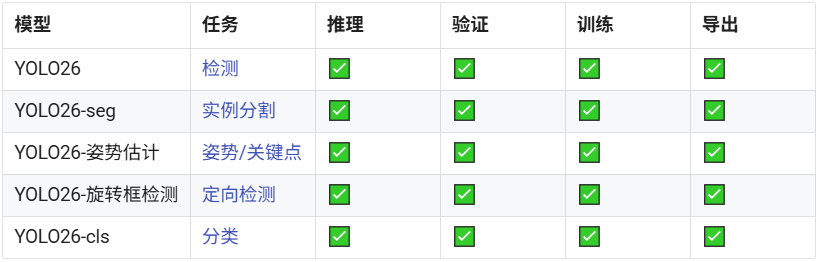
这种统一的框架确保 YOLO26 适用于实时检测、分割、分类、姿势估计和定向对象检测,所有这些都支持训练、验证、推理和导出。
四、部署优势与行业应用
- 多格式无缝导出:支持 ONNX(跨平台)、TensorRT(GPU 加速)、CoreML(iOS)、TFLite(Android /
边缘)、OpenVINO(Intel 硬件),无需自定义转换脚本; - 资源约束适配:可部署于无独立 GPU 的设备(如 ARM CPU 智能相机、Qualcomm Snapdragon AI
加速器),INT8 量化后模型大小缩减 75%; - 低部署门槛:Ultralytics 提供 Python 包,统一训练、验证、导出流程,降低工程师技术成本。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)