数据挖掘可视化学习系统:让Pandas、Scikit-learn变得直观易懂
一、项目概述
这是一个基于Streamlit开发的数据挖掘可视化学习系统,包含数据处理、特征工程和机器学习三大模块,共36个逐步递进的实战案例。系统采用侧边栏导航设计,用户可以选择不同主题进行交互式学习,每个案例都提供代码实现、示例演示和实时运行功能。从基础的Pandas数据框操作到高级的关联规则挖掘,系统覆盖了完整的数据科学工作流程,让学习者能够直观理解每个概念并通过实践掌握技能。
二、适用范围
适用于数据科学初学者和教学场景。学生可交互式学习从数据处理到机器学习的全流程;教师可作为可视化教学工具;职场新人能快速掌握数据分析基础;适合个人自学、课堂辅助、团队培训等场景。无需复杂环境配置,一站式实践平台。
三、技术栈
-
前端框架: Streamlit(全栈Web应用)
-
数据处理: Pandas, NumPy
-
机器学习: Scikit-learn
-
可视化: Matplotlib
-
数据处理: 内置
io、random模块
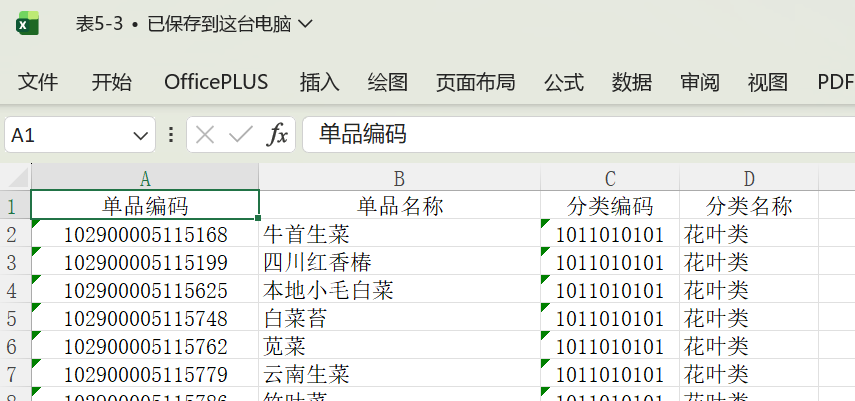
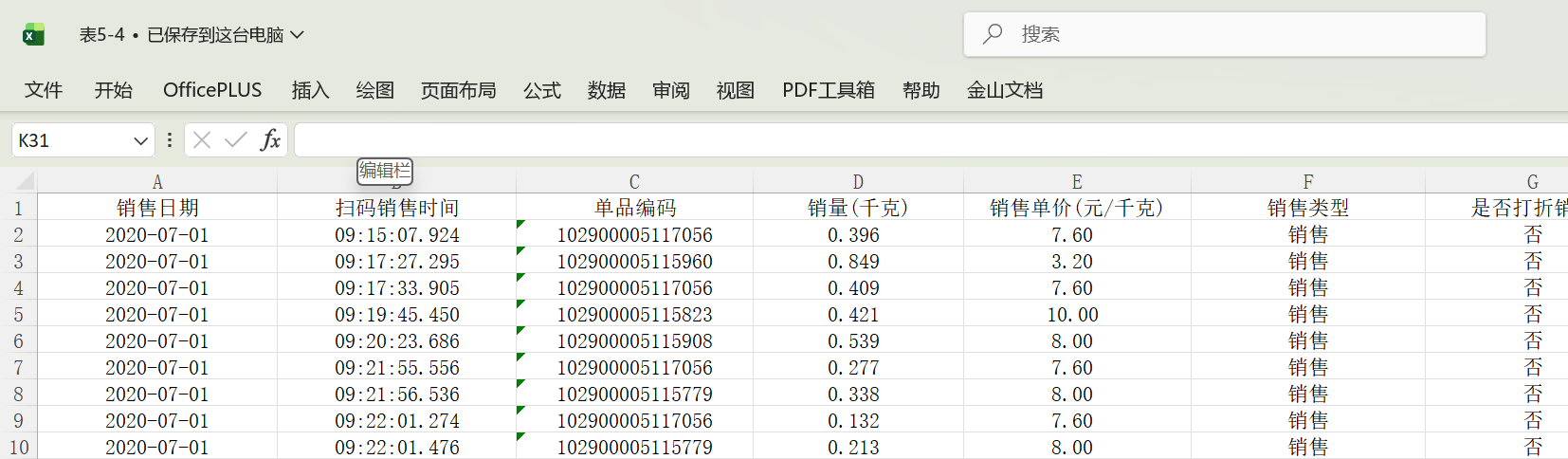
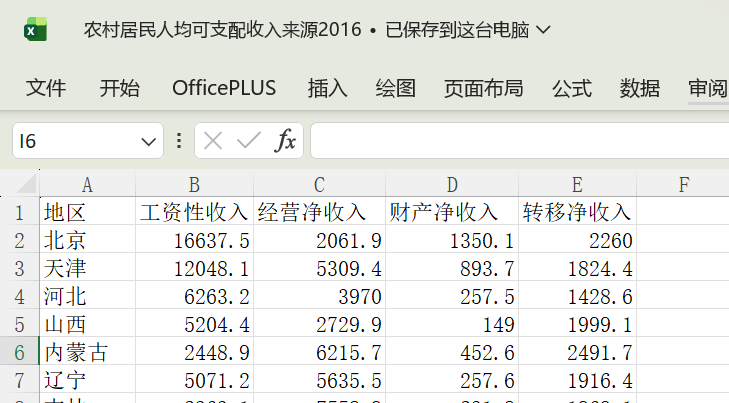
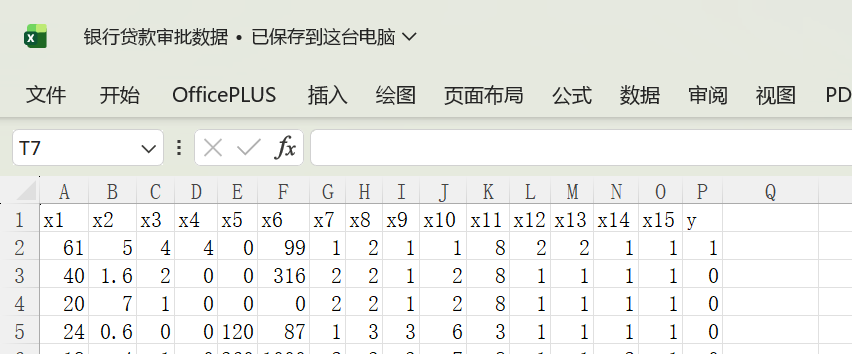
四、数据集准备

![]()
![]()

五、模块逻辑
5.1 主页面设置
第一级:三大学习栏目(左侧栏主导航) ↓ 第二级:具体学习内容(子选择框) ↓ 第三级:详细内容(主区域)
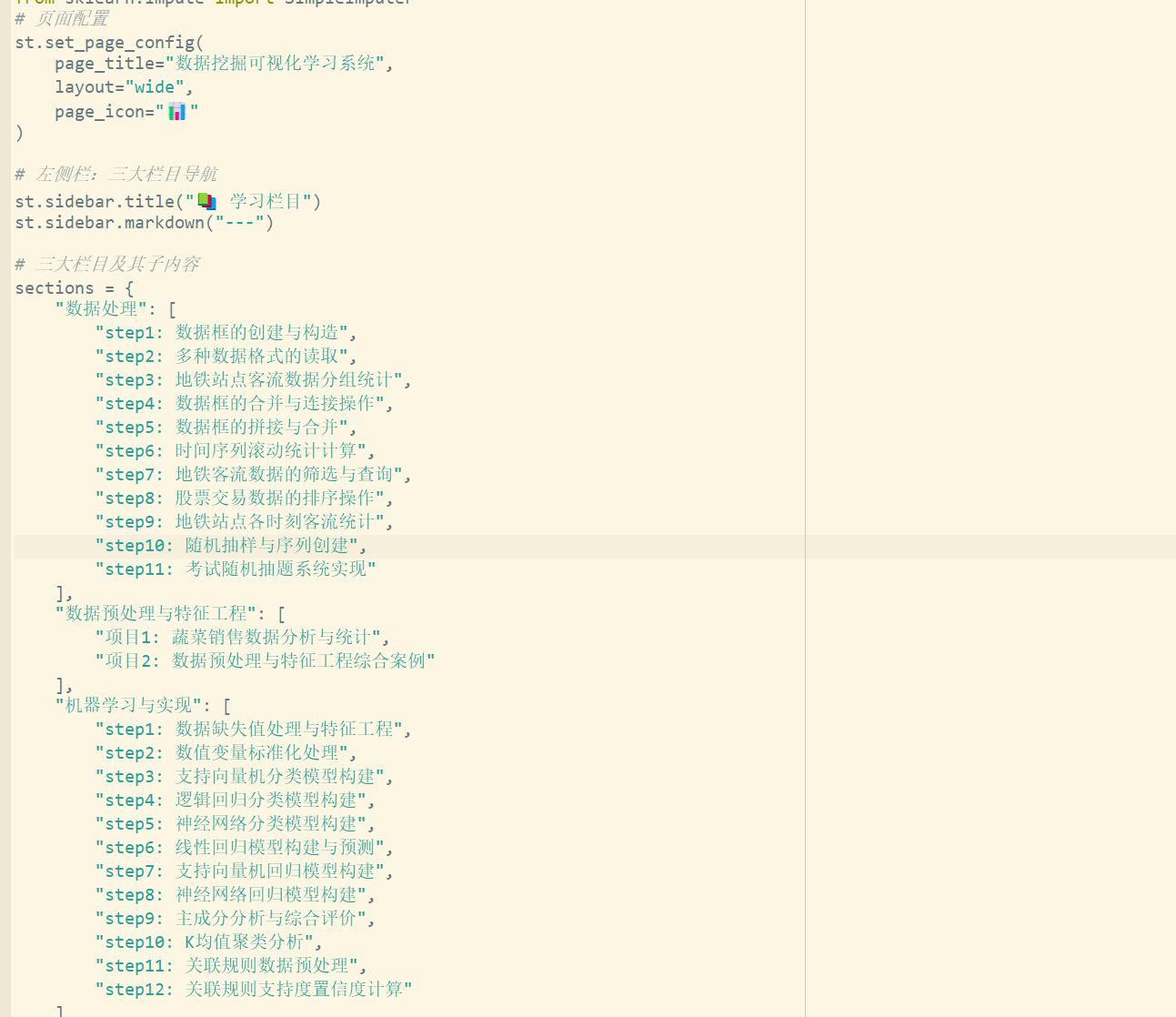
5.2 侧边选择
- 主栏目选择独立
- 子内容动态生成

5.3 三大模块分区展示
-
三大核心模块:数据处理 → 数据预处理 → 机器学习
-
渐进式学习路径:从基础到高级,逻辑清晰
-
细分子步骤:每个模块拆分为多个学习步骤/项目
-
左侧边栏导航:清晰的层级结构
-
二级选择:先选模块,再选具体内容



六、模块分析
6.1 数据处理模块
step1
展示step1代码,以及用数据框展示数据
-
数据结构定义 - 列表和元组的创建
-
混合数据类型处理 - 数字与字符串并存
-
数据框构造方法:
-
简单构造:默认索引+自定义列名
-
复杂构造:自定义索引+自定义列名
-



step2
展示step2代码,以及读取文件数据并提供文件数据下载
-
Excel文件:
pd.read_excel("文件.xlsx", "Sheet2") - TXT文件:
pd.read_table("文件.txt", header=None)(无表头) -
CSV大文件:分块读取
chunksize=20000 -
简单读取:Excel、TXT
-
复杂处理:CSV分块读取



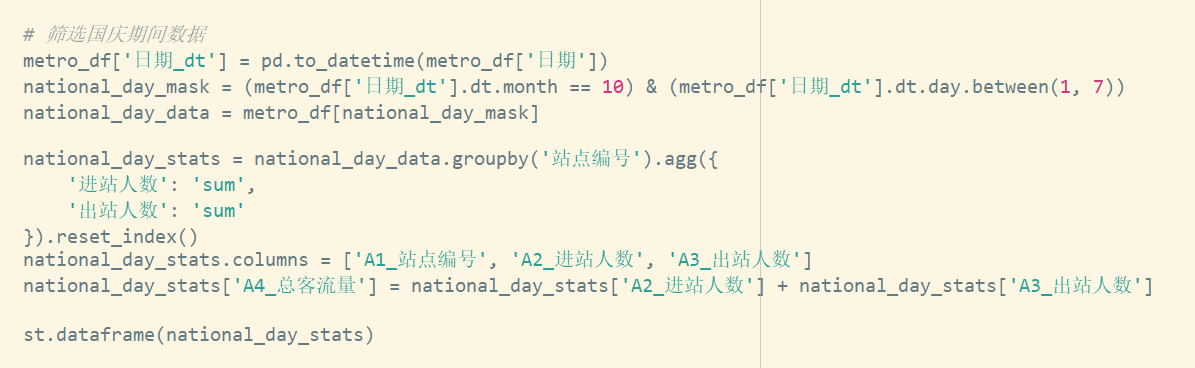
step3
展示step3代码,使用groupby()进行分组统计,使用布尔索引筛选特定站点,使用sort_values()进行排名
-
学习目标:掌握使用groupby进行数据分组统计
-
任务描述:地铁客流数据的三个具体分析任务
-
核心知识点:分组统计的关键技术要点
-
基础任务:获取站点编号列表
-
核心任务:每日分组统计
-
高级任务:特定日期段筛选统计


step4
展示step4代码,并使用数据框展示运行示例
-
学习目标:掌握数据框的合并与连接操作
-
任务描述:四个具体的合并连接任务
-
核心知识点:合并连接的技术要点
-
字典创建DataFrame:
pd.DataFrame(dict1) -
三种连接操作:
-
内连接:
how='inner' -
左连接:
how='left' -
右连接:
how='right'
-
-
多键连接:
on=['code','month']


step5
展示step5代码,并使用数据框展示运行示例
-
多字典创建DataFrame:分别创建df1、df2、df3
-
水平合并(axis=1):
pd.concat([df1, df2], axis=1)- 按列合并 -
垂直合并(axis=0):
pd.concat([df3, df4], axis=0)- 按行合并 -
索引重置:
ignore_index=True- 重新生成顺序索引


step6
展示step6代码,并使用数据框展示运行示例
-
学习目标:掌握时间序列滚动统计计算方法
-
任务描述:四个具体的滚动计算任务
-
列表转序列:
S = pd.Series(L)- 基础数据结构转换 -
滚动窗口创建:
S.rolling(window=10)- 创建窗口大小为10的滚动对象 -
多种统计量计算:
-
滚动求和:
.sum() -
滚动均值:
.mean() -
滚动最大值:
.max() -
滚动最小值:
.min()
-


step7
展示step7代码,并使用数据框展示运行示例
-
iloc索引法:基于整数位置的索引
-
D.iloc[:,0]:选取第0列(所有行) -
D.iloc[:,0].values:获取列的值数组
-
-
loc索引法:基于标签的索引
-
D['站点编号']:通过列名选取列 -
D['站点编号'].values:获取值数组
-
-
复杂条件筛选:
-
站点条件:
== 135 -
日期范围:
<= '2015-10-02' -
时间范围:
>= 9且<= 11
-


step8
展示step8代码,并使用数据框展示运行示例
-
axis=0:按行排序(默认值)
-
升序排序:默认从小到大
-
多列顺序:列表中的顺序决定优先级


step9
展示step9代码,并使用数据框展示运行示例
-
学习目标:掌握分组统计和数据处理方法
-
任务描述:四个具体的数据处理任务
-
核心知识点:完整数据处理流程的技术要点

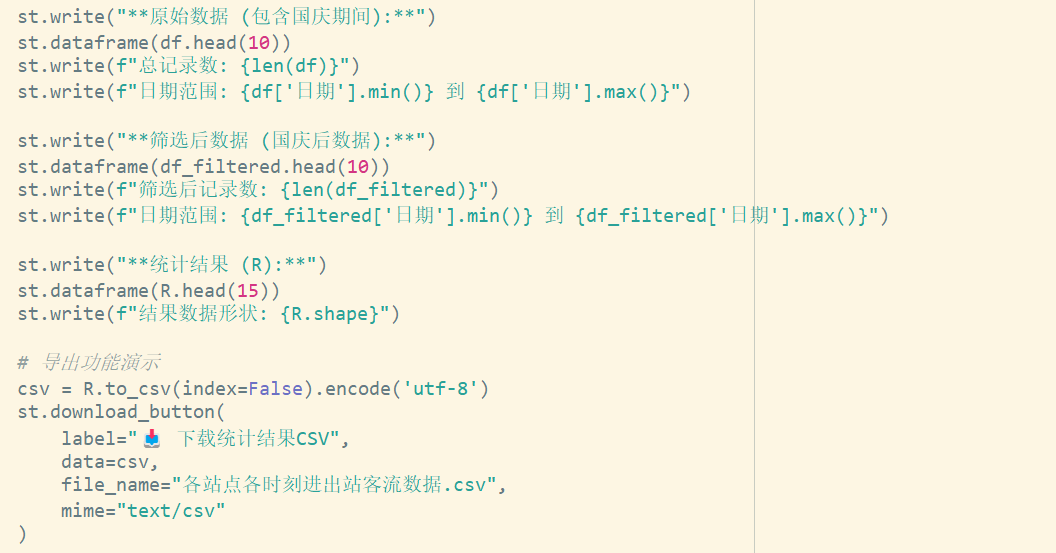
step10
展示step10代码,并使用数据框展示运行示例
-
无放回抽样:
random.sample()确保每个元素只被抽中一次 -
索引设置:Series可以自定义索引
-
随机种子:
random.seed(42)保证结果可重现


step11
展示step11代码,并使用数据框展示运行示例
-
学习目标:掌握随机数生成和数据框创建方法
-
任务描述:四个具体的系统构建任务
-
核心知识点:随机数生成和数据处理的技术要点


6.2 数据预处理与特征工程模块
项目一
-
以“单品编码”为关联字段,进行内连接合并
-
计算销售额 = 销量 × 单价
-
按蔬菜品类和日期分组统计销售量和销售额
-
使用
groupby分组计算:-
每个品类每天的销售量总和
-
每个品类每天的销售额总和
-
-
返回合并后的数据表和两个分组结果


项目二
-
对累计变量进行离散化处理
-
对故障标签y进行映射操作(将4001映射为1,0保持为0)
-
处理样本不均衡问题(过采样)
-
特征选择并比较模型效果
-
标签映射编码(map函数)
-
数据去重处理(drop_duplicates)
-
特征重要性评估(如基于树模型的特征重要性)


6.3 机器学习与实现
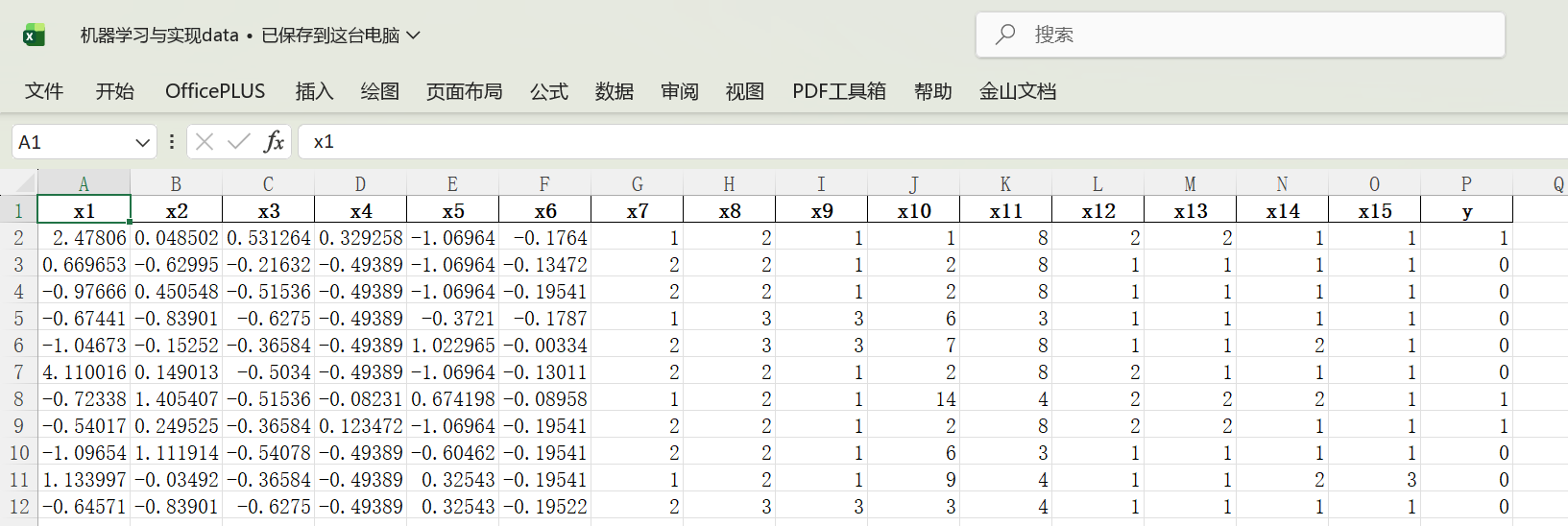
step1
-
读取数据
-
对数值变量(x1-x6)的缺失值使用均值策略填充
-
对名义变量(x7-x15)的缺失值使用最频繁值策略填充
-
返回处理后的自变量X和决策变量Y


step2
-
对数值变量(x1~x6)进行均值-方差标准化(Z-score标准化)
-
保留名义变量(x7~x15)不变
-
返回标准化处理后的完整自变量矩阵
X1 -
均值-方差标准化(Z-score标准化)
-
数值变量与名义变量的区别处理
-
标准化公式:z = (x - μ) / σ
-
数据预处理的重要性(消除量纲影响,提高模型性能)


step3
-
加载
X1.npy和Y.npy -
划分数据:前600条为训练集,后90条为测试集
-
创建SVM分类器(使用默认参数)
-
训练模型并预测
-
计算训练集和测试集准确率
-
返回
(rv, r)

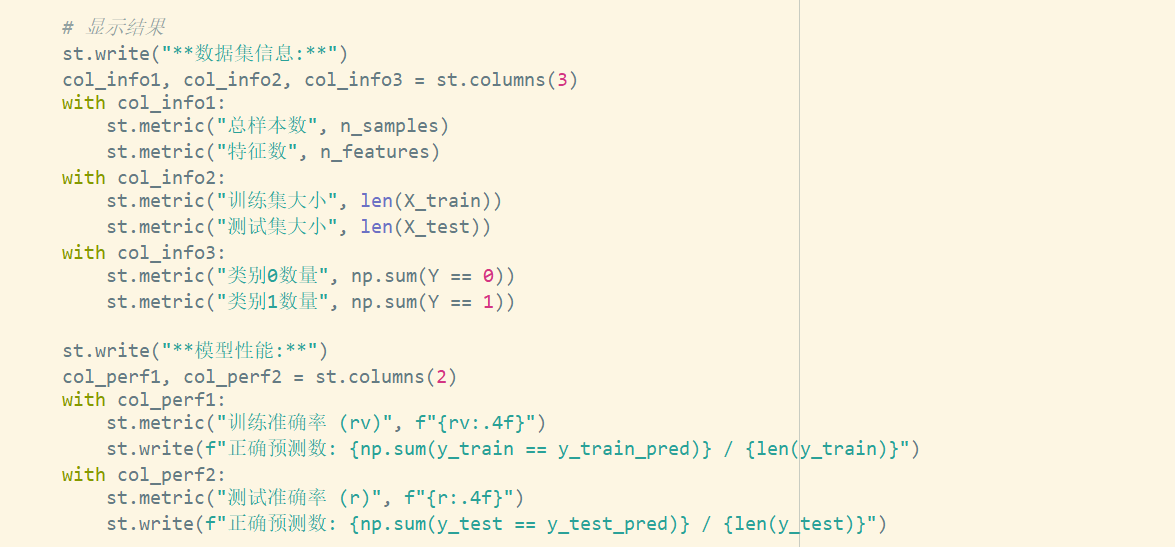
step4
-
加载
Xl.npy和Y.npy(注意:Xl应为X1) -
划分数据:前600条为训练集,后90条为测试集
-
创建逻辑回归分类器(设置
max_iter=2000确保收敛) -
训练模型并预测
-
计算训练集和测试集准确率
-
返回
(rv, r)


step5
-
使用前600条记录作为训练数据
-
使用后90条记录作为测试数据
-
构建神经网络分类模型(MLPClassifier)
-
输出:
-
训练集准确率(rv)
-
测试集准确率(r)
-


step6
-
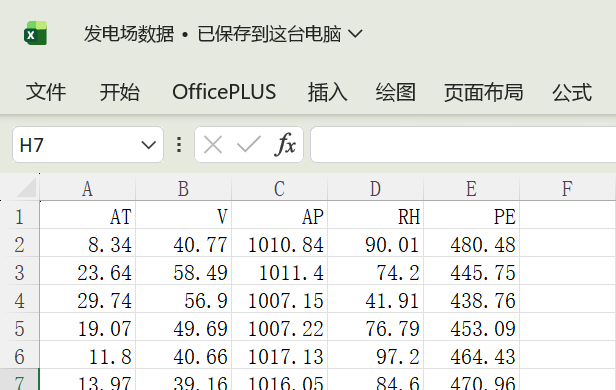
求出 PE与AT、V、AP、RH之间的线性回归关系式系数向量
-
求出 回归方程的拟合优度(判定系数R²)
-
利用模型预测 AT=28.4、V=50.6、AP=1011.9、RH=80.54 时的 PE 值
-
读取
发电场数据.xlsx -
提取自变量(前4列)和因变量(第5列)
-
创建
LinearRegression模型并训练 -
获取系数和截距,合并为列表
b -
计算判定系数
r(拟合优度)


step7
-
读取
发电场数据.xlsx -
提取自变量(前4列)和因变量(第5列)
-
循环测试四种核函数(linear、poly、rbf、sigmoid)
-
分别训练 SVR 模型,记录拟合优度和预测值
-
将结果整理为字典
-
支持向量机回归模型(SVR)
-
不同核函数的效果(线性、多项式、RBF、Sigmoid)


step8
-
读取
发电场数据.xlsx -
提取自变量(前4列)和因变量(第5列)
-
创建
MLPRegressor神经网络回归模型,参数为:-
hidden_layer_sizes=(10, 5)(两层隐藏层,第一层10个神经元,第二层5个神经元) -
max_iter=1000(最大迭代次数) -
random_state=42(随机种子)
-
-
训练模型并计算拟合优度(R²)
-
对新数据进行预测


step9
-
读取数据,提取指标数据(X)和地区名称(dq)
-
使用
StandardScaler进行标准化 -
使用
PCA进行主成分分析,设置n_components=0.95(累计贡献率≥95%) -
计算综合得分:
X_pca与explained_variance_ratio_的点积(加权和) -
创建 Series 对象
Rs,按综合得分降序排序


step10
-
读取数据,提取指标数据(X,排除“地区”列)
-
使用
StandardScaler进行标准化 -
创建
KMeans模型,参数为:-
n_clusters=4(聚类数) -
random_state=0(随机种子) -
max_iter=500(最大迭代次数)
-
-
训练模型并获取聚类标签
c -
创建 Series 对象
Fs,以地区为索引,聚类标签为值 -
按标签升序排序并返回

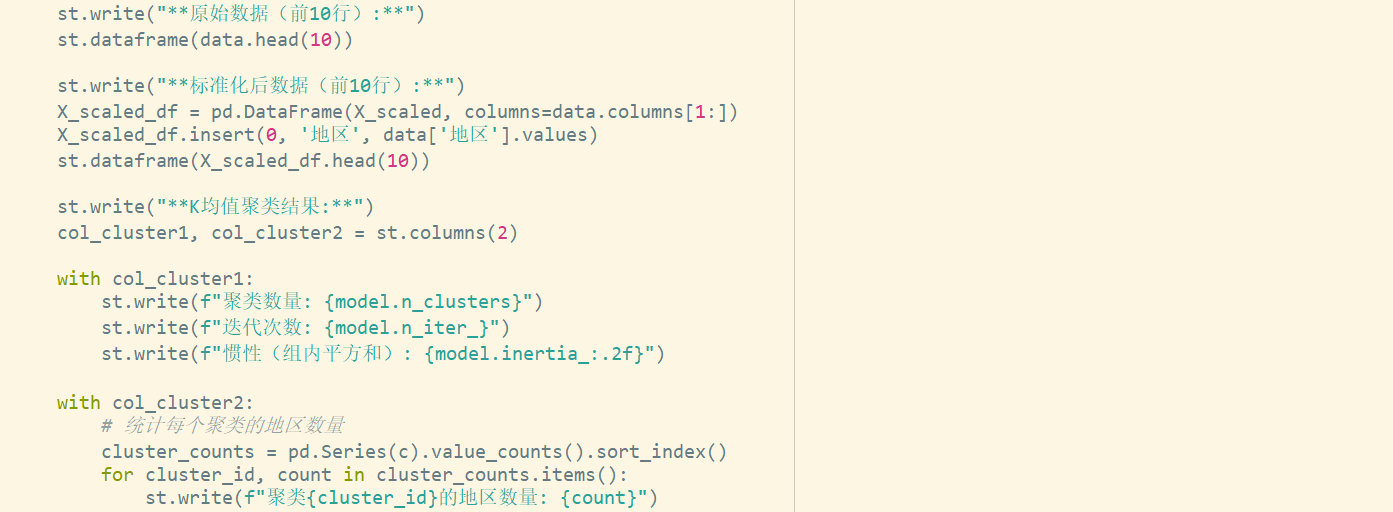
step11
-
读取
超市购买记录.txt -
解析每一行,提取商品列表
-
构建所有唯一商品集合
-
创建布尔 DataFrame(交易×商品)
-
返回该 DataFrame


step12
-
计算规则 "A → B" 的:
支持度(Support)置信度(Confidence) -
计算规则 "A,B → C" 的:
支持度 置信度-
关联规则基本概念(前项、后项、规则)
-
支持度计算方法:
Support(A→B) = P(A∩B) -
置信度计算方法:
Confidence(A→B) = P(B|A) = Support(A∩B)/Support(A) -
规则评估指标(支持度、置信度)
-
关联规则挖掘意义(发现项集间关系)
-


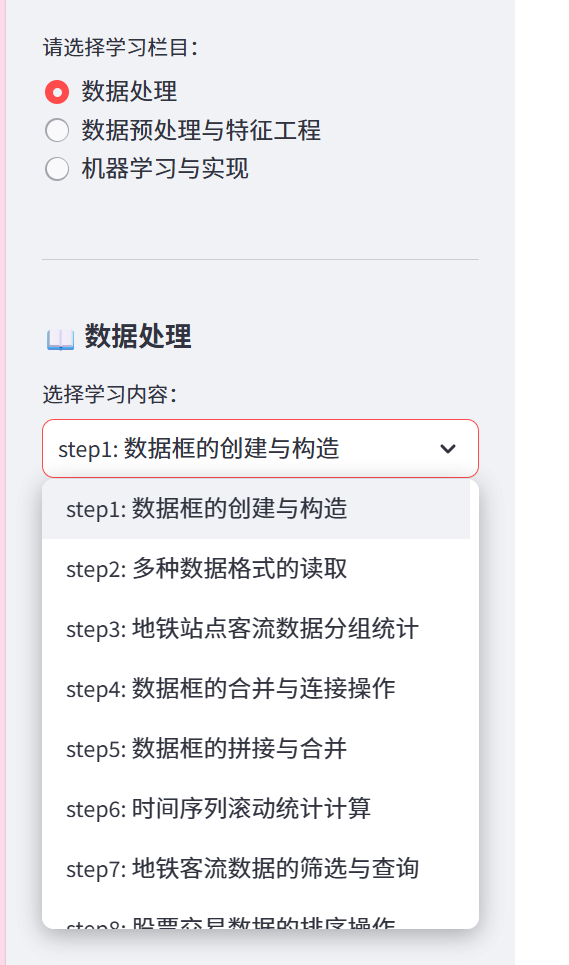
七、界面介绍
每个学习步骤均采用相同的界面结构:
-
左侧栏:任务描述 + 数据说明
-
右侧栏:核心知识点 + 代码实现区域
学习目标:明确该步骤的学习重点
任务描述:具体的数据处理或建模任务
核心知识点:涉及的理论和技能点
代码实现:
-
可展开/折叠的代码块
-
包含完整或部分代码实现
-
部分步骤提供“运行示例”按钮

-
选择栏目:点击单选按钮切换不同栏目
-
选择步骤:点击某个step后,右侧或下方应显示:
-
学习目标
-
任务描述
-
核心知识点
-
代码实现区域
-
运行按钮
-
八、程序总结
该代码构建了一个交互式的数据挖掘学习平台,使用Streamlit实现Web界面。系统左侧导航栏分为数据处理、数据预处理与特征工程、机器学习与实现三大模块,每个模块包含多个具体学习步骤(如数据框创建、缺失值处理、SVM分类等)。每个学习主题都提供详细的任务描述、核心知识点、可执行的代码示例,以及交互式演示功能(用户可点击按钮生成示例数据并查看运行结果)。系统还集成了多种数据可视化组件(如DataFrame展示、统计图表、结果下载等),帮助学习者直观理解数据挖掘的各个环节。整体设计结构清晰,内容全面,适合循序渐进地学习数据科学技能。
学习心得
-
系统性教学:代码将数据挖掘流程模块化,从基础的数据处理到高级的机器学习算法,形成了完整的学习路径,适合不同阶段的学习者。
-
交互式体验:利用Streamlit的交互组件(如下拉菜单、按钮、数据展示等),让学习过程更加直观和动手实践,增强了学习效果。
-
代码可复用性:每个学习步骤的代码都独立且完整,学习者可以直接运行和修改,便于理解和实验。
-
实际案例驱动:许多步骤(如地铁客流分析、蔬菜销售统计)都基于真实场景的数据,增强了学习的实用性和趣味性。
-
可视化辅助:通过Pandas DataFrame、Matplotlib图表等形式展示数据和处理结果,帮助用户直观理解数据变化和模型效果。
注:本程序部分优化来源于AI协助

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)