LUMI 大模型分拣机器人应用 和 Lumi视觉标定****
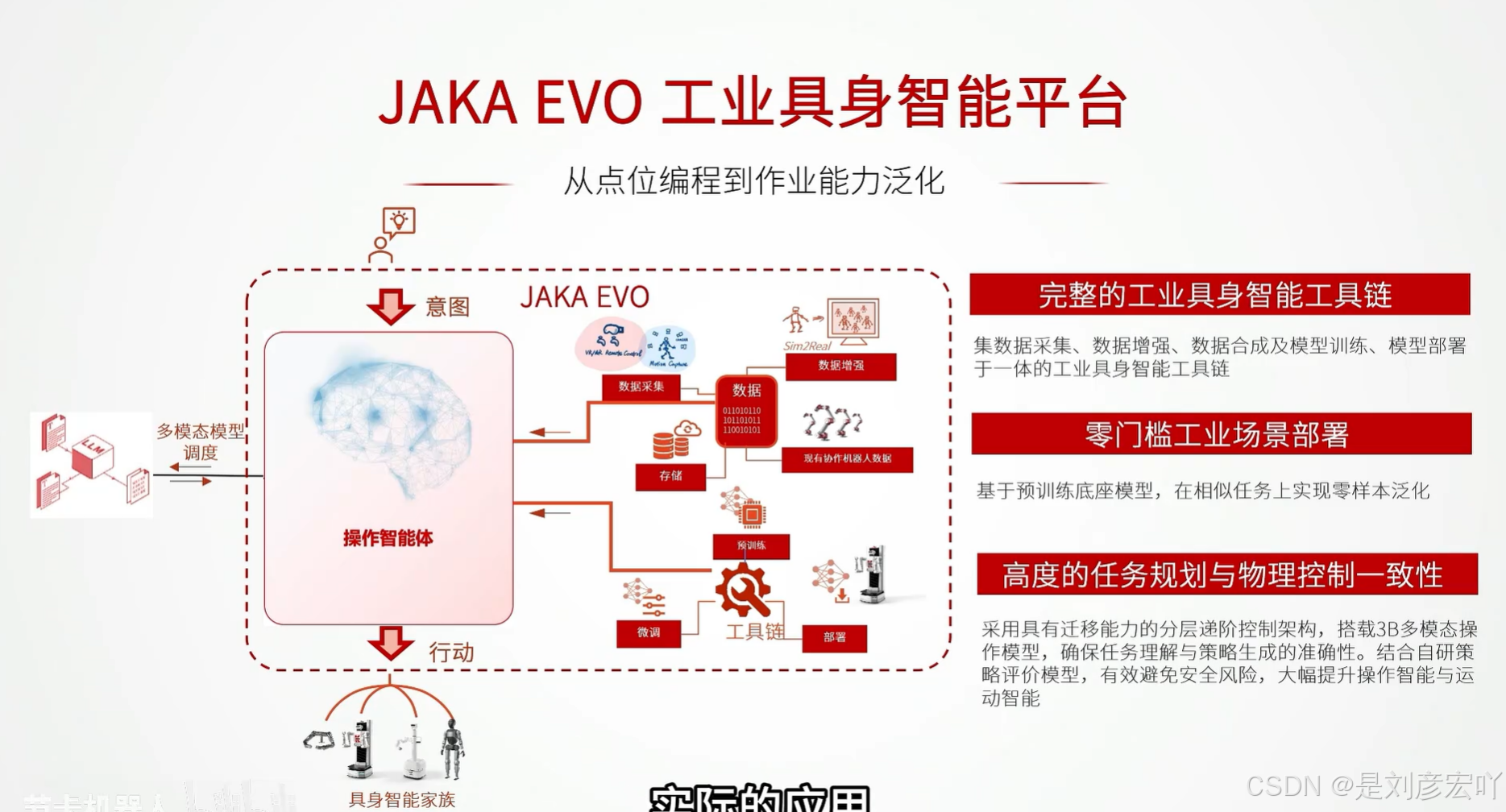
1、JAKA 具身智能机器人家族和EVO平台
1.1 EVO平台
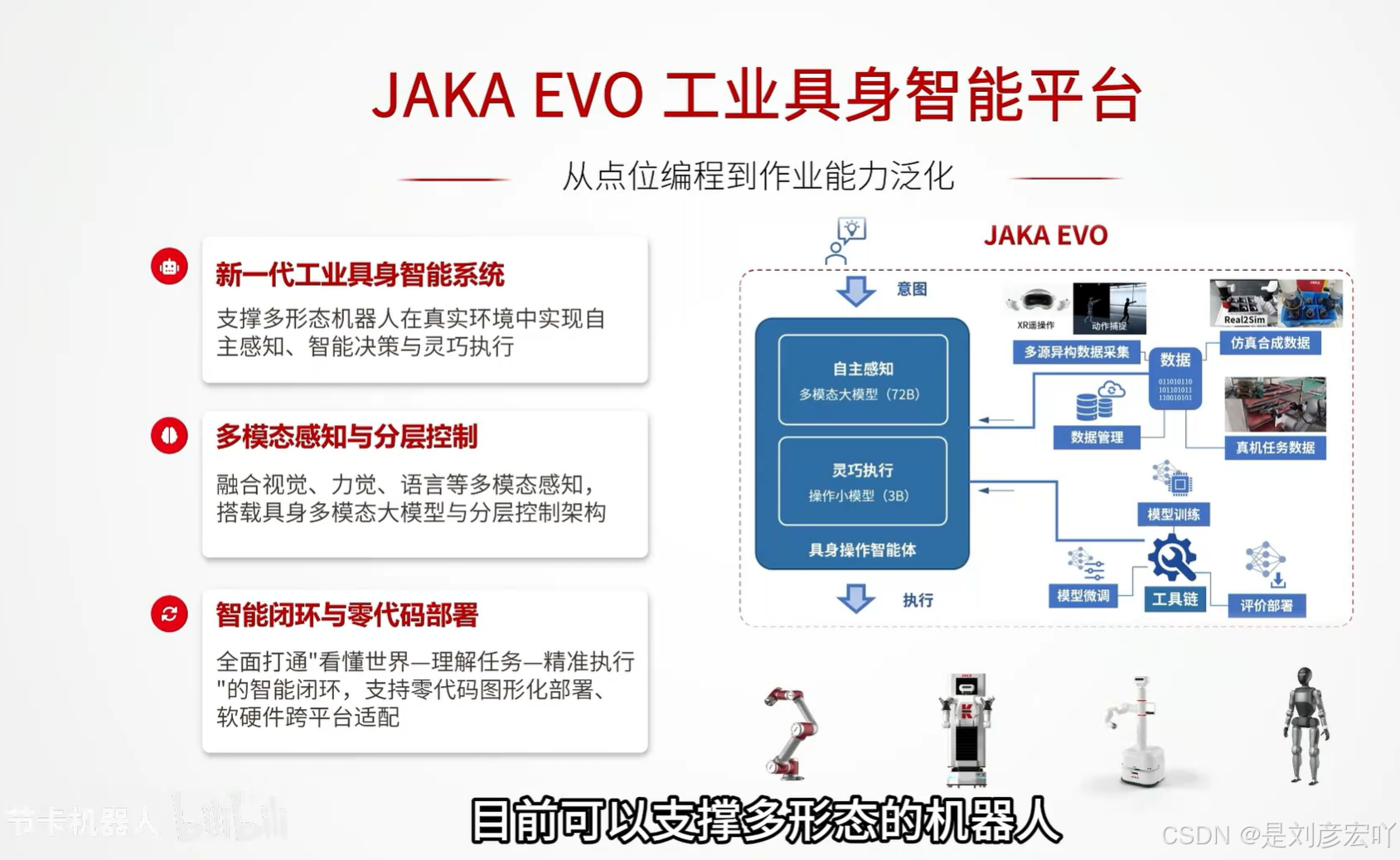
JAKA EVO 工业具身智能平台总结
核心理念: 从传统的“点位编程”升级为“作业能力泛化”,赋予机器人更强的自主感知、决策与执行能力。
核心特点与优势:
-
新一代工业具身智能系统:
- 支持多形态机器人在真实复杂环境中实现自主感知、智能决策与灵巧执行。
-
多模态感知与分层控制:
- 多模态感知:融合视觉、力觉、语音等多种感知方式。
- 分层控制:搭载具身多模态大模型与分层控制架构,提升智能水平和控制精度。
-
智能闭环与零代码部署:
- 智能闭环:打通“看懂世界—理解任务—精准执行”的完整链路。
- 零代码部署:支持零代码图形化操作,降低使用门槛,提升部署效率。
- 软件跨平台适配:具备良好的软件兼容性,可跨不同平台适配。
平台架构核心流程(推测):
- 意图输入 → 自主感知(多模态大模型)→ 具身通用智能体(决策)→ 灵巧执行(操作小模型)→ 执行反馈。
- 数据支撑:整合多源异构数据、仿真数据、真实任务数据等进行数据管理与模型训练(视觉训练、模型训练、工具库、评价标准)。
应用范围:
- 目前可支撑多形态的机器人,展现出良好的通用性和扩展性。
总结:
JAKA EVO 平台旨在通过先进的人工智能技术(特别是具身智能和大模型)、多模态感知融合以及人性化的零代码部署方式,显著提升工业机器人的智能化水平、环境适应性和作业灵活性,推动机器人从简单的执行者向具备自主作业能力的智能体转变。
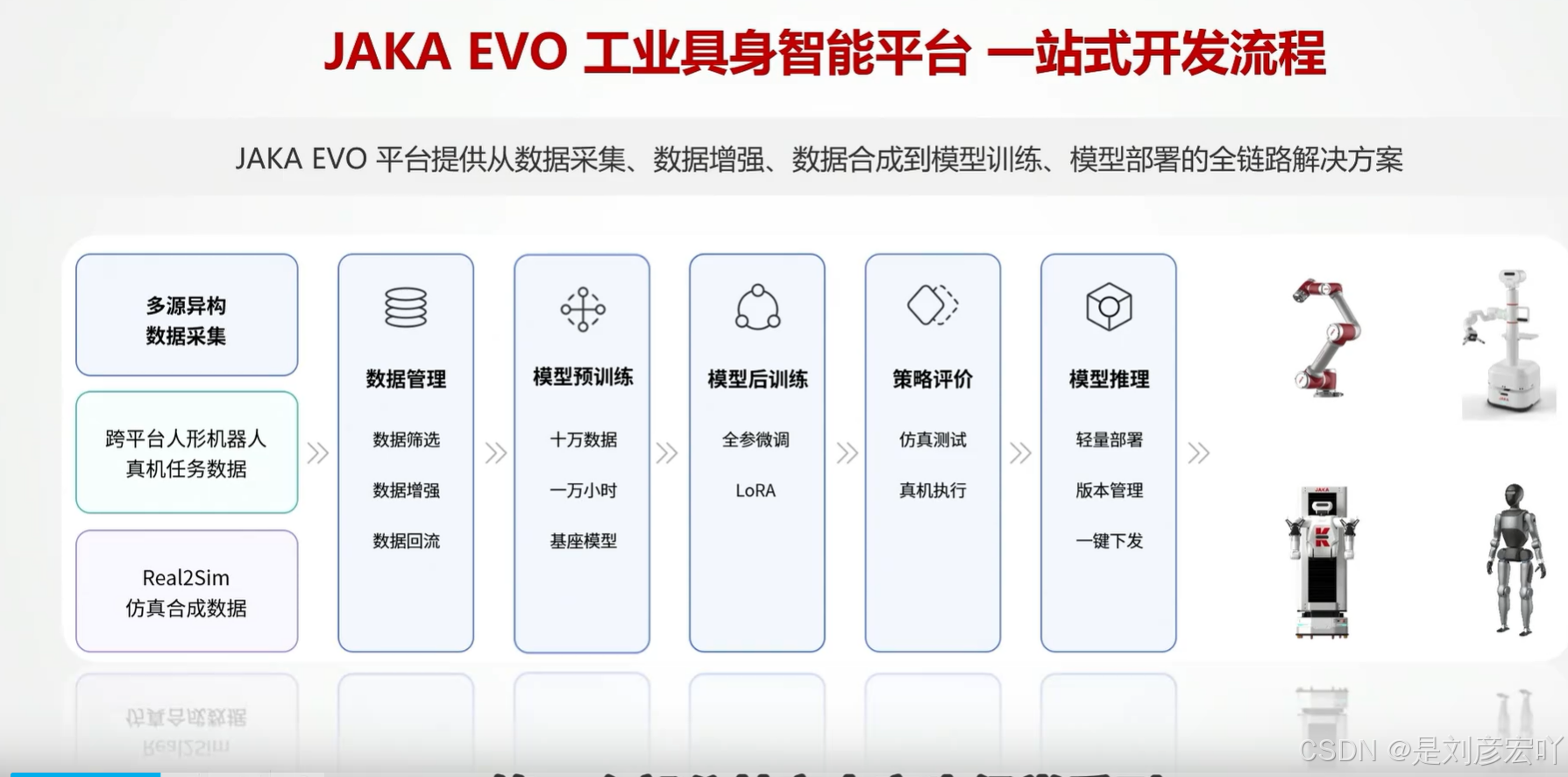
JAKA EVO 工业具身智能平台的一站式开发流程是一个从数据到部署的全链路解决方案,主要包含以下六个核心步骤:
-
多源异构数据采集
- 内容:平台能够收集来自不同渠道和格式的数据。
- 跨平台人形机器人真机任务数据:直接从真实的机器人在实际任务中获取的数据。
- Real2Sim 仿真合成数据:通过仿真环境生成的模拟数据,以补充真实数据。
- 目标:为后续模型训练提供丰富、多样的原始数据。
- 内容:平台能够收集来自不同渠道和格式的数据。
-
数据管理
- 内容:对采集到的数据进行处理和优化。
- 数据筛选:选择高质量、有用的数据。
- 数据增强:通过各种技术手段扩充数据量、提升数据多样性,改善数据质量。
- 数据回流:可能指将后续环节(如模型测试或部署)产生的数据反馈回数据池,形成闭环。
- 目标:确保用于训练的数据是干净、有效且充足的。
- 内容:对采集到的数据进行处理和优化。
-
模型训练
- 内容:利用准备好的数据进行人工智能模型的构建和训练。
- 十万级数据:基于大规模数据进行训练。
- 一万小时基准模型:可能指使用了一万小时级别的数据预训练得到的基础模型,或者训练过程本身耗时。
- 目标:训练出能够完成特定工业任务的初始AI模型。
- 内容:利用准备好的数据进行人工智能模型的构建和训练。
-
模型后训练
- 内容:对初步训练好的模型进行进一步的调优和精进。
- 全参数微调:对模型的所有参数进行调整,以更好地适应特定任务或数据。
- LoRA (Low-Rank Adaptation):一种参数高效的微调方法,只调整少量新增参数,即可使模型适应新任务,同时节省计算资源。
- 目标:提升模型在特定任务上的性能和泛化能力。
- 内容:对初步训练好的模型进行进一步的调优和精进。
-
策略评价
- 内容:对训练好的模型(或其执行策略)进行评估和验证。
- 仿真测试:在虚拟仿真环境中对模型策略进行测试,验证其有效性和安全性。
- 真机执行:在真实的机器人硬件上执行模型策略,进行最终的效果检验。
- 目标:确保模型策略的正确性、可靠性和安全性,满足实际应用需求。
- 内容:对训练好的模型(或其执行策略)进行评估和验证。
-
模型推理
- 内容:将经过验证的模型部署到实际的机器人或生产系统中,并进行管理。
- 轻量化部署:对模型进行优化,使其能够在资源受限的边缘设备(如机器人控制器)上高效运行。
- 版本管理:对不同版本的模型进行追踪和管理。
- 一键下发:便捷地将选定版本的模型部署到目标机器人或设备上。
- 目标:实现模型从研发环境到生产环境的平稳过渡和高效运行,最终赋能工业机器人。
- 内容:将经过验证的模型部署到实际的机器人或生产系统中,并进行管理。
总结:
JAKA EVO平台旨在提供一个端到端的闭环开发流程。从多源数据的采集与管理开始,经过模型的训练与精细调优,再到严格的策略评估与验证,最终实现模型的高效部署与推理,从而快速、高效地开发和部署工业具身智能应用,赋能于人形机器人及其他工业自动化场景。这个流程强调了数据驱动、仿真与真实结合、以及模型全生命周期管理的重要性。
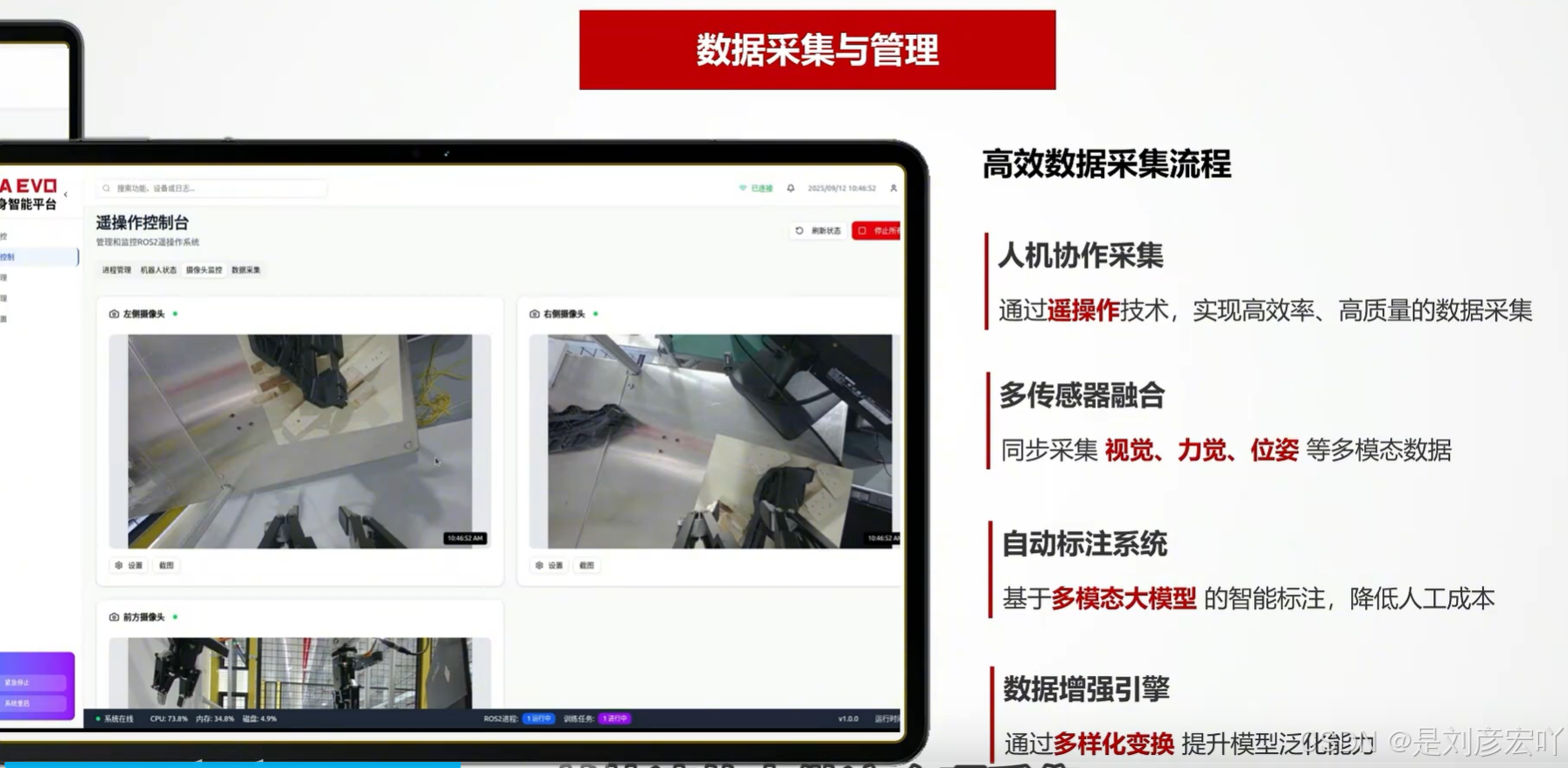
“数据采集与管理”的核心在于高效数据采集流程,其关键要素包括:
- 人机协作采集:通过遥操作技术,实现高效率、高质量的数据采集。
- 多传感器融合:同步采集视频、力觉、位姿等多模态数据。
- 自动标注系统:基于多模态大模型的智能标注,降低人工成本。
- 数据增强引擎:通过多样化变换,提升模型泛化能力。
总结来说,该方案旨在通过人机协作、多传感融合、智能标注和数据增强等手段,实现高效、高质量、低成本的数据采集与管理,为后续模型训练提供有力支持。
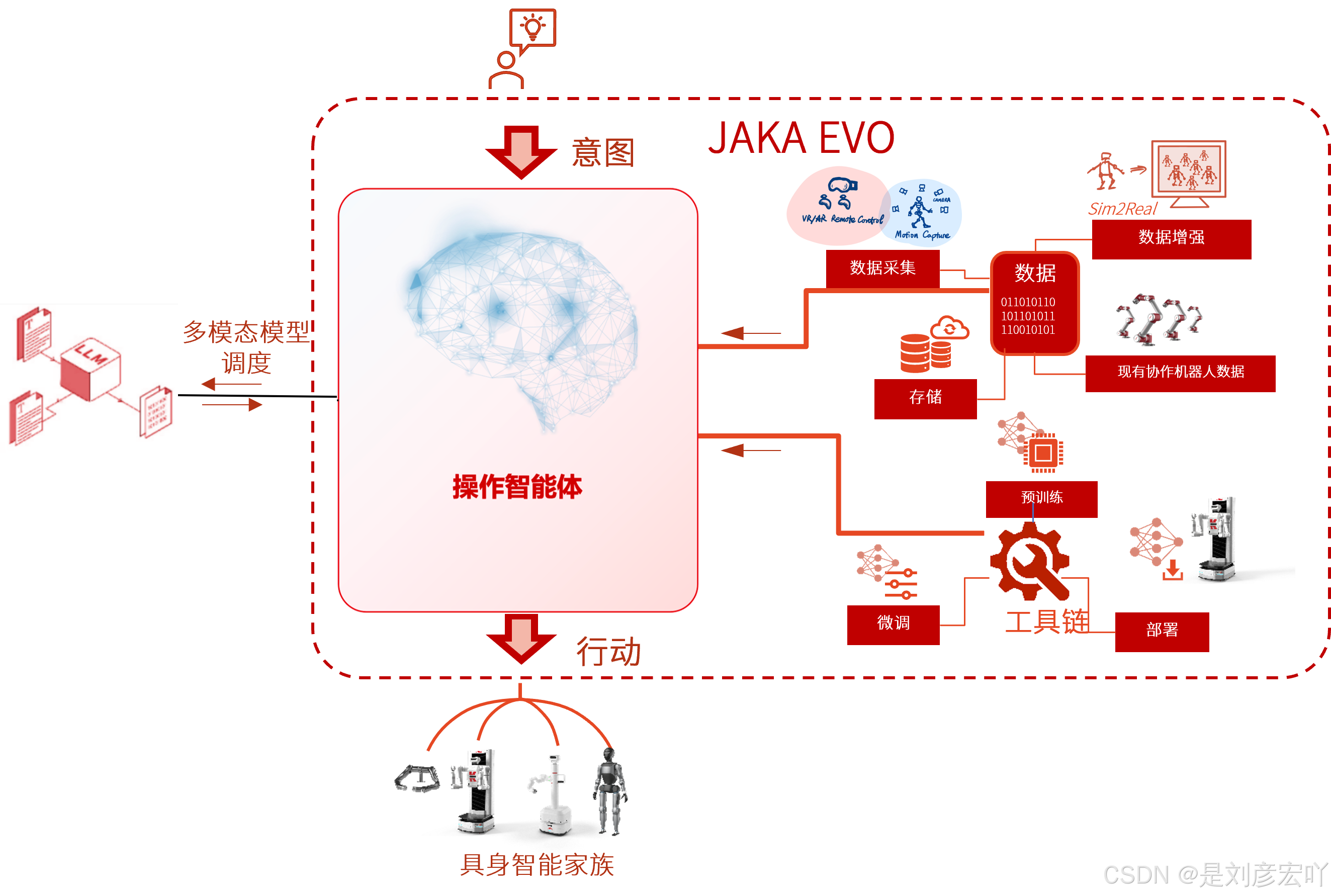
JAKA EVO 工业具身智能平台总结
核心理念:
从传统的“点位编程”升级为“作业能力泛化”,通过智能化技术提升工业机器人的自主决策与灵活执行能力。
核心架构与功能:
-
操作智能体(核心)
- 接收用户“意图”,结合“多模态视觉感知”(如摄像头、传感器数据)进行分析决策,最终输出“行动”指令。
- 连接“具身智能家族”(机器人硬件),实现从感知到执行的闭环。
-
技术支撑模块
- 数据层:涵盖数据采集、存储、分析与模型训练,形成完整的工业智能工具链。
- 工具链:集成环境感知、数据处理、模型构建与部署,支持端到端的智能化任务开发。
三大核心优势:
-
完整的工业具身智能工具链
- 一体化整合数据采集、标注、融合、模型训练及部署,简化开发流程。
-
零门槛工业场景部署
- 基于预训练模型,通过“样本泛化”能力,在相似任务中快速适配,降低使用难度。
-
高度的任务规划与物理控制一致性
- 采用分层进阶控制结构,结合3B+多模态模型,确保任务规划与执行的精准性;
- 融合碰撞检测与动态避障,提升操作安全性与智能适应性。
应用目标:
实现工业机器人从“被动执行”到“主动决策”的跨越,提升复杂场景下的作业效率、安全性与灵活性,推动智能制造向更高阶的自主化发展。
总结:
JAKA EVO 平台通过“感知-决策-执行”一体化架构,结合数据驱动与模型泛化能力,旨在解决传统工业机器人编程复杂、场景适应性差的痛点,为工业智能化提供高效、低门槛的解决方案。
1.12 具身智能机器人家族

1、JAKA K1


2、JAKA Kargo

3、JAKA Lumi


4、JAKA K1L


2、项目的结构化技术文档整理
以下是对"LUMI大模型分拣机器人应用"项目的结构化技术文档整理,重点突出核心功能与操作流程:
一、项目架构概览
二、核心功能模块
- 视觉抓取系统(
visualDetect_ali.py)
- 工作模式:
--auto:全自动执行(无人工确认)--camera-sn:指定相机序列号--list-cameras:枚举可用相机
- 技术栈:
- 阿里大模型目标检测(需
dashscope_api_key) - OpenCV实时图像处理
- 机器人位姿解算
- 阿里大模型目标检测(需
- 多站点调度引擎(
multi_station_demo.py)
- 调度策略:
# 伪代码逻辑 while stations: agv.move_to(station) if station.mode == "grasp_priority": execute_grasp_before_put() elif station.mode == "put_only": release_object() - 配置文件驱动:
conf/userCmdControl.json定义站点参数- 支持动态加载站点配置
- 标定系统
| 脚本文件 | 功能描述 | 关键操作 |
|---|---|---|
AutoCalibProccess.py |
手眼标定数据采集 | 按k采集,按p计算 |
visualValidCalib.py |
标定结果验证(像素→世界坐标映射) | 点击图像实时输出坐标 |
三、部署关键步骤
- 环境配置
依赖安装
pip install -r requirements.txt # 含opencv/numpy/dashscope
SDK配置
export LD_LIBRARY_PATH=/path/to/JAKA_SDK_LINUX:$LD_LIBRARY_PATH
-
标定流程
-
运行
AutoCalibProccess.py→ 采集15组以上位姿数据 -
生成
CalibParams-lumi-hand.json(含相机内参/外参) -
使用
visualValidCalib.py验证映射误差(需<1mm) -
启动分拣任务
单站点抓取(自动模式)
python visualDetect_ali.py --auto --camera-sn ABC123
多站点调度
python multi_station_demo.py
四、配置文件详解(CalibParams-lumi-hand.json(含相机内参/外参))
{
"CameraMatrix": [
[
609.9114684876723,
0.0,
638.9891937054473
],
[
0.0,
609.6184563342996,
365.7710880006769
],
[
0.0,
0.0,
1.0
]
],
"CameraDistCoeffs": [
[
-0.009617626122747252,
-0.048253520420754856,
0.0020027063260829457,
0.00015407968504852678,
0.07459687514773326
]
],
"RotationMat": [
[
0.0024364698258561024,
-0.05155623909217327,
0.9986671206290203
],
[
-0.999811163511517,
0.01912837174298887,
0.003426764101655766
],
[
-0.019279547000229547,
-0.9984868850441314,
-0.05149989769245433
]
],
"TranslationMat": [
[
5.803001575334491
],
[
217.80533478699027
],
[
-33.35354435405952
]
]
}
四、配置文件详解(userCmdControl.json)
{
"cameraParams": {
"align_mode": "SW",
"enable_sync": true,
"saveImgPath": "./images/project1"
},
"objects": {
"moveObjects": "yellow things",
"putObject": "box"
},
"operationMode": "grasp_only",
"robotParams": {
"basePose": [
292,
26,
98,
-24,
58,
-102
],
"relativeUpMotionHeight": 60,
"RelativeOffset-Z": 0,
"RelativeOffset-Zput": 30,
"RelativeOffset-X": 50,
"RelativeOffset-Y": 20
},
"calibrateParams": {
"robotIP": "192.168.10.90",
"CalibrateImageSaveDir": "./lumi_handCam/",
"boardRowNums": 8,
"boardCowNums": 11,
"boardLength": 10
},
"genNearPointParams": {
"nearPointInterval": 10,
"nearPointTimes": 10
},
"systemConfig": {
"robot_ip": "192.168.10.90",
"ext_base_url": "http://192.168.10.90:5000/api/extaxis",
"agv_ip": "192.168.10.10",
"agv_port": 31001
},
"extAxisLimits": {
"joint1": {
"min": 0,
"max": 200,
"desc": "\u5347\u964d\uff0c\u5355\u4f4dmm"
},
"joint2": {
"min": -140,
"max": 140,
"desc": "\u8170\u90e8\u65cb\u8f6c\uff0c\u5355\u4f4d\u5ea6"
},
"joint3": {
"min": -180,
"max": 180,
"desc": "\u5934\u90e8\u65cb\u8f6c\uff0c\u5355\u4f4d\u5ea6"
},
"joint4": {
"min": -5,
"max": 35,
"desc": "\u5934\u90e8\u4fef\u4ef0\uff0c\u5355\u4f4d\u5ea6"
}
},
"stations": {
"station1": {
"name": "station1",
"agv_marker": "desk",
"robot_home_pos": [
292,
26,
98,
-24,
58,
-102
],
"ext_home_pos": [
10,
0,
0,
30
],
"operation_mode": "grasp_only"
},
"station2": {
"name": "station2",
"agv_marker": "move",
"robot_home_pos": [
292,
26,
98,
-24,
58,
-102
],
"ext_home_pos": [
10,
0,
0,
0
],
"operation_mode": "none"
},
"station3": {
"name": "station3",
"agv_marker": "cabinet",
"robot_home_pos": [
292,
26,
98,
-24,
58,
-102
],
"ext_home_pos": [
200,
0,
0,
0
],
"operation_mode": "put_cola"
},
"station4": {
"name": "station4",
"agv_marker": "wait",
"robot_home_pos": [
292,
26,
98,
-24,
58,
-102
],
"ext_home_pos": [
10,
0,
0,
0
],
"operation_mode": "none"
}
}
}
关键参数组:
operationMode:both(抓放一体)/grasp_only(仅抓取)genNearPointParams:深度搜索半径(解决点云噪点)
五、注意事项
-
硬件要求:
- Orbbec Gemini2等深度相机
- JAKA Zu系列机械臂(需支持Ethernet通信)
- AGV需提供ROS接口或TCP通信协议
-
精度保障:
- 标定环境光照需>500lux
- 机械臂重复定位精度需≤0.05mm
- 相机-机械臂距离建议50-80cm
-
扩展能力:
- 支持接入第三方AGV(修改
systemConfig节点) - 可替换视觉模型(修改
dashscope调用逻辑)
- 支持接入第三方AGV(修改
六、二次开发建议
-
视觉模块扩展:
# visualDetect_ali.py中替换检测模型 def detect_objects(image): # 原阿里大模型调用 # result = dashscope.ImageDetection(image) # 替换为YOLOv8示例 results = yolov8_model.predict(image) return parse_yolo_results(results) -
新增功能方向:
- 集成缺陷检测(在抓取前进行质检)
- 增加动态避障模块(通过点云分析)
- 部署数字孪生监控界面
参考资源:
- Orbbec SDK配置指南
- 阿里大模型API密钥获取
- JAKA官方开发文档(见SDK包内
docs目录)
项目采用模块化设计,各脚本均含详细函数注释。建议从
visualValidCalib.py入手理解坐标转换逻辑,再深入调度引擎开发。
六 ## 依赖安装与SDK配置详细步骤
1. Python依赖安装
运行以下命令安装项目所需的Python依赖库(需提前安装Python 3.8+):
pip install -r requirements.txt # 安装OpenCV、NumPy、DashScope等核心库
若遇到网络问题,可使用国内镜像加速安装:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
关键依赖说明:
opencv-python:用于图像处理与相机驱动dashscope:阿里视觉大模型API调用numpy:数值计算支持
2. Orbbec相机SDK配置
安装方式(二选一)
A. 使用官方SDK(推荐)
git clone https://github.com/orbbec/pyorbbecsdk
cd pyorbbecsdk
pip install .
B. 使用项目自带SDK
将项目内OrbbecSDK目录添加到Python路径:
export PYTHONPATH=/path/to/OrbbecSDK:$PYTHONPATH
验证安装:
python -c "import pyorbbecsdk; print(pyorbbecsdk.__version__)"
3. JAKA机器人SDK配置
Linux环境配置
- 解压
JAKA_SDK_LINUX至任意目录(如/opt/JAKA_SDK) - 添加动态链接库路径:
echo 'export LD_LIBRARY_PATH=/opt/JAKA_SDK:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
- 权限设置(避免运行时错误):
sudo chmod -R 755 /opt/JAKA_SDK
验证SDK
运行测试脚本:
cd /opt/JAKA_SDK/examples
./demo_connect # 确认能连接机器人控制器
- 环境变量总体验证
执行以下命令检查所有配置是否生效:
检查Python依赖
pip list | grep -E "opencv|dashscope|numpy"
检查SDK路径
echo $LD_LIBRARY_PATH # 应包含JAKA和Orbbec路径
python -c "import pyorbbecsdk, jakasdk; print('SDK加载成功')"
常见问题解决
| 问题现象 | 解决方案 |
|---|---|
ImportError: libjakasdk.so not found |
检查LD_LIBRARY_PATH是否包含JAKA路径 |
| Orbbec相机无法初始化 | 确认USB3.0接口并安装libusb驱动:sudo apt install libusb-1.0-0-dev |
dashscope认证失败 |
检查API密钥是否在环境变量DASHSCOPE_API_KEY中设置 |
相关的代码文件
Read file: utilfs/handToEyeCalibration.py
Read file: utilfs/handToEyeCalibration.py
Read file: conf/userCmdControl.json
七、手动标定原理详解
**眼在手外(Eye-to-Hand)**的标定方式。其核心原理如下:
1. 标定目标
计算相机相对于机器人基座标系的变换矩阵,即找到相机坐标系到机器人基座标系的变换关系。
2. 标定工具
使用棋盘格标定板作为标定工具:
- 棋盘格尺寸:8×11个内角点
- 每个方格边长:10mm
- 通过检测棋盘格角点来建立相机坐标系与标定板坐标系的关系
3. 数据采集过程
if findCorners(color_image,boardRowNums,boardCowNums):
程序通过以下步骤采集数据:
- 手动控制:用户按’k’键触发数据采集
- 机器人位姿记录:获取当前机器人TCP(工具中心点)的6DOF位姿
[x, y, z, rx, ry, rz] - 图像采集:获取相机拍摄的棋盘格图像
- 角点检测:使用
findCorners函数检测棋盘格角点 - 数据验证:只有成功检测到角点才保存数据
4. 标定算法原理
标定过程基于以下数学关系:
目标变换链:
机器人基座 → 机器人末端 → 相机 → 标定板
数学表达式:
T_base_target = T_base_gripper × T_gripper_camera × T_camera_target
其中:
T_base_gripper:机器人末端到基座的变换(从机器人位姿获得)T_camera_target:标定板到相机的变换(从角点检测获得)T_gripper_camera:相机到机器人末端的变换(待求解)
5. 核心算法步骤
5.1 相机内参标定
def calibCamera(self,images,boardWidth,boardHeight,squareSize,criteria,ShowCorners=False):
objp = np.zeros((boardWidth * boardHeight, 3), np.float32)
objp[:, :2] = np.mgrid[0:boardWidth, 0:boardHeight].T.reshape(-1, 2)
objp = objp * squareSize # 18.1 mm
- 建立标定板的世界坐标系
- 使用OpenCV的
calibrateCamera函数计算相机内参矩阵和畸变系数
5.2 外参计算
def get_RT_from_chessboard(self,imagePoints,objectPoints,mtx,dist,Testing=False):
R_target2camera_list = []
T_target2camera_list = []
for i,corners in enumerate(imagePoints):
_, rvec, tvec = cv2.solvePnP(objectPoints[i], corners, mtx, distCoeffs=dist)
- 对每张图像使用
solvePnP计算标定板到相机的旋转和平移
5.3 手眼标定 utilfs/handToEyeCalibration.py
R_camera2base, T_camera2base = cv2.calibrateHandEye(R_gripper2base_list, T_gripper2base_list,
R_target2camera_list, T_target2camera_list)
使用OpenCV的calibrateHandEye函数求解手眼变换矩阵,该函数基于以下约束:
R_gripper2base × R_camera2gripper = R_camera2base × R_target2camera
import json
import os
import random
import cv2
from math import *
import numpy as np
import matplotlib.pyplot as plt
class Calibration:
def __init__(self,boardWidth,boardHeight,squareSize,ShowCorners=False):
self.boardWidth=boardWidth
self.boardHeight=boardHeight
self.squareSize=squareSize
self.criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
self.ShowCorners=ShowCorners
def calibCamera(self,images,boardWidth,boardHeight,squareSize,criteria,ShowCorners=False):
objp = np.zeros((boardWidth * boardHeight, 3), np.float32)
objp[:, :2] = np.mgrid[0:boardWidth, 0:boardHeight].T.reshape(-1, 2)
objp = objp * squareSize # 18.1 mm
objectPoints = []
imagePoints = []
if isinstance(images, str):
imgPaht=images
images=[]
imgs = [os.path.join(imgPaht, tmp) for tmp in os.listdir(imgPaht)]
print(imgs)
for fname in imgs:
img = cv2.imread(fname)
images.append(img)
else:
images=images
print("Finding corners...")
grayshape=list()
for i,img in enumerate(images):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
grayshape = gray.shape[::-1]
ret, corners = cv2.findChessboardCorners(gray, (boardWidth, boardHeight), None)
if ret == True:
cv2.cornerSubPix(gray, corners, (3, 3), (-1, -1), criteria)
objectPoints.append(objp)
imagePoints.append(corners)
if ShowCorners:
print("img: ",i)
cv2.drawChessboardCorners(img, (boardWidth, boardHeight), corners, ret)
cv2.namedWindow('findCorners', cv2.WINDOW_NORMAL)
cv2.resizeWindow('findCorners', 1280, 640)
cv2.imshow('findCorners', img)
cv2.waitKey(1000)
cv2.destroyAllWindows()
# make folder
if not os.path.exists("../DetectedCorners-k1"):
os.makedirs("../DetectedCorners-k1")
cv2.imwrite("DetectedCorners-k1/DetectedCorners" + str(i) + ".png", img)
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objectPoints, imagePoints, grayshape, None,None)
print("ret:", ret)
# print("mtx:\n", mtx)
# print("dist:\n", dist)
# print("rvecs:\n", rvecs)
# print("tvecs:\n", tvecs)
print("The projection error from the calibration is: ",
self.calculate_reprojection_error(objectPoints, imagePoints, rvecs, tvecs, mtx, dist, False))
return objectPoints,imagePoints,mtx, dist
def get_RT_from_chessboard(self,imagePoints,objectPoints,mtx,dist,Testing=False):
R_target2camera_list = []
T_target2camera_list = []
for i,corners in enumerate(imagePoints):
_, rvec, tvec = cv2.solvePnP(objectPoints[i], corners, mtx, distCoeffs=dist)
if Testing == True:
print("Current iteration: ", i, " out of ", len(imagePoints[0]), " iterations.")
Matrix_target2camera = np.column_stack(((cv2.Rodrigues(rvec))[0], tvec))
Matrix_target2camera = np.row_stack((Matrix_target2camera, np.array([0, 0, 0, 1])))
R_target2camera = Matrix_target2camera[:3, :3]
T_target2camera = Matrix_target2camera[:3, 3].reshape((3, 1))
R_target2camera_list.append(R_target2camera)
T_target2camera_list.append(T_target2camera)
return R_target2camera_list, T_target2camera_list
def calculate_reprojection_error(self, objpoints, imgpoints, rvecs, tvecs, mtx, dist, ShowPlot=False):
"""Calculates the reprojection error of the camera for each image. The output is the mean reprojection error
If ShowPlot is True, it will show the reprojection error for each image in a bar graph"""
total_error = 0
num_points = 0
errors = []
for i in range(len(objpoints)):
imgpoints_projected, _ = cv2.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
imgpoints_projected = imgpoints_projected.reshape(-1, 1, 2)
error = cv2.norm(imgpoints[i], imgpoints_projected, cv2.NORM_L2) / len(imgpoints_projected)
errors.append(error)
total_error += error
num_points += 1
mean_error = total_error / num_points
if ShowPlot:
# Plotting the bar graph
fig, ax = plt.subplots()
img_indices = range(1, len(errors) + 1)
ax.bar(img_indices, errors)
ax.set_xlabel('Image Index')
ax.set_ylabel('Reprojection Error')
ax.set_title('Reprojection Error for Each Image')
plt.show()
print(errors)
# Save the bar plot as a .png
fig.savefig('ReprojectionError.png')
return mean_error
def attitudeVectorToMatrix(self,worldTcpPos, useQuaternion=False, seq=""):
'''
:param worldTcpPos: [x, y, z, rx, ry, rz]
:param use_quaternion:
:param seq:
:return:
'''
assert worldTcpPos.size in [6, 10], "Input matrix must have 6 or 10 elements."
Matrix_gripper2base = np.eye(4, dtype=np.float64)
if useQuaternion:
quaternion_vec = worldTcpPos[3:7].flatten()
R_gripper2base = self.quaternionToRotatedMatrix(quaternion_vec)
Matrix_gripper2base[:3, :3] = R_gripper2base
else:
if worldTcpPos.size == 6:
rot_vec = worldTcpPos[3:].flatten()
else:
rot_vec = worldTcpPos[7:].flatten()
if seq == "":
Matrix_gripper2base[:3, :3]=cv2.Rodrigues(rot_vec)
else:
R_gripper2base = self.eulerAngleToRotatedMatrix(rot_vec, seq)
Matrix_gripper2base[:3, :3] = R_gripper2base
Matrix_gripper2base[:3, 3] = worldTcpPos[:3].flatten()
return Matrix_gripper2base
def quaternionToRotatedMatrix(self,q):
w, x, y, z = q
x2 = x * x
y2 = y * y
z2 = z * z
xy = x * y
xz = x * z
yz = y * z
wx = w * x
wy = w * y
wz = w * z
res = np.array([
[1 - 2 * (y2 + z2), 2 * (xy - wz), 2 * (xz + wy)],
[2 * (xy + wz), 1 - 2 * (x2 + z2), 2 * (yz - wx)],
[2 * (xz - wy), 2 * (yz + wx), 1 - 2 * (x2 + y2)]
])
return res
def eulerAngleToRotatedMatrix(self,euler_angle, seq):
rx, ry, rz=euler_angle
rot_x = np.array([[1, 0, 0],
[0, np.cos(rx), -np.sin(rx)],
[0, np.sin(rx), np.cos(rx)]])
rot_y = np.array([[np.cos(ry), 0, np.sin(ry)],
[0, 1, 0],
[-np.sin(ry), 0, np.cos(ry)]])
rot_z = np.array([[np.cos(rz), -np.sin(rz), 0],
[np.sin(rz), np.cos(rz), 0],
[0, 0, 1]])
# Combine rotations based on sequence
if seq == "zyx":
rot_mat = np.dot(rot_x, np.dot(rot_y, rot_z))
elif seq == "yzx":
rot_mat = np.dot(rot_x, np.dot(rot_z, rot_y))
elif seq == "zxy":
rot_mat = np.dot(rot_y, np.dot(rot_x, rot_z))
elif seq == "xzy":
rot_mat = np.dot(rot_y, np.dot(rot_z, rot_x))
elif seq == "yxz":
rot_mat = np.dot(rot_z, np.dot(rot_x, rot_y))
elif seq == "xyz":
rot_mat = np.dot(rot_z, np.dot(rot_y, rot_x))
else:
raise ValueError("Euler angle sequence string is wrong.")
return rot_mat
# process calibrator.process(calibrateImages, robotPoses)
def process(self, imgs, worldPoses,isEyeToHand=True):
if isinstance(imgs, str):
images=[]
imgs = [os.path.join(imgs, tmp) for tmp in os.listdir(imgs)]
print(imgs)
for fname in imgs:
img = cv2.imread(fname)
images.append(img)
else:
images=imgs
if isinstance(worldPoses, str):
# worldPoses = np.loadtxt('../data1/robotTcpPos.txt', delimiter=',')
worldPoses = np.loadtxt(worldPoses, delimiter=',')
objectPoints, imagePoints, mtx, dist = self.calibCamera(images, self.boardWidth,
self.boardHeight, self.squareSize,
self.criteria, self.ShowCorners)
R_target2camera_list, T_target2camera_list = self.get_RT_from_chessboard(imagePoints,objectPoints, mtx,dist, Testing=False)
R_gripper2base_list = []
T_gripper2base_list = []
for worldPos in worldPoses:
Matrix_gripper2base = self.attitudeVectorToMatrix(np.array(worldPos), False, "xyz") # R_gripper2base, T_gripper2base
if isEyeToHand:
Matrix_gripper2base=np.linalg.inv(Matrix_gripper2base)
R_gripper2base=Matrix_gripper2base[:3, :3]
T_gripper2base=Matrix_gripper2base[:3,3].reshape((3, 1))
R_gripper2base_list.append(R_gripper2base)
T_gripper2base_list.append(T_gripper2base)
print("T_gripper2base_list: ",np.array(T_gripper2base_list).shape)
print("T_target2camera_list: ", np.array(T_target2camera_list).shape)
R_camera2base, T_camera2base = cv2.calibrateHandEye(R_gripper2base_list, T_gripper2base_list,
R_target2camera_list, T_target2camera_list)
RT_camera2base = np.column_stack((R_camera2base, T_camera2base))
RT_camera2base = np.row_stack((RT_camera2base, np.array([0, 0, 0, 1])))
print(RT_camera2base)
self.SaveCalibResult(mtx, dist, R_camera2base, T_camera2base) # save params to json
self.CalculateExtrinsicEyeToHandRms(worldPoses,RT_camera2base,R_target2camera_list,T_target2camera_list)
return RT_camera2base,R_camera2base, T_camera2base, R_gripper2base_list, T_gripper2base_list, R_target2camera_list, T_target2camera_list
def rotation_matrix_to_eulerAngles(self,R):
sy = np.sqrt(R[0, 0] * R[0, 0] + R[1, 0] * R[1, 0])
singular = sy < 1e-6
if not singular:
x = np.arctan2(R[2, 1], R[2, 2])
y = np.arctan2(-R[2, 0], sy)
z = np.arctan2(R[1, 0], R[0, 0])
else:
x = np.arctan2(-R[1, 2], R[1, 1])
y = np.arctan2(-R[2, 0], sy)
z = 0
return np.array([x, y, z])
def homogeneous_matrix_to_pose(self,world_pos):
"""Convert a homogeneous transformation matrix to a RobotPose-like dictionary."""
# Extract translation (T)
T = world_pos[:3, 3]
# Extract rotation matrix (R)
R = world_pos[:3, :3] # Assuming a typo in the original code, should be full 3x3 or clarify intent
# Convert rotation matrix to Euler angles
euler_angles_degrees=self.rotation_matrix_to_eulerAngles(R)
# Pack into a dictionary similar to RobotPose
ret_pose = {
'X': round(T[0],3),
'Y': round(T[1],3),
'Z': round(T[2],3),
'Rx': round(euler_angles_degrees[0],3),
'Ry': round(euler_angles_degrees[1],3),
'Rz': round(euler_angles_degrees[2],3),
}
return ret_pose
def CalculateExtrinsicEyeToHandRms(self,worldPoses,RT_camera2base,R_target2camera_list,T_target2camera_list):
RT_target2camera=[]
for i in range(len(R_target2camera_list)):
tmp=np.column_stack((R_target2camera_list[i], T_target2camera_list[i]))
tmp=np.row_stack((tmp, np.array([0, 0, 0, 1])))
RT_target2camera.append(tmp)
poses = []
for i in range(len(RT_target2camera)):
worldPos= np.dot(RT_camera2base,RT_target2camera[i])
pose = self.homogeneous_matrix_to_pose(worldPos)
print(f"{i + 1}: {pose['X']}, {pose['Y']}, {pose['Z']}")
poses.append(pose)
rms_values = []
for i, (pose_calib, pose_actual) in enumerate(zip(poses, worldPoses)):
print("pos num: ",i)
print("pose_calib : ",pose_calib)
print("pose_actual: ",pose_actual)
xx = abs(pose_calib['X'] - pose_actual[0])
yy = abs(pose_calib['Y'] - pose_actual[1])
zz = abs(pose_calib['Z'] - pose_actual[2])
dRms = sqrt(xx ** 2 + yy ** 2 + zz ** 2)
rms_values.append(dRms)
print(f"{i + 1}: {dRms}")
dRmsMax = max(rms_values)
dRmsMin = min(rms_values)
extrinsicRms = (dRmsMax + dRmsMin) / 2
print(f"CalibrationTool|Eye To Hand Rms: {extrinsicRms}")
def check_result(self, R_cg, T_cg, R_gb, T_gb, R_tc, T_tc):
for i in range(len(R_gb)):
RT_gripper2base = np.column_stack((R_gb[i], T_gb[i]))
RT_gripper2base = np.row_stack((RT_gripper2base, np.array([0, 0, 0, 1])))
print("RT_gripper2base: ",RT_gripper2base)
RT_camera2gripper = np.column_stack((R_cg, T_cg))
RT_camera2gripper = np.row_stack((RT_camera2gripper, np.array([0, 0, 0, 1])))
print("RT_camera_to_gripper: ",RT_camera2gripper)
RT_target2camera = np.column_stack((R_tc[i], T_tc[i]))
RT_target2camera = np.row_stack((RT_target2camera, np.array([0, 0, 0, 1])))
print("RT_target_to_camera: ",RT_target2camera)
RT_target2base = RT_gripper2base @ RT_camera2gripper @ RT_target2camera
RT_target2base = np.linalg.inv(RT_target2base)
print(RT_target2base)
print('')
def SaveCalibResult(self,mtx,dist,R_camera2base, T_camera2base):
print("CameraMatrix:",mtx)
print("CameraDistCoeffs: ",dist)
print("RotationMat: ",R_camera2base)
print("TranslationMat: ",T_camera2base)
calibrateCameraResult=dict()
calibrateCameraResult["CameraMatrix"]=mtx.tolist()
calibrateCameraResult["CameraDistCoeffs"] = dist.tolist()
calibrateCameraResult["RotationMat"] = R_camera2base.tolist()
calibrateCameraResult["TranslationMat"] = T_camera2base.tolist()
try:
with open("./conf/CalibParams-k1.json", "w") as f:
f.write(json.dumps(calibrateCameraResult, indent=4, ensure_ascii=False))
print("【SAVE SUCCESS...】")
except:
print("【SAVE FAILURE...】")
if __name__ == "__main__":
calibrator = Calibration(9, 7, 0.001)
worldPos=[]
for i in range(9):
tmp=[random.randint(-300,300),random.randint(-300,300),random.randint(-300,300),random.randint(-180,180),random.randint(-180,180),random.randint(-180,180)]
worldPos.append(tmp)
print(worldPos)
calibrator.process('./data/pic',worldPos)
6. 标定精度评估
程序通过计算重投影误差来评估标定精度:
def CalculateExtrinsicEyeToHandRms(self,worldPoses,RT_camera2base,R_target2camera_list,T_target2camera_list):
# 计算每个位姿的RMS误差
for i, (pose_calib, pose_actual) in enumerate(zip(poses, worldPoses)):
xx = abs(pose_calib['X'] - pose_actual[0])
yy = abs(pose_calib['Y'] - pose_actual[1])
zz = abs(pose_calib['Z'] - pose_actual[2])
dRms = sqrt(xx ** 2 + yy ** 2 + zz ** 2)
7. 使用流程
- 准备阶段:放置棋盘格标定板,确保相机和机器人都能看到
- 数据采集:按’k’键采集多组数据(建议15-20组),每次改变机器人位姿和标定板位置
- 开始标定:按’p’键执行标定算法
- 结果保存:标定结果保存到
./conf/CalibParams.json
8. 关键优势
- 手动控制:用户可以精确控制数据采集时机
- 实时验证:每次采集都验证角点检测是否成功
- 灵活性强:可以随时调整标定板位置和机器人姿态
- 精度可控:通过RMS误差评估标定质量
这种手动标定方法虽然需要人工干预,但能够获得高质量的标定数据,特别适用于对精度要求较高的工业应用场景。
八、 LUMI 大模型分拣机器人应用
项目简介
本项目基于视觉大模型与机器人集成,面向多站点分拣、自动标定、智能检测与抓取等场景。支持多站点任务调度、手眼标定、视觉识别与抓取、AGV联动等功能。
目录结构
multi_station_demo.py多站点分拣主控脚本visualDetect_ali.py视觉识别与抓取主流程visualValidCalib.py标定结果验证与像素-世界坐标映射AutoCalibProccess.py手动手眼标定采集与计算utilfs/机器人与工具函数库conf/配置文件(机器人参数、标定参数、站点配置等)requirements.txt依赖环境JAKA_SDK_LINUX/JAKA机器人SDK(需配置环境变量)images/检测结果与采集图片保存目录
环境配置
-
依赖安装
pip install -r requirements.txt- 依赖主要包括:
opencv-python,numpy,matplotlib,dashscope等。
- 依赖主要包括:
-
Orbbec相机SDK
- 推荐使用 pyorbbecsdk 或本项目自带的
OrbbecSDK目录。 - 确保相机驱动和SDK已正确安装。
- 推荐使用 pyorbbecsdk 或本项目自带的
-
JAKA机器人SDK
- 将
JAKA_SDK_LINUX路径加入环境变量:export LD_LIBRARY_PATH=/path/to/JAKA_SDK_LINUX:$LD_LIBRARY_PATH
- 将
配置文件说明
conf/userCmdControl.json
- cameraParams:相机对齐、同步、图片保存路径
- objects:分拣目标与放置目标名称
- operationMode:操作模式(
both/grasp_only/put_only/grasp_priority) - robotParams:机器人初始位姿、抓取/放置偏移、抬升高度等
- calibrateParams:标定板参数、机器人IP、标定图片保存路径
- genNearPointParams:像素点深度搜索参数
- systemConfig:机器人、AGV、外部轴等系统IP与端口
- stations:多站点配置(站点名、AGV标记、机器人/外部轴初始位、站点操作模式)
conf/CalibParams-lumi-hand.json
- 相机内参、畸变、旋转、平移矩阵(标定结果)
主要功能与脚本
1. 多站点分拣任务(multi_station_demo.py)
- 支持多站点自动调度,AGV移动、机器人抓取/放置、视觉检测一体化。
- 站点配置、操作模式均可在
userCmdControl.json中灵活设定。 - 运行方式:
python multi_station_demo.py
#!/usr/bin/env python3
# coding:UTF-8
'''
多站点任务示例脚本
演示如何使用JAKAIntegrated类在多个站点之间移动并执行检测抓取任务
'''
import os
import time
import sys
import json
# 导入集成控制类
from utilfs.jaka_integrated import JAKAIntegrated
# 导入检测抓取模块
import visualDetect_ali
# 从配置文件加载站点配置
def load_stations():
"""从配置文件加载站点配置"""
try:
with open('./conf/userCmdControl.json', 'r') as f:
user_config = json.load(f)
if "stations" in user_config:
print("成功从配置文件加载站点信息")
return user_config["stations"]
else:
print("警告: 配置文件中没有站点信息,请先配置站点")
return {}
except Exception as e:
print(f"加载站点配置失败: {e}")
return {}
def load_config():
"""加载系统配置"""
try:
with open('./conf/userCmdControl.json', 'r') as f:
user_config = json.load(f)
# 从userCmdControl.json的systemConfig部分获取系统配置
if "systemConfig" in user_config:
return user_config["systemConfig"]
else:
print("警告: userCmdControl.json中没有systemConfig部分,使用默认配置")
# return {
# "robot_ip": "192.168.10.90",
# "ext_base_url": "http://192.168.10.100",
# "agv_ip": "192.168.10.10",
# "agv_port": 31001
# }
except Exception as e:
print(f"加载配置文件失败: {e}")
# return {
# "robot_ip": "192.168.10.90",
# "ext_base_url": "http://192.168.10.100",
# "agv_ip": "192.168.10.10",
# "agv_port": 31001
# }
def update_operation_mode(station_config):
"""更新操作模式到配置文件"""
try:
with open('./conf/userCmdControl.json', 'r') as f:
user_cmd_config = json.load(f)
# 更新操作模式
user_cmd_config["operationMode"] = station_config["operation_mode"]
with open('./conf/userCmdControl.json', 'w') as f:
json.dump(user_cmd_config, f, indent=4)
print(f"已更新操作模式为: {station_config['operation_mode']}")
except Exception as e:
print(f"更新操作模式失败: {e}")
def execute_task_at_station(control, station_id, station_config):
"""
在指定站点执行任务
:param control: JAKAIntegrated控制实例
:param station_id: 站点ID
:param station_config: 站点配置信息
"""
print(f"准备在 {station_config['name']} 执行任务...")
# 1. 移动到站点
if not control.move_to_station(station_config['name'], station_config['agv_marker']):
print(f"移动到 {station_config['name']} 失败,跳过此站点任务")
return False
# 2. 设置机器人和外部轴到初始位
if control.ext_base_url:
# 尝试移动外部轴,如果超出限制则会在方法内部打印错误
ext_result = control.ext_moveto(station_config['ext_home_pos'])
if not ext_result:
print(f"警告: 外部轴移动失败,但将继续执行任务")
control.rob_moveto(station_config['robot_home_pos'])
# 检查操作模式,如果是"none"则跳过后续操作
operation_mode = station_config.get('operation_mode')
if operation_mode == 'none':
print(f"站点 {station_config['name']} 的操作模式为'none',仅执行移动操作,不执行检测和抓取")
print(f"在 {station_config['name']} 的移动任务执行完成")
return True
if operation_mode == 'put_cola':
print(f"站点 {station_config['name']} 的操作模式为'put_only',仅执行移动操作,不执行检测和抓取")
# control.rob_moveto([292,26,98,-24,58,-102])
control.rob_moveto([279,60,79,-40,-2,-102],50) #1
control.rob_moveto([263,68,65,-40,-10,-102],50) #2
time.sleep(2)
control.grab_action(0)
time.sleep(1)
control.rob_moveto([273,68,65,16,-8,-151],50)
control.rob_moveto([292,26,98,-24,58,-102],50)
time.sleep(1)
return True
# 3. 更新操作模式
update_operation_mode(station_config)
# 4. 执行视觉检测和抓取
try:
# 这里我们通过修改系统路径并导入visualDetect_ali模块来执行任务
# 注意:我们假设visualDetect_ali.py已经被修改为可以作为模块导入
print(f"开始执行视觉检测和抓取任务,操作模式: {operation_mode}")
# 调用visualDetect_ali.py的主函数
# 这里假设已经修改visualDetect_ali.py为可导入模块
# 实际使用时可能需要根据具体情况调整
visualDetect_ali.run_detection(robot=control, auto_execute=True)
print(f"在 {station_config['name']} 的任务执行完成")
return True
except Exception as e:
print(f"执行任务时出错: {e}")
return False
def main():
"""主函数"""
print("=== 多站点任务系统 ===")
# 加载系统配置
config = load_config()
# 加载站点配置
stations = load_stations()
if not stations:
print("没有可用的站点配置,程序退出")
return
# 创建集成控制实例
control = JAKAIntegrated(
robot_ip=config["robot_ip"],
ext_base_url=config.get("ext_base_url"),
agv_ip=config.get("agv_ip"),
agv_port=config.get("agv_port")
)
# 初始化系统
if not control.setup_system():
print("系统初始化失败,程序退出")
return
try:
# 按顺序执行各站点任务
for station_id, station_config in stations.items():
print(f"\n===== 开始 {station_config['name']} 任务 =====")
execute_task_at_station(control, station_id, station_config)
print(f"===== 完成 {station_config['name']} 任务 =====\n")
# 任务间暂停
time.sleep(2)
except KeyboardInterrupt:
print("\n用户中断程序")
except Exception as e:
print(f"程序执行过程中发生错误: {e}")
finally:
# # 关闭系统
# control.shutdown_system()
print("程序已退出")
if __name__ == "__main__":
time.sleep(3)
main()
2. 视觉检测与抓取(visualDetect_ali.py)
- 支持自动/手动两种模式,自动识别目标物体与放置点,自动完成抓取与放置动作。
- 支持命令行参数:
--auto自动执行(不等待人工确认)--camera-sn指定相机序列号--list-cameras列出所有可用相机
- 运行方式:
python visualDetect_ali.py
源代码如下:
import time
import cv2
from OrbbecSDK.orbbecCamera import Camera
from utilfs.jaka import *
from utilfs.tools import loadJsonFile, saveOriginImg, generatorNearPoints, pixel_to_world,vl_ali
step_flag = None # -1:catch 1:put
IO_TOOL = 1 # Grab IO
PI=3.1415926
def kine_caculate(robot, ref_pos,base_loc,world_loc,mapJsonData,step_type):
base2objup_pos=None
objup2obj_pos =None
grasp_flag =None
mv_type = -1
grip_loc = tuple(world_loc.tolist() + list(base_loc[3:])) # A
# obj cartesian_pose
grip_loc = list(grip_loc)
grip_loc[0] += mapJsonData["robotParams"]["RelativeOffset-X"]
grip_loc[1] += mapJsonData["robotParams"]["RelativeOffset-Y"]
if step_type == -1:
# catch
grip_loc[2] += mapJsonData["robotParams"]["RelativeOffset-Z"]
elif step_type == 1:
# put
grip_loc[2] += mapJsonData["robotParams"]["RelativeOffset-Zput"]
# obj-up cartesian_pose
grip_loc_up = grip_loc[:]
grip_loc_up[2] = grip_loc_up[2] + mapJsonData["robotParams"]["relativeUpMotionHeight"]
grip_loc = tuple(grip_loc)
grip_loc_up = tuple(grip_loc_up)
# base 2 obj
# Check which method to use based on what's available in the robot object
if hasattr(robot, 'kine_inverse_origin'):
base2obj_pos = robot.kine_inverse_origin(ref_pos, grip_loc)
else:
base2obj_pos = robot.kine_inverse(ref_pos, grip_loc)
# base 2 obj-up
if hasattr(robot, 'kine_inverse_origin'):
base2objup_pos = robot.kine_inverse_origin(ref_pos, grip_loc_up)
else:
base2objup_pos = robot.kine_inverse(ref_pos, grip_loc_up)
# if base2obj-up faluire, turn to base2a
if base2objup_pos[0]!=0:
grasp_flag= base2obj_pos[0]
mv_type = 1
# if base2obj-up success, turn to obj-up2obj
elif base2objup_pos[0]==0:
if hasattr(robot, 'kine_inverse_origin'):
objup2obj_pos = robot.kine_inverse_origin(base2objup_pos[1], grip_loc)
else:
objup2obj_pos = robot.kine_inverse(base2objup_pos[1], grip_loc)
if objup2obj_pos[0]==0:
grasp_flag= objup2obj_pos[0]
mv_type = 2
else:
grasp_flag = base2obj_pos[0]
mv_type = 1
return mv_type,grip_loc,grip_loc_up,base2obj_pos,base2objup_pos,objup2obj_pos,grasp_flag
def jointMove(robot, mv_type,base2obj_pos,base2objup_pos,objup2obj_pos,grab_status):
# base move 2 obj-up 2 obj
if mv_type == 2: # base move 2 obj-up
# Check which method to use based on what's available in the robot object
if hasattr(robot, 'joint_move_origin'):
ret_base2objup = robot.joint_move_origin(base2objup_pos[1], 1, 0)
else:
ret_base2objup = robot.joint_move(joint_pos=base2objup_pos[1], move_mode=0, is_block=True, speed=30)
if ret_base2objup == 0 or (isinstance(ret_base2objup, tuple) and ret_base2objup[0] == 0):
time.sleep(1)
if hasattr(robot, 'joint_move_origin'):
ret_move2obj = robot.joint_move_origin(objup2obj_pos[1], 1, 0)
else:
ret_move2obj = robot.joint_move(joint_pos=objup2obj_pos[1], move_mode=0, is_block=True, speed=30)
if ret_move2obj == 0 or (isinstance(ret_move2obj, tuple) and ret_move2obj[0] == 0):
robot.grab_action(grab_status)
time.sleep(3)
if hasattr(robot, 'joint_move_origin'):
moveRet = robot.joint_move_origin(base2objup_pos[1], 1, 0)
else:
moveRet = robot.joint_move(joint_pos=base2objup_pos[1], move_mode=0, is_block=True, speed=30)
if moveRet == 0 or (isinstance(moveRet, tuple) and moveRet[0] == 0):
print("obj move 2 obj-up success")
else:
print("obj move 2 obj-up failure")
time.sleep(1)
else:
print("obj-up move 2 obj failure")
else:
print("base move 2 obj-up failure")
# base 2 obj
if mv_type == 1:
if hasattr(robot, 'joint_move_origin'):
ret_move2obj = robot.joint_move_origin(base2obj_pos[1], 1, 0)
else:
ret_move2obj = robot.joint_move(joint_pos=base2obj_pos[1], move_mode=0, is_block=True, speed=30)
if ret_move2obj == 0 or (isinstance(ret_move2obj, tuple) and ret_move2obj[0] == 0):
time.sleep(1)
robot.grab_action(grab_status)
time.sleep(3)
print('next: obj move 2 put-up')
else:
print("base move 2 obj failure")
return
def show_unreachable_warning(image, status_text, auto_execute=False):
"""显示不可达警告窗口"""
print('Warning: Position unreachable!')
print(f"STATUS: {status_text}")
# 如果不是自动执行模式,显示窗口等待用户确认
if not auto_execute:
# 在显示窗口中添加状态文本
cv2.putText(image, f"STATUS: {status_text}", (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)
cv2.namedWindow("Object Detection - UNREACHABLE", cv2.WINDOW_NORMAL)
cv2.imshow("Object Detection - UNREACHABLE", image)
print("Press any key to continue...")
cv2.waitKey(0) # 等待任意按键
cv2.destroyAllWindows()
print('Continuing to next detection cycle...')
def run_detection(robot=None, auto_execute=False, camera_serial_number=None):
"""
运行视觉检测和抓取任务
:param robot: 可选,JAKA机器人控制对象。如果提供,将使用此对象而不是创建新对象
:param auto_execute: 是否自动执行机器人动作,不等待用户点击图像。True表示自动执行,False表示等待用户确认
:param camera_serial_number: 可选,相机的序列号,用于指定使用特定的相机
"""
mapJsonData = loadJsonFile('./conf/userCmdControl.json')
calibParams = loadJsonFile('./conf/CalibParams-lumi-hand.json')
# 使用传入的机器人控制对象或创建新的
if robot is None:
robot = JAKA(mapJsonData["calibrateParams"]["robotIP"], connect=True)
robot._login()
# robot move to basepose
base_loc = mapJsonData["robotParams"]["basePose"]
print("base_loc: ",base_loc)
# 检查是否有joint_move_origin方法,没有则使用joint_move
if hasattr(robot, 'joint_move_origin'):
robot.joint_move_origin(base_loc, 1, 0)
else:
robot.joint_move(joint_pos=base_loc, move_mode=0, is_block=True, speed=30)
# open grab
robot.grab_action(0)
time.sleep(2)
mv_obj = mapJsonData["objects"]["moveObjects"]
put_obj = mapJsonData["objects"]["putObject"]
# 根据操作模式确定需要检测的物体
if "operationMode" not in mapJsonData:
operation_mode = "both" # 默认模式:抓取和放置都必须可达
else:
operation_mode = mapJsonData["operationMode"]
# 显示当前操作模式
print(f"当前操作模式: {operation_mode}")
print("可选模式: 'both'(抓取和放置都必须可达), 'grasp_only'(仅执行抓取), 'put_only'(仅执行放置), 'grasp_priority'(优先抓取,不要求放置可达)")
# 根据操作模式确定需要检测的物体
if operation_mode == "grasp_only":
tags = [mv_obj] # 只检测抓取物体
print(f"仅抓取模式:只检测 '{mv_obj}'")
elif operation_mode == "put_only":
tags = [put_obj] # 只检测放置位置
print(f"仅放置模式:只检测 '{put_obj}'")
else:
tags = [mv_obj, put_obj] # 检测两种物体
print(f"检测所有物体: '{mv_obj}' 和 '{put_obj}'")
detect_continue = True # Repeated detection and grabbing
# 如果指定了相机序列号,先列出所有相机
if camera_serial_number:
# 临时创建一个相机对象以列出所有相机
try:
temp_cam = Camera()
devices = temp_cam.list_connected_devices()
temp_cam.close()
print("\n可用的Orbbec相机:")
for device in devices:
print(f"索引: {device['index']}, 名称: {device['name']}, 序列号: {device['serial_number']}")
# 检查指定的序列号是否存在
sn_exists = any(device['serial_number'] == camera_serial_number for device in devices)
if not sn_exists and devices:
print(f"警告: 未找到序列号为 {camera_serial_number} 的相机,将使用默认相机")
except Exception as e:
print(f"列出相机时出错: {e}")
print("将尝试直接使用指定的相机序列号")
while detect_continue:
mv_objs = [] # Allow multiple similar items
put_objs = [] # Only one target location.
mv_centers, put_center = [],[]
# 尝试获取相机图像,处理可能的错误
try:
# Get image
cam = Camera(serial_number=camera_serial_number)
color_img, depth_data, _ = cam.getColorDepthData()
cam.close()
# 检查获取的图像是否有效
if color_img is None or len(color_img) == 0 or depth_data is None or len(depth_data) == 0:
print("无法获取有效的相机图像,跳过此次检测")
time.sleep(1) # 等待一秒再试
continue
# Save originimg
img_path = saveOriginImg(color_img, mapJsonData["cameraParams"]["saveImgPath"])
# Objects Detection
obj_labels, obj_locs = vl_ali(tags, img_path)
except Exception as e:
print(f"获取相机数据时出错: {e}")
print("等待1秒后重试...")
time.sleep(1)
continue
if len(obj_labels) == 0 or len(obj_locs) == 0:
print("未检测到任何物体,继续下一次检测...")
continue
if len(obj_labels) != len(obj_locs):
if put_obj not in obj_labels:
black_name = len(obj_locs) - len(obj_labels)
for i in range(black_name - 1):
obj_labels.append(obj_labels[0])
obj_labels.append(put_obj)
else:
obj_labels = [mv_obj for _ in range(len(obj_locs) - 1)]
obj_labels.append(put_obj)
for i in range(len(obj_labels)):
# print('objPos:',objPos)
center_x = (int(obj_locs[i][0]) + int(obj_locs[i][2])) / 2
center_y = (int(obj_locs[i][1]) + int(obj_locs[i][3])) / 2
if obj_labels[i]==mv_obj:
mv_objs.append(obj_locs[i])
mv_centers.append([int(center_x), int(center_y)])
if obj_labels[i]==put_obj:
put_objs.append(obj_locs[i])
put_center.append([int(center_x), int(center_y)])
print("mv_objs,mv_centers: ",mv_objs,mv_centers)
print("put_objs,put_center: ",put_objs,put_center)
# 检查是否检测到了必要的物体
if len(mv_objs) == 0 and operation_mode != "put_only":
print(f"未检测到移动物体({mv_obj}),继续下一次检测...")
continue
if len(put_objs) == 0 and operation_mode != "grasp_only":
print(f"未检测到放置位置({put_obj}),继续下一次检测...")
continue
# 处理移动物体 - 只在非仅放置模式下处理
grasp_flag = 0 # 默认可达
if operation_mode != "put_only":
for i in range(len(mv_objs)):
cur_obj_pos = mv_objs[i]
cur_center_pos = mv_centers[i]
cv2.rectangle(color_img, (cur_obj_pos[0], cur_obj_pos[1]),
(cur_obj_pos[2], cur_obj_pos[3]), (0, 0, 255), 2)
mv_obj_depth = depth_data[cur_center_pos[1], cur_center_pos[0]]
# Current point gets depth of 0, search for the depth of the surrounding point
if int(mv_obj_depth) == 0:
gen_center_points = generatorNearPoints(put_center,
mapJsonData["genNearPointParams"][
"nearPointInterval"],
mapJsonData["genNearPointParams"][
"nearPointTimes"])
for i, point in enumerate(gen_center_points):
# 修复点的索引方式,确保正确访问点的坐标
try:
# 如果point是嵌套列表
mv_obj_depth = depth_data[point[0][1], point[0][0]]
except (TypeError, IndexError):
# 如果point是单个坐标点
mv_obj_depth = depth_data[point[1], point[0]]
if int(mv_obj_depth) != 0 or i == len(gen_center_points):
break
print("【{} depth is: {} (mm)】".format(mv_obj,mv_obj_depth))
obj_world_loc = pixel_to_world(cur_center_pos, mv_obj_depth, calibParams["CameraMatrix"],
calibParams["RotationMat"],
calibParams["TranslationMat"])
# Display coordinates on image
text_pixel = f"Pixel: ({cur_center_pos[0]}, {cur_center_pos[1]})"
text_world = f"World: ({obj_world_loc[0]:.2f}, {obj_world_loc[1]:.2f}, {obj_world_loc[2]:.2f})"
cv2.putText(color_img, text_pixel, (cur_obj_pos[0], cur_obj_pos[1]-30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.putText(color_img, text_world, (cur_obj_pos[0], cur_obj_pos[1]-10), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
ref_pos = robot.getjoints()
base_loc= robot.get_tcp_pos()
print('Calculate whether the position of the item to be captured is reachable')
mv_type,grip_loc,grip_up_loc,base2obj_pos,base2objup_pos,objup2obj_pos,grasp_flag = kine_caculate(robot, ref_pos,base_loc,obj_world_loc,mapJsonData,step_type=-1)
else:
# 在仅放置模式下,设置默认值以便程序正常运行
ref_pos = robot.getjoints()
base_loc = robot.get_tcp_pos()
mv_type = 1 # 设置默认移动类型
grip_up_loc = base_loc # 使用当前位置
base2obj_pos = [0, base_loc] # 假设可达
base2objup_pos = [0, base_loc]
objup2obj_pos = [0, base_loc]
# 处理放置物体 - 只在非仅抓取模式下处理
put_flag = 0 # 默认可达
if operation_mode != "grasp_only" and len(put_objs) > 0:
put_obj_depth = depth_data[put_center[0][1], put_center[0][0]]
put_obj_pos = put_objs[0]
put_center = put_center[0]
cv2.rectangle(color_img, (put_obj_pos[0], put_obj_pos[1]),
(put_obj_pos[2], put_obj_pos[3]), (0, 0, 255), 2)
if int(put_obj_depth) == 0:
gen_center_points=generatorNearPoints(put_center,mapJsonData["genNearPointParams"]["nearPointInterval"],mapJsonData["genNearPointParams"]["nearPointTimes"])
for i,point in enumerate(gen_center_points):
# 修复点的索引方式,确保正确访问点的坐标
try:
# 如果point是嵌套列表
put_obj_depth = depth_data[point[0][1], point[0][0]]
except (TypeError, IndexError):
# 如果point是单个坐标点
put_obj_depth = depth_data[point[1], point[0]]
if int(put_obj_depth) != 0 or i==len(gen_center_points):
break
print("【{} depth is: {} (mm)】".format(put_obj,put_obj_depth))
put_world_loc = pixel_to_world(put_center, put_obj_depth, calibParams["CameraMatrix"],
calibParams["RotationMat"],
calibParams["TranslationMat"])
# Display put object coordinates on image
text_pixel = f"Pixel: ({put_center[0]}, {put_center[1]})"
text_world = f"World: ({put_world_loc[0]:.2f}, {put_world_loc[1]:.2f}, {put_world_loc[2]:.2f})"
cv2.putText(color_img, text_pixel, (put_obj_pos[0], put_obj_pos[1]-30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 0, 0), 2)
cv2.putText(color_img, text_world, (put_obj_pos[0], put_obj_pos[1]-10), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 0, 0), 2)
# 计算放置位置可达性
print('Calculate whether the location of the item to be placed is reachable')
if mv_type == 2:
ref_pos_d = base2objup_pos[1]
elif mv_type == 1:
ref_pos_d = base2obj_pos[1]
put_type,put_loc,put_loc_up,objup2put_pos,objup2putup_pos,putup2put_pos,put_flag = kine_caculate(robot, ref_pos_d,grip_up_loc,put_world_loc,mapJsonData,step_type=1)
else:
# 在仅抓取模式下,设置默认值
put_type = 1
put_loc = base_loc
put_loc_up = base_loc
objup2put_pos = [0, base_loc]
objup2putup_pos = [0, base_loc]
putup2put_pos = [0, base_loc]
# Display detection results in window
cv2.namedWindow("Object Detection", cv2.WINDOW_NORMAL)
cv2.imshow("Object Detection", color_img)
# 根据auto_execute参数决定是否等待用户点击
if not auto_execute:
print("Press any key to continue with robot movement...")
cv2.waitKey(0) # Wait for any key press
else:
print("Auto executing robot movement...")
cv2.waitKey(1) # Just refresh the window without waiting
# 保存检测结果图片
cv2.imwrite(img_path,color_img)
# 根据操作模式判断是否执行机器人动作
execute_grasp = False
execute_put = False
# 检查各种操作模式并决定执行哪些操作
if operation_mode == "both":
# 抓取和放置都必须可达
if grasp_flag == 0 and put_flag == 0:
execute_grasp = True
execute_put = True
else:
status_message = "不可达: "
if grasp_flag != 0: status_message += "抓取位置 "
if put_flag != 0: status_message += "放置位置"
show_unreachable_warning(color_img, status_message, auto_execute)
continue
elif operation_mode == "grasp_only":
# 只执行抓取,不执行放置
if grasp_flag == 0:
execute_grasp = True
else:
show_unreachable_warning(color_img, "抓取位置不可达", auto_execute)
continue
elif operation_mode == "put_only":
# 只执行放置(假设物体已被抓取)
if put_flag == 0:
execute_put = True
else:
show_unreachable_warning(color_img, "放置位置不可达", auto_execute)
continue
elif operation_mode == "grasp_priority":
# 只要抓取可达就执行,不管放置是否可达
if grasp_flag == 0:
execute_grasp = True
# 如果放置也可达,则执行放置
execute_put = (put_flag == 0)
else:
show_unreachable_warning(color_img, "抓取位置不可达", auto_execute)
continue
# 执行抓取操作
if execute_grasp:
print('---开始抓取---')
jointMove(robot, mv_type, base2obj_pos, base2objup_pos, objup2obj_pos, grab_status=1)
# 执行放置操作
if execute_put:
print('---开始放置---')
jointMove(robot, mv_type, objup2put_pos, objup2putup_pos, putup2put_pos, grab_status=0)
# 移动到基准位置
if hasattr(robot, 'joint_move_origin'):
robot.joint_move_origin(base_loc, 1, 0)
else:
robot.joint_move(joint_pos=base_loc, move_mode=0, is_block=True, speed=30)
# robot.grab_action(0)
# Destroy all OpenCV windows
cv2.destroyAllWindows()
# 如果成功执行了动作,退出循环
if execute_grasp or execute_put:
print("动作执行完成,退出检测循环")
detect_continue = False
else:
print("准备下一次检测...")
if __name__=='__main__':
import argparse
parser = argparse.ArgumentParser(description='运行视觉检测和抓取任务')
parser.add_argument('--auto', action='store_true', help='自动执行模式,不等待用户确认')
parser.add_argument('--camera-sn', type=str, default=None, help='指定要使用的相机序列号')
parser.add_argument('--list-cameras', action='store_true', help='列出所有可用的相机')
args = parser.parse_args()
# 如果指定了--list-cameras参数,列出所有相机后退出
if args.list_cameras:
try:
print("正在搜索连接的Orbbec相机...")
temp_cam = Camera()
devices = temp_cam.list_connected_devices()
temp_cam.close()
if not devices:
print("没有找到连接的Orbbec相机")
else:
print("\n可用的Orbbec相机:")
for device in devices:
print(f"索引: {device['index']}, 名称: {device['name']}, 序列号: {device['serial_number']}")
print("\n使用方法: python visualDetect_ali.py --camera-sn <序列号>")
# 如果命令行没有指定相机序列号,则使用第一个找到的相机
if args.camera_sn is None and devices:
args.camera_sn = devices[0]["serial_number"]
print(f"\n自动选择第一个相机: {args.camera_sn}")
except Exception as e:
print(f"列出相机时出错: {e}")
import traceback
traceback.print_exc()
exit(0)
# 执行检测
try:
print(f"使用相机序列号: {args.camera_sn if args.camera_sn else '默认'}")
run_detection(auto_execute=args.auto, camera_serial_number=args.camera_sn)
except KeyboardInterrupt:
print("\n程序被用户中断")
except Exception as e:
print(f"运行过程中出错: {e}")
import traceback
traceback.print_exc()
3. 手动手眼标定(AutoCalibProccess.py)
- 按
k采集一组图片与机器人位姿,按p执行标定计算,按q退出。 - 标定结果保存在
conf/CalibParams-lumi-hand.json。
源代码:
'''
标定:眼在手外
'''
from utilfs.handToEyeCalibration import *
import cv2
from OrbbecSDK.orbbecCamera import Camera
import getch
from utilfs.jaka import *
from utilfs.tools import loadJsonFile,findCorners
PI=3.1415926
mapJsonData = loadJsonFile('./conf/userCmdControl.json')
boardRowNums=mapJsonData["calibrateParams"]["boardRowNums"]
boardCowNums = mapJsonData["calibrateParams"]["boardCowNums"]
boardLength = mapJsonData["calibrateParams"]["boardLength"]
CalibrateImageSaveDir = mapJsonData["calibrateParams"]["CalibrateImageSaveDir"]
if not os.path.exists(CalibrateImageSaveDir):
os.makedirs(CalibrateImageSaveDir)
save_path = os.path.join(CalibrateImageSaveDir, 'robotTcpPos.txt')
print('------:',save_path)
tcp = JAKA(mapJsonData["calibrateParams"]["robotIP"])
oberrecCamera = Camera()
startIndex=0
robotPoses = []
calibrateImages = []
print('--------------请按下k进行数据采集-------')
while True:
key = getch.getch() # 读取按键
keystr = key
print(keystr)
if keystr == 'k':
print("开始采集数据...")
currentTcpPos = tcp.get_tcp_pos()
print("currentTcpPos: ",currentTcpPos)
color_image = oberrecCamera.getColorImage()
print("get color_image success.")
if findCorners(color_image,boardRowNums,boardCowNums):
robotPoses.append(currentTcpPos)
calibrateImages.append(color_image)
cv2.imwrite(os.path.join(CalibrateImageSaveDir, "{:04d}.png".format(int(startIndex))), color_image)
startIndex+=1
print("本次数据采集成功")
else:
print("舍弃本次采集...")
if keystr == 'p':
print("开始标定...")
if len(calibrateImages)==len(robotPoses):
print("数据一致,开始标定")
np.savetxt(save_path,robotPoses, fmt='%f', delimiter=',')
print("位姿保存成功...")
calibrator = Calibration(boardRowNums, boardCowNums, boardLength)
calibrator.process(calibrateImages, robotPoses)
else:
print("图像和位姿数量不一致...")
if keystr == 'q':
break
4. 标定结果验证(visualValidCalib.py)
- 实时显示相机画面,点击像素点可输出其世界坐标,辅助验证标定精度。
import json
from utilfs.tools import pixel_to_world, loadJsonFile, generatorNearPoints
# from OrbbecSDK.pyorbbecsdk import *
from pyorbbecsdk import *
# from OrbbecSDK.orbbecCamera import Camera
# from pyorbbecsdk import *
from OrbbecSDK.orbbecUtils import frame_to_bgr_image
# from pyorbbecsdk.orbbecUtils import frame_to_bgr_image
# from pyorbbecsdk import *
# from orbbecUtils import frame_to_bgr_image
import cv2
import numpy as np
import sys
import time
from utilfs.jaka import *
# from utils.log import *
PI=3.1415926
ESC_KEY = 27
PRINT_INTERVAL = 1 # seconds
MIN_DEPTH = 20 # 20mm
MAX_DEPTH = 10000 # 10000mm
# TemporalFilter 类,实现一种时间滤波器。
# 时间滤波器通常用于视频处理中,用于减少图像的噪声和闪烁,提高图像的平滑性和视觉效果
# 通过将当前帧与前一帧进行混合来减少噪声和平滑图像。
class TemporalFilter:
def __init__(self, alpha):
# alpha:浮点数,表示滤波器的权重。alpha值通常在0到1间,决定当前帧与前一帧在滤波过程中的权重比例
self.alpha = alpha
# 用于存储上一帧的图像数据,初始值为 None
self.previous_frame = None
# 类的一个方法,用于处理传入的图像帧。
# frame:传入的当前帧图像。
def process(self, frame):
# None(即没有前一帧),则直接将当前帧作为结果
if self.previous_frame is None:
result = frame
else:
# 如果有前一帧,则用cv2.addWeighted函数将当前帧与前一帧进行加权平均混合。
# frame:当前帧。
# self.alpha:当前帧的权重。
# self.previous_frame:前一帧。
# 1 - self.alpha:前一帧的权重。
# 0:伽马校正参数(通常设置为 0)
result = cv2.addWeighted(frame, self.alpha, self.previous_frame, 1 - self.alpha, 0)
# 将处理后的结果存储为下一帧的前一帧。
self.previous_frame = result
# 返回处理后的图像帧。
return result
with open("/home/jam/JAKA_WORK/LUMI/upload_files/LUMI_DEMO-v1/conf/conf/Cali.json", "r") as f:
data = json.load(f)
print("CalibParams:",data)
# with open("./conf/CalibParams.json", "r") as f:
# data = json.load(f)
# print("CalibParams:",data)
# mapJsonData = loadJsonFile('./conf/userCmdControl.json')
# print(mapJsonData["calibrateParams"])
# tcp = JAKA(mapJsonData["calibrateParams"]["robotIP"])
# print('tcp:',tcp)
# # 看世界坐标系下的情况
# tcp_world = JAKA(mapJsonData["calibrateParams"]["robotIP"]) #
# tcp_world.set_user_frame_id_origin(0) # 切换到世界坐标系
# ret_world = tcp_world.get_user_frame_id_origin()
# print("初始坐标系id(ret_world)为: ", ret_world)
# # tcp.joint_move_origin([PI / 2, PI / 2, -PI / 2, PI / 2, PI / 2, PI / 2], 50, 0)
# # print(tcp.get_tcp_pos())
# # homePos=[PI / 2, PI / 2, -PI / 2, PI / 2, PI / 2, PI / 2]
def on_EVENT_LBUTTONDOWN(event, x, y, flags, param):
# 检查是否是鼠标左键点击事件
if event == cv2.EVENT_LBUTTONDOWN:
# 获取鼠标点击点的坐标,并从深度数据中获取该点的深度值。
xy = "%d,%d" % (x, y)
depth = depth_data[y, x]
# depth = depth_data[x, y]
print(xy,depth)
# 如果点击点的深度为0(可能表示没有检测到物体),则生成一些附近的点。
if int(depth) == 0:
genCenterPoints = generatorNearPoints([x,y],1,4) # 试着修改参数看效果
# genCenterPoints = generatorNearPoints([x,y],mapJsonData["genNearPointParams"]["nearPointInterval"],mapJsonData["genNearPointParams"]["nearPointTimes"]) # 没有调用传入参数
# 根据附近点获取深度 (遍历生成的附近点,获取第一个非0的深度值。)
for i, centerPoint in enumerate(genCenterPoints):
depth = depth_data[centerPoint[0][1], centerPoint[0][0]]
# depth = depth_data[centerPoint[0][0], centerPoint[0][1]]
if int(depth) != 0 or i == len(genCenterPoints):
break
# 将像素坐标转换为世界坐标系中的坐标。
worldPos=pixel_to_world([x,y],depth, data["CameraMatrix"], data["RotationMat"], data["TranslationMat"])
print("worldPos: ",worldPos)
# # 获取机器人工具中心点的当前位置。
# tcpPos = tcp.get_tcp_pos()
# print("tcpPos: ",tcpPos)
# end_tcpPos = tcpPos[3:]
# print('end_tcpPos:',end_tcpPos)
# # 计算目标TCP位置,通常在Z轴方向上增加一定的距离(这里为150mm)。
# tmpTcpPos = worldPos.tolist() + tcpPos[3:]
# tmpTcpPos[2]=tmpTcpPos[2] # +100
# print("tmpTcpPos: ",tmpTcpPos)
# # 获取机器人当前的关节位置。
# ref_pos = tcp.getjoints()
# print("ref_pos: ",ref_pos)
# # 使用逆向运动学计算从当前关节位置到目标TCP位置的关节运动。
# ret = tcp.kine_inverse7_origin(ref_pos, tmpTcpPos)
# print("ret: ",ret)
# ret_5kine = ref_pos[4]
# end_ret = (ret[0], ret[1][:4] + (ret_5kine,) + ret[1][5:])
# print('end_ret:',end_ret)
# # logger.info(f"end_ret: {end_ret}")
# # 移动机器人
# # 如果逆向运动学计算成功,则控制机器人移动到计算出的关节位置;否则,输出失败信息。
# if ret[0] == 0:
# print('OK')
# # moveRet=tcp.joint_move7_origin(end_ret[1], 0.5, 0) # 10
# # if moveRet==0:
# # print("机器人移动成功")
# # else:
# # print("机器人移动失败")
# else:
# print("【机器人逆解失败...】")
# 在图像上绘制点击点,并显示图像。
cv2.circle(color_image, (x, y), 1, (255, 0, 0), thickness = -1)
cv2.putText(color_image, xy, (x, y), cv2.FONT_HERSHEY_PLAIN,
2.0, (255,0,0), thickness = 2)
cv2.imshow("image", color_image)
if __name__ == "__main__":
# log_directory = "./Log" # 修改为你希望保存日志的目录路径
# logger = setup_logging(log_directory,'AutoCalibProccess')
cv2.namedWindow("image", cv2.WINDOW_NORMAL)
# cv2.resizeWindow("image", 1280, 720)
# 为窗口 "image" 设置鼠标回调函数 on_EVENT_LBUTTONDOWN。当鼠标在该窗口中点击时,会触发这个回调函数。
cv2.setMouseCallback("image", on_EVENT_LBUTTONDOWN)
# # 获取图像
# oberrecCamera = Camera()
# color_image, depth_data, depth_image = oberrecCamera.getColorDepthData()
# oberrecCamera.close()
# 创建一个 Pipeline 对象,并通过它获取当前使用的设备。
pipeline = Pipeline()
device = pipeline.get_device()
device_info = device.get_device_info()
device_pid = device_info.get_pid()
# OBCameraParam_param = pipeline.getCameraParam()
# print('OB:',OBCameraParam_param)
# 创建一个 Config 对象,用于配置流媒体的参数。
config = Config()
# 设置对齐模式和同步
align_mode = "SW" # align mode, HW=hardware mode,SW=software mode,NONE=disable align
enable_sync = True # enable sync
# 尝试获取颜色和深度传感器的默认视频流配置,并使用 config.enable_stream 方法启用这些流。
# 如果过程中发生异常,打印异常信息。
try:
profile_list = pipeline.get_stream_profile_list(OBSensorType.COLOR_SENSOR)
# color_profile = profile_list.get_default_video_stream_profile()
color_profile = profile_list.get_video_stream_profile(1280, 800, OBFormat.MJPG, 30)
config.enable_stream(color_profile)
profile_list = pipeline.get_stream_profile_list(OBSensorType.DEPTH_SENSOR)
assert profile_list is not None
# depth_profile = profile_list.get_default_video_stream_profile()
depth_profile = profile_list.get_video_stream_profile(1280, 800, OBFormat.Y16, 30)
assert depth_profile is not None
# 打印颜色和深度流的配置信息,包括分辨率、帧率和数据格式。
print("color profile : {}x{}@{}_{}".format(color_profile.get_width(),
color_profile.get_height(),
color_profile.get_fps(),
color_profile.get_format()))
print("depth profile : {}x{}@{}_{}".format(depth_profile.get_width(),
depth_profile.get_height(),
depth_profile.get_fps(),
depth_profile.get_format()))
config.enable_stream(depth_profile)
except Exception as e:
print(e)
if align_mode == 'HW':
if device_pid == 0x066B:
# Femto Mega does not support hardware D2C, and it is changed to software D2C
config.set_align_mode(OBAlignMode.SW_MODE)
else:
config.set_align_mode(OBAlignMode.HW_MODE)
elif align_mode == 'SW':
config.set_align_mode(OBAlignMode.SW_MODE)
else:
config.set_align_mode(OBAlignMode.DISABLE)
if enable_sync:
try:
pipeline.enable_frame_sync()
except Exception as e:
print(e)
try:
pipeline.start(config)
except Exception as e:
print(e)
while True:
try:
frames: FrameSet = pipeline.wait_for_frames(100)
if frames is None:
continue
color_frame = frames.get_color_frame()
if color_frame is None:
continue
# covert to RGB format
color_image = frame_to_bgr_image(color_frame)
if color_image is None:
print("failed to convert frame to image")
continue
depth_frame = frames.get_depth_frame()
if depth_frame is None:
continue
width = depth_frame.get_width()
height = depth_frame.get_height()
scale = depth_frame.get_depth_scale()
depth_data = np.frombuffer(depth_frame.get_data(), dtype=np.uint16)
depth_data = depth_data.reshape((height, width))
depth_data = depth_data.astype(np.float32) * scale
# 尝试修改alpha 对识别效果的影响
temporal_filter = TemporalFilter(alpha=0.5)
depth_data = np.where((depth_data > MIN_DEPTH) & (depth_data < MAX_DEPTH), depth_data, 0)
depth_data = depth_data.astype(np.uint16)
# Apply temporal filtering
depth_data = temporal_filter.process(depth_data)
# center_distance = depth_data[center_y, center_x]
# depth_image = cv2.normalize(depth_data, None, 0, 255, cv2.NORM_MINMAX, dtype=cv2.CV_8U)
# depth_image = cv2.applyColorMap(depth_image, cv2.COLORMAP_JET)
#
# # overlay color image on depth image
# depth_image = cv2.addWeighted(color_image, 0.5, depth_image, 0.5, 0)
cv2.imshow("image", color_image)
cv2.resizeWindow('image', 1280, 720)
key = cv2.waitKey(1)
if key == ord('q') or key == ESC_KEY:
break
except KeyboardInterrupt:
break
pipeline.stop()
# while(1):
# cv2.imshow("image", img)
# if cv2.waitKey(0)&0xFF==27:
# break
# cv2.destroyAllWindows()
# cv2.imshow("image", color_image)
# cv2.resizeWindow('image', 1280, 720)
# key = cv2.waitKey(1)
# if key == ord('q') or key == ESC_KEY:
# exit
典型流程
1. 手眼标定
运行 AutoCalibProccess.py,采集标定图片与位姿,生成标定参数。
2. 标定验证
运行 visualValidCalib.py,点击画面验证像素-世界坐标映射。
3. 配置参数
编辑 conf/userCmdControl.json,设定机器人、相机、站点、目标物体等参数。
4. 主要分拣任务运行
运行 multi_station_demo.py 或 visualDetect_ali.py,实现多站点分拣或单站点视觉抓取。
5. 集成JAKA机器人、外部轴和AGV的控制功能 utilfs\jaka_integrated.py
# coding:UTF-8
'''
JAKA Integrated Control System
集成JAKA机器人、外部轴和AGV的控制功能
'''
import os
import time
import requests
import json
import socket
try:
from JAKA_SDK_LINUX import jkrc
except:
raise NameError("JAKA SDK path error! current work path: ", os.path.abspath('.'))
from utilfs.jaka import JAKA
class JAKAIntegrated(JAKA):
# 默认设置
DEFAULT_EXT_VEL = 100
DEFAULT_EXT_ACC = 100
DEFAULT_ROB_VEL = 90
def __init__(self, robot_ip, ext_base_url=None, agv_ip=None, agv_port=None):
"""
初始化集成控制系统
:param robot_ip: JAKA机器人IP地址
:param ext_base_url: 外部轴控制基础URL
:param agv_ip: AGV IP地址
:param agv_port: AGV端口
"""
# 调用父类初始化,但不立即连接
super().__init__(robot_ip, connect=False)
# 外部轴控制相关
self.ext_base_url = ext_base_url
if ext_base_url:
self.EXT_MOVETO_URL = f"{ext_base_url}/moveto"
self.EXT_SYSINFO_URL = f"{ext_base_url}/sysinfo"
self.EXT_RESET_URL = f"{ext_base_url}/reset"
self.EXT_ENABLE_URL = f"{ext_base_url}/enable"
self.EXT_GETSTATE_URL = f"{ext_base_url}/status"
# AGV控制相关
self.agv_ip = agv_ip
self.agv_port = agv_port
# 加载外部轴关节限制
self.ext_axis_limits = self._load_ext_axis_limits()
def _load_ext_axis_limits(self):
"""加载外部轴关节限制参数"""
try:
import json
with open('./conf/userCmdControl.json', 'r') as f:
config = json.load(f)
if "extAxisLimits" in config:
return config["extAxisLimits"]
else:
print("警告: 未找到外部轴限制配置,使用默认值")
return {
"joint1": {"min": 0, "max": 200, "desc": "升降,单位mm"},
"joint2": {"min": -140, "max": 140, "desc": "腰部旋转,单位度"},
"joint3": {"min": -180, "max": 180, "desc": "头部旋转,单位度"},
"joint4": {"min": -5, "max": 35, "desc": "头部俯仰,单位度"}
}
except Exception as e:
print(f"加载外部轴限制失败: {e},使用默认值")
return {
"joint1": {"min": 0, "max": 200, "desc": "升降,单位mm"},
"joint2": {"min": -140, "max": 140, "desc": "腰部旋转,单位度"},
"joint3": {"min": -180, "max": 180, "desc": "头部旋转,单位度"},
"joint4": {"min": -5, "max": 35, "desc": "头部俯仰,单位度"}
}
def _adjust_to_joint_limits(self, point):
"""
调整关节位置以确保在限制范围内
:param point: 目标位置 [joint1, joint2, joint3, joint4]
:return: (调整后的位置, 是否被调整, 调整信息)
"""
if not hasattr(self, 'ext_axis_limits') or self.ext_axis_limits is None:
self.ext_axis_limits = self._load_ext_axis_limits()
adjusted = False
messages = []
result = list(point) # 复制输入点以进行调整
joint_names = ["joint1", "joint2", "joint3", "joint4"]
for i, (joint_name, value) in enumerate(zip(joint_names, point)):
if joint_name in self.ext_axis_limits:
min_val = self.ext_axis_limits[joint_name]["min"]
max_val = self.ext_axis_limits[joint_name]["max"]
desc = self.ext_axis_limits[joint_name]["desc"]
if value < min_val:
messages.append(f"{joint_name}({desc})超出最小限制: {value} < {min_val}")
result[i] = min_val
adjusted = True
elif value > max_val:
messages.append(f"{joint_name}({desc})超出最大限制: {value} > {max_val}")
result[i] = max_val
adjusted = True
adjustment_msg = "; ".join(messages) if messages else "无需调整"
return result, adjusted, adjustment_msg
#===========================
# 外部轴控制功能
#===========================
def ext_check_connection(self):
"""检查外部轴连接状态"""
if not self.ext_base_url:
print("外部轴URL未配置")
return False
try:
response = requests.get(self.EXT_SYSINFO_URL, timeout=2)
if response.status_code == 200:
print("外部轴连接正常")
return True
else:
print(f"外部轴连接错误: {response.status_code}")
return False
except Exception as e:
print(f"外部轴连接异常: {e}")
return False
def ext_reset(self):
"""重置所有外部轴关节"""
if not self.ext_base_url:
print("外部轴URL未配置")
return False
response = requests.post(self.EXT_RESET_URL, json={})
if response.status_code == 200:
print("外部轴重置成功")
return True
else:
print(f"外部轴重置失败: {response.status_code}")
return False
def ext_enable(self, enable=True):
"""
使能或禁用外部轴
:param enable: True表示使能,False表示禁用
"""
if not self.ext_base_url:
print("外部轴URL未配置")
return False
response = requests.post(self.EXT_ENABLE_URL, json={"enable": 1 if enable else 0})
if response.status_code == 200:
print("外部轴" + ("使能成功" if enable else "禁用成功"))
return True
else:
print(f"外部轴" + ("使能失败" if enable else "禁用失败") + f": {response.status_code}")
return False
def ext_get_state(self):
"""
获取外部轴状态
:return: 成功返回状态信息,失败返回None
"""
if not self.ext_base_url:
print("外部轴URL未配置")
return None
response = requests.get(self.EXT_GETSTATE_URL)
if response.status_code == 200:
return json.loads(response.text)
else:
print(f"获取外部轴状态失败: {response.status_code}")
return None
def ext_moveto(self, point, vel=None, acc=None):
"""
控制外部轴移动到指定位置
:param point: 目标位置坐标 [x, y, z, r]
:param vel: 速度,默认100
:param acc: 加速度,默认100
:return: 成功返回True,失败返回False
"""
if not self.ext_base_url:
print("外部轴URL未配置")
return False
# 检查关节限制并调整到限制范围内
adjusted_point, was_adjusted, adjustment_msg = self._adjust_to_joint_limits(point)
if was_adjusted:
print(f"警告: {adjustment_msg}")
print(f"原始位置: {point} -> 调整后位置: {adjusted_point}")
point = adjusted_point
vel = vel if vel is not None else self.DEFAULT_EXT_VEL
acc = acc if acc is not None else self.DEFAULT_EXT_ACC
response = requests.post(
self.EXT_MOVETO_URL,
json={"pos": point, "vel": vel, "acc": acc},
)
if response.status_code == 200:
print('外部轴移动成功!')
return True
else:
print(f"外部轴移动失败: {response.status_code}")
return False
#===========================
# AGV控制功能
#===========================
def _send_command_to_agv(self, command):
"""
向AGV发送命令并接收响应
:param command: 要发送的命令
:return: JSON格式的响应数据,失败返回None
"""
if not self.agv_ip or not self.agv_port:
print("AGV连接信息未配置")
return None
try:
# 创建TCP/IP套接字
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
# 连接到服务器
sock.connect((self.agv_ip, self.agv_port))
# 发送命令
sock.sendall(command.encode('utf-8'))
# 接收响应
response = sock.recv(4096).decode('utf-8')
# 解析JSON响应
response_json = json.loads(response)
return response_json
except Exception as e:
print(f"发送AGV命令时发生错误: {e}")
return None
def agv_get_status(self):
"""
获取AGV状态
:return: AGV状态信息,失败返回None
"""
response = self._send_command_to_agv("/api/robot_status")
return response
def agv_moveto(self, point_name):
"""
控制AGV移动到指定标记点
:param point_name: 目标点位的标记号
:return: 成功返回True,失败返回False
"""
# 发送移动命令
response = self._send_command_to_agv(f"/api/move?marker={point_name}")
if not response:
print("发送AGV移动命令失败")
return False
print(f"AGV开始移动到标记点 {point_name}")
print(json.dumps(response, indent=4))
# 等待移动完成
is_done = False
while not is_done:
time.sleep(0.5)
try:
response = self._send_command_to_agv("/api/robot_status")
if response and response['results']['move_status'] == "succeeded":
is_done = True
print(f"AGV已到达标记点 {point_name}")
except Exception as e:
print(f"检查AGV状态时发生错误: {e}")
return False
return True
#===========================
# 集成控制功能
#===========================
def setup_system(self):
"""
初始化整个系统
:return: 成功返回True,失败返回False
"""
# 连接机器人
self.jaka_connect()
robot_ok = True
# 检查外部轴连接
ext_ok = True
if self.ext_base_url:
ext_ok = self.ext_check_connection()
if ext_ok:
self.ext_reset()
self.ext_enable(True)
# AGV无需特别初始化
return robot_ok and ext_ok
def shutdown_system(self):
"""
关闭整个系统
"""
# 断开机器人连接
if self.robot:
self.robot_disconnect()
# 禁用外部轴
if self.ext_base_url:
self.ext_enable(False)
print("系统已关闭")
def move_to_station(self, station_name, agv_marker):
"""
移动到指定工作站
:param station_name: 工作站名称(用于日志)
:param agv_marker: AGV目标点位标记
:return: 成功返回True,失败返回False
"""
print(f"开始移动到工作站: {station_name}")
if self.agv_ip and self.agv_port:
agv_result = self.agv_moveto(agv_marker)
if not agv_result:
print(f"AGV移动到工作站 {station_name} 失败")
return False
print(f"已到达工作站: {station_name}")
return True
# 扩展JAKA类的方法,使其更适用于集成控制系统
def rob_moveto(self, jpos, vel=None):
"""
控制机器人移动到指定关节角度(度数)
:param jpos: 目标关节角度 [J1, J2, J3, J4, J5, J6],单位为度
:param vel: 关节速度,默认90度/秒
"""
import math
vel = vel if vel is not None else self.DEFAULT_ROB_VEL
print(f"输入的关节角度(度): {jpos}")
# 将角度转换为弧度 - 使用math.radians更精确
joint_pos = [math.radians(angle) for angle in jpos]
print(f"转换后的关节角度(弧度): {joint_pos}")
# 执行关节运动
# 注意参数顺序: joints, sp, move_mode
# move_mode=0 表示绝对运动模式
print(f"开始执行关节运动, 速度: {vel}, 模式: 绝对运动(0)")
ret = self.joint_move_origin(joint_pos, vel, 0)
print(f"关节运动结果: {ret}")
return ret
6 utilfs\jaka.py
# coding:UTF-8
'''
JAKA SDK Python API custom-made software development (CSD)
Discription:
JAKA robot movement control library.
'''
import os
import time
try:
from JAKA_SDK_LINUX import jkrc
except:
raise NameError("JAKA SDK path error! current work path: ", os.path.abspath('.'))
class JAKA():
# parameters
_ABS = 0
_INRC = 1
_homePose = None
def __init__(self, address, connect=True):
self.address = address
self.robot = None
if (connect):
self.jaka_connect()
def _login(self): # 3,5
self.jaka_connect()
def _logout(self): # 4,6
self.robot_disconnect()
def _get_sdk_version(self): # 9
ret = self.robot.get_sdk_version()
# print("SDK version is:", ret[1])
return ret
def _get_controller_ip(self): # 10
ret = self.robot.get_controller_ip()
print("controller ip is:", ret[1])
return ret[1]
def _drag_mode_enable(self): # 11
self.robot.drag_mode_enable(True)
ret = self.robot.is_in_drag_mode()
return ret[0]
def _drag_mode_unable(self): # 12
self.robot.drag_mode_enable(False)
ret = self.robot.is_in_drag_mode()
return ret[0]
def _is_in_drag_mode(self):
ret = self.robot.is_in_drag_mode()
return ret[0]
def _set_debug_mode(self): # 14
ret = self.robot.set_debug_mode(True)
return ret[0]
def _unset_debug_mode(self): # 15
ret = self.robot.set_debug_mode(False)
return ret[0]
def send_tio(self,channel,cmd):
return self.robot.send_tio_rs_command(channel, cmd)
def set_user_frame_origin(self,id,user_frame, name):
# '''
# :param id: 用户坐标系 ID,可选 ID 为 1 到 10,0 代表机器人基坐标系
# :param user_frame:用户坐标系参数[x,y,z,rx,ry,rz]
# :param name:用户坐标系别名
# :return:
# '''
ret=self.robot.set_user_frame_data(id, user_frame, name)
if ret[0]==0:
return 0
else:
return -1
def get_user_frame_origin(self):
# '''
# :return: 成功:(0, id, tcp), id : 用户坐标系 ID,可选 ID 为 1 到 10, 0 代表机器人基坐标系
# tcp: 用户坐标系参数[x,y,z,rx,ry,rz]
# '''
ret=self.robot.get_user_frame_data()
return ret
def set_user_frame_id_origin(self,id):
ret = self.robot.set_user_frame_id(id)
if ret[0]==0:
return 0
else:
return -1
def get_user_frame_id_origin(self):
ret = self.robot.get_user_frame_id() # 成功:(0, id),id 值范围为 0 到 10, 0 代表机器人基坐标系
if ret[0] == 0:
return ret[1]
else:
return -1
def grab_action(self,send_tio):
if send_tio == 0:
# open
self.robot.set_digital_output(1, 0, 0)# IO_TOOL =1,设置 DO1 的引脚输出值为 0
time.sleep(0.1)
self.robot.set_digital_output(1, 1, 0)#设置 DO2 的引脚输出值为 0
time.sleep(0.5)
if send_tio == 1:
# close
self.robot.set_digital_output(1, 0, 1)# IO_TOOL =1,设置 DO1 的引脚输出值为 0
time.sleep(0.1)
self.robot.set_digital_output(1, 1, 0)#设置 DO2 的引脚输出值为 0
time.sleep(0.5)
return
def joint_move_origin(self, joints, sp,move_mode):
# joints = 180*joints/pi
move_mode=move_mode if move_mode else 0
sp=sp if sp else 30
ret=self.robot.joint_move(joint_pos=joints, move_mode=move_mode, is_block=True, speed=sp)
# time.sleep(0.08)
if ret[0] == 0:
return 0
else:
return -1
def getjoints(self):
ret = self.robot.get_joint_position()
if ret[0] == 0:
return ret[1]
else:
return None
def tcp_pos(self, homepos):
ret = self.robot.kine_forward(homepos)
if ret[0] == 0:
return ret[1]
def set_analogoutput(self,iotype,index,value):
ret = self.robot.set_analog_output(iotype,index,value)
return ret
# 计算指定位姿在当前工具、当前安装角度以及当前用户坐标系设置下的逆解。
def kine_inverse_origin(self,ref_pos, cartesian_pose):
# '''
# :param ref_pos: 关节空间参考位置,建议选用机器人当前关节位置。
# :param cartesian_pose: 笛卡尔空间位姿计算结果.
# :return:(0 , joint_pos) joint_pos 是一个包含 6 位元素的元组 (j1, j2, j3, j4, j5, j6),
# j1, j2, j3, j4, j5, j6 分别代表关节 1 到关节 6 的角度值
# '''
ret=self.robot.kine_inverse(ref_pos, cartesian_pose)
return ret
def liner_move(self, pos, sp):
# add 180
pos_now = self.robot.get_joint_position()
if pos_now[0] == 0:
print('now pos', pos_now)
target_joint = self.robot.kine_inverse(pos_now[1], pos)
if target_joint[0] == 0:
de = target_joint[1][5] - pos_now[1][5]
print("1::::", de / 3.1415926 * 180)
if (abs(de) > (3.1415 / 2)):
joint_pos = []
for i in target_joint[1]:
joint_pos.append(i)
if de > 0:
joint_pos[5] -= 3.1415
else:
joint_pos[5] += 3.1415
print("2::: ", (joint_pos[5] - pos_now[1][5]) / 3.1415926 * 180)
ret, tcp_pos = self.robot.kine_forward(joint_pos)
else:
tcp_pos = pos
print("move before: ", pos_now)
ret = self.robot.linear_move(end_pos=tcp_pos, move_mode=self._ABS, is_block=True, speed=120)
# ret = self.robot.linear_move(end_pos = pos, move_mode = self._ABS, is_block = True, speed = sp)
pos_now = self.robot.get_joint_position()
print("move after:", pos_now)
if (ret[0] == 0):
pass
else:
print(ret[0])
else:
print(target_joint[0])
# time.sleep(0.08)
else:
print('[JAKA] error!!!!!', pos_now)
# '''
# INCRPose : increase position [X, Y, Z, Roll, Pitch, Yaw]
# '''
def moveInWorldCoordinate(self, INCRPose, speedInput=20):
curPose = self.getpos6DoF()
tarPose = [0, 0, 0, 0, 0, 0]
for i in range(3):
INCRPose[i] = curPose[i] + INCRPose[i]
ret = self.robot.linear_move(end_pos=INCRPose, move_mode=self._ABS, is_block=True, speed=speedInput)
if (ret[0] == -4):
print("[JAKA] Inverse solution failed")
return ret
# get pose
# get [X, Y, Z] pose
def getposXYZ(self):
ret = self.robot.get_tcp_position()
if ret[0] == 0:
return ret[1][0:3]
def get_tcp_pos(self):
ret = self.robot.get_tcp_position()
if ret[0] == 0:
return ret[1]
# get [Roll, Pitch, Yaw] pose
def getposRPY(self):
ret = self.robot.get_tcp_position()
ret = self.robot.get_robot_status()
if ret[0] == 0:
# return ret[1][18][3:]
# else:
print("positon get:", ret)
# get [X, Y, Z, Roll, Pitch, Yaw] pose
def getpos6DoF(self):
ret = self.robot.get_robot_status()
return ret[1][18]
# download program
def download_file(self, local, remote, opt=2):
self.robot.init_ftp_client()
result = self.robot.download_file(local, remote, opt)
print('download file from APP state is : ' + str(result))
self.robot.close_ftp_client()
# upload program
def upload_file(self, local, remote, opt=2):
self.robot.init_ftp_client()
result = self.robot.upload_file(local, remote, opt)
print('upload file to APP, the state is : ' + str(result))
self.robot.close_ftp_client()
# run program
def run_program(self, program):
# program:'./sdk_exam'
ret = self.robot.program_load(program)
if ret[0] == 0:
print('load program success! start running......')
self.robot.get_loaded_program()
ret = self.robot.program_run()
if ret[0] == 0:
print('running program over !!! ')
# disconnect from the robot
def robot_disconnect(self):
self.robot.power_off()
print("[JAKA] power_off successfully")
self.robot.logout()
print("[JAKA] logout successfully")
def jaka_connect(self):
self.robot = jkrc.RC(self.address)
print("[JAKA] logining...")
ret=self.robot.login()
print("login status: "+str(ret))
if not self.robot.power_on():
print("[JAKA] power_on successfully")
if not self.robot.enable_robot():
print("[JAKA] enable_robot successfully")
# else:
# print("[JAKA] enable_robot failed.")
7. utilfs\tools.py
import cv2
import json
from http import HTTPStatus
import dashscope
import numpy as np
from dashscope import MultiModalConversation
import os
PI=3.1415926
dashscope.api_key=os.getenv('DASHSCOPE_API_KEY')
def loadJsonFile(jsonFile):
with open(jsonFile,"r",encoding='utf8') as file:
data=json.load(file)
return data
def simple_multimodal_conversation_call(image_file, text):
"""Simple single round multimodal conversation call.
"""
messages = [
{
"role": "system",
"content": [
{"text": "Caption with Grounding"},
]
},
{
"role": "user",
"content": [
{"image": image_file},
{"text": text},
]
}
]
response = MultiModalConversation.call(model='qwen-vl-max-2025-01-25',
# seed=random.randint(1,20000),
messages=messages,
result_format='message',
response_format={'type': 'json_object'})
# The response status_code is HTTPStatus.OK indicate success,
# otherwise indicate request is failed, you can get error code
# and message from code and message.
if response.status_code == HTTPStatus.OK:
ans = response.output.choices[0].message.content
else:
ans = None
print(response.code) # The error code.
print(response.message) # The error message.
return ans
def vl_ali(tags,img_path):
text = "请帮我将"
for i in range(len(tags)):
if i==len(tags)-1:
text+="和"
elif i>0:
text+=","
text+=tags[i]
text+="这{}种物体在图中框取出来".format(len(tags))
print(text)
image_file = f"file://{img_path}"
ans=simple_multimodal_conversation_call(image_file,text)
if ans and isinstance(ans, list) and len(ans) > 0:
ans_text = ans[0].get('text', '')
try:
json_data = json.loads(ans_text.strip('```json\n').strip('```'))
objs = [item['label'] for item in json_data]
objPos = [[item['bbox_2d'][0], item['bbox_2d'][1], item['bbox_2d'][2], item['bbox_2d'][3]] for item in json_data]
except json.JSONDecodeError as e:
print(f"JSON ERROR: {e}")
objs = []
objPos = []
else:
objs = []
objPos = []
return objs,objPos
def pixel_to_world(pixel_xy, depth, K, R_camera_to_world, T_camera_to_world):
u, v = pixel_xy
# # Intrinsic parameters
fx, fy = K[0][0], K[1][1]
cx, cy = K[0][2], K[1][2]
x_n = (u - cx) / fx
y_n = (v - cy) / fy
X_c = depth * x_n
Y_c = depth * y_n
Z_c = depth
P_camera=np.array([X_c,Y_c,Z_c])
T_camera_to_world=np.array(T_camera_to_world).reshape(3)
P_world=np.dot(np.array(R_camera_to_world),P_camera)+T_camera_to_world
print('Pix_to_world:' ,P_world)
return P_world
def findCorners(img,boardWidth,boardHeight):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, corners = cv2.findChessboardCorners(gray, (boardWidth, boardHeight), None)
return ret
def generatorNearPoints(current_pos,near_point_interval=2,nums=2):
# currentPos = [10, 10]
points = []
points.append(current_pos)
for i in range(1, nums + 1):
left_top_x = current_pos[0] - near_point_interval * i
left_top_y = current_pos[1] - near_point_interval * i
right_bottom_x = current_pos[0] + near_point_interval * i
right_bottom_y = current_pos[1] + near_point_interval * i
for i in range(left_top_x, right_bottom_x + near_point_interval, near_point_interval):
points.append([i, left_top_y])
points.append([i, right_bottom_y])
for j in range(left_top_y + near_point_interval, right_bottom_y, near_point_interval):
points.append([left_top_y, j])
points.append([right_bottom_y, j])
return points
def saveOriginImg(color_image,save_dir):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 获取目录下已有的文件数量
files = os.listdir(save_dir)
img_name = f"{len(files) + 1}.jpg"
# 构造保存路径
img_path = os.path.join(save_dir, img_name)
# 保存图像
cv2.imwrite(img_path, color_image)
return os.path.abspath(img_path)
9. utilfs\lumi_url.py
API_URL = “http://192.168.10.90:5000/api/extaxis”
API_URL = “http://localhost:5000/api/extaxis”
LUMI_ENABLE_URL = API_URL + “/enable”
LUMI_RESET_URL = API_URL + “/reset”
LUMI_MOVETO_URL = API_URL + “/moveto”
LUMI_STATUS_URL = API_URL + “/status”
LUMI_SYSINFO_URL = API_URL + “/sysinfo”
LUMI_GETSTATE_URL = API_URL + “/status”
9 test_client.py
#!/usr/bin/env python3
# coding:UTF-8
'''
测试客户端
用于向socket服务器发送控制命令
'''
import socket
import sys
def send_command(command):
"""
向服务器发送命令并获取响应
"""
try:
# 创建客户端套接字
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接到服务器
host = '127.0.0.1' # 本地服务器地址
port = 9999
client.connect((host, port))
# 发送命令
client.sendall(command.encode('utf-8'))
# 接收响应
response = client.recv(1024).decode('utf-8')
print(f"服务器响应: {response}")
# 关闭连接
client.close()
return response
except Exception as e:
print(f"客户端错误: {e}")
return None
def main():
"""
主函数
"""
if len(sys.argv) < 2:
print("用法: python test_client.py <命令>")
print("可用命令:")
print(" START_DEMO - 启动multi_station_demo.py")
print(" STOP_DEMO - 停止multi_station_demo.py")
print(" STATUS - 查询multi_station_demo.py运行状态")
return
command = sys.argv[1]
send_command(command)
if __name__ == "__main__":
main()
10. socket_control_server.py Socket控制服务器
#!/usr/bin/env python3
# coding:UTF-8
'''
Socket控制服务器
接收客户端命令,并根据命令运行multi_station_demo.py脚本
'''
import socket
import subprocess
import sys
import os
import signal
def start_multi_station_demo():
"""
启动multi_station_demo.py脚本
"""
try:
# 使用subprocess模块运行脚本
process = subprocess.Popen([sys.executable, "multi_station_demo.py"])
print(f"启动multi_station_demo.py成功,进程ID: {process.pid}")
return process
except Exception as e:
print(f"启动multi_station_demo.py失败: {e}")
return None
def stop_process(process):
"""
停止正在运行的进程
"""
if process and process.poll() is None:
try:
# 发送终止信号
process.terminate()
print(f"已发送终止信号到进程 {process.pid}")
return True
except Exception as e:
print(f"停止进程失败: {e}")
return False
return False
def main():
"""
主函数 - 创建Socket服务器并处理连接
"""
# 创建Socket服务器
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 允许端口复用
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定到本地地址和端口
host = '0.0.0.0' # 监听所有网络接口
port = 9999
try:
server.bind((host, port))
server.listen(1)
print(f"服务器启动成功,监听 {host}:{port}")
# 保存当前运行的进程实例
current_process = None
while True:
print("等待连接...")
client, addr = server.accept()
print(f"收到来自 {addr} 的连接")
# 接收数据
data = client.recv(1024).decode('utf-8')
print(f"收到命令: {data}")
# 处理命令
if data == "START_COLA_PROJECT":
if current_process and current_process.poll() is None:
# 如果进程已在运行
response = "multi_station_demo.py 已经在运行中"
print(response)
else:
# 启动新进程
current_process = start_multi_station_demo()
if current_process:
response = "multi_station_demo.py 启动成功"
else:
response = "multi_station_demo.py 启动失败"
elif data == "STOP_DEMO":
if current_process and stop_process(current_process):
response = "multi_station_demo.py 已停止"
current_process = None
else:
response = "没有正在运行的multi_station_demo.py进程"
elif data == "STATUS":
if current_process and current_process.poll() is None:
response = "multi_station_demo.py 正在运行"
else:
response = "multi_station_demo.py 未运行"
else:
response = f"未知命令: {data}"
# 发送响应
client.sendall(response.encode('utf-8'))
# 关闭客户端连接
client.close()
except KeyboardInterrupt:
print("\n用户中断服务器")
except Exception as e:
print(f"服务器错误: {e}")
finally:
# 关闭服务器
server.close()
# 确保所有子进程都被终止
if current_process and current_process.poll() is None:
stop_process(current_process)
print("服务器已关闭")
if __name__ == "__main__":
main()
注意事项
- 需提前配置好机器人、相机、AGV等硬件网络与SDK环境。
- 标定参数需与实际相机/机器人安装位置一致。
- 运行前请确保
conf/下配置文件参数正确,且图片保存目录存在。
参考/扩展
如需更详细的接口说明、二次开发指导,请参考各脚本源码及注释。
Requirements.txt
This file is autogenerated by pip-compile with Python 3.10
by the following command:
pip-compile requirements.in
–index-url https://pypi.tuna.tsinghua.edu.cn/simple
aiohttp3.9.5
# via dashscope
aiosignal1.3.1
# via aiohttp
async-timeout4.0.3
# via aiohttp
attrs23.2.0
# via aiohttp
certifi2023.11.17
# via requests
charset-normalizer2.0.4
# via requests
contourpy1.2.1
# via matplotlib
cycler0.12.1
# via matplotlib
dashscope1.19.0
# via -r requirements.in
fonttools4.51.0
# via matplotlib
frozenlist1.4.1
# via
# aiohttp
# aiosignal
getch1.0
# via -r requirements.in
idna3.10
# via
# requests
# yarl
kiwisolver1.4.5
# via matplotlib
matplotlib3.8.4
# via -r requirements.in
multidict6.0.5
# via
# aiohttp
# yarl
numpy1.26.4
# via
# -r requirements.in
# contourpy
# matplotlib
# opencv-python
opencv-python4.9.0.80
# via -r requirements.in
packaging24.0
# via matplotlib
pillow10.3.0
# via matplotlib
pyparsing3.1.2
# via matplotlib
python-dateutil2.9.0.post0
# via matplotlib
requests2.31.0
# via dashscope
six1.16.0
# via python-dateutil
urllib32.2.1
# via requests
yarl1.9.4
# via aiohttp
{
“robot_ip”: “192.168.10.90”,
“ext_base_url”: “http://192.168.10.100”,
“agv_ip”: “192.168.10.10”,
“agv_port”: 31001,
“comments”: “系统配置文件,包含机器人、外部轴和AGV的连接信息”
}

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 67
67 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)