Sklearn 与 TensorFlow 机器学习实用指南-第五章-支持向量机-笔记
补充:
本文是关于《Sklearn 与 TensorFlow 机器学习实用指南》的学习笔记,基于五、支持向量机 - 【布客】Sklearn 与 TensorFlow 机器学习实用指南 第二版,感谢译者
本文和原文的区别:
本文会更精简、系统地表述书中概念,会对书中未介绍的陌生概念加以解释,每行我都会添加注释,介绍具体做了什么。
后续会持续更新所有章节
正文开始 ~
————————————————
1.线性支持向量机分类
支持向量机(SVM):一种监督学习算法,主要用于分类任务,也可用于回归分析。
核心思想: 通过寻找一个超平面,将不同类别的数据点尽可能分开,并最大化该超平面到最近数据点的距离,在不同类别之间保持了一条尽可能宽敞的街道(即间隔)。SVM 分类器也被称为最大间隔分类。
1.1 软间隔分类
首先来介绍一个概念-线性可分:
线性可分:在数据空间中,存在一条直线(二维)或超平面(高维),能够将不同类别的数据点完全分开,且没有重叠的情况。即:同一类别的所有数据点位于超平面的一侧,没有误分类的样本。
例如二维空间:若两类数据点可以用一条直线完全分开,则数据是线性可分的。
线性不可分:不存在这样的超平面能完全分开数据
1.1.1 硬间隔(hard margin)分类: 所有的数据都在间隔两边
硬间隔分类有两个问题:只对线性可分的数据起作用,对异常点敏感
1.1.2 软间隔(soft margin)分类:允许部分样本误分类或进入间隔,允许间隔违规。
间隔违规:数据点出现在间隔中央或者甚至在错误的一边
为了在”保持间隔尽可能大“和”间隔违规程度“之间找到一个良好的平衡,在 Scikit-Learn 库的 SVM 类,可以用C超参数(惩罚系数)来控制,C值代表了对支持向量的惩罚力度。
当C过大:模型试图将所有训练样本正确分类,包括噪声点,模型可能变得过于复杂,从而可能导致过拟合,对噪声敏感。
当C过小:模型倾向于找到一个简单的一致性较高的决策边界,导致更宽的间隔,增加泛化能力,在数据分布不理想的情况下,可能导致欠拟合和较高的错误率。
import numpy as np
from sklearn import datasets # 数据集
from sklearn.pipeline import Pipeline # 管道
from sklearn.preprocessing import StandardScaler # 标准化(Standardization)处理器:将每个特征的值减去其均值,然后除以标准差。使得数据的分布具有零均值和单位方差。
from sklearn.svm import LinearSVC # 线性支持向量机
iris = datasets.load_iris() # 鸢尾花(Iris)数据集
X = iris["data"][:, (2, 3)] # 花瓣的长、宽
"""
[[1.4 0.2]
[1.4 0.2]
[1.3 0.2]
[1.5 0.2]
........ ]
"""
y = (iris["target"] == 2).astype(np.float64) # 是否为Virginica花,将True、False转变成 0.0 和 1.
# [0. 0. 0. 0. 0. ...]
svm_clf = Pipeline((
("scaler", StandardScaler()),
("linear_svc", LinearSVC(C=1, loss="hinge"))))
svm_clf.fit(X, y) # 拟合数据
print(svm_clf.predict([[5.5, 1.7]])) # 预测类别
# array([ 1.])hinge损失(原始合页损失):max(0, 1 - y_true * y_pred),其中y_true是真实标签(+1或-1),y_pred是预测值。
hinge损失鼓励模型不仅要正确分类样本,还要有一定的置信度。当预测结果与实际标签一致时,损失为0;否则,损失会增加。squared hinge损失(平方合页损失):(max(0, 1 - y_true * y_pred))^2。
squared hinge损失对模型施加更大的惩罚,可能对噪声数据过拟合(平方会放大较大误差的影响)。此外,平方操作使损失函数更加平滑,有助于优化算法的收敛。
分类器的选择:LinearSVC、SVC和SGDClassifier
1. LinearSVC:
- 全称:Linear Support Vector Classification(线性支持向量分类器)。
- 基于:使用线性核,适用于线性可分的数据集。
- 优点:
- 训练速度快,适合高维数据。
- 内存占用较低。
- 缺点:
- 仅能处理线性问题。
- 对于非线性数据表现不佳。
- 适用场景:适用于特征维度较高、且数据呈线性可分的情况。
2. SVC:
- 全称:Support Vector Classification(支持向量分类器)。
- 基于:使用核技巧,可以处理非线性问题。
- 优点:
- 能够通过核函数映射到高维空间,找到复杂的决策边界。
- 对于小规模数据表现优秀。
- 缺点:
- 训练时间较长,特别是当数据集较大或核函数复杂时。
- 内存占用较高。
- 适用场景:适用于中小规模的数据集,尤其是当数据不是线性可分的时候。
3. SGDClassifier:
- 全称:Stochastic Gradient Descent Classifier(随机梯度下降分类器)。
- 基于:使用随机梯度下降算法进行优化,支持多种损失函数(如Hinge、Log损失等)。
- 优点:
- 训练速度快,适合在线学习和大数据集。
- 支持部分训练数据的更新模型,适合实时预测。
- 缺点:
- 对于高维数据可能需要较长的调参时间。
- 模型的泛化能力依赖于正则化参数的选择。
- 适用场景:适用于数据量大、维度高的情况,或者需要快速训练和更新模型的应用。
总结:
需要非线性分类 → 选 SVC;
线性分类且数据量适中 → 选 LinearSVC;
数据极大或需在线更新 → 选 SGDClassifier。
上述分类器的损失函数:


2.非线性支持向量机分类
很多数据集并不是线性可分的。一种处理非线性数据集方法是增加更多的特征,例如多项式特征,例如x1增加特征x2=x1的2次方
以Moons 数据集为例,看如何实现
from sklearn.datasets import make_moons # 卫星数据集(moons datasets)
from sklearn.pipeline import Pipeline # 管道
from sklearn.preprocessing import PolynomialFeatures, StandardScaler # 多项式特征、标准化
from sklearn.svm import LinearSVC # 线性支持向量机
from sklearn.model_selection import train_test_split # 分割训练集、测试集
import numpy as np
import matplotlib.pyplot as plt # 绘图
# 生成 Moons 数据集
X, y = make_moons(n_samples=1000, noise=0.1, random_state=42)
print(X[:2], y[:2])
# [[-0.05146968 0.44419863]
# [ 1.03201691 -0.41974116]]
# [1 1]
# 定义管道:多项式特征 -> 标准化 -> 线性SVM分类器
polynomial_svm_clf = Pipeline([
("poly_features", PolynomialFeatures(degree=3)),
("scaler", StandardScaler()),
("svm_clf", LinearSVC(C=10, loss="hinge"))
])
polynomial_svm_clf.fit(X, y) # 拟合数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 拆分数据集为训练集和测试集
y_pred = polynomial_svm_clf.predict(X_test) # 在测试集上进行预测
# 绘制决策边界
x0_min, x0_max = X[:, 0].min() - 1, X[:, 0].max() + 1 # 取出最小、最大值
x1_min, x1_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x0_min, x0_max, 500), np.linspace(x1_min, x1_max, 500)) # 生成网格点
Z = polynomial_svm_clf.predict(np.c_[xx.ravel(), yy.ravel()]) # 预测每个网格点的类别
Z = Z.reshape(xx.shape) # (250000,) → (500, 500)
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral) # 绘制颜色填充图,显示了模型在网格坐标 (xx, yy) 处的预测结果或概率分布,使用Spectral颜色映射表,红色和蓝色代表了不同的类别。
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral, edgecolors='k') # 绘制散点图,展示了实际数据点的位置,并根据其类别 y 进行上色。每个点的轮廓为黑色。
plt.xlabel('X0') # 轴
plt.ylabel('X1')
plt.title('Decision Boundary on Moons Dataset')
plt.show()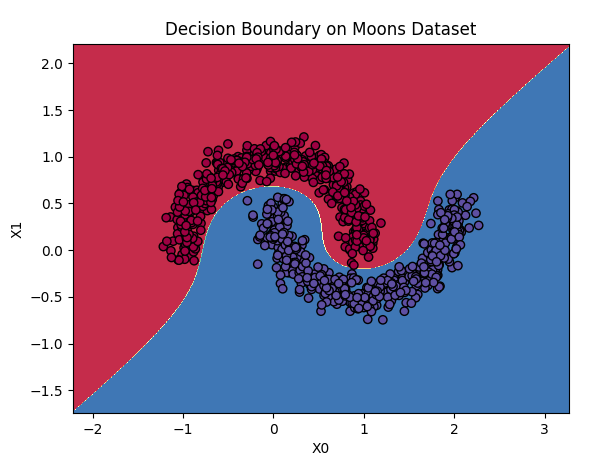
2.1 多项式核
也可以用下面的模型来实现,称为核技巧,它可以取得高次数的多项式一样好的结果。而且能够规避高次数的多项式的缺点,因为没有增加任何特征,所以不会大量特征导致的组合爆炸。
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))
))
poly_kernel_svm_clf.fit(X, y)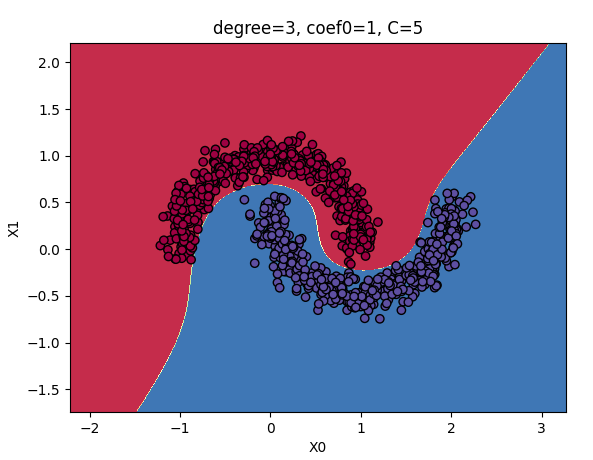
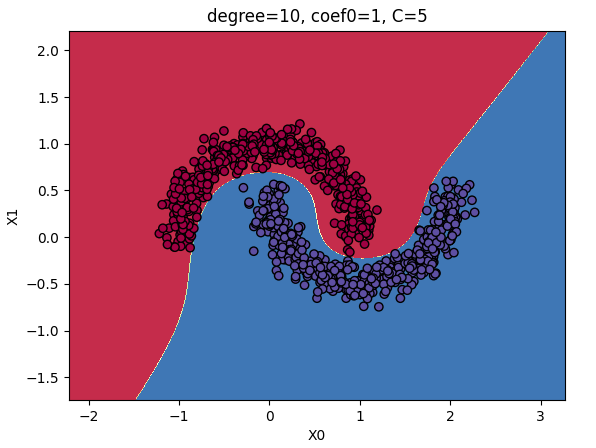
degree和拟合程度的关系:
如果模型过拟合,可以减小多项式核的阶数
如果模型欠拟合,可以增大多项式核的阶数
超参数coef0:偏置项,相当于在计算内积时添加了一个常数项。
coef0和拟合程度的关系:
较大时,模型会更加关注数据点之间的相似性,可能导致模型对训练数据的过度拟合。
较小时,可能使模型更倾向于寻找较简单的模式,减少过拟合的风险。
C:超参数,上文有讲
如何找到合适的超参数?
网格搜索(见第 2 章)去找到最优超参数。首先进行非常粗略的网格搜索,一般会很快,然后在找到的最佳值进行更细的网格搜索。
2.2 增加相似性特征
数据原本的特征不足以分类,于是我们给数据增加新的特征。即每个样本与特定地标(landmark)的相似度。
步骤:设置地标-选定相似函数(高斯径向基函数)-转化原始数据集
相似函数:
![]()
例如x1=-1:距离第一个地标距离是 1,距离第二个地标是 2。因此它的新特征为x2=exp(-0.3 × (1^2))≈0.74和x3=exp(-0.3 × (2^2))≈0.30
缺点:由于一般会选每个样本作为地标,m个样本,n个特征的训练集被转换成了m个实例,m个特征的训练集(假设你删除了原始特征)。这样一来,如果训练集非常大,最终会得到同样大的特征。
2.3 高斯 RBF 核
相似特征法在所有额外特征上的计算成本可能很高,特别是在大规模的训练集上。高斯核函数能获得同样好的效果,同时降低计算成本。
rbf_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001)) # SVC 类的高斯 RBF 核
))
rbf_kernel_svm_clf.fit(X, y)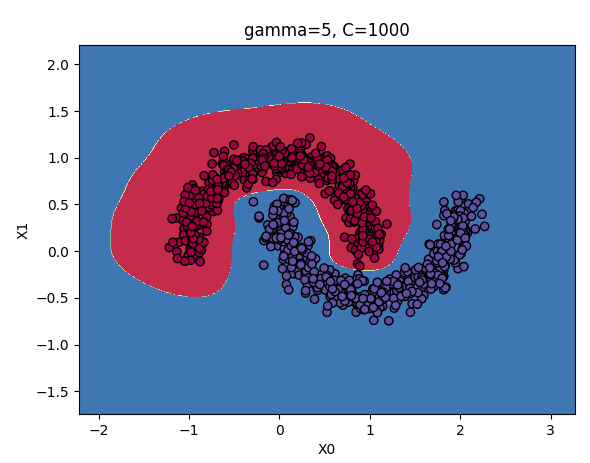
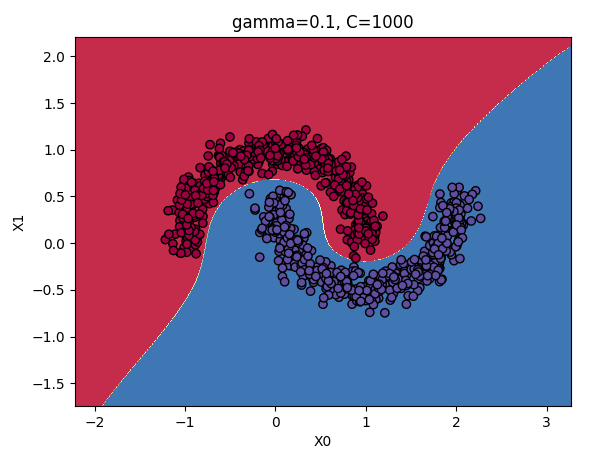
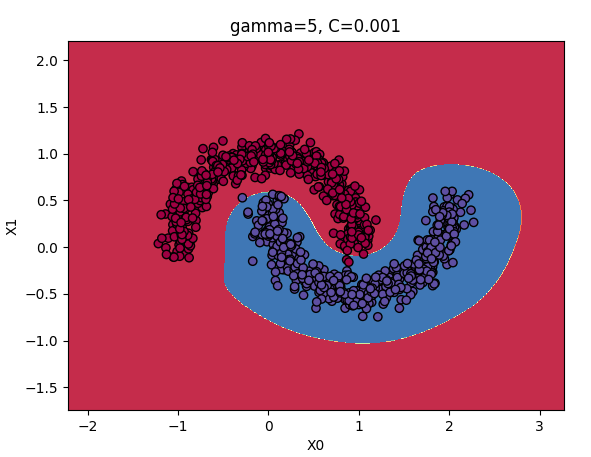
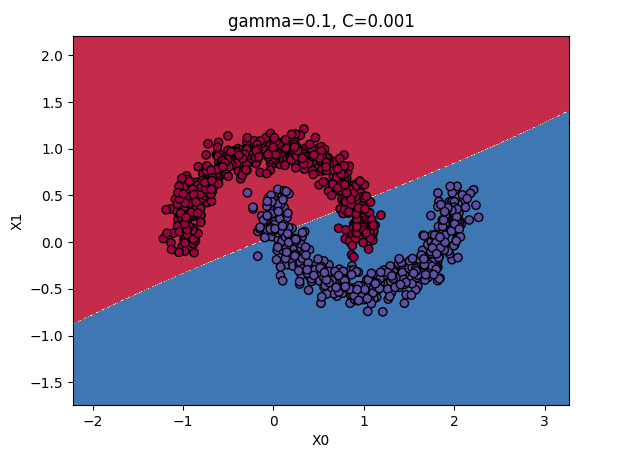
gamma和C参数:
增大:使钟型曲线更窄,样本的影响范围变得更小,即判定边界最终变得更不规则,在单个样本周围环绕。
减小:使钟型曲线更宽,样本有更大的影响范围,判定边界最终则更加平滑。
结论:如果模型过拟合,应该减小参数值;若欠拟合,则增大
核函数的选择:
一般来说,应该先尝试LinearSVC(LinearSVC比SVC(kernel="linear")要快得多),尤其是当训练集很大或者有大量的特征的情况下。
如果训练集不太大,也可以尝试高斯径向基核(Gaussian RBF Kernel),它在大多数情况下都很有效。
如果有空闲的时间和计算能力,还可以使用交叉验证和网格搜索来试验其他的核函数,特别是有专门用于你的训练集数据结构的核函数。
2.4 计算复杂性

3.SVM回归
回归:回归分析是一种统计方法,用于研究一个或多个自变量(独立变量)与一个因变量(依赖变量)之间存在何种关系。
SVR的目标是找到一个函数关系 f(x)(通常为线性或核函数映射后的非线性函数),使大多数样本的预测值在真实值附近的间隔带(称为 ϵ-insensitive tube)内。允许少数样本偏离间隔带,但偏离的程度受到惩罚。
from sklearn.svm import LinearSVR
svm_reg = LinearSVR(epsilon=1.5) # 线性支持向量回归
svm_reg.fit(X, y)引用原文的图,左图是较小的正则化(即更大的C值),右图则是更大的正则化(即小的C值)
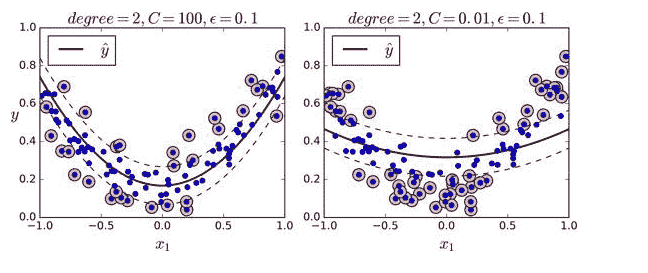
在回归任务上,SVR类和SVC类是一样的,并且LinearSVR是和LinearSVC等价。
LinearSVR类和训练集的大小成线性(就像LinearSVC类),当训练集变大,SVR会变的很慢(就像SVC类)
from sklearn.svm import SVR
svm_poly_reg = SVR(kernel="poly", degree=2, C=100, epsilon=0.1) # 使用多项式核技巧的支持向量回归
svm_poly_reg.fit(X, y)4.背后机制
是对支持向量机数学公式和计算层面的探讨,不影响阅读,后续再来填坑

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)