数据流图/系统流程图/程序流程图设计 - 软考备战(五十二)
数据流图、系统流程图、程序流程图设计
参考资料:
数据流图(DFD)入门指南:概念,绘制教程,实例详解 - ProcessOn知识社区
系统流程图(Flowchart)指南:底层逻辑架构与ISO标准符号详解
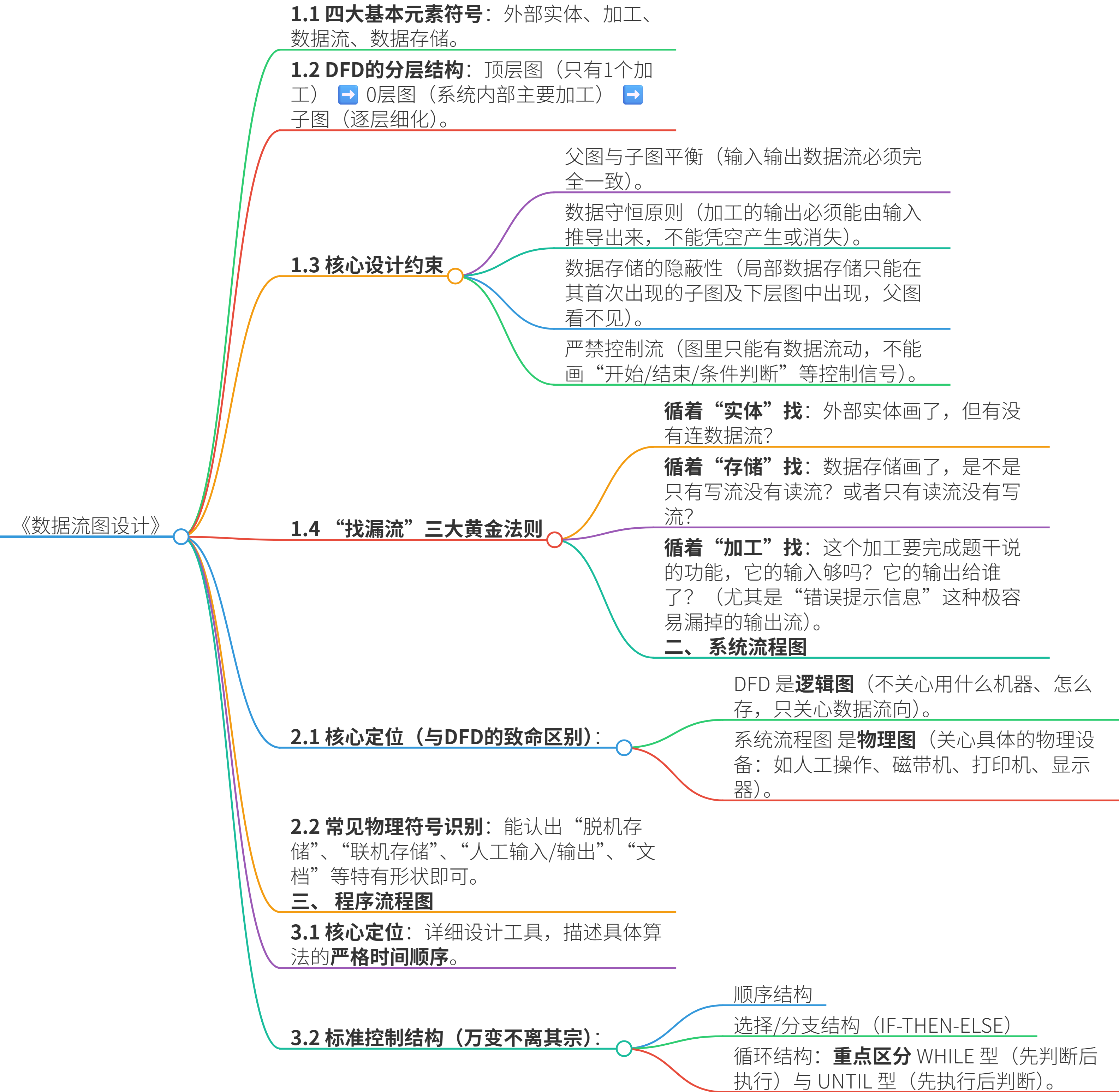
一、 分层数据流图(DFD)
数据流图,顾名思义,就是画“数据”是怎么在系统里“流动”的。
它不关心时间先后,不关心谁先执行谁后执行,它只关心数据的流向和加工变形。
1.1 四大基本元素符号
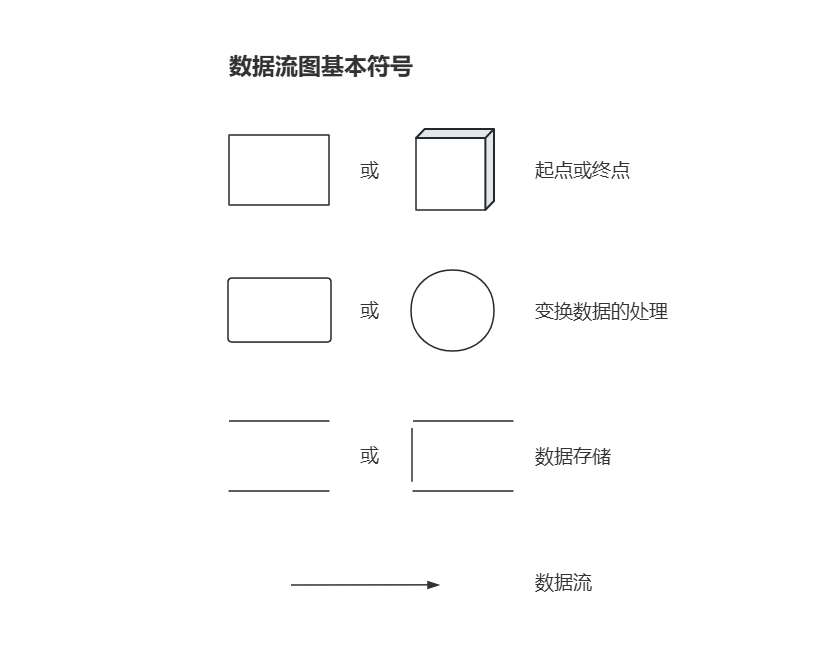
外部实体(矩形/方框)
长相:直角矩形,里面写名字(有时为了区分,会在左上角画一条斜线,但本质一样)。
含义:系统之外的人、外部系统、设备/物品。它是系统数据的提供者(源头)或接收者(终点)。
做题识别:题干里的“用户”、“客户”、“管理员”、“外部系统”。
铁律:外部实体不能参与系统内部的加工,它只能在系统边界上发数据或收数据。
加工(圆角矩形/圆形/泡泡)
长相:圆角矩形或椭圆。里面必须写编号和名字(例如:1.1 验证用户)。
含义:对流入的数据进行处理、变换或计算。
做题识别:题干里的动词短语(“计算工资”、“生成订单”、“校验密码”)。
数据存储(双横线/开口矩形)
长相:两条平行横线,左边有编号(例如:D1 用户表),右边写名字。注意:它没有右边的竖线封口!
含义:数据的暂存处或永久存放处(数据库表、文件)。
做题识别:题干里的“XX表”、“XX文件”、“XX库”、“记录”。
数据流(带箭头的直线)
长相:带箭头的线,线上面写数据流的名字。
含义:数据的流动方向。
注意:
一条数据流上必须写名字!
另外,数据流是有方向的,起点和终点必有一个是加工。
1.2 DFD的分层结构(自顶向下,逐层撕开)
为什么叫“分层数据流图”?
因为一个复杂系统不可能画在一张图里,太乱了。
必须像剥洋葱一样一层层剥开:
顶层图
把整个系统看作唯一的一个大加工(编号为0)。
图里只有外部实体、流向这个大加工的数据流、以及从大加工流出的数据流。顶层图的作用是划定系统边界(谁是系统的外人)。
0层图
把顶层图的那个大加工(0)砸碎,变成几个小的加工(编号1、2、3...)。
这时候系统内部的数据存储(D1、D2...)开始登场。0层图是整个系统的核心骨架。
子图
如果0层图里的加工“1”还是很复杂,就继续把它单独拉出来砸碎,变成加工1.1、1.2、1.3...,这就叫加工1的子图。
1.3 核心设计约束(找错/找漏)
1. 父图与子图平衡(极其重要!)
原则:父图(比如0层图)中某个加工的输入输出数据流,必须与其子图(比如加工1的子图)的输入输出数据流在宏观上完全一致。
举例:
0层图中,加工“1”有一条输入流“用户信息”,两条输出流“验证结果”和“错误提示”。
那么当你去看加工1的子图时,子图整体(不管里面怎么绕)必须也包含这“一进两出”。
如果子图里漏了“错误提示”这条输出流,这就是考点,让你补上!
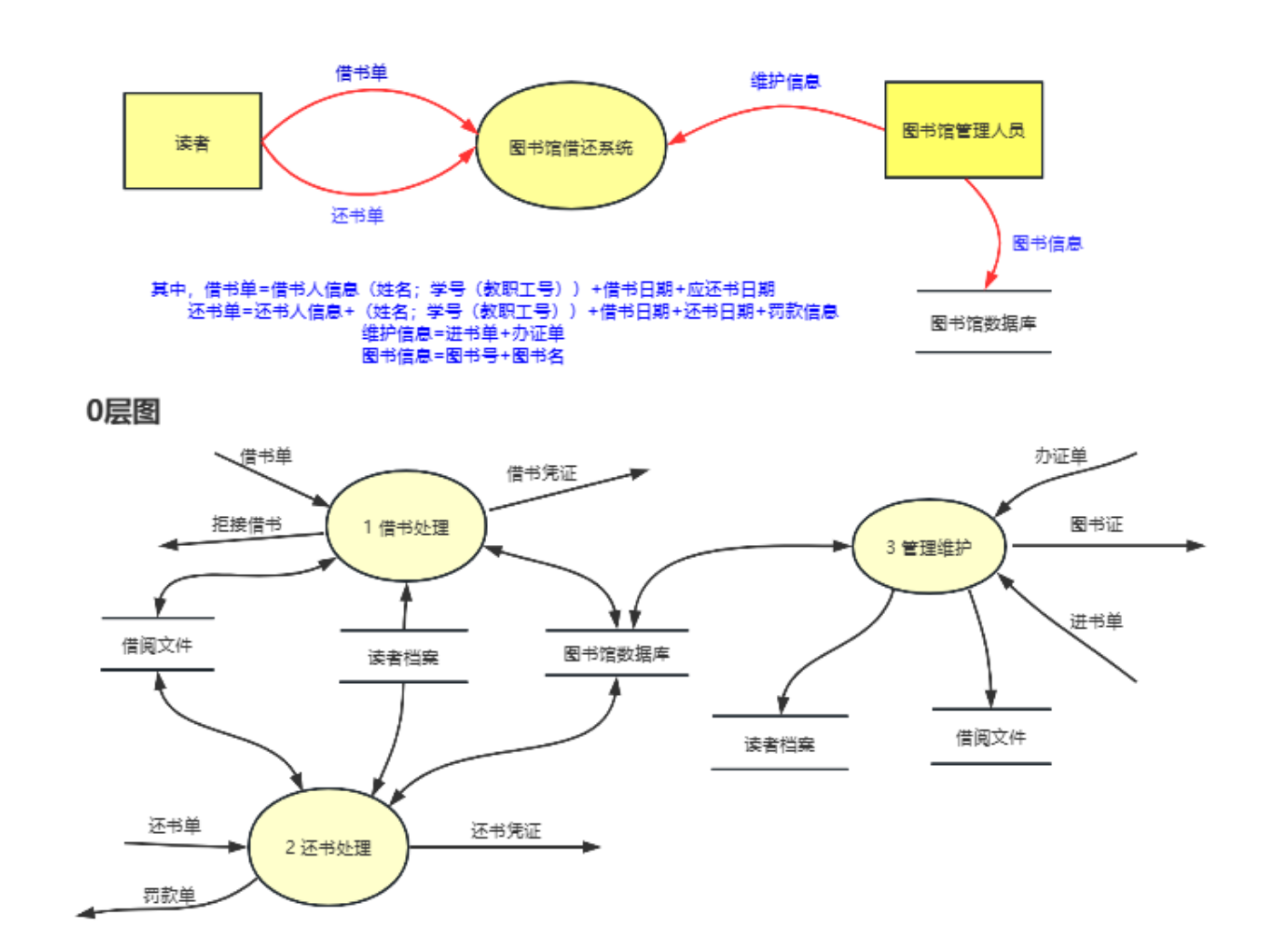
注意:
有时候子图会比父图多出一些数据存储的读写流,这是允许的(因为细节展开了),但外部实体的进出流绝对不能变。
2. 数据守恒原则(黑/白/灰洞理论)
每一个加工都必须遵循“能量守恒定律”:
进去什么,就得出来什么(经过加工变形后)。
绝对不能凭空产生,也不能凭空消失。
黑洞(只进不出)
数据流进了加工,但没有流出来。
比如:收到了“订单数据”,但没有产生任何“订单确认”或“库存扣减”数据,这是错的。
白洞(奇迹)(只出不进)
加工没有输入数据,却凭空输出了数据。
比如:没有收到“查询条件”,却输出了“查询结果”,这叫无米之炊,绝对是错的。
灰洞(进出的数据流一样)
进去了“订单数据”,出来的还是“订单数据”,中间没有任何改变。
这说明这个加工是个废物,啥也没干,违反了“加工必须改变数据”的定义。
3. 数据存储的隐蔽性(首次出现原则)
原则:一个数据存储(比如D1),只有当某个加工需要读写它时,它才应该在那一层图里画出来。
举例:
D1“订单表”在0层图中,只有加工2(创建订单)在写它,加工3(统计订单)在读它。
那么当你去看加工2的子图时,子图里可以画D1。
但是!如果你去看加工3的子图,如果加工3内部的小加工(3.1、3.2)并没有直接读写D1,那么D1绝对不能出现在加工3的子图中。
做题套路:
如果题目问“图X中多了什么元素?”
你去看那个数据存储,发现它在父图里有,但在这个子图里根本没人用它,那它就是多余的。
4. 严禁控制流(数据流图的底线)
原则:数据流图里只能画数据,绝对不能画控制信号。
做题排雷:
看到类似“开始信号”、“结束标志”、“循环控制”、“打开/关闭指令”这种词作为数据流画在图上,直接判错。
这不是数据,这是程序流程图才有的东西。
有时候出题人会玩文字游戏,比如把“取款成功标志”作为数据流。
如果它仅仅是告诉系统“状态变了”,这是控制流;
但如果这个“标志”包含了“成功的金额、时间”等信息,被下游加工用来生成报表了,那它就披着控制流外衣的数据流。
1.4 “找漏流”三大黄金法则
第一步:循着“外部实体”找(查边界)
外部实体是系统的边界。每一个出现在图里的外部实体,它要么给系统发数据,要么收系统的数据,绝不能悬空!
操作:
看图上的外部实体(比如“客户”),如果它只有一条向内的箭头(提交订单),那它大概率缺一条向外的箭头(比如“订单确认反馈”或“错误提示”)。
因为现实中客户不可能只发消息不收回复。
第二步:循着“数据存储”找(查读写成对)
数据存储是被动挨打的,它不能自己动,必须被加工读写。
而业务逻辑决定了,读和写往往是成对出现的。
操作:盯着图上的每一个双横线(D1、D2...),问自己三个问题:
谁往里写数据?
没有写流?补!比如“保存订单”加工必须有流指向“订单表”。
谁从里面读数据?
建了表却不读?补!比如“订单表”必须被“统计加工”读取。
读写的业务闭环完整吗?
比如图里有“增加员工记录”写D1,也有“查询员工”读D1,那有没有“修改员工信息”或“删除员工”的写流?
如果题干提到了修改功能,这里大概率漏了修改的写流。
第三步:循着“加工”找(查逻辑闭环与异常)
看图上某个加工的名字(比如“1.2 验证身份”),然后去题干里找关于这个加工的详细描述。
操作:
查输入够不够
加工要完成它的任务,给它的输入数据够吗?(比如“计算折扣”加工,如果输入只有“商品原价”,没有“会员等级”或“折扣规则表”,那肯定是漏了输入流)。
查输出全不全(重点排查异常分支!)
题干里描述:“如果验证成功,则...;如果验证失败,则返回错误信息”。
不能忽略了“验证失败”时的错误提示输出流!
1.5 答题规范
数据流名字必须精炼(名词或名词短语)。
起点 ➔ 终点:数据流名称
正确示例:客户 ➔ 1.2 提交订单:订单信息
错误示例1(缺箭头):客户 1.2 提交订单 订单信息
错误示例2(起终点反了):1.2 ➔ 客户:订单信息 (明明是客户提交,你写成了系统发给客户)
错误示例3(数据流名字啰嗦):写了一大段话。
二、 系统流程图
系统流程图是“物理图”,它关心的是数据在哪些“具体的物理设备或人”之间流转。
2.1 核心定位与致命区别
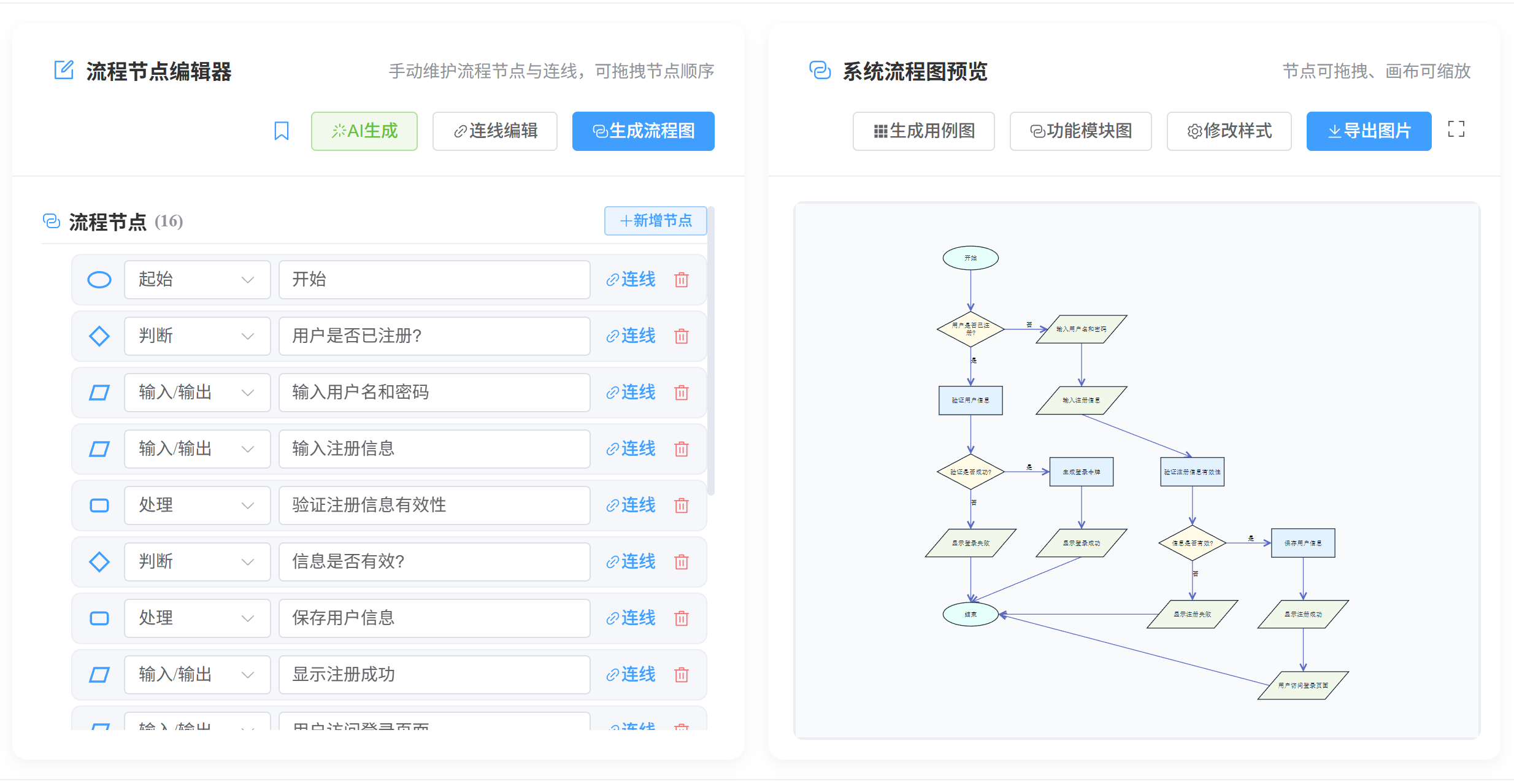
DFD的回答
数据从“客户”流向“处理加工”,再存入“数据存储”。(不知道是用电脑存、还是用纸存、还是用U盘存)。
系统流程图的回答
“业务员”通过“键盘”把数据输入到“磁带”中,然后“主机”读取“磁带”,最后通过“打印机”打印成“报表”。
看到选项里出现了具体的物理设备(磁带、磁盘、显示器、打印机、传感器)或者人工动作(人工核对、手动盖章),那它描述的一定是系统流程图,绝对不是DFD!
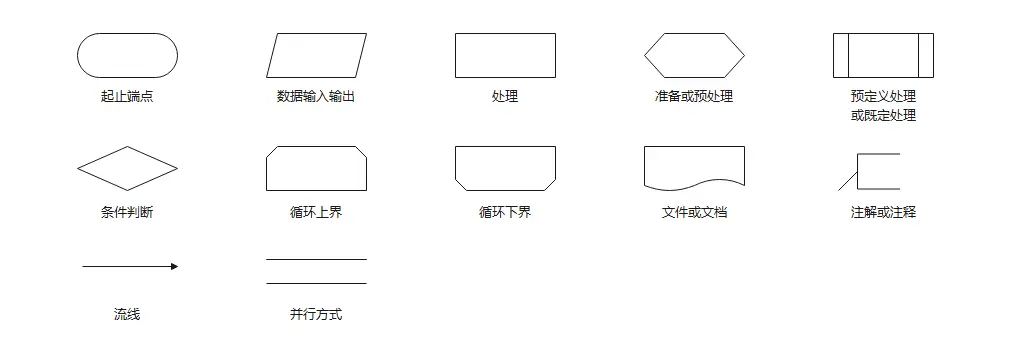
2.2 必须认识的物理符号
人工输入/输出:
梯形(像漏斗),代表需要人用键盘敲或者手写。
文档/报表:
带波浪底边的图形,代表打印出来的纸质文件。
联机存储:
圆柱体(长得跟DFD的数据存储一样,但语境不同,这里特指硬盘等直接连着主机的存储)。
脱机存储:
像一卷磁带或者被画了根线断开的圆柱,代表没插在主机上的备份带、U盘等。
处理:
方框(注意:DFD的加工是圆角,系统流程图的处理是直角方框,代表一段物理程序)。
2.3 常见的5种基本处理操作
系统流程图里,数据在被处理时通常经历以下几种变形:
变换
数据的格式改变。比如把十进制转成二进制,把拼音转成汉字。
分类/排序
按某种规则重排。比如把乱序的员工表按工资从高到低排。
合并
把多个数据集拼成一个。比如把“北京分公司的表”和“上海分公司的表”合在一起。
划分/分解
合并的逆操作。比如把“全校学生名单”按学院拆分成“计算机学院名单”、“文学院名单”等。
更新
用新数据修改老数据。比如用今天的交易流水去修改昨天的账户余额。
三、 程序流程图
这是大家最熟悉的老朋友,也就是我们写代码时画的“框图”。
它属于详细设计阶段的工具,颗粒度极细。
3.1 核心定位
本质
描述具体算法的表达工具,具有极其严格的时间顺序。
区别
DFD没有时间概念(数据可以同时流来流去);
程序流程图有严格的时间先后(第一步干啥,第二步干啥,必须按箭头走)。
3.2 标准控制结构(万变不离其宗)
所有的复杂程序,都是用以下三种基本结构拼起来的(这就是著名的“结构化程序设计”定理):

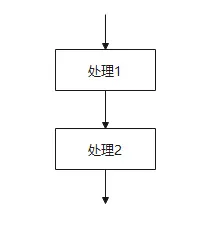
顺序结构
从上到下,一步一步执行(A框 ➡️ B框)。
选择/分支结构
遇到岔路口,根据条件走不同的路。
单分支:如果条件成立,干A;否则什么都不干。
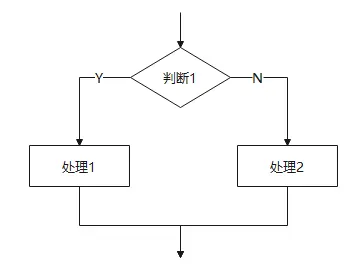
双分支:如果条件成立,干A;否则干B。
多分支:根据变量的值(比如星期几),分成很多条路走。
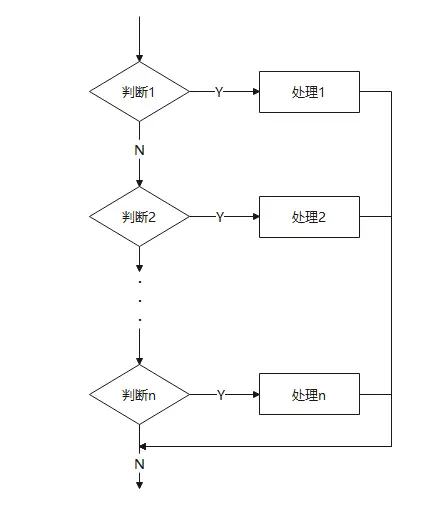
循环结构
循环结构的核心难点在于:什么时候判断条件?
这直接决定了循环体“最少执行几次”。
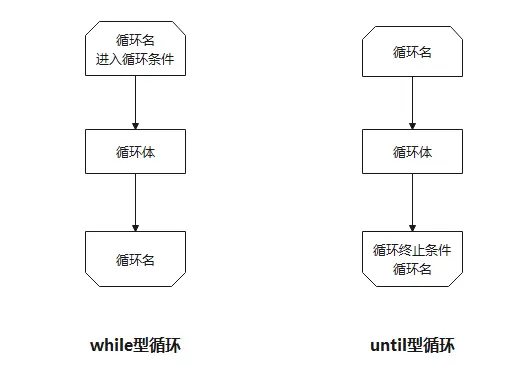
WHILE 型循环(当型循环)
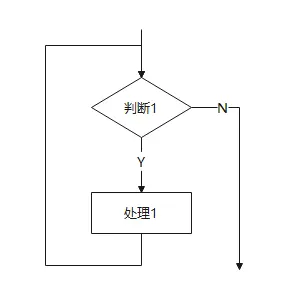
动作顺序:先判断,后执行。
特征:如果一开始条件就不成立,循环体一次都不执行。
记忆:“当条件满足时,我才干活;不满足我就直接跳过”。
UNTIL 型循环(直到型循环)
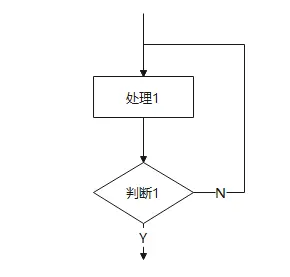
动作顺序:先执行,后判断。
特征:无论条件成不成立,循环体至少要执行一次!
记忆:“一直干活,直到条件满足了才停下来”。
四、 例题分析方法论
90%的答案在题干文字里,流程图只是把文字翻译成了框图。
搞清楚输入是什么、输出是什么、要达成什么业务目的(比如“冒泡排序”、“求最大公约数”)。
画一个表格,列出流程图里所有的变量(比如 i, j, max, temp)。
自己随便编一组最简单的输入数据(比如求最大值,你就编三个数:1, 3, 2)。
按照流程图的箭头,每经过一个处理框,就在草稿纸上更新一次变量的值。走到判断框时,自己判断走Yes还是No。
当你“干跑”到挖空的地方时,看看此时变量的状态,反推这里应该填什么赋值语句或者判断条件(特别注意循环边界 i < n 还是 i <= n,差一个等号结果全错)。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)