ModelCache学习资料汇总 - 大语言模型语义缓存系统
ModelCache简介
ModelCache是由CodeFuse AI团队开发的一个开源项目,旨在为大语言模型(LLM)提供语义缓存能力。通过缓存预生成的模型结果,ModelCache可以显著减少相似请求的响应时间,从而提升用户体验。
该项目的主要目标是通过引入缓存机制来优化LLM服务,帮助企业和研究机构降低推理部署成本,提高模型性能和效率,并为大模型提供可扩展的服务。
核心特性
ModelCache继承了GPTCache的主要思想,包括以下核心模块:
- adapter: 处理各种任务的业务逻辑
- embedding: 将文本转换为语义向量表示
- similarity: 对召回的向量进行排序和相似度评估
- data_manager: 管理数据库
为了更好地适应工业应用,ModelCache在架构和功能上做了一些升级:
- 类似Redis的嵌入式设计,提供语义缓存能力
- 支持多种模型加载方案
- 数据隔离能力(环境隔离、多租户数据隔离)
- 支持系统命令
- 长短文本区分处理
- Milvus性能优化
- 数据管理能力(缓存清理、命中查询召回等)
快速部署
ModelCache提供了两种启动脚本:
- flask4modelcache_demo.py: 快速测试服务,内嵌sqlite和faiss
- flask4modelcache.py: 正常服务,需配置mysql和milvus数据库
依赖环境
- Python 3.8+
- 安装依赖包:
pip install -r requirements.txt
启动服务
- 下载embedding模型文件
- 使用对应脚本启动后端服务
更多详细步骤请参考项目README。
服务访问
ModelCache通过RESTful API提供三个核心功能:缓存写入、缓存查询和缓存清理。
具体的API调用示例代码可以在项目README中查看。
学习资源
- 项目文档: GitHub README
- 技术文章: 微信公众号文章
- 模块架构图:
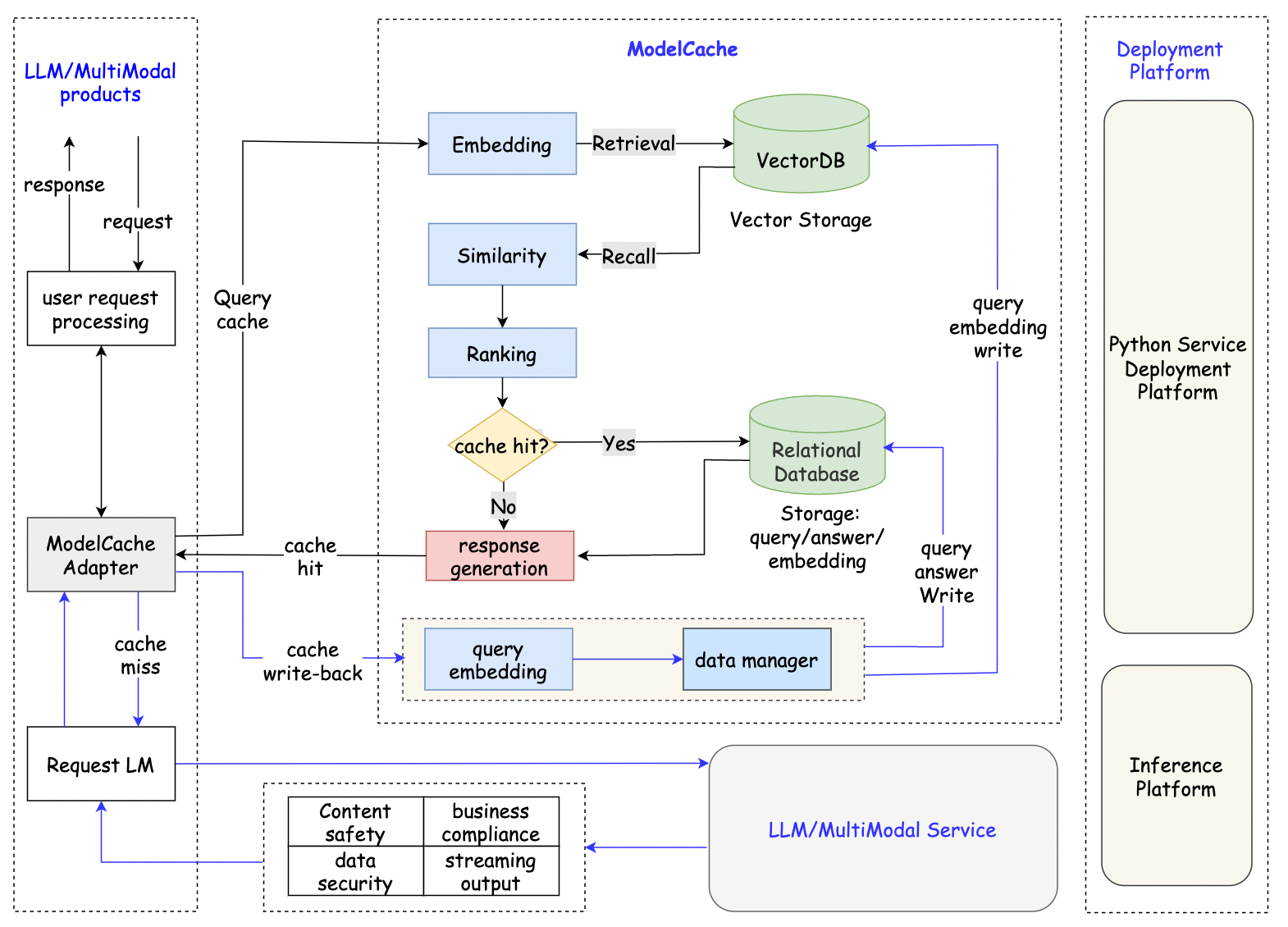
- 源代码: GitHub仓库
参与贡献
ModelCache是一个有趣且有价值的项目,无论您是经验丰富的开发者还是刚刚入门的新手,都欢迎为这个项目做出贡献。您可以通过提出问题、提供建议、编写代码或创建文档和示例来参与,这将有助于提高项目质量并为开源社区做出重要贡献。
总结
ModelCache作为一个针对大语言模型的语义缓存系统,为提升LLM服务性能和用户体验提供了有效解决方案。通过本文汇总的学习资料,读者可以快速了解项目核心思想、部署方法和使用方式,为进一步探索和应用ModelCache打下基础。
文章链接:www.dongaigc.com/a/model-cache-resources-summary
https://www.dongaigc.com/a/model-cache-resources-summary

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)