周志华《机器学习导论》第 4 章 决策树分类
树形分类结构
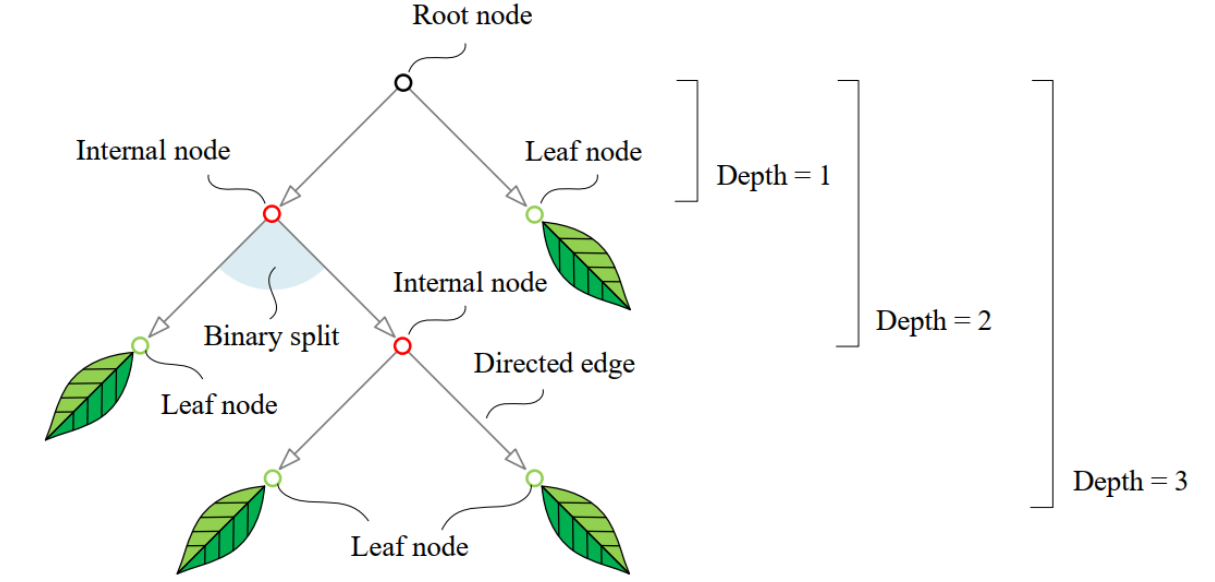
如何选择划分位置(特征选择);划分次数(决策树深度)
baseline 递归划分步骤:
当前子块 如果(都同一类 or 属性都一样 or 集合不包含样本)return 停止划分。
需要划分则 选择特征后,信息增益如果不超过阈值,说明没必要划分,return 停止划分。
按特征划分为不同类,继续递归划分。
1. 特征选择
如何选择特征,使得分支后节点中的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
sklearn - DecisionTreeClassifier 对应参数:
1. 包括分裂策略:
使用什么损失 criterion{“gini”, “entropy”, “log_loss”}, default=”gini”
考虑部分特征 or 随机特征 or 全部特征;
2. 停止条件:
树的最大深度;分裂需要的最小不纯度下降值;
一个叶节点 / 分裂一个内部节点 必须拥有的最小样本数;
3. 后剪枝 ccp_alpha
1.1 信息增益

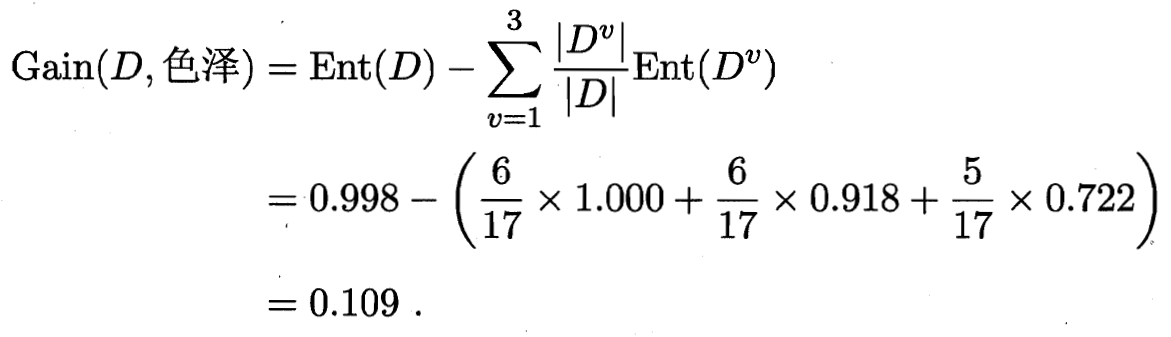
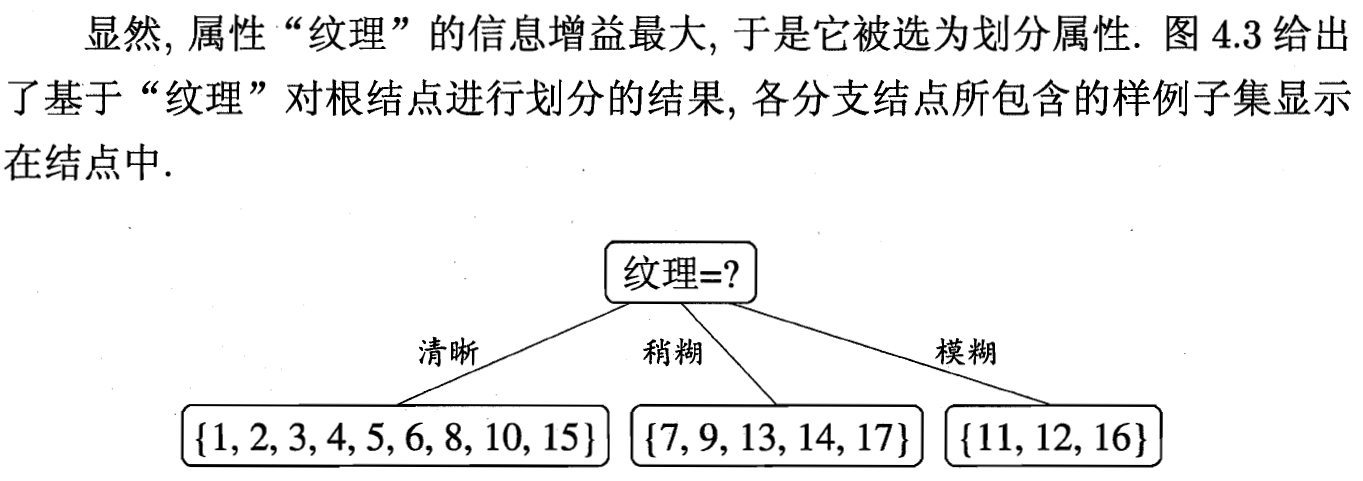
1.2 增益率
上面划分的问题:加入我把标号看做一个特征,按标号划分就把每个样本都分开了。
那上方的信息增益很大,但对我们实际问题的解决没有帮助。
信息增益准则对可取值数目较多的属性有所偏好,
为减少这种偏好可能带来的不利影响,我们引入了“增益率”。
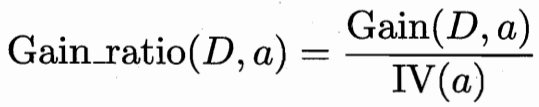
其中分母是特征 a 无关样本类别,对特征 a 的取值数目进行惩罚。
如同类别“纯度”一样,可看做是 特征 a 的纯度。
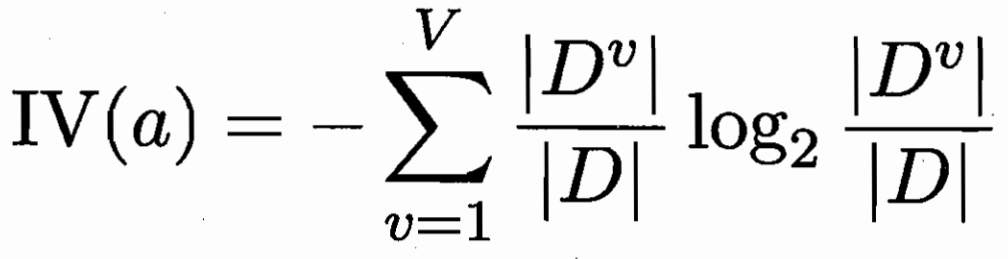
1.3 基尼指数
直观来说,Gini(D) 反映了从数据集 D 中随机抽取两个样本,其类别标记 不一致的概率。
因此Gini(D)越小,则数据集 D 的纯度越高.
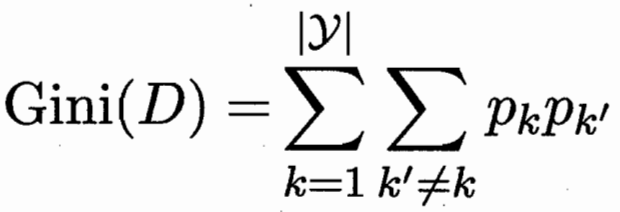
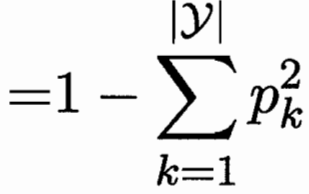 替换信息熵。
替换信息熵。
对应 CART 分类与回归树:用基尼指数不断二分类,形成二叉树。
(做回归任务的话 把基尼指数换成方差 or 均方误差等指标)
在分类树中,叶节点输出的是多数类;在回归树中,叶节点输出所有样本目标值的平均值。
| 学生 | 年级 | 项目经历 | 奖学金 | 会写代码 | 是否适合 |
|---|---|---|---|---|---|
| 小A | 高年级 | 强 | 高 | 不会 | 不适合 |
| 小B | 低年级 | 一般 | 中等 | 会 | 适合 |
| 小C | 低年级 | 无 | 高 | 不会 | 不适合 |
| 小D | 低年级 | 一般 | 高 | 会 | 适合 |
| 小E | 低年级 | 一般 | 低 | 不会 | 不适合 |

看到最后一列,会写代码与适合都对应,即 gini = 0。所以现在该按 代码能力划分。
2. ✂️剪枝(Pruning)
目的:降低模型的过拟合(Overfitting) 风险,提高泛化能力。
方法:通过主动移除决策树中的某些分支或子树,简化模型结构。
| 特点 | 预剪枝 | 后剪枝 |
|---|---|---|
| 剪枝时机 | 建树过程中,划分前判断 | 建树完成后自底向上检查 |
| 判断依据 | 划分是否提高验证集精度 | 替换为叶节点是否提高精度 |
| 训练速度 | 快 | 慢 |
| 过拟合控制 | 较强,可能欠拟合 | 较好,平衡拟合与泛化 |
| 适用场景 | 数据量大、要求训练效率 | 对模型精度要求高 |
3. 连续与缺失值
之前讨论离散特征的情形,但像年龄,含糖量等等连续值。
可以进行选阈值二分划分,年龄 ≤ a 的为一类,年龄 > a 的为一类。
可以先排序,然后取相邻值的中间值作为候选分割点,再找最优划分点。
缺失值处理:如何选择属性?
对于属性A:只考虑在属性 A 中没有缺失值的样本子集,
由于只用了部分样本,乘上补偿系数(部分样本在总样本数的占比)
若选择的属性,样本在该属性缺失,如何划分样本?
按照有属性值的 左右子树比例,把属性值缺失的样本按照比例概率划分到左右子树。
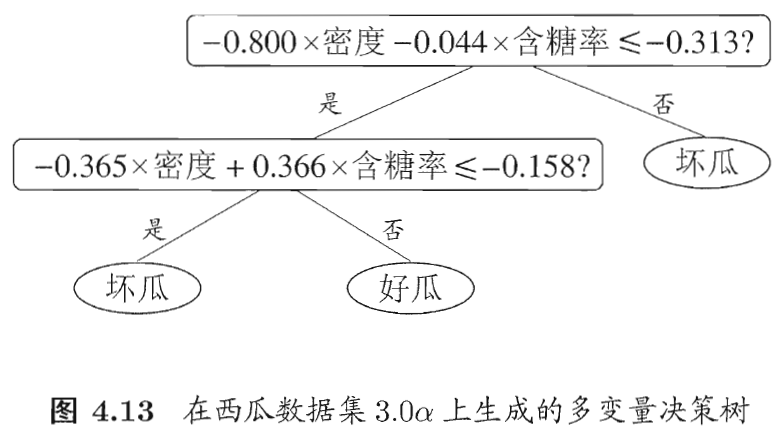
4. 多变量决策树
如果只是单特征划分,每次划分都是平行于坐标轴的。
但现实中复杂情形,可能需要多个平行于轴的进行划分。
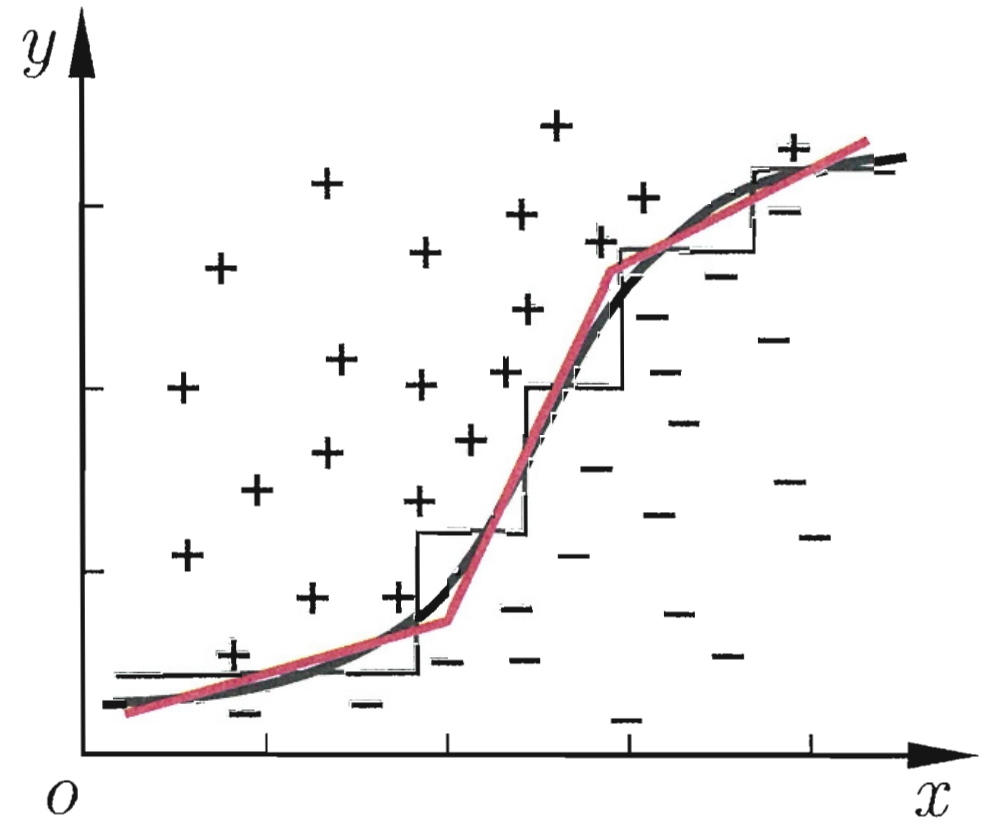
联系现实,特征之间相互作用影响标签,需要结合考虑。
非叶结点不再是仅对某个属性,而是对属性的线性组合进行测试:
每个非叶节点,对应空间中的一个分类边界 ![]()

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 13
13 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)