医学图像分析中的目标检测:来自RT-DETR模型的见解
点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
https://dl.acm.org/doi/full/10.1145/3730436.3730506
计算机视觉研究院专栏
Column of Computer Vision Institute
深度学习已成为解决复杂模式识别和目标检测难题的变革性方法。本文聚焦于基于RT-DETR模型的新型检测框架在分析复杂图像数据中的应用,尤其关注糖尿病视网膜病变检测等领域。

PART/1
概述
深度学习已成为解决复杂模式识别和目标检测难题的变革性方法。本文聚焦于基于RT-DETR模型的新型检测框架在分析复杂图像数据中的应用,尤其关注糖尿病视网膜病变检测等领域。糖尿病视网膜病变是全球致盲的主要原因之一,需要准确且高效的图像分析来识别早期病变。所提出的RT-DETR模型基于Transformer架构构建,在处理高维医学图像数据时表现出色,具有更强的鲁棒性和准确性。与YOLOv5、YOLOv8、SSD和DETR等模型的对比评估表明,RT-DETR在精度、召回率、mAP50和mAP50-95等指标上均实现了更优的性能,尤其在检测小规模目标和密集分布目标时表现突出。本研究强调了像RT-DETR这样的基于Transformer的模型在推进目标检测任务方面的潜力,为医学成像及其他领域提供了有前景的应用方向。
PART/2
背景
糖尿病视网膜病变(DR)是糖尿病患者最常见的眼部并发症,也是全球成年人视力丧失的主要原因之一。该疾病在早期通常无明显症状,患者往往会忽视,这会导致病情恶化,最终可能引发失明。早期检测和干预是预防视力丧失的关键。传统的DR筛查通常依赖眼科医生通过手动检查视网膜图像来诊断。这一过程耗时且具有高度主观性,还可能受到诊断医生的经验和疲劳程度的影响。因此,基于深度学习的自动诊断系统已成为重要的研究方向。
深度学习的发展开启了计算机视觉和医学图像分析的新纪元,改变了复杂视觉数据的解读和处理方式。在这一背景下,医学影像中病灶的检测面临一系列独特挑战,包括病灶区域尺寸小、密集目标分布广泛以及图像对比度低等。所有这些因素都要求使用鲁棒且高精度的检测框架。近年来,深度学习模型,尤其是卷积神经网络(CNNs),通过实现自动化、可扩展且客观的系统,在医学诊断变革中发挥了关键作用。Xiao等人的研究就是一个具有代表性的例子,在该研究中,细胞神经网络被用于对乳腺癌的细胞病理学图像进行分类。这项工作不仅展示了CNN识别复杂细胞结构的能力,还展示了深度学习架构如何降低诊断主观性。
尽管取得了成功,但传统CNN模型在处理视觉任务时常常面临困难,尤其是在医学影像场景中,病灶特征可能很细微或视觉上模糊不清。这些局限性促使了旨在改进特征表示和区分度的架构创新。例如,Du的研究探索了一种优化的CNN架构,该架构适用于智能异常检测,在这种检测中,必须在有噪声的条件下检测到微小但重要的模式。本研究聚焦于优化参数效率和提高异常敏感性的方法,直接阐明了图像中损伤的准确检测所需的策略。
除了单一模型架构外,基于图的方法已成为表示数据点间复杂相互依赖关系的新范式。Mei等人提出了一种用于疾病风险评估的协作超映射网络,该网络整合了患者层面和特征层面的相关性,以丰富预测建模。Gao等人也通过扩展超图框架实现了这种关系推理能力,通过多通道设计捕捉时间和上下文关系。尽管这些模型并非直接为视觉检测而设计,但捕捉不同数据点间更高阶依赖关系的基本原理可用于增强图像检测任务中的空间感知和关系推理能力,尤其是在诊断如糖尿病视网膜病变这类进行性疾病时。
强化学习领域也为改进视觉模型提供了概念性贡献。Yao提出了一种用于系统动态风险控制的时间序列强化学习策略。该模型适应实时决策策略的能力,反映了自适应图像处理系统的需求,在这类系统中,检测策略必须随输入数据而变化。通过将强化学习技术转化为研究视角,RT-DETR的未来迭代可以结合自适应学习路径、动态校准注意力权重,或根据损伤的密度或空间分布修改检测策略。
与此同时,最初为自然语言处理(NLP)开发的大规模模型优化策略正日益应用于可视化任务。Hu等人专注于使用基于LoRa的微调算法优化大型语言模型,以显著提高训练效率和鲁棒性。尽管其语境是语言学层面的,但低阶自适应和有效参数微调的潜在机制为在医学影像中扩展视觉Transformer提供了一条很有前景的途径。这些技术能够在不产生高额计算成本的情况下,对RT-DETR模型进行特定领域的调整,从而实现多疾病视网膜筛查或多模态诊断等任务的定制化。
这些不同的研究共同为现代深度学习研究提供了一个多维度的视角,阐明了架构设计、训练策略、优化和数据表示方面的创新如何融合,以提高自动化感知系统的效率。从基于CNN的损伤分类器到由Transformer驱动的检测流程,从少样本学习到超图推理和神经架构搜索(NAS),本文反映了在医学影像等复杂且高风险环境中推动深度学习发展的持续努力。这些研究成果为RT-DETR的采用和发展奠定了坚实基础,并为该模型在糖尿病视网膜病变检测及更广泛的医学应用中的成功提供了方法论知识和实用技术。
PART/3
新算法框架解析
为实现糖尿病视网膜病变病灶的自动检测,本研究采用RT-DETR深度模型,通过端到端目标检测框架完成病灶的识别与定位。RT-DETR采用基于Transformer的检测头结构,通过注意力机制实现高效的目标特征提取和目标检测。该模型结构由三部分组成:特征提取网络、位置编码模块和目标检测头,形成了无NMS(非极大值抑制)的目标检测架构。本节将详细推导该模型的目标检测过程及损失函数的定义。模型架构如图1所示。
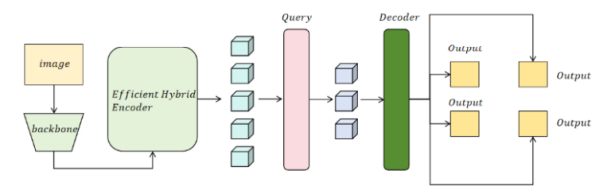
图1
通过对上述目标检测机制和综合损失函数的优化,本研究实现了糖尿病视网膜病变病灶的高效自动检测。该模型充分利用了RT-DETR的注意力机制和无NMS检测策略,提升了对微小病灶和密集目标的识别能力,确保了检测结果的准确性和鲁棒性。
PART/4
新算法框架解析
数据集
本研究采用EyePACS数据集作为主要数据源,该数据集是糖尿病视网膜病变研究领域公开可用的资源。EyePACS在医学数据分析领域,尤其是糖尿病视网膜病变(DR)的自动化诊断方面得到了广泛认可。它包含了来自不同地区糖尿病患者的数千张视网膜图像,每张图像都经过仔细标注,以反映不同程度的病灶。该数据集将图像分为五个严重程度等级,范围从0级(无病变)到4级(重度病变),分级基于医学专业人员的手动诊断结果。这些带有完整临床标签的高质量眼底图像,为训练和验证用于DR检测的深度学习模型提供了宝贵基础。
EyePACS数据集中的图像来自大型医学影像平台,且经过细致的预处理和标注,以确保准确性和一致性。每张图像通常为224×224像素,保持了高分辨率和清晰度,有助于模型检测最细微的病变变化。该数据集同时包含健康和病变的视网膜图像,涵盖了糖尿病视网膜病变的关键特征,如微动脉瘤、出血和渗出。由于这些早期病变通常难以通过传统图像处理方法检测,EyePACS特别适合基于深度学习的自动化诊断。
EyePACS已在深度学习研究中被广泛采用,是糖尿病视网膜病变自动化诊断的标准基准数据集。它拥有约35,000张带标注的图像,涵盖了多样的视网膜图像质量和临床病例,非常适合训练大规模模型。通过利用该数据集,研究人员可以在真实临床场景中评估模型性能,最终推动糖尿病视网膜病变早期筛查和诊断技术的发展。使用该数据集的对比实验有助于评估模型的泛化能力、准确性以及在疾病早期检测中的有效性。

从实验结果可以看出,RT-DETR模型在多项评估指标上表现出色,在微小目标检测能力和复杂场景鲁棒性方面超越了其他几款目标检测模型。首先,RT-DETR的准确率(Precision)为0.90,显著高于其他模型,表明其能更准确地检测糖尿病视网膜病变病灶,减少假阳性结果的产生。相比之下,YOLOv5和YOLOv8的准确率分别为0.86和0.88。尽管它们的表现也不错,但在该指标上的差距显示,RT-DETR在目标识别和定位方面具有更高的可靠性。SSD和DETR模型的准确率分别为0.82和0.85,相对较低,这表明它们在视觉特征提取和目标识别过程中可能存在一定不足,尤其是在糖尿病视网膜病变病灶这类细微病灶的检测中。RT-DETR的表现更符合临床需求。
其次,RT-DETR在召回率(Recall)上具有显著优势,数值为0.85,高于YOLOv8的0.83、YOLOv5的0.80以及DETR的0.79。更高的召回率意味着RT-DETR能够识别更多的病灶区域,尤其是那些难以检测的微小目标和边缘病灶。RT-DETR显然具有更强的捕捉能力。相比之下,虽然YOLOv5和YOLOv8的召回率较高,但仍低于RT-DETR,这可能与其在处理微小目标时的局限性有关。SSD模型的召回率为0.75,在所有模型中最低,表明其在检测一些微小病灶和难以识别的病灶区域时效果较差,这也反映了SSD在复杂病灶场景下的不足。
在mAP50(交并比(IoU)阈值为50%时的平均精度均值)方面,RT-DETR再次领先,得分为0.88,超过了YOLOv5的0.86、YOLOv8的0.84和DETR的0.83。mAP50反映了模型在IoU为50%的情况下检测目标的准确率。RT-DETR的高分表明,在常见的IoU阈值条件下,它能够更好地定位和识别目标。YOLOv5和YOLOv8的表现也不错,但仍不及RT-DETR,这表明在目标定位准确性方面,RT-DETR更能满足临床对病灶检测准确性的需求。DETR的mAP50为0.83,尽管它也表现良好,但其目标定位能力略逊于RT-DETR和YOLO系列,尤其是在糖尿病视网膜病变等复杂背景下的目标检测任务中,RT-DETR表现出更高的准确性。
mAP50-95(IoU阈值从50%到95%的平均精度)进一步凸显了RT-DETR的优势。该指标衡量模型在不同IoU阈值下的平均精度,反映模型对检测框准确性的综合评估。在该指标中,RT-DETR以0.76的得分远超其他模型,尤其是在IoU阈值较高的条件下(如IoU大于75%),这表明RT-DETR在高精度要求下仍能保持较高的检测准确率。相比之下,YOLOv8(0.72)、YOLOv5(0.70)和DETR(0.68)都存在一定差距,尤其是在微小病灶和密集目标检测任务中。RT-DETR能有效提高检测框的准确性和鲁棒性,而其他模型在高精度要求下性能有所下降,可能在细粒度目标定位和高密度病灶区域检测方面面临挑战。
总体而言,RT-DETR不仅在所有指标上表现出色,其无NMS设计策略和基于Transformer的深度学习架构还特别适用于糖尿病视网膜病变病灶的自动检测。RT-DETR能有效应对微小病灶、复杂背景和高密度目标等挑战,使其在临床应用中具有很高的实用性。与YOLOv5、YOLOv8、SSD和DETR相比,RT-DETR在准确率、召回率和目标定位准确性方面具有明显优势,尤其是在糖尿病视网膜病变这种复杂疾病的自动检测中,RT-DETR展现出了其独特的优势。这些结果表明,RT-DETR在该疾病的早期筛查和诊断中具有更高的潜力,能够为糖尿病视网膜病变的诊断提供更可靠、更准确的支持。 此外,我们还给出了实验过程中的损失函数下降图,如图2所示。
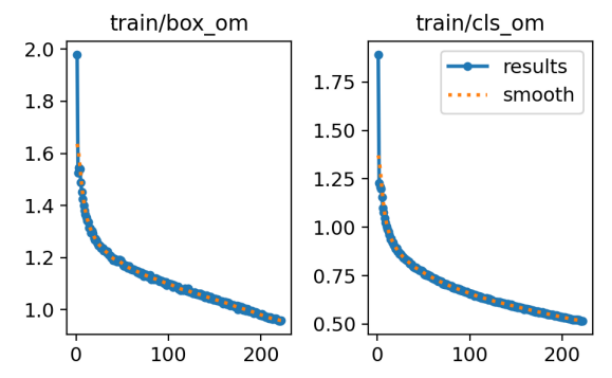
图2
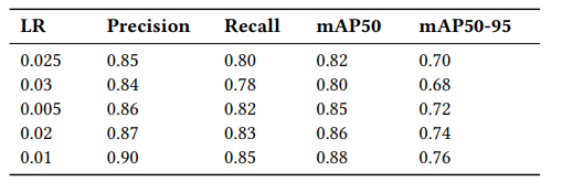
在消融实验中,我们探究了不同优化器对实验结果的影响。
通过对不同学习率的实验对比,当学习率为0.01时模型性能最佳,准确率、召回率、mAP50和mAP50-95均达到最高值。较低的学习率(如0.005和0.02)表现略差,尤其是在准确率和召回率方面。实验结果表明,合适的学习率能显著提升RT-DETR模型在糖尿病视网膜病变检测中的性能。
结论
本研究凸显了RT-DETR模型(一种基于Transformer的自动检测框架)的优势,它通过在准确率、召回率和mAP指标上的卓越表现,推动了目标检测技术的发展。对比实验表明,RT-DETR在性能上优于YOLOv5、YOLOv8、SSD和DETR等主流模型,尤其在处理小规模目标以及在复杂背景下保持鲁棒性方面表现突出。这些结果证实了RT-DETR作为解决高维图像分析挑战的领先方法的潜力,包括其在糖尿病视网膜病变检测中的适用性——该检测需要在分析复杂视觉模式时兼具精度和效率。
尽管RT-DETR表现出强劲的性能,但在应对数据分布不均和高度复杂的视觉背景带来的挑战方面,仍有进一步优化的空间。未来的研究可以聚焦于增强模型的多尺度特征学习能力、丰富训练数据集的质量和多样性,以及整合多模态数据源。这些进展将进一步完善基于Transformer架构的鲁棒性和泛化能力,释放其在不同领域的全部潜力。除了目前在糖尿病视网膜病变检测中的应用,RT-DETR还可扩展到自动化图像分析的广泛挑战中,例如检测黄斑变性、青光眼和其他眼科疾病。将深度学习与多模态数据集(包括病历和生理测量数据)相整合,将有助于开发更全面的诊断工具。此外,基于Transformer架构的改进将继续推动实时图像处理、可扩展人工智能系统和多模态数据融合等领域的创新,使RT-DETR成为通用图像分析的基础框架。
总体而言,本研究强调了人工智能在视觉识别和自动化诊断方面的变革潜力。RT-DETR例证了深度学习(尤其是基于Transformer的模型)如何重塑目标检测和数据驱动决策制定中的复杂任务,为从医学影像到工业应用等领域的智能精准解决方案铺平了道路。随着持续发展,RT-DETR及类似模型将在推动人工智能驱动系统的创新中发挥关键作用。
有相关需求的你可以联系我们!

END



转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
往期推荐
🔗

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 23
23 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)